
- Qu'est-ce qui consomme exactement autant de mémoire?
- y-a-t-il un moyen d'éviter ça?
Ici, je veux parler de la façon dont je cherchais des réponses à ces questions. Je prévois d'utiliser ce matériel comme référence chaque fois que j'ai besoin de profiler du code Python.
J'ai commencé à analyser Pylint, en commençant par le point d'entrée du programme (
pylint/__main__.py), et je suis arrivé à la boucle "fondamentale" à forlaquelle vous vous attendriez dans un programme qui vérifie de nombreux fichiers:
def _check_files(self, get_ast, file_descrs):
# pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
Pour commencer, je viens de mettre une instruction dans cette boucle
print(«HI»)pour m'assurer que c'est bien la boucle qui démarre lorsque j'exécute la commande pylint my_code. Cette expérience s'est déroulée sans heurts.
Ensuite, j'ai décidé de découvrir ce qui est exactement stocké en mémoire pendant le travail de Pylint. Je l'ai donc utilisé
heapypour faire un simple "heap dump", dans l'espoir d'analyser ce dump pour quelque chose d'inhabituel:
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
Le profil de tas s'est finalement composé presque entièrement de cadres de pile d'appels (
types.FrameType). Pour une raison quelconque, je m'attendais à quelque chose comme ça. Un tel nombre d'objets dans la décharge m'a fait penser qu'il semble y en avoir plus qu'il ne devrait y en avoir.
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
C'est à ce moment que j'ai trouvé l'outil Navigateur de profils , qui vous permet de travailler facilement avec ces données.
J'ai configuré le moteur de vidage pour que les données soient écrites dans un fichier toutes les 10 itérations de boucle. Ensuite, j'ai construit un diagramme montrant le comportement du programme pendant le fonctionnement.
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
J'ai fini avec ce qui est montré ci-dessous. Ce diagramme confirme que les objets
type.FrameTypeet type.TracebackType(informations de trace) ont consommé beaucoup de mémoire pendant l'exécution explorée de Pylint.

Analyse des données
La prochaine étape de l'étude était l'analyse des objets
types.FrameType. Étant donné que les mécanismes de gestion de la mémoire en Python sont basés sur le comptage du nombre de références aux objets, les données sont conservées en mémoire tant que quelque chose y fait référence. J'ai décidé de savoir ce qui "détient" exactement les données en mémoire.
Ici, j'ai utilisé une excellente bibliothèque
objgraphqui, en utilisant les capacités du gestionnaire de mémoire Python, donne des informations sur les objets en mémoire et vous permet de savoir ce qui fait exactement référence à ces objets.
En fait, c'est formidable que nous ayons la capacité de faire ce genre de recherche sur les logiciels. À savoir, s'il y a une référence à un objet, vous pouvez trouver tout ce qui fait référence à cet objet (dans le cas des extensions C, tout n'est pas si fluide, mais, en général,
objgraphdonne des informations raisonnablement exactes). Devant nous se trouve un excellent outil de débogage de code, donnant accès à de nombreuses informations sur les mécanismes internes de CPython. Pour moi, c'est une autre raison de penser à Python comme un langage agréable à utiliser.
Au début, je suis tombé sur la recherche d'objets, car l'équipe
objgraph.by_type('types.TracebackType')n'a rien trouvé du tout. Et cela malgré le fait que je savais qu'il existe un grand nombre de ces objets. Il s'est avéré qu'une chaîne devait être utilisée comme nom de type traceback. La raison de ceci n'est pas tout à fait claire pour moi, mais qu'est-ce que c'est? La commande correcte, à la fin, ressemble à ceci:
random.choice(objgraph.by_type('traceback'))
Cette construction sélectionne des objets au hasard
traceback. Et avec l'aide, objgraph.show_backrefsvous pouvez créer un diagramme de ce qui fait référence à ces objets.
En fin de compte, au lieu de simplement lancer une exception, j'ai décidé d'étudier ce qui se passe dans la boucle
for( import pdb; pdb.set_trace()) après 100 itérations. J'ai commencé à étudier des objets choisis au hasard traceback.
