
En octobre, traditionnellement, GPT-3 est à nouveau à l'honneur. Il y a plusieurs nouvelles liées au modèle d'OpenAI - bonnes et pas si bonnes.
Accord OpenAI et Microsoft
Nous devrons commencer par une version moins agréable: Microsoft a repris les droits exclusifs de GPT-3. L'accord a provoqué l'indignation de manière prévisible - Elon Musk, fondateur d'OpenAI et maintenant ancien membre du conseil d'administration de la société, a déclaré que Microsoft avait essentiellement repris OpenAI.
Le fait est qu'OpenAI a été créé à l'origine en tant qu'organisation à but non lucratif avec une mission élevée - ne pas permettre à l'intelligence artificielle d'être entre les mains d'un État ou d'une entreprise distincte. Les fondateurs de l'organisation ont appelé à l'ouverture de la recherche dans ce domaine, afin que la technologie fonctionne dans l'intérêt de toute l'humanité.
Microsoft, pour sa défense, déclare ne pas restreindre l'accès au modèle d'API. Ainsi, en fait, rien n'a changé - avant cela, OpenAI ne publiait pas non plus le code, mais si auparavant, même les entreprises partenaires étaient autorisées à travailler avec GPT-3 uniquement via l'API, Microsoft a désormais des droits exclusifs d'utilisation.
ruGPT3 de Sberbank
Passons maintenant à des nouvelles plus agréables - des chercheurs de la Sberbank ont publié un modèle en libre accès qui répète l'architecture GPT-3 et est basé sur le code GPT-2 et, surtout, est formé au corpus en langue russe.
Une collection de littérature russe, des données de Wikipédia, des instantanés des sites d'actualités et de questions-réponses, des documents provenant des portails Pikabu, 22century.ru banki.ru, Omnia Russica ont été utilisés comme ensemble de données pour la formation. Les développeurs ont également inclus des données de GitHub et StackOverflow pour enseigner comment générer et programmer du code. La quantité totale de données nettoyées est supérieure à 600 Go.
Les nouvelles sont vraiment bonnes, mais il y a quelques mises en garde. Ce modèle est similaire à GPT-3, mais pas. Les auteurs eux-mêmes admettentqu'il est 230 fois plus petit que la plus grande version de GPT-3, qui a 175 milliards de poids, ce qui signifie qu'il ne peut pas répéter exactement les résultats de référence. Autrement dit, ne vous attendez pas à ce que ce modèle rédige des textes indiscernables des textes journalistiques.
Il convient également de considérer que l'architecture GPT-3 décrite peut différer de l'implémentation réelle. Vous ne pouvez le dire avec certitude qu'après vous être familiarisé avec les paramètres d'entraînement, et si avant que les poids ne soient publiés avec un retard, à la lumière des événements récents, ils ne peuvent pas être attendus.
Le fait est que le budget du projet dépend du nombre de paramètres de formation et, selon les experts, la formation GPT-3 a coûté au moins 10 millions de dollars. Ainsi, seules les grandes entreprises dotées de solides spécialistes du ML et de puissantes ressources informatiques peuvent reproduire le travail d'OpenAI.
Rapport sur l'état de l'IA 2020
Tout ce qui précède confirme les conclusions du troisième rapport annuel sur l'état actuel des choses dans le domaine de l'apprentissage automatique. Nathan Benaich et Ian Hogarth, investisseurs spécialisés dans les startups IA, ont publié une présentation détaillée qui couvre la technologie, les ressources humaines, les applications industrielles et les subtilités juridiques.
Curieusement, jusqu'à 85% des recherches sont publiées sans code source. Si les organisations commerciales peuvent être justifiées par le fait que le code est souvent intégré à l'infrastructure des projets, qu'en est-il des instituts de recherche et des sociétés à but non lucratif comme DeepMind et OpenAI?
