Commencer un exemple
Ci-dessous, nous allons écrire une application simple en java (l'auteur a utilisé java 14, mais java 8 convient aussi), mesurer ses performances à l'aide de compteurs à l'intérieur de l'application et essayer d'améliorer le résultat en exécutant le code dans plusieurs threads. Tout ce qui est nécessaire pour reproduire l'exemple est un environnement de développement java ou simplement jdk et un utilitaire visualvm qui nous aidera à diagnostiquer les problèmes qui se sont posés. L'exemple n'utilise intentionnellement pas divers points de repère pour mesurer les performances et d'autres outils avancés - dans ce cas, ils sont superflus. Le cas de test a été exécuté sous Windows sur un processeur Intel Core i7 avec 4 cœurs physiques et 8 cœurs logiques.
Alors, créons une application simple qui, en boucle, effectuera une tâche de calcul qui alourdit le processeur, à savoir le calcul de la factorielle. De plus, chaque tâche de la boucle calculera également la factorielle d'un nombre compris entre 1 et 25. La plage flottante est prise pour rapprocher l'exemple de la réalité. Voici le code de la fonction work ():
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(RandomUtils.nextInt(1, 25));
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
La fonction reçoit en entrée le nombre de cycles de calcul de la factorielle, spécifié par une constante:
private static final int POWER_BASE = 1000000;Après avoir terminé un certain nombre de tâches spécifiées dans la variable
private static final int LOG_STEP = 10;Le nombre de tâches terminées et la durée totale de leur exécution sont enregistrés.La
fonction work () utilise également:
//
private long startTime;
//
private AtomicLong counter = new AtomicLong();
//
private long factorial(int power) {
if (power == 1) return power;
else return power * factorial(power - 1);
}
Il convient de noter qu'une exécution unique de la fonction work () dans un thread prend environ 20 ms, donc un appel synchronisé à la variable de compteur partagée à la fin, qui pourrait être un goulot d'étranglement, ne crée pas de problèmes, car cela ne se produit pas plus de 20 fois pour chaque thread ms, ce qui dépasse considérablement le temps d'exécution de counter.incrementAndGet (). En d'autres termes, la contention entre les threads associée à l'accès à un compteur synchronisé ne devrait pas affecter de manière significative les résultats de l'expérience et peut être négligée.
Exécutons le code suivant dans un thread et voyons le résultat:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
work(POWER_BASE);
}
Dans la console, nous voyons le résultat suivant:
10 tâches terminées en 0 seconde
...
100 tâches terminées en 2 secondes
...
500 tâches terminées en 10 secondes
Ainsi, dans un thread, nous avons obtenu des performances égales à 50 tâches par seconde ou 20 ms par tâche.
Paralléliser le code
Si nous avons les performances X dans un thread, alors sur 4 processeurs, en l'absence de charge supplémentaire, nous pouvons nous attendre à ce que les performances soient d'environ 4 * X, c'est-à-dire qu'elles augmenteront de 4 fois. Cela semble assez logique. Eh bien essayons!
Introduisons un pool simple avec un nombre fixe de threads:
private ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
Constant:
private static final int POOL_SIZE = 1;Nous allons changer dans la plage de 1 à 16 et fixer le résultat.
Refonte du code de lancement:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(() -> work(POWER_BASE));
}
Par défaut, la taille de la file d'attente des tâches dans le pool de threads est Integer.MAX_VALUE, nous n'ajoutons pas plus de tâches Integer.MAX_VALUE au pool de threads, donc la file d'attente des tâches ne doit pas déborder.
Aller!
Tout d'abord, définissons la constante POOL_SIZE sur 8 threads:
private static final int POOL_SIZE = 8;Exécutez l'application et regardez la console:
10 Tâches terminées en 3 secondes
20 Tâches terminées en 6 secondes
30 Tâches terminées en 8 secondes
40 Tâches achevées en 10 secondes
50 Tâches terminées en 14 secondes
60 Tâches achevées en 16 secondes
70 Tâches achevées en 19 secondes
80 Tâches achevées en 20 secondes
90 Tâches achevées en 23 secondes
100 Tâches achevées en 24 secondes
110 Tâches achevées en 26 secondes
120 Tâches achevées en 28 secondes
130 Tâches achevées en 29 secondes
140 Tâches achevées en 31 secondes
150 Tâches achevées en 33 secondes
160 Tâches achevées en 36 secondes
170 tâches accomplies en 46 secondes
Que voyons-nous? Au lieu de l'augmentation attendue des performances, elle a chuté de plus de 10 fois, passant de 20 ms par tâche à 270 ms. Mais ce n'est pas tout! Le message concernant 170 tâches terminées est le dernier du journal. Ensuite, l'application semblait s'être complètement arrêtée.