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
Au départ, je ne voyais que des chaînes d'objets
traceback, j'ai donc décidé de grimper à une profondeur de 100 objets ...

Analyse des objets de trace
Il s'avère que certains objets
tracebackfont référence à d'autres objets du même type. Eh bien, bien. Et il y avait beaucoup de telles chaînes.
Pendant un certain temps, sans grand succès pour l'entreprise, je les ai étudiés, puis je suis passé à l'étude des objets du deuxième type qui m'intéressaient -
FrameType(frame). Ils avaient également l'air suspect. En les analysant, je suis arrivé à des diagrammes qui ressemblent aux suivants.

Analyse des objets frame
Il s'avère que les objets
tracebackcontiennent des objetsframe(il y en a donc un nombre similaire). Tout cela, bien sûr, semble extrêmement déroutant, mais les objetsframepointent au moins vers des lignes de code spécifiques. Tout cela m'a conduit à réaliser une chose ridiculement simple: je n'ai jamais pris la peine de regarder des données en utilisant de si grandes quantités de mémoire. Je devrais certainement regarder les objets eux-mêmestraceback.
J'ai marché vers cet objectif, semble-t-il, le plus sinueux de tous les chemins possibles. À savoir, il a reconnu les adresses dans la décharge créée par
objgraph, puis a regardé les adresses en mémoire, puis a cherché sur Internet "comment obtenir un objet Python en connaissant son adresse". Après toutes ces expériences, j'ai proposé le schéma d'actions suivant:
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
En fait, vous pouvez simplement dire à Python: «Regardez cette mémoire. Il y a certainement au moins un objet Python normal ici. "
Plus tard, j'ai réalisé que j'avais déjà des liens vers des objets qui m'intéressaient grâce à
objgraph. C'est - je pourrais simplement les utiliser.
C'était comme si la bibliothèque
astroid, l'analyseur AST utilisé dans Pylint, créait des objets partout tracebackgrâce au code de gestion des exceptions. Je suppose que lorsque quelque chose est utilisé quelque part que l'on peut appeler un "truc intéressant", alors en cours de route, ils oublient comment faire la même chose plus facilement. Donc je ne m'en plains pas vraiment.
Les objets
tracebackont beaucoup de données liées astroid. Il y a eu des progrès dans mes recherches! Bibliothèqueastroidest assez similaire à un programme qui peut contenir d'énormes quantités de données en mémoire, car il analyse les fichiers.
J'ai fouillé dans le code et j'ai trouvé les lignes suivantes dans le fichier
astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
«C'est ça», ai-je pensé, «c'est exactement ce que je recherche!» C'est une séquence d'exceptions qui aboutit à la plus longue chaîne d'objets
traceback. Et ici, entre autres, les fichiers sont analysés, donc des mécanismes récursifs peuvent également être rencontrés ici. Et quelque chose qui ressemble à une construction raise thing from other_thinglie tout cela ensemble.
J'ai enlevé
from exet ... rien ne s'est passé. La quantité de mémoire consommée par le programme est restée pratiquement au même niveau, les objets tracebackne sont pas allés nulle part non plus.
J'étais conscient que les exceptions stockent leurs liaisons locales dans des objets
traceback, vous pouvez donc y accéder ex. En conséquence, leur mémoire ne peut pas être effacée.
J'ai fait une refactorisation massive du code, en essayant de me débarrasser du bloc
except, ou au moins à partir d'un lien vers ex. Mais, encore une fois, je n'ai rien. Même
si j'éclatais, je ne pouvais pas "inciter" le garbage collector sur des objets
traceback, même en considérant qu'il n'y avait aucune référence à ces objets. J'ai supposé que la raison en était qu'il y avait un autre lien quelque part.
En fait, j'ai pris une fausse piste à l'époque. Je ne savais pas si c'était la cause de la fuite de mémoire, car à un moment donné, j'ai commencé à réaliser que je n'avais aucune preuve pour étayer ma «théorie des chaînes d'exceptions». Je n'avais qu'un tas de suppositions et des millions d'objets
traceback.
