Pour générer le rapport requis avec une fréquence spécifiée, il suffit d'écrire une ressource de rapport personnalisée correspondante.
Scénarios d'utilisation
Des rapports de mesure personnalisés sont nécessaires, par exemple, dans les cas suivants:
- OpenShift, , (worker nodes) . . CPU , , -, , .
- OpenShift. Metering, , , , . , , , .
- De plus, dans une situation avec des clusters publics, le service des opérations serait utile pour pouvoir conserver des enregistrements dans le contexte des équipes et des services par le temps de fonctionnement total de leurs pods (ou par combien de ressources CPU ou mémoire y ont été dépensées). En d'autres termes, nous sommes à nouveau intéressés par des informations sur qui possède tel ou tel sous-marin.
Pour résoudre ces problèmes dans le cluster, il suffit de créer certaines ressources personnalisées, ce que nous ferons ensuite. L'installation de l'opérateur de comptage dépasse le cadre de cet article, donc vous référer à la documentation d'installation si nécessaire . Vous pouvez en savoir plus sur l'utilisation des rapports de comptage standard dans la documentation associée .
Comment fonctionne le comptage
Avant de créer des ressources personnalisées, jetons un coup d'œil à la mesure. Une fois installé, il crée six types de ressources personnalisées, dont nous nous concentrerons sur les éléments suivants:
- ReportDataSources (RDS) - Ce mécanisme vous permet de définir quelles données seront disponibles et peuvent être utilisées dans ReportQuery ou dans des ressources de rapport personnalisées. RDS vous permet également d'extraire des données de plusieurs sources. Dans OpenShift, les données sont extraites de Prometheus ainsi que des ressources ReportQuery (RQ) personnalisées.
- ReportQuery (rq) – SQL- , RDS. RQ- Report, RQ- , . RQ- RDS-, RQ- Metering view Presto ( Metering) .
- Report – , , ReportQuery. , , , Metering. Report .
De nombreux RDS et RQ sont disponibles immédiatement. Puisque nous nous intéressons principalement aux rapports au niveau du nœud, examinons ceux d'entre eux qui vous aideront à rédiger vos requêtes personnalisées. Exécutez la commande suivante dans le projet "openshift-metering":
$ oc project openshift-metering
$ oc get reportdatasources | grep node
node-allocatable-cpu-cores
node-allocatable-memory-bytes
node-capacity-cpu-cores
node-capacity-memory-bytes
node-cpu-allocatable-raw
node-cpu-capacity-raw
node-memory-allocatable-raw
node-memory-capacity-raw
Nous nous intéressons ici à deux RDS: node-capacity-cpu-core et node-capput-capacity - capacity-raw, car nous voulons obtenir un rapport sur la consommation CPU. Commençons par node-capacity-cpu-core et exécutons la commande suivante pour voir comment il collecte les données de Prometheus:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml
<showing only relevant snippet below>
spec:
prometheusMetricsImporter:
query: |
kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)
Ici, nous voyons une requête Prometheus qui récupère les données de Prometheus et les stocke dans Presto. Exécutons la même requête dans la console de métriques OpenShift et voyons le résultat. Nous avons un cluster OpenShift avec deux nœuds de travail (chacun avec 16 cœurs) et trois nœuds maîtres (chacun avec 8 cœurs). La dernière colonne, Value, contient le nombre de cœurs affectés au nœud.

Ainsi, les données sont reçues et stockées dans les tables Presto. Voyons maintenant les ressources de rapport personnalisé (RQ):
$ oc project openshift-metering
$ oc get reportqueries | grep node-cpu
node-cpu-allocatable
node-cpu-allocatable-raw
node-cpu-capacity
node-cpu-capacity-raw
node-cpu-utilization
Nous nous intéressons ici aux RQS suivants: node-cpu-capacity et node-cpu-capacity-raw. Comme son nom l'indique, ces métriques contiennent à la fois des données descriptives (combien de temps un nœud est en cours d'exécution, combien de processeurs il a alloué, etc.) et des données agrégées.
