
Cet article concerne l'outil de découverte de données le plus simple et le plus rapide que vous voyez fonctionner sur KDPV. Fait intéressant, whale est conçu pour être hébergé sur un serveur git distant. Détails sous la coupe.
Comment l'outil de découverte de données d'Airbnb a changé ma vie
Au cours de ma carrière, j'ai eu la chance de travailler sur des problèmes amusants: j'ai étudié les mathématiques des flux pendant mon diplôme au MIT, travaillé sur des modèles incrémentaux et le projet open source pylift chez Wayfair, et introduit de nouveaux modèles de ciblage de page d'accueil et des améliorations CUPED à Airbnb. Mais tout ce travail n'a jamais été glamour - en fait, j'ai souvent passé la plupart de mon temps à rechercher, explorer et valider des données. Bien que ce soit une condition persistante au travail, il ne m'est pas venu à l'esprit que c'était un problème jusqu'à ce que j'arrive à Airbnb, où il a été résolu avec l'outil de découverte de données Dataportal .
Où puis-je trouver {{data}}? Dataportal .
Que signifie cette colonne? Dataportal .
Comment va {{metric}} aujourd'hui? Dataportal .
Qu'est-ce qu'un sens de la vie? Dans Dataportal , probablement.
D'accord, vous avez présenté une photo. Trouver des données et comprendre ce qu'elles signifient, comment elles ont été créées et comment les utiliser - tout cela ne prend que quelques minutes, pas des heures. Je pourrais passer mon temps à tirer des conclusions simples ou de nouveaux algorithmes (... ou à répondre à des questions aléatoires sur les données), plutôt que de fouiller dans des notes, d'écrire des requêtes SQL répétitives et de mentionner des collègues de Slack pour essayer de recréer le contexte. que quelqu'un d'autre avait déjà.
Quel est le problème?
J'ai réalisé que la plupart de mes amis n'avaient pas accès à un tel outil. Peu d'entreprises sont disposées à consacrer d'énormes ressources à la création et à la maintenance d'un outil de plate-forme comme Dataportal. Bien qu'il existe plusieurs solutions open source disponibles, elles sont généralement conçues pour évoluer, ce qui rend difficile la configuration et la maintenance sans un ingénieur DevOps dédié. J'ai donc décidé de créer quelque chose de nouveau.
Whale: un outil de découverte de données idiot

Et oui, par simple à stupidité, je veux dire simple à stupidité. Whale n'a que deux composants:
- Une bibliothèque Python qui collecte les métadonnées et les met en forme dans MarkDown.
- Interface de ligne de commande Rust pour rechercher ces données.
Du point de vue de l'infrastructure interne, il n'y a que beaucoup de fichiers texte et un programme de mise à jour de texte pour la maintenance. Voilà, donc l'hébergement sur un serveur git comme Github est trivial. Pas de nouveau langage de requête à apprendre, pas d'infrastructure de gestion, pas de sauvegardes. Git est connu de tous, donc la synchronisation et la collaboration sont gratuites. Examinons de plus près les fonctionnalités de Whale v1.0 .
Interface graphique git complète
Whale est conçu pour naviguer dans l'océan d'un serveur git distant. Il est très personnalisable: définissez certaines connexions, copiez le script Github Actions (ou écrivez-le pour la plate-forme CI / CD de votre choix) et vous disposez immédiatement d'un outil de découverte de données Web. Vous pourrez rechercher, visualiser, documenter et partager vos tableaux directement sur Github.
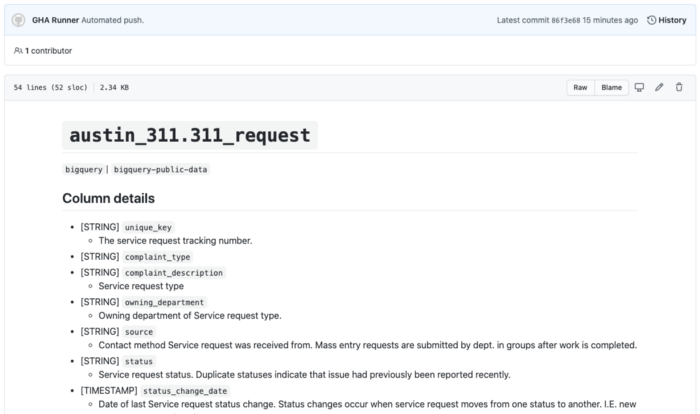
Un exemple de table de stub générée à l'aide d'actions Github. Consultez cette section pour une démonstration de fonctionnement complète .