Puis j'ai commencé à regarder ces objets au hasard à la recherche d'indices supplémentaires. J'ai essayé de "monter" manuellement la chaîne de maillons, mais à la fin je n'ai trouvé que du vide.
Puis il m'est apparu: tous ces objets
tracebacksont situés «l'un au-dessus de l'autre», mais il doit y avoir un objet «au-dessus» de tous les autres. Un qui n'est référencé par aucun des autres objets de ce type.
Les liens étaient faits à travers une propriété
tb_next, la séquence de ces liens était une simple chaîne. J'ai donc décidé de jeter un œil aux objets tracebackau bout des chaînes respectives:
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
Il y a quelque chose de magique à se frayer un chemin à travers un demi-million d'objets avec une seule ligne et à trouver ce dont vous avez besoin.
En général, j'ai trouvé ce que je cherchais. J'ai trouvé la raison pour laquelle Python devait garder tous ces objets en mémoire.

Trouver la source du problème
Tout était question de cache de fichiers!
Le fait est que la bibliothèque
astroidmet en cache les résultats du chargement des modules. Si le code a besoin d'un module qui a déjà été utilisé, la bibliothèque lui fournira simplement le résultat du chargement de ce module qu'elle a déjà. Cela conduit également à la reproduction des erreurs en stockant les exceptions levées.
À ce stade, j'ai pris une décision audacieuse, en raisonnant comme ceci: «Il est logique de mettre en cache quelque chose qui ne contient pas d'erreurs. Mais à mon avis, il ne sert à rien de stocker des objets
tracebackgénérés par notre code. "
J'ai décidé de me débarrasser de l'exception, de conserver ma propre classe
Erroret de simplement reconstruire les exceptions si nécessaire. Les détails peuvent être trouvés dans cePR, mais ce n'est vraiment pas particulièrement intéressant.
En conséquence, j'ai pu réduire la consommation de mémoire en travaillant avec notre base de code de 500 Mo à 100 Mo.
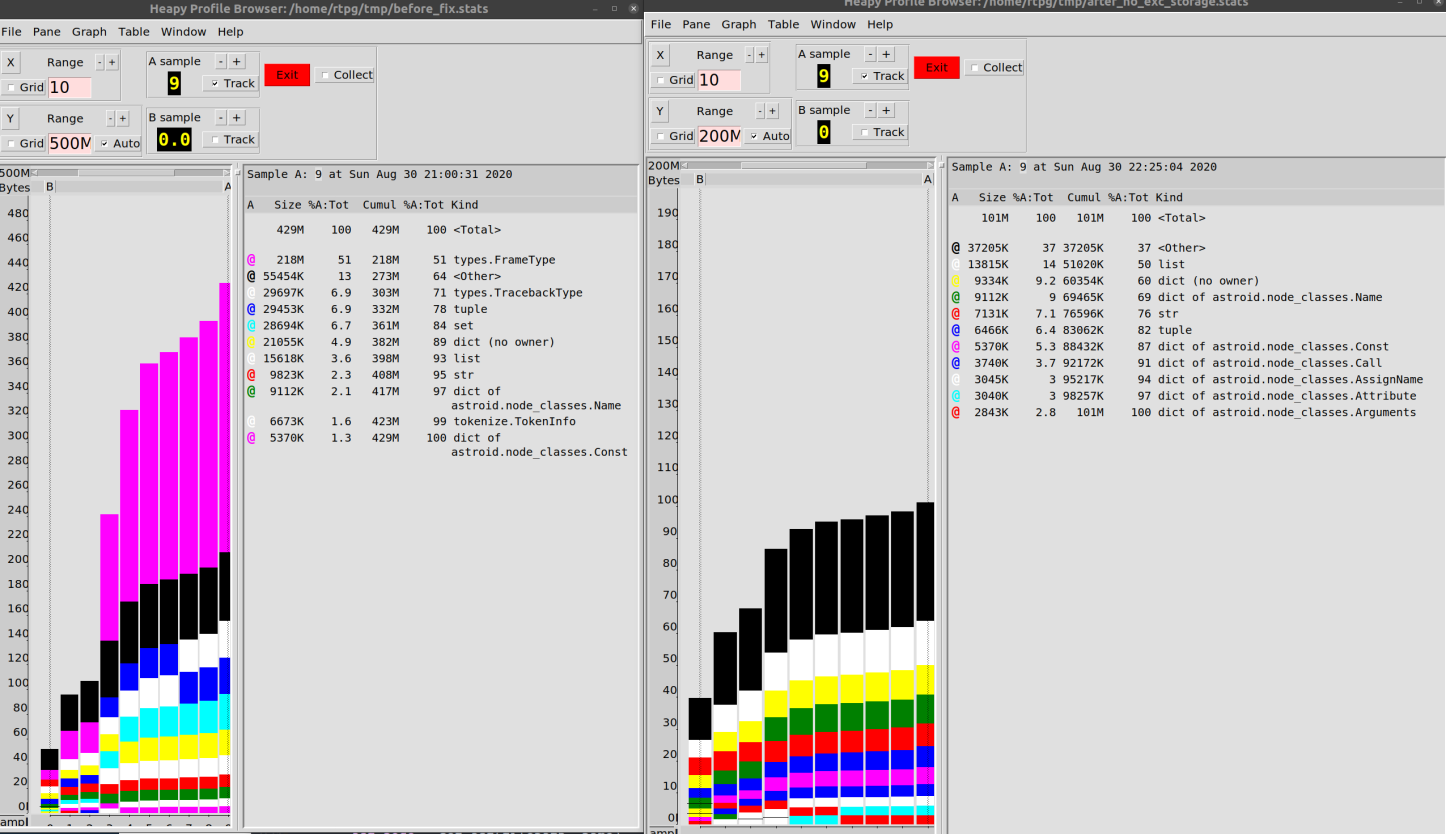