Les deux RDS et deux RQS qui nous intéressent sont interconnectés par la chaîne suivante:
node-cpu-capacity (rq) <b>uses</b> node-cpu-capacity-raw (rds) <b>uses</b> node-cpu-capacity-raw (rq) <b>uses</b> node-capacity-cpu-cores (rds)
Rapports personnalisables
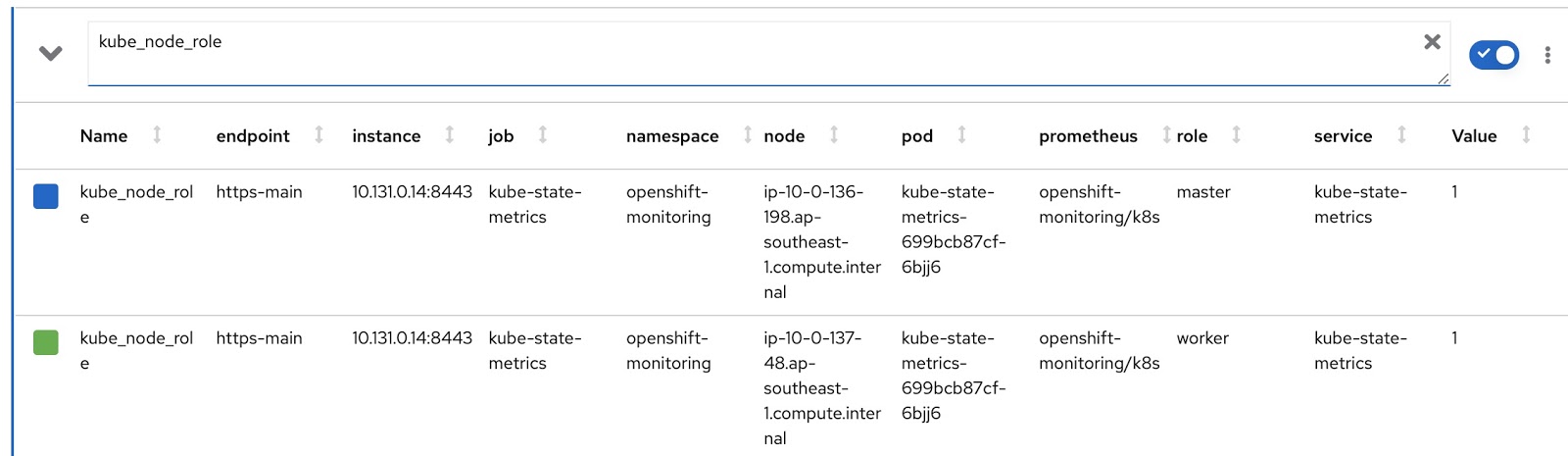
Nous allons maintenant écrire nos propres versions personnalisées de RDS et RQ. Nous devons modifier la requête Prometheus afin qu'elle affiche le mode du nœud (maître / travailleur) et l'étiquette de nœud correspondant, qui indique à quelle équipe ce nœud appartient. Le mode de fonctionnement du nœud est contenu dans la métrique kube_node_role Prometheus, voir la colonne role:
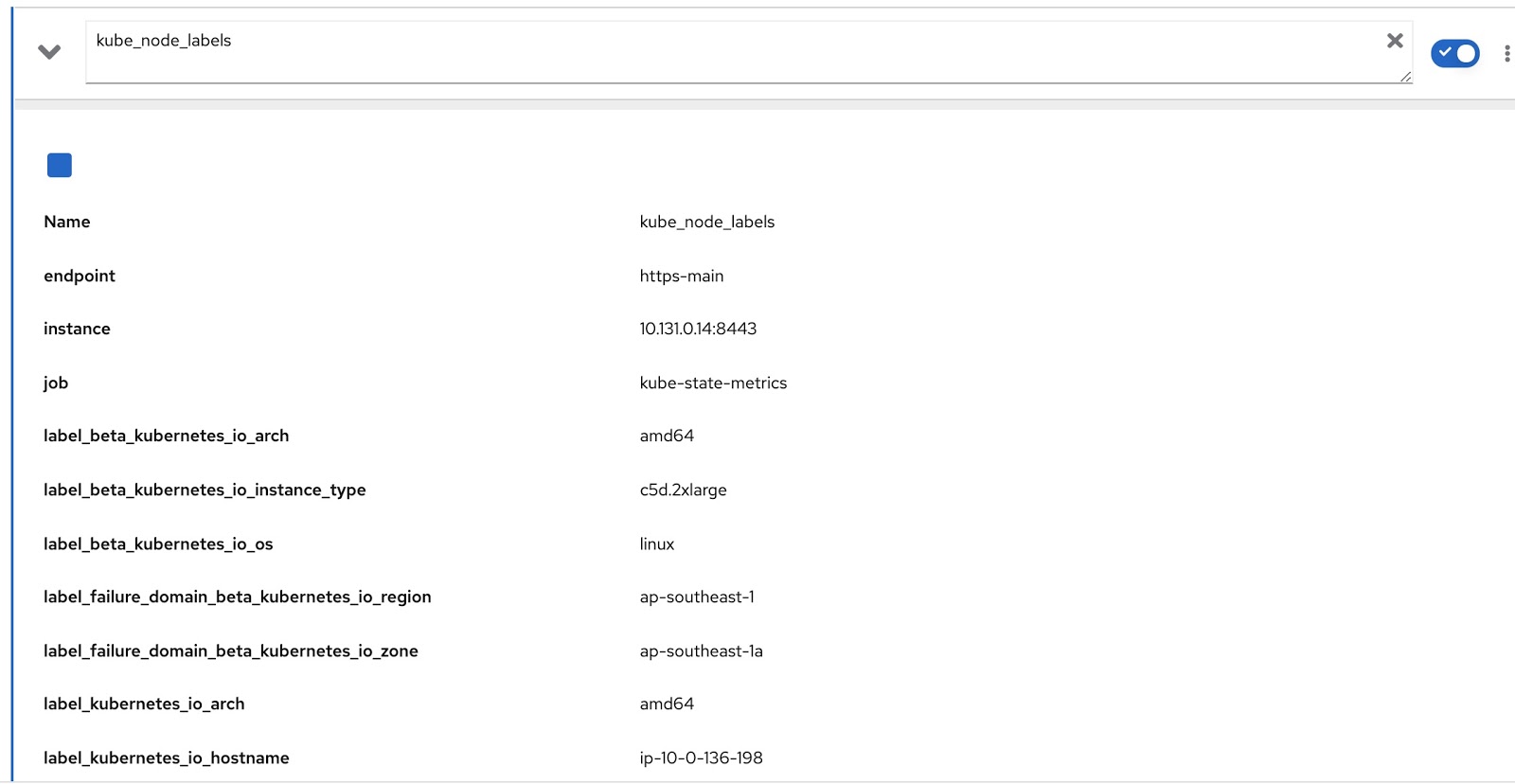
Et toutes les étiquettes affectées au nœud sont contenues dans la métrique Prometheus kube_node_labels, où elles sont formées à l'aide du modèle label_. par exemple, si un nœud a une étiquette node_lob, alors dans la métrique Prometheus, il sera affiché sous la forme label_node_lob.
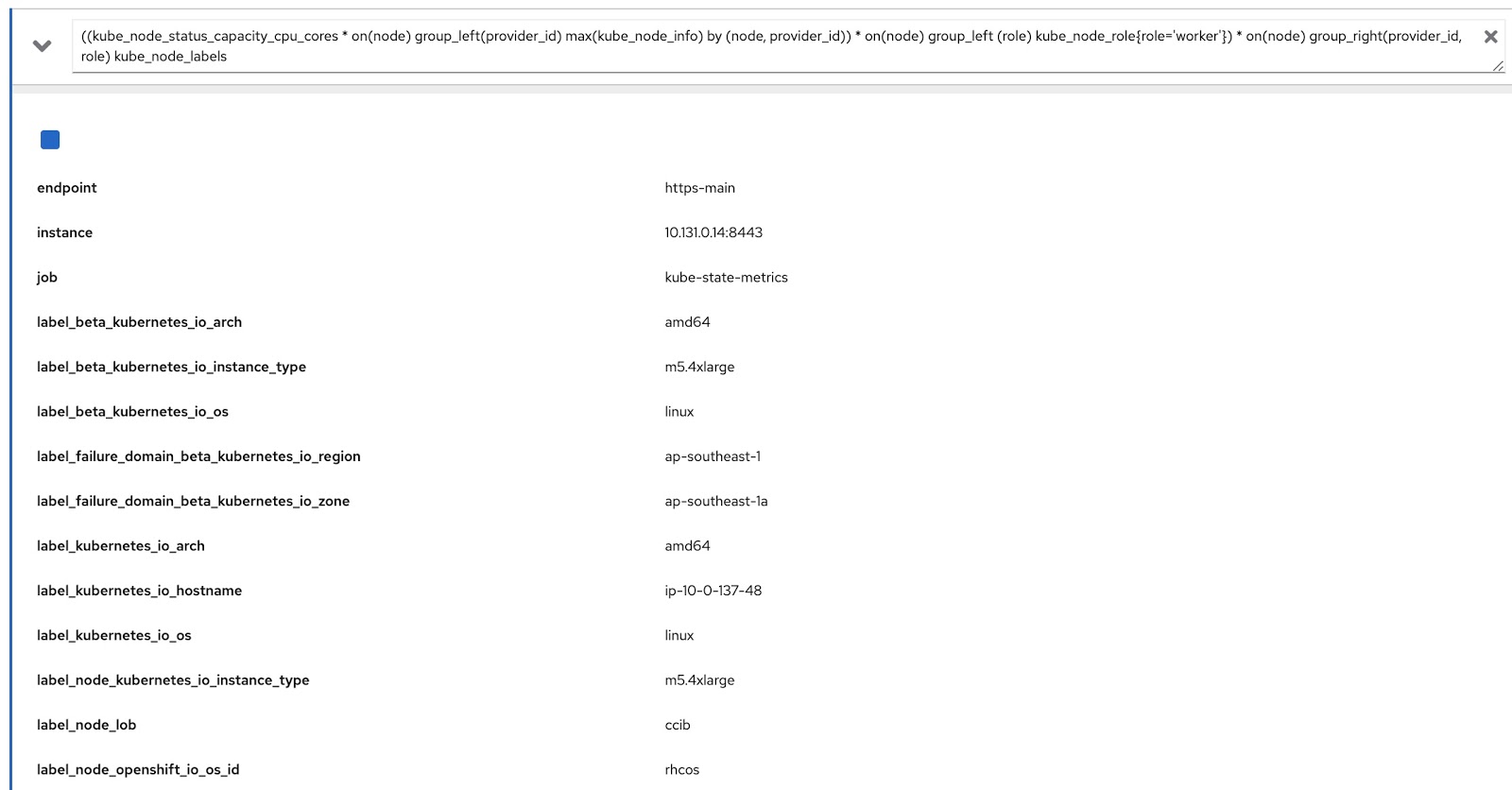
Il ne nous reste plus qu'à modifier la requête d'origine à l'aide de ces deux requêtes Prometheus pour obtenir les données dont nous avons besoin, comme ceci:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