Avant de traiter les raisons de ce comportement étrange du programme, comprenons la dynamique et supprimons le journal séquentiellement pour 4 et 16 threads en définissant la constante POOL_SIZE sur les valeurs appropriées.
Journal pour 4 threads:
10 Tâches terminées en 2 secondes
20 Tâches terminées en 4 secondes
30 Tâches terminées en 6 secondes
40 Tâches achevées en 8 secondes
50 Tâches achevées en 10 secondes
60 Tâches achevées en 13 secondes
70 Tâches achevées en 15 secondes
80 tâches terminées en 18 secondes
90 tâches terminées en 21 secondes
100 tâches terminées en 33 secondes
Les 90 premières tâches terminées en environ le même temps que pour 8 threads, puis 12 secondes supplémentaires ont été nécessaires pour terminer 10 autres tâches et l'application s'est bloquée.
Journal pour 16 threads:
10 Tâches terminées en 2 secondes
20 Tâches terminées en 3 secondes
30 Tâches terminées en 6 secondes
40 Tâches terminées en 8 secondes
...
290 Tâches achevées en 51 secondes
300 Tâches achevées en 52 secondes
310 Tâches achevées en 63 secondes
Après l'achèvement Pour 310 tâches, l'application s'est figée et, comme dans les cas précédents, les 10 dernières tâches ont duré plus de 10 secondes.
Résumons:
La parallélisation de l'exécution des tâches conduit à une dégradation des performances de 10 fois ou plus.Dans
tous les cas, l'application se bloque et moins il y a de threads plus elle se bloque rapidement (nous reviendrons sur ce fait)
Rechercher des problèmes
De toute évidence, quelque chose ne va pas avec notre code. Mais comment trouvez-vous la raison? Pour ce faire, nous utiliserons l'utilitaire visualvm. Et nous le lancerons avant l'exécution de notre application, et après le lancement de l'application, nous passerons au processus java requis dans l'interface visualvm. L'application peut être lancée directement depuis l'environnement de développement. Bien sûr, c'est généralement faux, mais dans notre exemple, cela n'affectera pas le résultat.
Tout d'abord, nous regardons l'onglet Moniteur et voyons que quelque chose ne va pas avec la mémoire.
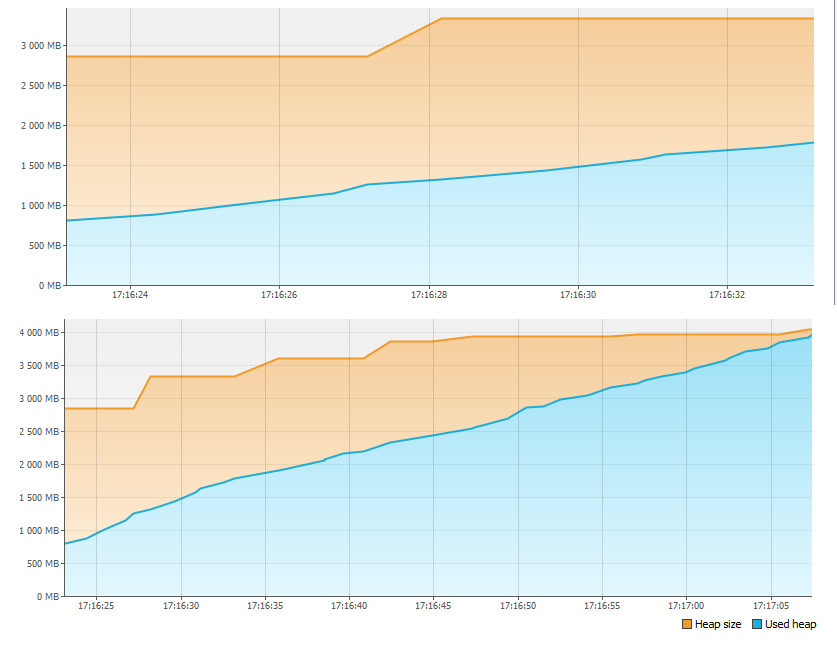
En moins d'une minute, 4 Go de mémoire ont tout simplement manqué! Par conséquent, l'application s'est arrêtée. Mais où est passé le souvenir?
