Bob Steagall a récemment donné une conférence à la CppCon 2020 intitulée " Adventures in SIMD-thinking ", où, entre autres, il a parlé de son expérience d'utilisation d'AVX512 pour le filtrage médian avec la fenêtre 7. Cette conférence m'a causé deux sentiments: d'un côté, c'est cool , et est censé être presque 20x plus rapide que l'implémentation STL la plus stupide; D'un autre côté, en un seul passage de l'algorithme à partir de 16 échantillons d'entrée, il s'est avéré que 2 sorties, bien que les données d'entrée étaient suffisantes pour 10, et certains détails d'implémentation m'ont donné envie d'essayer de les améliorer. J'ai pensé, pensé et ai trouvé une idée, puis une autre, puis je les ai essayées "dans le logiciel" et j'ai réalisé que j'avais quelque chose à partager :) Donc cet article s'est avéré.
Implémentation de base
Je décrirai brièvement comment cela a été fait par Bob (en fait, un court récit de la partie correspondante de son histoire, avec ses propres images). Il a créé les primitives suivantes en utilisant AVX512 (je vais omettre celles des primitives décrites par lui qui correspondent directement à la seule opération AVX512):
rotation: faites pivoter les éléments du registre AVX-512 dans un cercle

décalage avec report : décale les articles d'un registre, remplacement des articles d'un deuxième registre
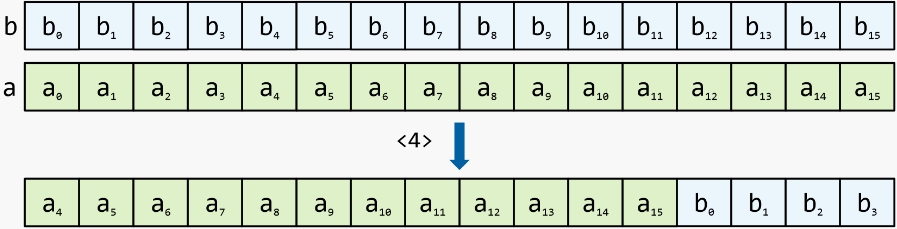
en place shift avec carry : comme shift avec carry, mais les registres d'entrée sont passés par référence et le résultat du décalage y reste
comparer avec échange : tri parallèle jusqu'à 8 paires d'éléments dans un registre

, , : perm 0..15, ; mask 1 «» . : , perm. vmin , vmax ́ . , .
, , . :
1) shift with carry, «» , «» (.. 0 0..6, 1 — 1..7 . .)
2) , 0 , 1 —
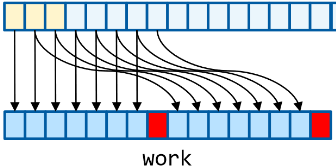
3) 7 , — 6 compare and exchange, . — — .
0
- , . , , ( , L2). , . AVX-512…
1
, — . 7 ; 6 !

, 6 r1-r6 , r0 r7? S[0..5], X, , S[3] .
X >= S[3], S[3] ,X <= S[2], S[2] S[3], S[2]S[2] < X < S[3], X S[3], , X. ,clamp(X, S[2], S[3])=>min(max(X, S[2]), S[3])!
:
«» 4 7- ( 0, 7, 2, 9) – X 4
6- 1..6 3..8 ( 0..7 8..15, )
6-
clamp 2 3 X[0] X[1], 2 3 X[2] X[3]
2x — 2 ( 6 5 , 7 — 6), clamp . : 1,86x . . ?
2
«» X . 6- ; 5 , 2 ( 3 ). — : S[0] <=> S[1], S[2] <=> S[3], S[4] <=> S[5]
2, . . , , !

— 2 , 2 . , : 1.06x. , .
3
- , 1, 6- .

, 4 ( ), 6; , 4- ?
2 , 4- . 6- : 2- Y 4- S, 2 3 ( Z). , min(Y[0], S[0]) => Z[0], ; max(Y[0], S[0]) Z[1]..Z[5] – . max(Y[1], S[3]) , min(Y[1], S[3]).
4- S[1], S[2], min/max. , 4 , 1 2 — 2 3 6- . , «» 4- S[1] S[2], — . , 2 , Y.
:
r1-r2 . .
— Y, r1-2, r5-6, r7-8, r11-12; permute 4 , Y r0-1, r4-5 . .
( ) «» ; r3-r6 r7-r10
max min Y[0]/S[0], Y[1]/S[3]
mask_permute Y S, S[1] S[2] ,
4
1 2, min/max X 8
, , , 2. — 1.64x , 2, 3 , .
; ( - permute; , - ), .
, :)
benchmark:
512 : 3.1-3.2 ; 7.3 , memcpy avx-512
50 : 2.8-2.9 ; 1.8 , memcpy (!)
.
5? , (disclaimer: — ).
16- 12 .
- 3 ( …)
1 , 4 ( 6 ) 4- — , . . 4 , 5 ; 8 .
2 , — 2 ; , .
3 , . , — , 12 . , «» — 24 , 12 .
9? 8 .
—
1 — 2 8- 4 , 4 ( 7 6 )
2 — , -
3 — , — 6- 2, 6- ( , ) , 8-.
, - . , https://github.com/tea/avx-median/. « », , -. , .
- , — . .
UPDATE
AVX2 . , , , , ( , 16 , ). , : 1.64x , .
Il s'est avéré que tout n'est pas perdu - la première étape d'optimisation peut également être appliquée à cette variante! Vous devez collecter 32 arêtes de X, vous devez brouiller les données pour le tri, les données triées doivent également être permutées, etc., mais malgré tous ces gestes, nous avons obtenu une accélération de 1,27 fois.
Je n'ai pas essayé de faire les étapes 2 et 3, car ce sera évidemment plus lent. Il est tout à fait possible que pour le cas, par exemple, de la fenêtre 11, ils fonctionnent dans un plus (seulement si quelqu'un a besoin d'un filtre 1D-médian rapide avec de grandes fenêtres - je ne sais pas).