Vous pouvez vous fier à votre avis, formé à partir de différentes sources d'informations, par exemple des publications sur des sites ou de l'expérience. Vous pouvez demander à des collègues et connaissances. Une autre option est de se pencher sur les sujets de la conférence: le comité de programme est des représentants actifs de l'industrie, nous leur faisons donc confiance pour choisir les sujets pertinents. Un domaine distinct est la recherche et les rapports. Mais il y a un problème. Des recherches sur l'état du DevOps sont effectuées chaque année dans le monde, des rapports sont publiés par des sociétés étrangères et il n'y a presque aucune information sur le DevOps russe.
Mais le jour est venu où une telle étude a été menée, et aujourd'hui nous vous parlerons des résultats obtenus. L'état du DevOps en Russie a été étudié conjointement par Express 42 et Ontiko". Express 42 aide les entreprises technologiques à mettre en œuvre et à développer des pratiques et des outils DevOps et a été l'un des premiers à parler de DevOps en Russie. Les auteurs de l'étude, Igor Kurochkin et Vitaly Khabarov, sont engagés dans l'analyse et le conseil chez Express 42, ayant une formation technique de l'exploitation et une expérience de travail dans différentes entreprises. Depuis 8 ans, des collègues se sont penchés sur des dizaines d'entreprises et de projets - des startups aux entreprises - avec des problèmes différents, ainsi qu'une maturité culturelle et technique différente.
Dans leur rapport, Igor et Vitaliy ont expliqué quels étaient les problèmes rencontrés dans le processus de recherche, comment ils les avaient résolus, ainsi que la manière dont la recherche DevOps est menée en principe et pourquoi Express 42 a décidé de mener la sienne. Leur rapport peut être consulté ici .

Recherche DevOps
Igor Kurochkin a commencé la conversation.
Nous posons régulièrement une question au public lors des conférences DevOps: "Avez-vous lu le rapport de situation DevOps pour cette année?" Seuls quelques-uns lèvent la main et notre étude a montré que seul un troisième les étudie. Si vous n'avez jamais vu de tels rapports, disons tout de suite qu'ils sont tous très similaires. Le plus souvent, il y a des phrases comme: "Par rapport à l'année dernière ..."
Ici, nous avons le premier problème, et après deux autres:
- Nous n'avons pas de données pour l'année écoulée. L'état du DevOps en Russie n'intéresse personne;
- Méthodologie. Il n'est pas clair comment tester des hypothèses, comment construire des questions, comment effectuer des analyses, comparer les résultats, trouver des liens;
- Terminologie. Tous les rapports sont en anglais, une traduction est nécessaire, un framework DevOps commun n'a pas encore été inventé et chacun propose le sien.
Jetons un œil à la manière dont les analyses de l'état du DevOps dans le monde ont été menées en général.
Référence historique
La recherche DevOps est menée depuis 2011. Le premier était détenu par Puppet, un développeur de systèmes de gestion de configuration. À l'époque, c'était l'un des principaux outils de description des infrastructures sous forme de code. Jusqu'en 2013, ces études se présentaient simplement sous la forme d'enquêtes fermées et sans rapports publics.
En 2013, IT Revolution est né, l'éditeur de tous les grands livres DevOps. Avec Puppet, ils ont préparé la première publication "State of DevOps", où 4 métriques clés sont apparues pour la première fois. L'année suivante, ThoughtWorks, une société de conseil connue pour ses radars technologiques réguliers sur les pratiques et les outils de l'industrie, s'est jointe à lui. Et en 2015, une section méthodologie a été ajoutée, et il est devenu clair comment ils effectuent l'analyse.
En 2016, les auteurs de l'étude, ayant créé leur société DORA (DevOps Research and Assessment), ont publié un rapport annuel. L'année suivante, DORA et Puppet ont publié pour la dernière fois un rapport conjoint.
Et puis l'intéressant a commencé:

En 2018, les entreprises se sont séparées et deux rapports indépendants ont été publiés: l'un de Puppet, l'autre de DORA en collaboration avec Google. DORA a continué à utiliser sa méthodologie avec des indicateurs clés, des profils de performance et des pratiques d'ingénierie qui ont un impact sur les indicateurs clés et les performances de l'entreprise. Et Puppet a proposé sa propre approche décrivant le processus et l'évolution de DevOps. Mais l'histoire n'a pas fait son chemin, en 2019, Puppet a abandonné cette méthodologie et a publié une nouvelle version des rapports, dans laquelle elle répertoriait les pratiques clés et comment elles affectaient DevOps de leur point de vue. Puis une autre chose s'est produite: Google a acheté DORA, et ensemble, ils ont publié un autre rapport. Vous l'avez peut-être vu.
Les choses se sont compliquées cette année. Puppet est connu pour avoir lancé son propre sondage. Ils l'ont fait une semaine plus tôt que nous, et c'est déjà terminé. Nous y avons participé et avons vu les sujets qui les intéressent. Puppet effectue actuellement son analyse et se prépare à publier le rapport.
Mais il n'y a toujours pas d'annonce de DORA et de Google. En mai, lorsque l'enquête a généralement commencé, des informations sont arrivées selon lesquelles Nicole Forsgren, l'une des fondatrices de DORA, avait déménagé dans une autre entreprise. Par conséquent, nous avons supposé qu'il n'y aurait pas de recherche ni de rapport de DORA cette année.
Comment ça va en Russie?
Nous n'avons effectué aucune recherche DevOps. Nous avons pris la parole lors de conférences, racontant les conclusions d'autres personnes et la Raiffeisenbank a traduit "State of DevOps" pour 2019 (vous pouvez trouver leur annonce sur Habré), merci beaucoup à eux. Et c'est tout.
Par conséquent, nous avons mené nos propres recherches en Russie en utilisant les méthodologies et les résultats de DORA. Nous avons utilisé le rapport de collègues de la Raiffeisenbank pour nos recherches, y compris pour la synchronisation de la terminologie et de la traduction. Et les questions spécifiques à l'industrie proviennent des rapports DORA et de l'enquête Puppet de cette année.
Processus de recherche
Le rapport n'est que la dernière partie. L'ensemble du processus de recherche se compose de quatre grandes étapes:
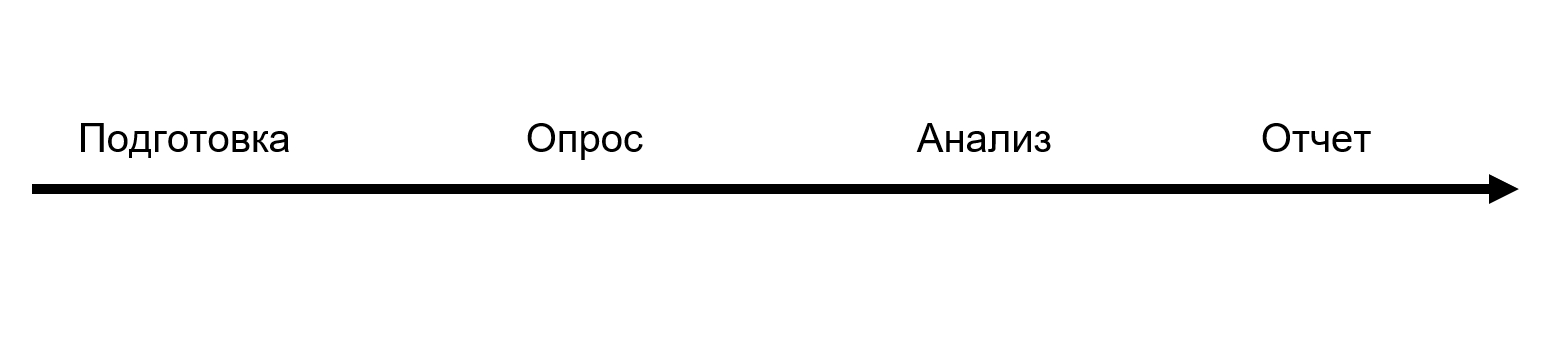
Au cours de la phase de préparation, nous avons interrogé des experts de l'industrie et préparé une liste d'hypothèses. Sur leur base, des questions ont été élaborées et une enquête a été lancée pour tout le mois d'août. Ensuite, nous avons analysé et préparé le rapport lui-même. Pour DORA, ce processus prend 6 mois. Nous nous sommes rencontrés 3 mois, et maintenant nous comprenons que nous avions à peine assez de temps: ce n'est qu'en effectuant l'analyse que vous comprenez quelles questions doivent être posées.
Les participants
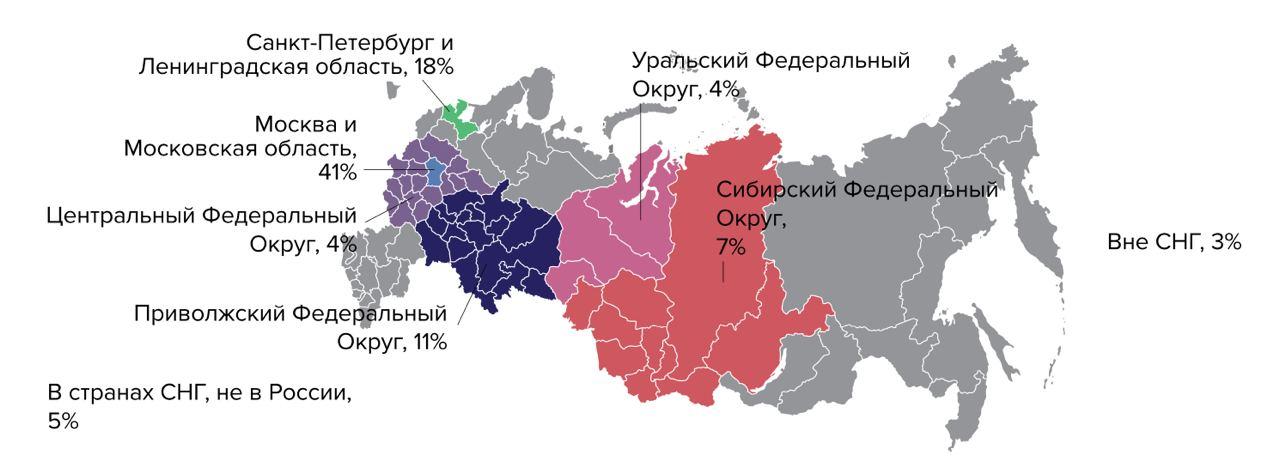
Tous les rapports étrangers commencent par un portrait des participants, et la plupart d'entre eux ne sont pas de Russie. Le pourcentage de répondants russes oscille entre 5 et 1% d'année en année, ce qui ne permet pas de tirer des conclusions.
Carte du rapport Accelerate State of DevOps 2019:

Dans notre étude, nous avons réussi à interroger 889 personnes - c'est beaucoup (DORA interroge environ un millier de personnes dans ses rapports chaque année) et ici nous avons atteint l'objectif:
Certes, tous nos participants n'ont pas atteint la fin: pourcentage le remplissage s'est avéré être légèrement inférieur à la moitié. Mais même cela était suffisant pour obtenir un échantillon représentatif et effectuer une analyse. DORA ne divulgue pas le pourcentage de remplissage dans ses rapports, il ne peut donc pas être comparé ici.
Industries et postes
Nos répondants représentent une dizaine d'industries. La moitié d'entre eux travaillent dans les technologies de l'information. Viennent ensuite les services financiers, le commerce, les télécommunications et autres. Parmi les postes se trouvent des spécialistes (développeur, testeur, ingénieur d'exploitation) et une équipe de direction (chefs d'équipes, groupes, directions, directeurs):

