Les besoins des clients peuvent être exprimés par les caractéristiques suivantes du profileur souhaité:
- disposer d'un outil d'analyse des performances pour un ensemble d'architectures spécifique;
- être capable de faire une analyse approfondie des performances jusqu'aux instructions en code démonté;
- pour avoir un moyen de visualiser et de travailler avec la sortie du code désassemblé dans une interface graphique pratique pour un tel ensemble d'architectures - x86_64, ARMv7, ARMv8.
Autrement dit, un profileur était requis, qui devrait:
- être multiplateforme;
- être capable de générer un désassembleur pour les fonctions des architectures de cet ensemble - x86_64, ARMv7, ARMv8;
- afficher les résultats et interagir avec l'utilisateur via l'interface graphique et maintenir la convivialité.
Pour répondre aux besoins du client, nous avons développé un nouveau composant système - un désassembleur multiplateforme avec génération de code pour x86_64, ARMv7, ARMv8 (fonctionnalité et interface graphique pour travailler avec sa sortie).
Examinons un exemple d'une simple démonstration de code C ++ sur Hotspot en action et les capacités d'analyse des performances qu'il fournit. Exemple:
cat demo.cpp:
#include <iostream>
int g (int arg) {
return abs(rand()) * arg;
}
int f() {
int i = 1;
int res = 1 ;
std::cout << abs(rand()) << std::endl;
while (i < 1000000) {
res += i * g(res);
i++;
}
std::cout << res << std::endl;
return res;
}
int main() {
std::cout << f() << std::endl;
return 0;
}Nous compilons, construisons notre application de démonstration:
g++ demo.cpp -o demoLancez notre profileur:
./hotspotÉtape 1 - Collectez et écrivez des données dans le fichier perf.data.
Cela peut être fait de deux manières - à partir de la ligne de commande en utilisant un appel explicite à perf
record -o /home/demo/perf.data --call-graph dwarf ./demoOu en utilisant le menu Hotspot File-> Record Data.
Pour notre démo, nous collectons des événements de type cycles, mais vous pouvez définir tout autre type d'événement ou un ensemble de types d'événements (échecs de cache, instructions, branchements manqués, etc.)

Cliquez sur Démarrer l'enregistrement, attendez que la vue Résultats s'allume:

Plongez dans le monde de l'analyse des performances.
Ici, nous trouverons des informations résumées et des champions parmi les consommateurs de l'exécution de notre démo.

Chaînes d'appels dans les deux sens - de la méthode appelée à la méthode appelante (Bottom Up) et vice versa (Bottom Down) avec des temps (poids).


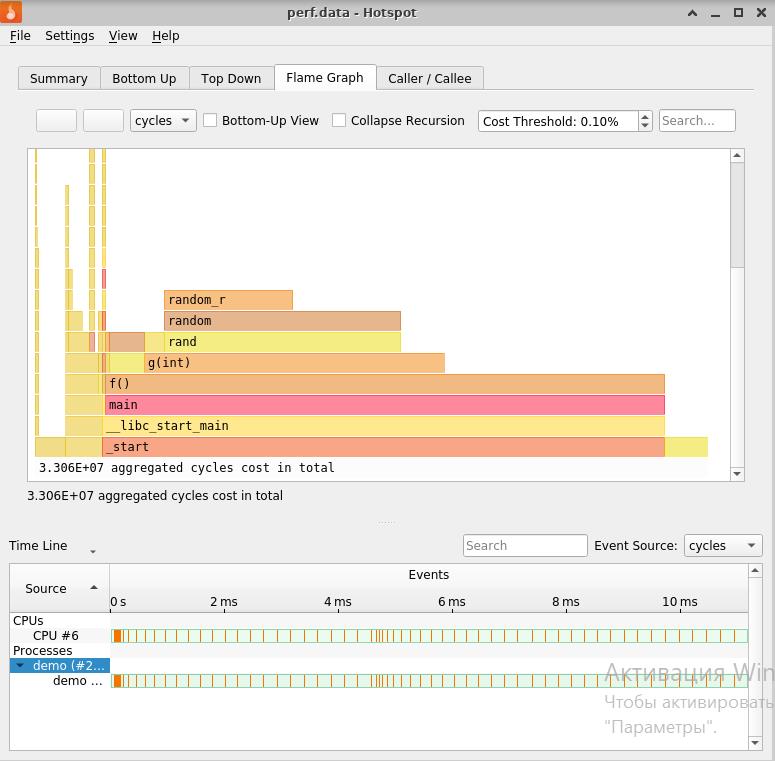
Flame Graph et données sur les performances, temps d'exécution pour chaque
fonction / méthode qui lui est significative.
Pour obtenir des informations plus détaillées sur la fonction qui nous intéresse, avec la distribution des événements en son sein (jusqu'aux instructions du code désassemblé), appuyez sur l'élément Désassemblage du menu contextuel. Il s'ouvre en faisant un clic droit sur la fonction que vous aimez:

maintenant nous savons tout sur cette fonction!