Lancez à nouveau l'application et appuyez sur le bouton Heap Dump de l'onglet Monitor. Après avoir supprimé et ouvert le vidage de la mémoire, nous voyons:

Dans la section Classes by Size of Instances, plus de 1 Go est occupé par la classe LinkedBlockingQueue $ Node. Ce n'est rien de plus qu'un sommet de la file d'attente des tâches du pool de threads. La deuxième classe la plus importante est la tâche elle-même ajoutée au pool de threads. À l'appui de cela, dans la section Classes By Number of Instances, nous voyons la correspondance entre le nombre d'instances des première et deuxième classes (la correspondance n'est pas entièrement précise, apparemment en raison du fait qu'une tâche est créée d'abord, puis seulement un nouveau haut de la file d'attente, et en raison du décalage horaire multiplié par le nombre de threads, nous avons une légère différence dans le nombre d'instances).
Maintenant comptons. Nous créons environ 2 milliards de tâches dans une boucle (Integer.MAX_VALUE), soit environ 2 Go de tâches. Les tâches sont exécutées plus lentement qu'elles ne sont créées, de sorte que la taille de la file d'attente continue d'augmenter. Même si chaque tâche ne nécessitait que 8 octets de mémoire, la taille maximale de la file d'attente serait:
8 * 2 Go = 16 Go
Avec une taille totale de segment de mémoire de 4 Go, il n'est pas surprenant qu'il n'y ait pas assez de mémoire. En fait, si on n'interrompait pas l'exécution de l'application dont le journal s'arrêtait, au bout d'un moment on verrait le fameux OutOfMemoryError et même sans visualvm, rien qu'en regardant le code, on pourrait deviner où va la mémoire.
Rappelons-nous que moins il y a de threads exécutant les tâches, plus l'application s'arrête rapidement. Nous pouvons maintenant essayer d'expliquer cela. Moins il y a de threads, plus l'application s'exécute rapidement (pourquoi - nous n'avons pas encore trouvé) et plus vite la file d'attente des tâches se remplit et la mémoire devient pleine.
Eh bien, la résolution du problème de débordement de mémoire est très simple. Créons une constante au lieu de Integer.MaxValue:
int statique final privé MAX_TASKS = 1024 * 1024;
Et changeons le code comme suit:
startTime = System.currentTimeMillis();
for (int i = 0; i < MAX_TASKS; i++) {
executorService.execute(() -> work(POWER_BASE));
}
Il reste maintenant à exécuter l'application et à s'assurer que tout est en ordre avec la mémoire:

Nous continuons l'analyse
Nous lançons à nouveau notre application, en augmentant séquentiellement le nombre de threads et en fixant le résultat.
1 thread - 500 tâches en 10 secondes
2 threads - 500 tâches en 21 secondes
4 threads - 500 tâches en 37 secondes
8 threads - 500 tâches en 49 secondes
16 threads - 500 tâches en 57 secondes
Comme on peut le voir, le temps d'exécution de 500 tâches en augmentant le nombre de threads ne diminue pas, mais augmente, tandis que la vitesse d'exécution de chaque portion de 10 tâches est uniforme et que les threads ne se figent plus.
Utilisons à nouveau l'utilitaire visualvm et effectuons un vidage de thread pendant que l'application est en cours d'exécution. Pour une image plus précise, il est préférable de faire un vidage lorsque vous travaillez sur 16 threads. Il existe différents utilitaires pour analyser les vidages de threads, mais dans notre cas, vous pouvez simplement faire défiler tous les threads avec les noms "pool-1-thread-1", "pool-1-thread-2", etc. dans l'interface visualvm et voir ce qui suit:

Au moment du dumping, la plupart des threads génèrent le prochain nombre aléatoire pour calculer la factorielle. Il s'avère que c'est la fonction la plus chronophage. Pourquoi alors? Pour le comprendre, allons dans le code source de Random.next () et voyons ce qui suit:
private final AtomicLong seed;
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
Tous les threads partagent une seule instance de la variable de départ, dont l'accès est synchronisé à l'aide de la classe AtomicLong. Cela signifie que lorsque chaque nombre aléatoire est généré, les threads sont mis en file d'attente pour accéder à cette variable, plutôt que d'être exécutés en parallèle. Par conséquent, la productivité n'augmente pas. Mais pourquoi tombe-t-elle? La réponse est simple. Lors de la mise en parallèle de l'exécution, des ressources supplémentaires sont consacrées à la prise en charge du traitement parallèle, en particulier à la commutation du contexte du processeur entre les threads. Il s'avère que des coûts supplémentaires sont apparus et que les threads ne fonctionnent toujours pas en parallèle, car ils sont en concurrence pour l'accès à la valeur de la variable de départ et sont mis en file d'attente lorsque seed.compareAndSet () est appelée. Concurrence entre les threads pour une ressource limitée, peut-êtrela cause la plus courante de dégradation des performances lors de la parallélisation des calculs.
