EXPLAIN (ANALYZE, BUFFERS) ...vous êtes votre outil préféré pour découvrir les particularités de ce SGBD, alors de nouvelles "puces" utiles de notre service de visualisation et d'analyse des plans explic.tensor.ru vous seront certainement utiles dans cette tâche difficile.
Mais laissez-moi vous rappeler tout de suite que sans une surveillance complète et complète de la base de données PostgreSQL, utiliser uniquement l'analyse de plan, c'est agir à partir de la position de sage # 5!

[ source KDPV , "The Blind and the Elephant" ]
, 1940
, ,
.
,
,
, .
, —
.
,
:
—
!
,
,
, ,
.
,
,
,
.
Des conflits ont éclaté parmi les aveugles
et ont duré une année entière.
Puis les aveugles
ont enfin mis leurs mains en mouvement.
Et comme le cinquième était fort,
Il a fermé la bouche de tout le monde.
Et désormais l'éléphant se compose d'
une queue!
Alors, aujourd'hui au programme:
- remplacer "chevrons" par "bretelles"
- nous rassemblons des "méga" plans
- nous gardons une archive personnelle
- étudier la généalogie des plans
- regarder dans les "fenêtres"
Pas une seule couleur!
Historiquement, lors de la visualisation du plan, nous avons marqué les nœuds "les plus chauds" avec un "chevron" vertical à gauche de la valeur - plus la valeur est élevée, plus la couleur est riche.

Mais dans un tel modèle, le rapport des valeurs est mal perçu - par exemple, un écart de 30% dans la différence de nuances ne peut être remarqué que par un œil averti. Par conséquent, nous avons fait un histogramme à partir de "bretelles" horizontales.

Statistiques utiles pour les "méga" plans
Beaucoup de gens ne remarquent pas l'onglet «Statistiques» du plan, le voici à droite:

Et celui qui l'a remarqué - l'a à peine utilisé. Nous avons décidé de corriger cette omission et de la rendre vraiment utile pour analyser les plans «volumineux» (plus de 100 nœuds).
Regroupement des nœuds
Tous les nœuds de plan "identiques" (c'est-à-dire ceux qui ont le même type de nœud, la même table utilisée et le même index) sont regroupés dans une ligne de table. Dans ce cas, tous leurs indicateurs (temps d'exécution, nombre d'enregistrements lus et rejetés, le nombre total de passes et la quantité de données lues) sont additionnés.
Et pour plus de clarté, chaque type de nœud porte une étiquette de couleur:
- rouge - la lecture des données
noeudsSeq Scan,Index Scan,CTE Scanet divers autres... Scan - jaune - traitement des données
noeudsSort,Unique,Aggregate,Group,Materialize, ... - vert - connexion
nœudsNested Loop,Merge Join,Hash Join, ...

Tri selon n'importe quel indicateur
Si soudainement vous avez besoin d'une analyse non pas par le temps total, mais par le type de nœud, par exemple - cliquez simplement sur l'en-tête de colonne - et tout sera:

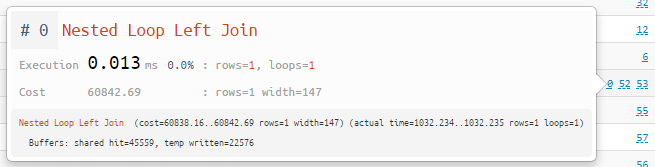
Indice de nœud contextuel
Pour comprendre en détail la contribution d'un nœud spécifique dans le groupe, survolez le nombre de l'un d'entre eux - et vous verrez l'indication traditionnelle de ce qui s'y est exactement passé:
Archives personnelles des plans
"Sans inscription et SMS!"Si vous utilisez activement notre service, il sera maintenant beaucoup plus facile de trouver vos plans précédemment analysés - il vous suffit de passer à l'onglet «mine» dans l'archive . Les plans tombent ici indépendamment de la publication dans les archives générales et ne sont visibles que par vous.

Généalogie des plans
Auparavant, il était assez difficile de trouver un spécifique de vos plans dans les archives, maintenant c'est simple. Ils peuvent être nommés et regroupés dans un «arbre généalogique» d'optimisations!
Il suffit de spécifier un nom lors de l'ajout d'un plan:

... ou sur un plan existant, vous pouvez le définir, modifier ou ajouter un plan lié:

Ensuite, vous pouvez rapidement basculer dans l'arborescence des options afin d'évaluer l'effet de certaines optimisations:

Et si un lien vers un plan spécifique soudainement perdu, il peut être facilement identifié par son nom dans ses archives personnelles:

Nous scrutons les "fenêtres"
Une petite mais utile amélioration de Query Profiler , dont j'ai parlé plus tôt - nous lui avons appris à «regarder dans les fenêtres» et à mapper correctement les nœuds de planification:
-> WindowAgg ==> WINDOW / OVER
-> Sort ==> PARTITION BY / ORDER BY... comme plusieurs définitions indépendantes de "window" (
WINDOW) dans une seule requête:
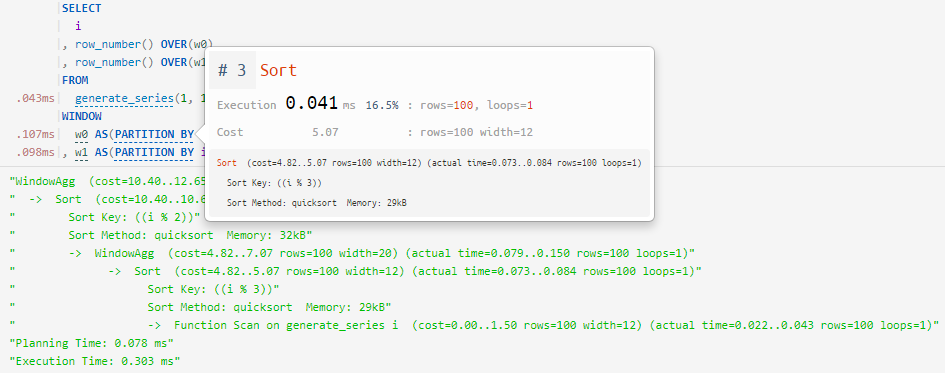
... et le tri dans les fonctions de fenêtre sans définition explicite:

Bonne chasse aux différentes inefficacités!