Maintenant, exécutons cette requête dans la console de métriques OpenShift et assurez-vous qu'elle renvoie des données à la fois par étiquettes (node_lob) et par rôles. Dans l'image ci-dessous, il s'agit tout d'abord de label_node_lob, ainsi que du rôle (il est là, il n'apparaissait tout simplement pas sur la capture d'écran):
Nous devons donc écrire quatre ressources personnalisées (vous pouvez les télécharger à partir de la liste ci-dessous):
- rds-custom-node-capacity-cpu-cores.yaml - Spécifie une requête Prometheus.
- rq-custom-node-cpu-capacity-raw.yaml - fait référence à la demande de l' étape 1 et génère des données brutes.
- rds-custom-node-cpu-capacity-raw.yaml - fait référence à RQ de l' étape 2 et crée un objet de vue dans Presto.
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml - fait référence à RDS de la clause 3 et produit des données en tenant compte des dates de début et de fin entrées du rapport. De plus, les colonnes de rôle et d'étiquette sont extraites dans le même fichier.
Après avoir créé ces quatre fichiers yaml, accédez au projet openshift-metering et exécutez les commandes suivantes:
$ oc project openshift-metering
$ oc create -f rds-custom-node-capacity-cpu-cores.yaml
$ oc create -f rq-custom-node-cpu-capacity-raw.yaml
$ oc create -f rds-custom-node-cpu-capacity-raw.yaml
$ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml
Il ne reste plus qu'à écrire un objet Report personnalisé qui fera référence à l'objet RQ de l'étape 4. Par exemple, vous pouvez le faire comme indiqué ci-dessous pour que le rapport s'exécute immédiatement et renvoie les données du 15 au 30 septembre.
$ cat report_immediate.yaml
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: custom-role-node-cpu-capacity-lables-immediate
namespace: openshift-metering
spec:
query: custom-role-node-cpu-capacity-labels
reportingStart: "2020-09-15T00:00:00Z"
reportingEnd: "2020-09-30T00:00:00Z"
runImmediately: true
$ oc create -f report-immediate.yaml
Après avoir exécuté ce rapport, le fichier de résultat (csv ou json) peut être téléchargé à partir de l'URL suivante (remplacez simplement DOMAIN_NAME par le vôtre):
metering-openshift-metering.DOMAIN_NAME / api / v1 / reports / get? Name = custom-role-node-cpu- capacity-hourly & namespace = openshift-metering & format = csv
Comme vous pouvez le voir dans la capture d'écran du fichier CSV, il contient à la fois role et node_lob. Pour obtenir la disponibilité du nœud en secondes, divisez node_capacity_cpu_core_seconds par node_capacity_cpu_cores:

Conclusion
L'opérateur de comptage est une chose intéressante pour les clusters OpenShift déployés n'importe où. En fournissant un cadre extensible, il vous permet de créer des ressources personnalisées pour générer les rapports que vous souhaitez. Tous les codes sources utilisés dans cet article peuvent être téléchargés ici .