Recherche CLI ultra rapide pour votre référentiel
Whale vit et respire sur la ligne de commande, fournissant des recherches puissantes en millisecondes sur vos tables. Même avec des millions de tables, nous avons réussi à rendre whale incroyablement performant en utilisant des mécanismes de mise en cache intelligents et en reconstruisant le backend dans Rust. Vous ne remarquerez aucun retard de recherche [bonjour Google DS].
Démo baleine, recherchez plus d'un million de tables .
Calcul automatique des statistiques [en version bêta]
L'une de mes choses les moins préférées en tant que data scientist est d'exécuter les mêmes requêtes encore et encore, juste pour vérifier la qualité des données utilisées. Whale prend en charge la possibilité de définir des métriques en SQL brut qui s'exécuteront selon un calendrier avec vos pipelines de nettoyage de métadonnées. Définissez un bloc de métriques YAML dans la table de stub et Whale s'exécutera automatiquement selon la planification et exécutera des requêtes de métriques imbriquées.
```metrics
metric-name:
sql: |
select count(*) from table
```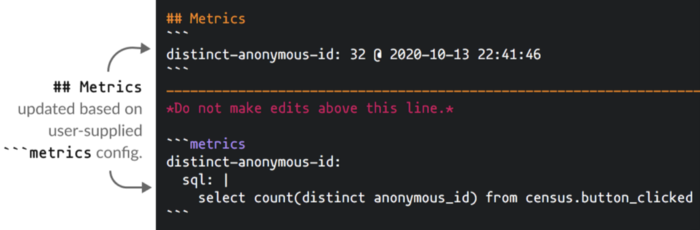
Lorsqu'elle est combinée avec Github, cette approche signifie que la baleine peut servir de source centrale simple de vérité pour les définitions métriques. Whale stocke même les valeurs avec l'horodatage dans le ~ /. whale / metrics "si vous voulez faire une sorte de graphique ou une recherche plus approfondie.
Futur
Après avoir discuté avec les utilisateurs de nos versions préliminaires de whale, nous avons réalisé que les gens avaient besoin de plus de fonctionnalités. Pourquoi un outil de recherche de table? Pourquoi pas un outil de recherche de métriques? Pourquoi ne pas surveiller? Pourquoi pas un outil d'exécution de requêtes SQL? Bien que whale v1 ait été conçu à l'origine comme un simple outil compagnon CLI
Dataportal/Amundsen, il a déjà évolué pour devenir une plate-forme autonome entièrement fonctionnelle et nous espérons qu'il fera partie intégrante de la boîte à outils du data scientist.
S'il y a quelque chose que vous voulez voir en développement, rejoignez notre communauté Slack , ouvrez Issues sur Github ou même contactez LinkedIn directement.... Nous avons déjà toute une série de fonctionnalités intéressantes - modèles Jinja, signets, filtres de recherche, alertes Slack, intégration Jupyter, même un panneau CLI pour les métriques - mais nous aimerions votre contribution.
Conclusion
Whale est développé et soutenu par Dataframe, une startup que j'ai récemment eu le plaisir de démarrer avec d'autres personnes. Alors que whale est destiné aux data scientists, Dataframe est destiné aux équipes data. Pour ceux d'entre vous qui souhaitent coopérer plus étroitement - n'hésitez pas à nous contacter , nous vous ajouterons à la liste d'attente.

Et avec le code promo HABR , vous pouvez obtenir un supplément de 10% sur la réduction indiquée sur le bandeau.
- Bootcamp en ligne pour la science des données
- Former le métier d'analyste de données à partir de zéro
- Bootcamp en ligne sur l'analyse des données
- Enseigner le métier de Data Science à partir de zéro
- «Python -»
E