chaque seconde travaille dans une entreprise de taille moyenne. Une personne sur trois travaille dans de grandes entreprises. La plupart travaillent en équipe de 9 personnes maximum. Séparément, nous avons posé des questions sur les principales activités, et la plupart sont d'une manière ou d'une autre liées à l'opération, et environ 40% sont engagés dans le développement:

c'est ainsi que nous avons collecté des informations pour comparer et analyser des représentants de différentes industries, entreprises, équipes. Mon collègue Vitaly Khabarov vous parlera de l'analyse.
Analyse et comparaison
Vitaly Khabarov: Un grand merci à tous les participants qui ont rempli notre enquête, rempli les questionnaires et nous ont donné des données pour une analyse plus approfondie et pour tester nos hypothèses. Et grâce à nos clients et clients, nous avons une riche expérience qui nous a permis d'identifier les sujets de préoccupation de l'industrie et de formuler les hypothèses que nous avons testées dans nos recherches.
Malheureusement, vous ne pouvez pas simplement prendre une liste de questions d'une part et des données de l'autre, les comparer d'une manière ou d'une autre, dire: «Oui, c'est comme ça que ça marche, nous avions raison» et disperser. Non, nous avons besoin de méthodologie et de méthodes statistiques pour être sûrs que nous ne nous trompons pas et que nos conclusions sont fiables. Ensuite, nous pouvons construire notre travail ultérieur sur la base de ces données:

Indicateurs clés
Nous avons pris comme base la méthodologie DORA, qu'ils ont décrite en détail dans le livre "Accelerate State of DevOps". Nous avons vérifié si les indicateurs clés sont adaptés au marché russe, peuvent-ils être utilisés de la même manière que DORA utilise pour répondre à la question: "Comment l'industrie en Russie correspond-elle à l'industrie étrangère?"
Indicateurs clés:
- Fréquence de déploiement. À quelle fréquence une nouvelle version d'une application est-elle déployée dans l'environnement de production (modifications planifiées, à l'exclusion des correctifs et de la réponse aux incidents)?
- Heure de livraison. Quel est le délai moyen entre la validation d'une modification (écriture de la fonctionnalité sous forme de code) et le déploiement de la modification dans l'environnement du produit?
- . , , ?
- . ( , )?
DORA a trouvé une relation entre ces paramètres et la performance organisationnelle dans ses recherches. Nous le vérifions également dans notre étude.
Mais pour vous assurer que les quatre indicateurs clés peuvent influencer quelque chose, vous devez comprendre - sont-ils en quelque sorte liés les uns aux autres? DORA a répondu par l'affirmative avec une mise en garde: la relation entre le taux d'échec du changement et les trois autres paramètres est légèrement plus faible. Nous avons à peu près la même image. Si le délai de livraison, la fréquence de déploiement et le temps de récupération sont corrélés (nous avons trouvé cette corrélation par le biais de la corrélation de Pearson et de l'échelle de Chaddock), alors il n'y a pas de corrélation aussi forte avec des changements infructueux.
En principe, la plupart des répondants ont tendance à répondre qu'ils ont un assez petit nombre d'incidents survenus en production. Bien qu'à l'avenir, nous verrons qu'il existe encore une différence significative entre les groupes de répondants en termes de taux de changements infructueux, pour cette division, nous ne pouvons pas encore utiliser cette métrique.
Nous attribuons cela au fait que (comme il s'est avéré lors de l'analyse et de la communication avec certains de nos clients) il y a une légère différence dans la perception de ce qui est considéré comme un incident. Si nous avons réussi à restaurer la fonctionnalité de notre service pendant la fenêtre technique, cela peut-il être considéré comme un incident? Probablement pas, car nous avons tout réglé, nous sommes super. Cela peut-il être considéré comme un incident si nous devions redéployer notre application 10 fois dans un mode normal et habituel pour nous? Il semble que non. Par conséquent, la question de la relation entre les modifications infructueuses et d'autres mesures reste ouverte. Nous l'affinerons à l'avenir.
Il est important ici que nous ayons trouvé une corrélation significative entre les délais de livraison, les temps de récupération et la fréquence de déploiement. Par conséquent, nous avons utilisé ces trois mesures pour diviser davantage les répondants en groupes de performance.
Combien peser en grammes?
Nous avons utilisé une analyse de cluster hiérarchique:
- Nous distribuons les répondants dans un espace à n dimensions, où la coordonnée de chaque répondant correspond à leurs réponses aux questions.
- Nous déclarons chaque répondant comme un petit groupe.
- Nous combinons les deux clusters les plus proches l'un de l'autre en un cluster plus grand.
- Trouvez la prochaine paire de clusters et combinez-les en un cluster plus grand.
C'est ainsi que nous regroupons tous nos répondants dans le nombre requis de grappes. À l'aide d'un dendrogramme (un arbre de connexions entre clusters), nous voyons la distance entre deux clusters voisins. Il ne nous reste plus qu'à fixer une certaine distance entre ces clusters et à dire: "Ces deux groupes se distinguent assez bien car la distance entre eux est énorme".
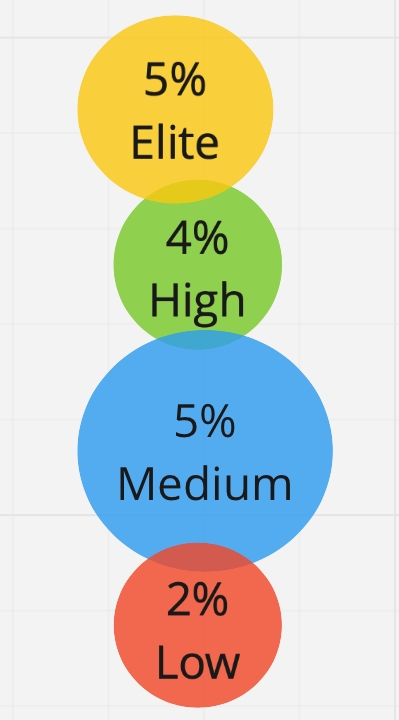
Mais il y a un problème caché ici: nous n'avons aucune restriction sur le nombre de clusters - nous pouvons obtenir 2, 3, 4, 10 clusters. Et la première idée était - pourquoi ne pas diviser tous nos répondants en 4 groupes, comme le fait DORA. Mais nous avons découvert que les différences entre ces groupes deviennent insignifiantes, et nous ne pouvons pas être sûrs que le répondant appartient réellement à son propre groupe, et non au groupe voisin. Nous ne pouvons toujours pas diviser le marché russe en quatre groupes. Par conséquent, nous nous sommes arrêtés à exactement trois profils, entre lesquels il existe une différence statistiquement significative:

Ensuite, nous avons déterminé le profil par clusters: nous avons pris les médianes pour chaque métrique pour chaque groupe et avons fait un tableau des profils de performance. En fait, nous avons obtenu les profils de performance du participant moyen de chaque groupe. Nous avons identifié trois profils d'efficacité: faible, moyen, élevé:

Ici, nous avons confirmé notre hypothèse selon laquelle les 4 indicateurs clés sont adaptés pour déterminer le profil de performance, et ils fonctionnent à la fois sur les marchés occidentaux et russes. Il y a une différence entre les groupes et elle est statistiquement significative. Je tiens à souligner qu'il existe une différence significative dans la moyenne entre les profils de performance selon la métrique des changements infructueux, même si nous n'avons pas initialement divisé les répondants par ce paramètre.
Alors la question se pose: comment utiliser tout cela?
Comment utiliser
Si vous prenez n'importe quelle équipe, 4 métriques clés et postulez à la table, alors dans 85% des cas, nous n'obtiendrons pas une correspondance complète - il ne s'agit que d'un participant moyen, et non de ce qui est en réalité. Nous sommes tous (et chaque équipe) un peu différents.
Nous avons vérifié: nous avons pris nos répondants et le profil de performance DORA, et nous avons regardé combien de répondants correspondaient à un profil particulier. Nous avons constaté que seulement 16% des répondants atteignaient avec précision l'un des profils. Tous les autres sont dispersés quelque part entre les deux:
Cela signifie que le profil de performance a une portée limitée. Pour comprendre où vous en êtes en première approximation, vous pouvez utiliser ce tableau: "Oh, il semble que nous soyons plus proches de Moyen ou Haut!" Si vous savez où aller ensuite, cela peut suffire. Mais si votre objectif est l'amélioration constante et continue, et que vous voulez savoir plus précisément où développer et quoi faire, alors vous avez besoin de fonds supplémentaires. Nous les avons appelés calculatrices:
- Calculatrice DORA
- Calculatrice Express 42 * (en développement)
- Développement personnel (vous pouvez créer votre propre calculatrice interne).
À quoi servent-ils? Comprendre:
- L'équipe au sein de notre organisation répond-elle à nos normes?
- Sinon, pouvons-nous l'aider - l'accélérer dans le cadre de l'expertise de notre entreprise?
- Si oui, pouvons-nous faire encore mieux?
Vous pouvez également les utiliser pour collecter des statistiques au sein de l'entreprise:
- Quelles équipes avons-nous;
- Divisez les équipes en profils;
- Voir: Oh, ces équipes sont sous-performantes (elles ne tirent pas un peu), et ce sont cool: elles se déploient tous les jours, sans erreur, elles ont moins d'une heure de délai.
Et puis vous pouvez découvrir qu'au sein de notre entreprise, il existe l'expertise et les outils nécessaires pour les équipes qui ne tiennent toujours pas.
Ou, si vous comprenez qu'au sein de l'entreprise, vous vous sentez bien, que vous êtes meilleur que beaucoup, alors vous pouvez jeter un regard plus large. Il ne s'agit que de l'industrie russe: pouvons-nous acquérir l'expertise nécessaire dans l'industrie russe pour nous accélérer? Calculator Express 42 vous aidera ici (il est en cours de développement). Si vous avez dépassé le marché russe, regardez le calculateur DORA et le marché mondial.
D'accord. Et si vous êtes dans le groupe Elit calculatrice DORA, que faire? Il n'y a pas de bonne solution ici. Vous êtes très probablement à la pointe de l'industrie, et une accélération et une amélioration de la fiabilité supplémentaires sont possibles grâce à la R&D interne et à la dépense de plus de ressources.
Passons à la comparaison la plus douce.
Comparaison
Nous voulions initialement comparer l'industrie russe avec l'industrie occidentale. Si nous comparons directement, nous voyons que nous avons moins de profils, et qu'ils sont un peu plus mélangés les uns aux autres, les frontières sont un peu plus floues:

nos Elite Performers sont cachés parmi les High Performers, mais ils existent - ce sont l'élite, les licornes qui ont atteint des hauteurs significatives. En Russie, la différence entre le profil Elite et le profil High n'est pas encore assez significative. Nous pensons qu'à l'avenir cette séparation aura lieu en lien avec l'amélioration de la culture de l'ingénierie, la qualité de la mise en œuvre des pratiques d'ingénierie et l'expertise au sein des entreprises.
Si nous passons à une comparaison directe au sein de l'industrie russe, nous voyons que les équipes de haut niveau sont meilleures à tous égards. Nous avons également confirmé notre hypothèse selon laquelle il existe une relation entre ces métriques et la performance organisationnelle: les équipes de haut niveau sont beaucoup plus susceptibles non seulement d'atteindre les objectifs, mais aussi de les dépasser.
Devenons des équipes de haut niveau et ne nous arrêtons pas là:
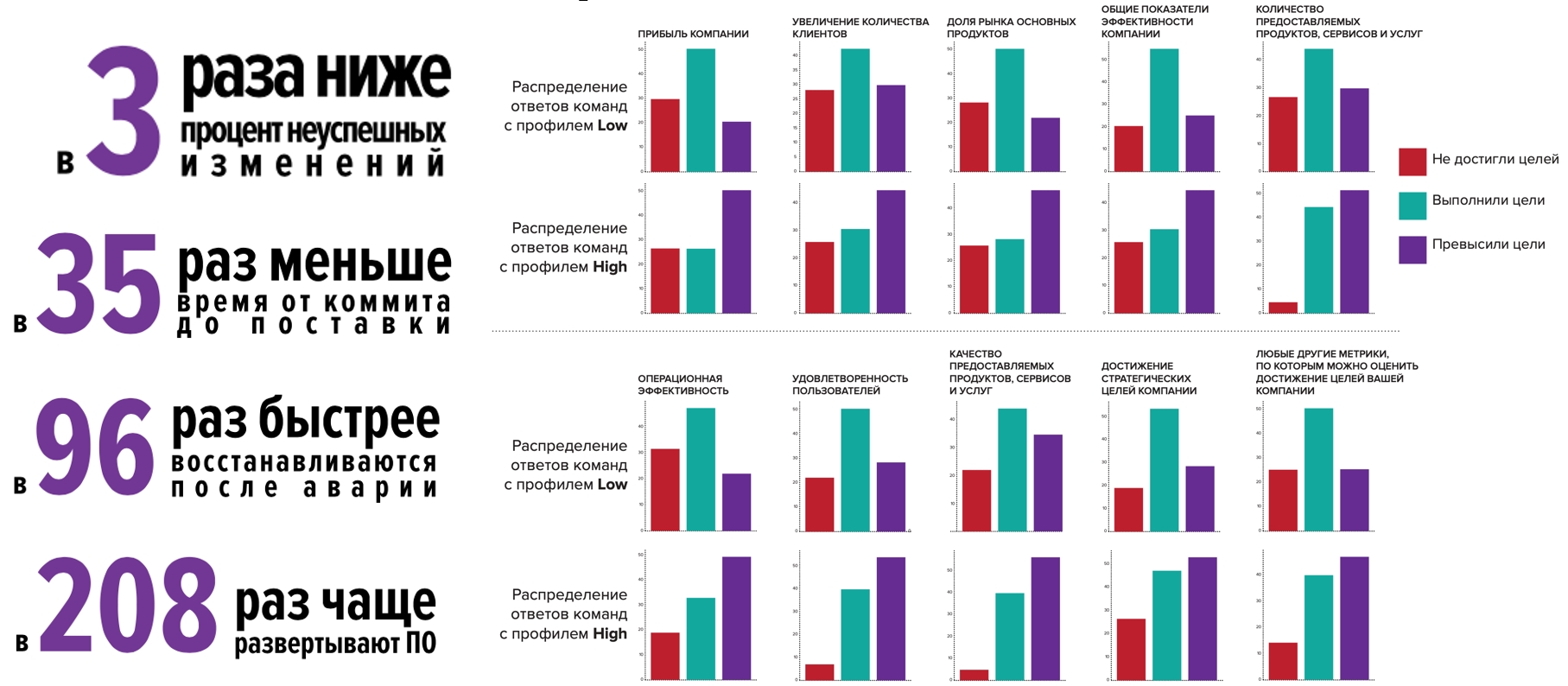
Mais cette année est spéciale, et nous avons décidé de vérifier comment les entreprises vivent dans une pandémie: les équipes de haut niveau font beaucoup mieux et se sentent mieux que la moyenne du secteur:
- Les nouveaux produits sont sortis 1,5 à 2 fois plus souvent
- 2 fois plus susceptibles d'améliorer la fiabilité et / ou les performances de l'infrastructure d'application.
Autrement dit, les compétences qu'ils avaient déjà les ont aidés à se développer plus rapidement, à introduire de nouveaux produits, à modifier les produits existants, conquérant ainsi de nouveaux marchés et de nouveaux utilisateurs:

qu'est-ce qui a aidé nos équipes?
Pratiques d'ingénierie

Je vais vous parler des résultats significatifs de chaque pratique que nous avons vérifiée. Peut-être que quelque chose d'autre a aidé les équipes, mais nous parlons de DevOps. Et au sein de DevOps, nous constatons une différence entre les équipes de différents profils.
Plateforme en tant que service
Nous n'avons trouvé aucun lien significatif entre l'âge de la plate-forme et le profil de l'équipe: les plates-formes sont apparues à peu près au même moment pour les équipes Low et High. Mais pour ces derniers, la plateforme fournit, en moyenne, plus de services et plus d'interfaces de programmation pour le contrôle via le code programme. Et les équipes de plateforme sont plus susceptibles d'aider leurs développeurs et équipes à utiliser la plateforme, plus souvent pour résoudre leurs problèmes et incidents liés à la plateforme, et pour former d'autres équipes.

Infrastructure en tant que code
Tout est assez standard ici. Nous avons trouvé une relation entre l'automatisation du code d'infrastructure et la quantité d'informations stockées dans le référentiel d'infrastructure. Les commandes High profile stockent plus d'informations dans les référentiels: il s'agit de la configuration de l'infrastructure, du pipeline CI / CD, des paramètres d'environnement et des paramètres de construction. Ils stockent ces informations plus souvent, fonctionnent mieux avec le code d'infrastructure et ont automatisé davantage de processus et de tâches pour travailler avec le code d'infrastructure.
Fait intéressant, nous n'avons constaté aucune différence significative dans les tests d'infrastructure. J'associe cela au fait que les commandes High profile ont généralement plus d'automatisation des tests. Peut-être qu'ils ne devraient pas être distraits séparément par les tests d'infrastructure, mais les tests qu'ils utilisent pour vérifier les applications sont suffisants, et grâce à eux, ils peuvent déjà voir quoi et où ils ont échoué.
Intégration et livraison
La section la plus ennuyeuse, car nous avons confirmé que plus vous avez d'automatisation, mieux vous travaillez avec le code, plus vous obtiendrez les meilleures métriques.
Architecture
Nous voulions voir comment les microservices affectent les performances. Si en réalité, ils ne le font pas, car l'utilisation de microservices n'est pas associée à une augmentation des indicateurs de performance. Les microservices sont utilisés à la fois par les commandes de profil haut et par les commandes de profil bas.
Mais ce qui est important, c'est que pour les équipes de haut niveau, la transition vers une architecture de microservices leur permet de développer et de déployer leurs services de manière indépendante. Si l'architecture permet aux développeurs d'agir de manière autonome, de ne pas attendre quelqu'un d'extérieur à l'équipe, alors c'est une compétence clé pour augmenter la vitesse. C'est là que les microservices aident. Et juste leur mise en œuvre ne joue pas un grand rôle.
Comment avons-nous trouvé tout cela?
Nous avions un plan ambitieux pour reproduire pleinement la méthodologie DORA, mais nous manquions de ressources. Si DORA utilise beaucoup de parrainage et que la recherche leur prend six mois, nous avons fait nos recherches en peu de temps. Nous voulions créer un modèle DevOps comme le fait DORA, et nous le ferons à l'avenir. Jusqu'à présent, nous nous sommes limités aux cartes thermiques:

nous avons examiné la répartition des pratiques d'ingénierie entre les équipes de chaque profil et avons constaté que les équipes de profil élevé, en moyenne, sont plus susceptibles d'utiliser des pratiques d'ingénierie. Vous pouvez en savoir plus sur tout cela dans notre rapport .
Pour un changement, passons des statistiques complexes aux statistiques simples.
Qu'avons-nous trouvé d'autre?
Outils
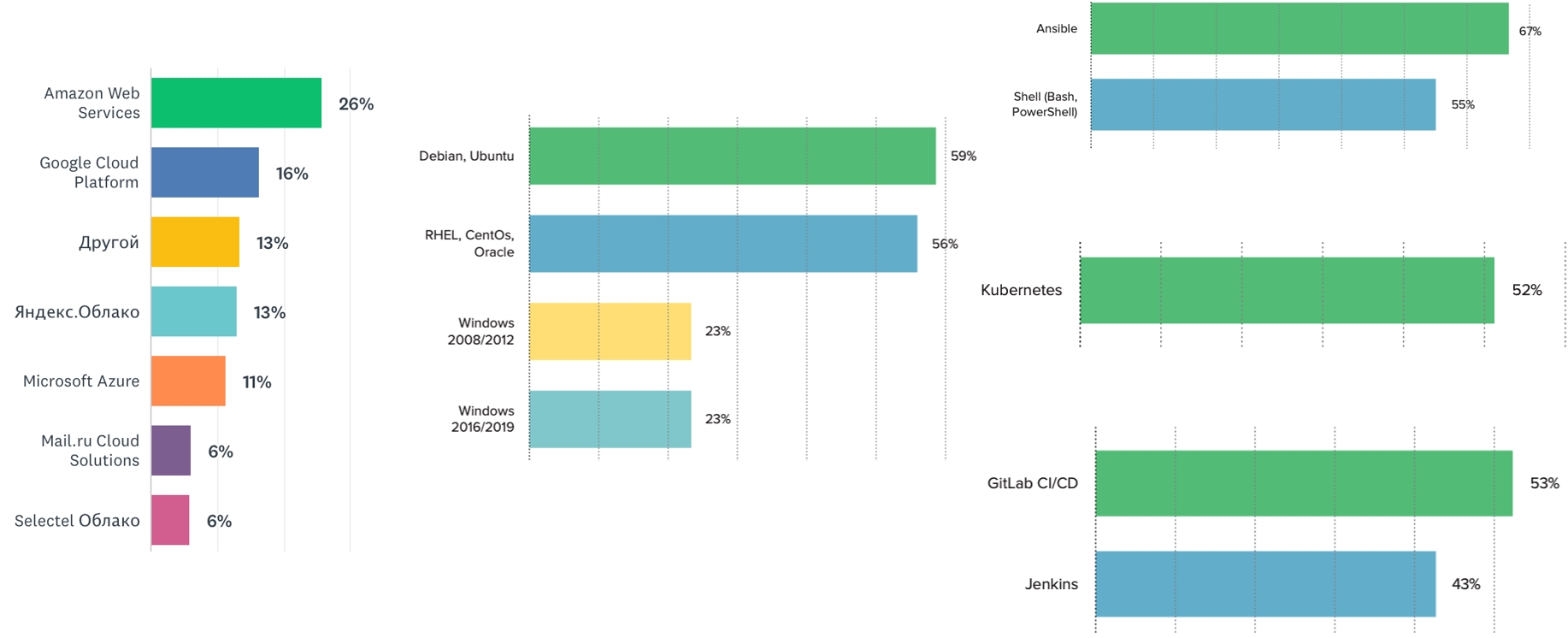
On observe que la plupart des équipes utilisent le système d'exploitation Linux. Mais Windows est toujours à la mode - au moins un quart de nos répondants ont indiqué utiliser l'une ou l'autre version de celui-ci. Le marché semble avoir ce besoin. Par conséquent, vous pouvez développer ces compétences et faire des présentations lors de conférences.
Kubernetes est le leader parmi les orchestrateurs (52%). Le prochain orchestrateur en ligne est Docker Swarm (environ 12%). Les systèmes CI les plus populaires sont Jenkins et GitLab. Le système de gestion de configuration le plus populaire est Ansible, suivi de notre bien-aimé Shell.
Parmi l'hébergement cloud, Amazon est toujours en tête. La part des nuages russes augmente progressivement. L'année prochaine, il sera intéressant de voir comment les fournisseurs de cloud computing russes se sentiront, si leur part de marché augmentera. Ils le sont, vous pouvez les utiliser, et c'est bien:
je donne la parole à Igor, qui vous donnera quelques statistiques supplémentaires.
Diffusion des pratiques
Igor Kurochkin: Par ailleurs, nous avons demandé aux répondants d'indiquer comment les pratiques d'ingénierie envisagées sont diffusées dans l'entreprise. La plupart des entreprises ont une approche mixte avec un ensemble différent de modèles, et les projets pilotes sont très populaires. Nous avons également constaté une légère différence entre les profils. Les représentants du haut profil utilisent plus souvent le modèle «Initiative par le bas», lorsque de petites équipes de spécialistes changent les processus de travail, les outils et partagent les développements réussis avec d'autres équipes. Chez Medium, il s'agit d'une initiative descendante qui affecte toute l'entreprise en créant des communautés et des centres d'excellence:

Agile et DevOps
La relation entre Agile et DevOps est un sujet brûlant dans l'industrie. Cette question est également soulevée dans le rapport sur l'état de l'Agile pour 2019/2020, nous avons donc décidé de comparer les relations entre les activités Agile et DevOps dans les entreprises. Nous avons constaté que le DevOps non Agile est rare. Pour la moitié des répondants, la diffusion de l'Agile a commencé beaucoup plus tôt, et environ 20% ont observé un démarrage simultané, et l'un des signes d'un profil bas sera l'absence de pratiques Agile et DevOps:

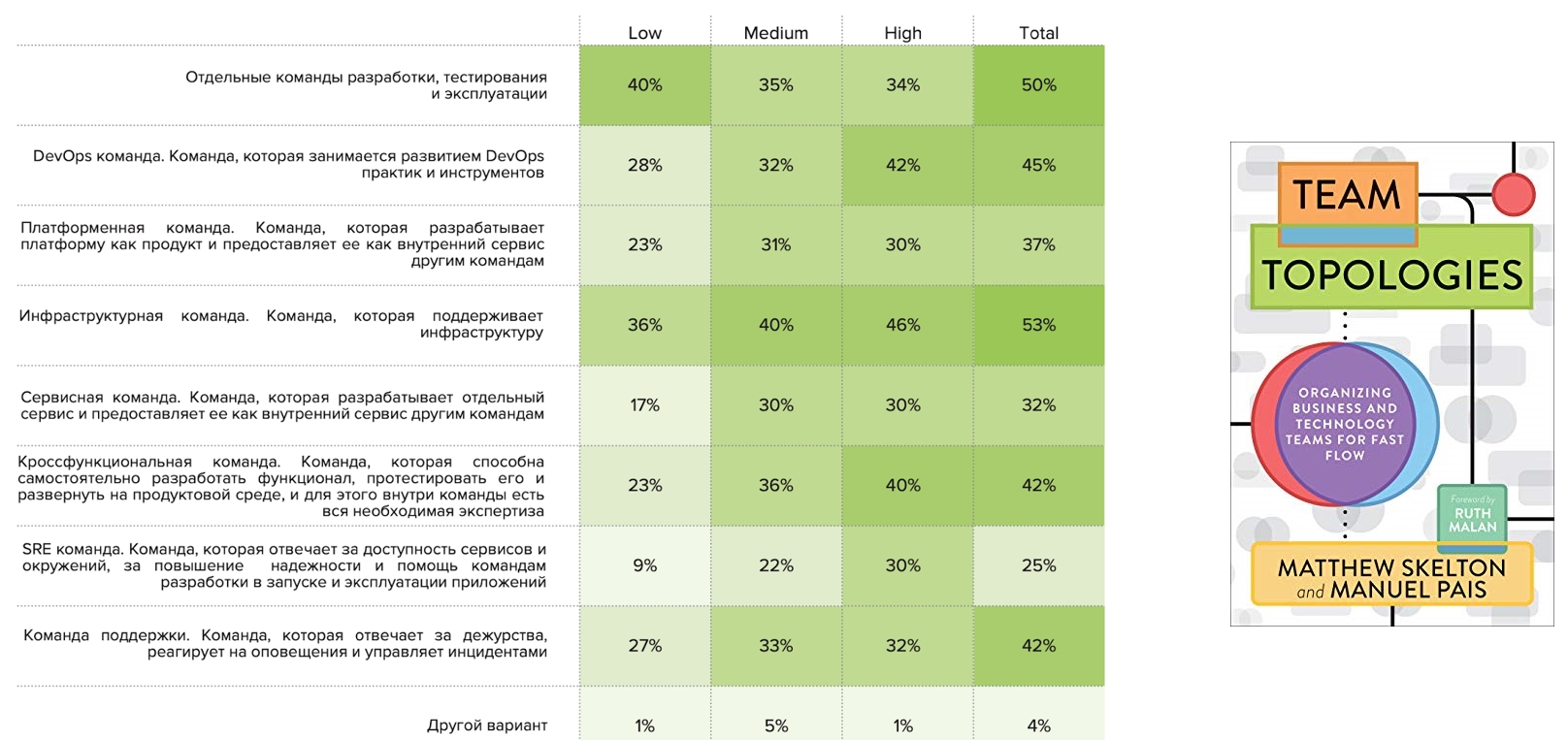
Topologies de commande
À la fin de l'année dernière, le livre « Topologies d'équipe » a été publié, qui proposait un cadre pour décrire les topologies d'équipe. Nous nous sommes demandé si cela s'appliquait aux entreprises russes. Et nous avons posé la question: "Quels modèles trouvez-vous?"
Les équipes d'infrastructure sont observées par la moitié des répondants, ainsi que par des équipes de développement, de test et d'exploitation distinctes. Les équipes DevOps individuelles ont été notées par 45%, parmi lesquelles les hauts représentants sont plus courants. Viennent ensuite les équipes interfonctionnelles, qui sont également plus courantes pour High. Des commandes SRE distinctes apparaissent dans les profils Haut, Moyen et apparaissent rarement dans le profil Bas:
Ratio DevQaOps
Nous avons vu cette question dans FaceBook du chef d'équipe de la plateforme Skyeng - il était intéressé par le ratio de développeurs, de testeurs et d'administrateurs dans les entreprises. Nous l'avons posé et regardé les réponses en fonction des profils: les représentants du Haut profil ont moins d'ingénieurs de test et d'exploitation par développeur:
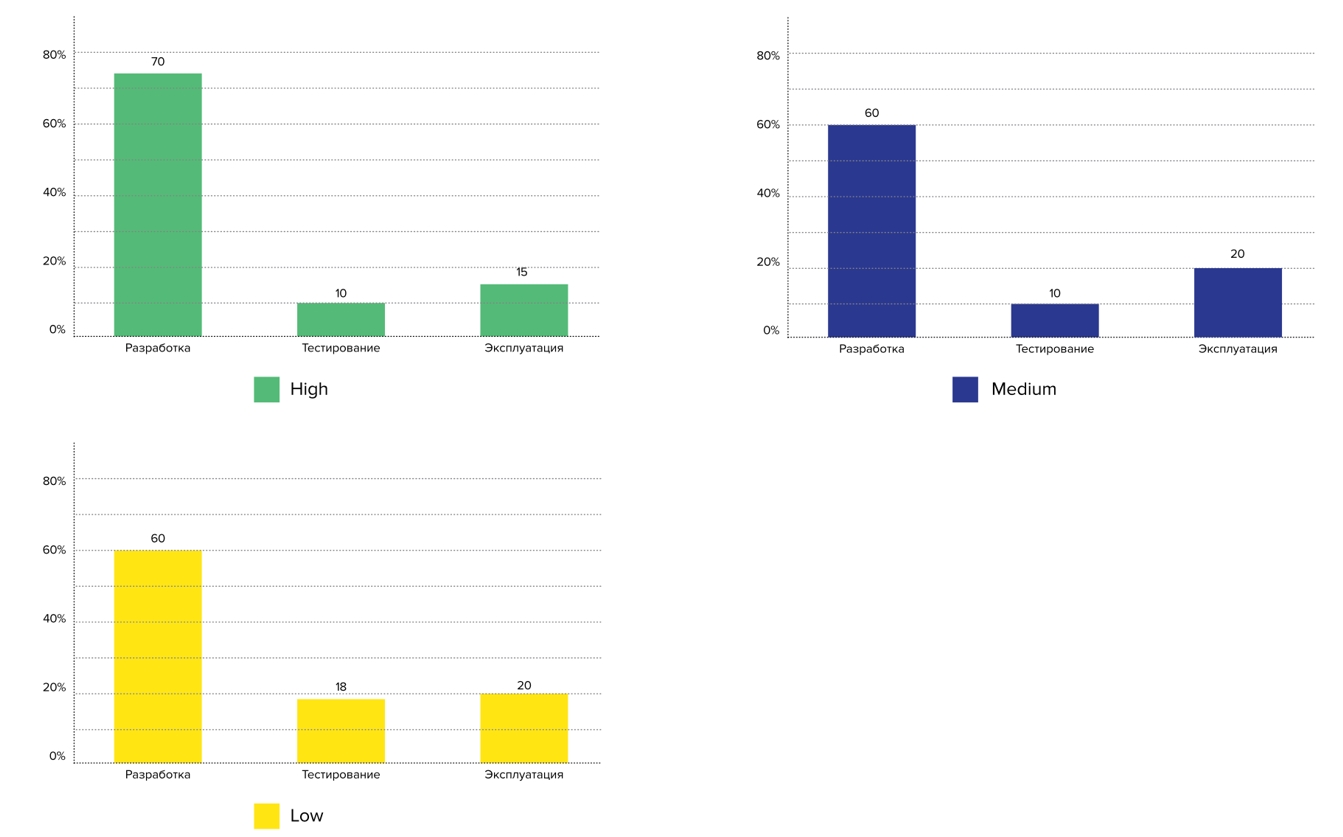
Plans pour 2021
Dans leurs plans pour l'année prochaine, les répondants ont noté les activités suivantes:

Ici, vous pouvez voir l'intersection avec la conférence DevOps Live 2020. Nous avons soigneusement examiné le programme:
- Infrastructure en tant que produit
- Transformation DevOps
- Diffusion des pratiques DevOps
- DevSecOps
- Clubs de cas et discussions
Mais notre discours ne sera pas assez de temps pour examiner tous les sujets. Laissé dans les coulisses:
- Plateforme en tant que service et en tant que produit;
- Infrastructure en tant que code, environnements et nuages;
- Intégration et livraison continues;
- Architecture;
- Modèles DevSecOps;
- Plateforme et équipes transverses.
Notre rapport s'est avéré volumineux, sur 50 pages, et vous pouvez le voir plus en détail.
Résumer
Nous espérons que nos recherches et notre rapport vous inspireront à expérimenter de nouvelles approches de développement, de test et d'exploitation, ainsi que de vous aider à naviguer, à vous comparer avec d'autres participants à la recherche et à identifier les domaines dans lesquels vous pouvez améliorer vos propres approches.
Résultats de la première enquête sur l'état du DevOps en Russie:
- Indicateurs clés. Nous avons constaté que les mesures clés (délai de livraison, fréquence de déploiement, temps de récupération et modifications infructueuses) sont appropriées pour analyser l'efficacité du développement, des tests et des opérations.
- High, Medium, Low. High, Medium, Low , , . High , Low. .
- , 2021 . , . High , , .
- Pratiques, outils DevOps et leur développement. Les principaux plans des entreprises pour l'année prochaine incluent le développement de pratiques et d'outils DevOps, l'introduction de pratiques DevSecOps et un changement dans la structure organisationnelle. Et la mise en œuvre et le développement efficaces des pratiques DevOps se font à l'aide de projets pilotes, de la formation de communautés et de centres de compétences, d'initiatives aux niveaux supérieur et inférieur de l'entreprise.
Nous serons heureux d'entendre vos commentaires, histoires, commentaires. Merci à tous ceux qui ont participé à l'étude et nous attendons avec impatience votre participation l'année prochaine.