Vous pouvez naviguer dans la pile d'appels. Double-cliquez sur l'instruction d'appel surlignée en bleu. Et devant nous, il y a un désassembleur pour la fonction appelée g (int). L'instruction consommatrice de CPU n'a pas de concurrents ici.

Ctrl + B, Ctrl + D - et nous avons également des codes machine de commandes, et le désassembleur a été généré en utilisant objdump. Dans les cas précédents, le code produit en appelant perf annotate était affiché.

Le bouton Retour est allumé, vous pouvez vous déplacer le long de la pile d'appels dans les deux sens!
Allez à l'instruction avec l'adresse 1236 et double-cliquez sur l'instruction avec l'adresse 124f. Et encore une fois, la transition vers l'instruction avec l'adresse 1236 est disponible.

Ctrl + B, Ctrl + I nous fait passer à la syntaxe Intel Assembler: Nous serons

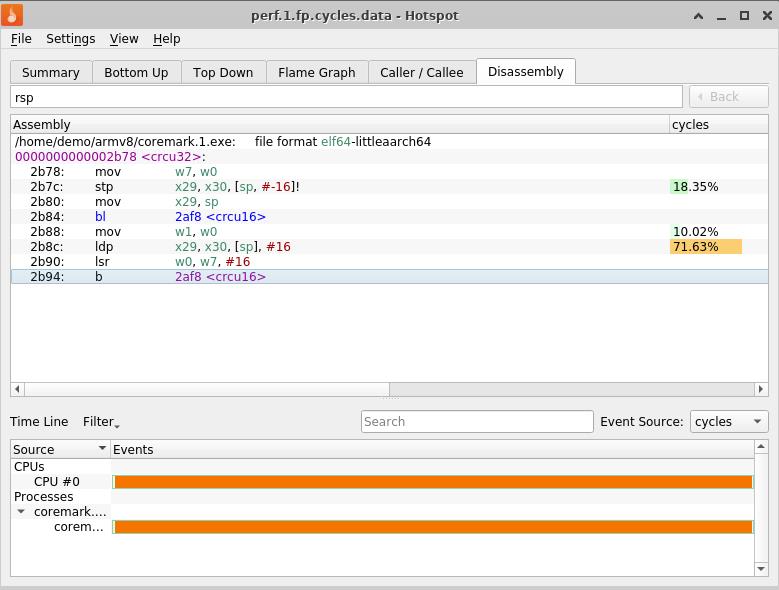
heureux de l'opportunité de rechercher du texte par le motif saisi, par exemple en utilisant le registre% rsp:

Et ... sans quitter l'endroit, nous passons à ARM ... Pour ce faire, nous aurons besoin, en gros, de deux entités - le fichier exécutable de l'application utilisateur, construit sur ARM, et le fichier perf.data correspondant, enregistré ici. Dans notre démo, il s'agit de coremark.1.exe et perf.1.fp.cycles.data, construits sur ARMv8. Nous les mettons dans / home / demo / armv8 / et chargeons perf.data -

Ainsi, nous avons non seulement rempli les tâches définies par le client, mais les avons également dépassées - en particulier, le calcul et l'affichage de la distribution des événements selon les instructions du désassembleur nous permet de faire une analyse approfondie jusqu'à une instruction pouvant être liée à une chaîne dans le code, le programme dispose d'une interface graphique - une interface conviviale avec des paramètres de profilage croisé.
Linux perf gui Hotspot est distribué sous les termes de la licence publique générale GNU en accord avec nos partenaires. En d'autres termes, nous accordons à tous les utilisateurs intéressés le droit de copier, modifier et distribuer gratuitement ce programme de profilage.
Il est hébergé sur GitHub avec des instructions de téléchargement et d'installation . Tout le monde peut en prendre connaissance et l'apprécier.
Nous vous invitons, en emmenant Linux Perf GUI (Hotspot) aux guides, à un voyage passionnant à travers votre application et les particularités de son travail, à plonger dans l'atmosphère d'élite des équipes d'assemblage, à visiter diverses architectures et bien plus encore.