Je dirais qu'une amélioration de 80% n'est pas si mal.
En parlant de relations publiques, je ne sais pas si cela sera inclus dans le projet. Les changements qu'il apporte en soi ne sont pas uniquement liés à la performance. Je crois que la façon dont cela fonctionne peut, dans certaines situations, réduire la valeur des données de trace de pile. C'est, compte tenu de tous les détails, un changement assez grossier, même si cette solution passe tous les tests.
En conséquence, j'ai tiré les conclusions suivantes pour moi-même:
- Python nous offre d'excellentes capacités d'analyse de la mémoire. Je devrais utiliser ces fonctionnalités plus souvent lors du débogage du code.
- , .
- , -, « ». . , , , .
- , (, , Git). , , . , .
En écrivant ceci, j'ai réalisé que j'avais déjà oublié une grande partie de ce qui m'a permis de tirer certaines conclusions. J'ai donc vérifié à nouveau certains des extraits de code. Ensuite, j'ai exécuté les mesures sur une base de code différente et j'ai découvert que les bizarreries de la mémoire sont spécifiques à un seul projet. J'ai passé beaucoup de temps à chercher et à corriger cette nuisance, mais il est très probable que ce ne soit qu'une caractéristique du comportement des outils que nous utilisons, qui ne se manifeste que chez un petit nombre de ceux qui utilisent ces outils.
Il est très difficile de dire quelque chose de précis sur les performances même après avoir pris de telles mesures.
J'essaierai de transférer l'expérience acquise grâce aux expériences que j'ai décrites à d'autres projets. Je pense qu'il y a beaucoup de ces problèmes de performances dans les projets Python open source qui sont faciles à résoudre. Le fait est que la communauté des développeurs Python accorde généralement peu d'attention à ce problème (c'est - si nous ne parlons pas de projets qui sont des extensions de Python, écrits en C).
Avez-vous déjà eu à optimiser les performances de votre code Python?