Modifions le code de la fonction work () comme suit:
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(20);
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
et vérifiez à nouveau les performances sur un nombre différent de threads:
1 thread - 1000 tâches en 17 secondes
2 threads - 1000 tâches en 10 secondes
4 threads - 1000 tâches en 5 secondes
8 threads - 1000 tâches en 4 secondes
16 threads - 1000 tâches en 4 secondes
Maintenant le résultat est proche de nos attentes. Les performances sur 4 threads ont été multipliées par 4 environ. En outre, l'augmentation des performances s'est pratiquement arrêtée car la parallélisation est limitée par les ressources du processeur. Jetons un coup d'œil aux graphiques de la charge du processeur, capturés via visualvm lorsque vous travaillez sur 4 et 8 threads.

Comme le montrent les graphiques, avec 4 threads, plus de 50% des ressources du processeur sont libres, et avec 8 threads, le processeur est utilisé à presque 100%. Cela signifie que dans cet exemple, 8 threads est la limite, les performances supplémentaires ne feront que diminuer. Dans notre exemple, la croissance des performances s'est déjà arrêtée sur 4 threads, mais si les threads, au lieu de calculer la factorielle, effectuaient des E / S synchrones, alors, très probablement, la limite de parallélisation à laquelle cela donne un gain de performance pourrait être considérablement augmentée. Les lecteurs peuvent le vérifier eux-mêmes et écrire le résultat dans les commentaires de l'
article.Si nous parlons de pratique, alors deux points importants peuvent être notés:
La parallélisation est généralement efficace lorsque le nombre de threads est jusqu'à 2 fois le nombre de cœurs de processeur (bien sûr, en l'absence d'une autre charge de processeur)
l'utilisation du processeur en pratique ne doit pas dépasser 80% pour garantir la tolérance aux pannes
Réduire les conflits entre les threads
S'emballer dans les discussions sur la performance, nous avons oublié une chose essentielle. En modifiant l'appel à RandomUtils.nextInt () dans le code en une constante, nous avons modifié la logique métier de notre application. Revenons à l'ancien algorithme tout en évitant les problèmes de performances. Nous avons découvert que l'appel de RandomUtils.nextInt () obligeait chacun des threads à utiliser la même variable de départ pour générer un nombre aléatoire, et, en attendant, c'est complètement facultatif. En utilisant dans notre exemple au lieu de
RandomUtils.nextInt(1, 25)la classe ThreadLocalRandom:
ThreadLocalRandom.current().nextInt(1, 25)résoudra le problème de la concurrence. Maintenant, chaque thread utilisera sa propre instance de la variable interne nécessaire pour générer le prochain nombre aléatoire.
L'utilisation d'une variable distincte pour chaque thread, au lieu d'un accès synchronisé à une seule instance d'une classe partagée entre les threads, est une technique courante pour améliorer les performances en réduisant les conflits entre les threads. La classe java.lang.ThreadLocal peut être utilisée pour stocker les valeurs de variables dans le contexte d'un thread, bien qu'il existe des outils plus avancés, par exemple, Mapped Diagnostic Context.
En conclusion, je voudrais noter que réduire la concurrence entre les threads n'est pas seulement une tâche technique, mais aussi une tâche logique. Dans notre exemple, chaque thread peut utiliser sa propre instance de variable sans aucun problème, mais que faire si nous avons besoin d'une instance pour tous, par exemple, un compteur partagé? Dans ce cas, vous devrez refactoriser l'algorithme lui-même. Par exemple, stockez un compteur dans le contexte de chaque flux et calculez périodiquement ou sur demande la valeur du compteur total sur la base des valeurs des compteurs pour chaque flux.
Conclusion
Donc, il y a 3 points qui affectent les performances du traitement parallèle:
- Ressources CPU
- Concurrence entre les fils
- Autres facteurs qui affectent indirectement le résultat global