On dit également qu'une augmentation des ensembles de données et des modèles conduit à une augmentation des budgets, et étant donné que le domaine de l'apprentissage automatique stagne, chaque nouvelle percée nécessite des budgets disproportionnés (comparez la taille de GPT-2 et GPT-3), ce qui signifie qu'ils peuvent se le permettre. seulement les grandes entreprises.
Nous vous conseillons de lire ce document, car il est rédigé de manière concise et claire, bien illustré. En outre, quatre prédictions pour 2020 du dernier rapport se sont déjà réalisées.
Nous n'exagérerons pas davantage, il y a encore de bonnes histoires, sinon cette collection n'existerait pas.
Ouvrez des modèles multilingues de Google et Facebook
mT5
Google a publié le code source et l' ensemble de données de la famille T5 de modèles multilingues. En raison du battage médiatique associé à OpenAI, cette nouvelle est passée presque inaperçue, malgré l'ampleur impressionnante - le plus grand modèle a 13 milliards de paramètres.
Pour la formation, un ensemble de données de 101 langues a été utilisé, parmi lesquelles le russe occupe la deuxième place. Cela peut s'expliquer par le fait que notre grand et puissant est le deuxième endroit le plus populaire sur le Web.
M2M-100
Facebook n'est pas non plus à la traîne et a mis en place un modèle multilingue , qui, selon leurs déclarations, permet de traduire directement 100x100 paires de langues sans langue intermédiaire.
Dans le domaine de la traduction automatique, il est courant de créer et de former des modèles pour chaque langue et tâche. Mais dans le cas de Facebook, cette approche ne peut pas évoluer efficacement, car les utilisateurs du réseau social publient du contenu dans plus de 160 langues.
En règle générale, les systèmes multilingues qui gèrent plusieurs langues à la fois s'appuient sur l'anglais. La traduction est médiatisée et imprécise. Combler le fossé entre la langue source et la langue cible est difficile en raison du manque de données, car il peut être très difficile de trouver une traduction du chinois vers le français et vice versa. Pour ce faire, les créateurs ont dû générer des données synthétiques par reverse translation.
L'article fournit des références, le modèle gère mieux la traduction que les analogues qui reposent sur l'anglais, ainsi qu'un lien vers l'ensemble de données .

Progrès de la visioconférence
En octobre, des nouvelles intéressantes de Nvidia sont apparues à la fois.
StyleGAN2
Tout d'abord, nous avons publié des mises à jour pour StyleGAN2 . L'architecture de modèle à faibles ressources offre désormais des performances améliorées sur les ensembles de données contenant moins de 30 000 images. La nouvelle version introduit la prise en charge de la précision mixte: entraînement accéléré ~ 1,6 fois, inférence ~ 1,3 fois, consommation de GPU diminuée d'environ 1,5 fois. Nous avons également ajouté une sélection automatique d'hyperparamètres modèles: des solutions prêtes à l'emploi pour des ensembles de données de différentes résolutions et un nombre différent de processeurs graphiques disponibles.
NeMo
Neural Modules est une boîte à outils open source qui vous aide à créer, entraîner et régler rapidement des modèles conversationnels. NeMo se compose d'un noyau qui fournit un "look and feel" unique pour tous les modèles et collections, composé de modules regroupés par portée.
Maxine
Un autre produit annoncé utilisera probablement les deux technologies ci-dessus en interne. La plate-forme d'appel vidéo Maxine combine tout un zoo d'algorithmes ML. Cela inclut l'amélioration déjà familière de la résolution, l'élimination du bruit, la suppression de l'arrière-plan, mais aussi la correction du regard et des ombres, la restauration de l'image par les principaux traits du visage (c'est-à-dire les deepfakes), la génération de sous-titres et la traduction de la parole dans d'autres langues en temps réel. Autrement dit, presque tout ce qui était précédemment rencontré séparément, Nvidia combiné en un seul produit numérique. Vous pouvez maintenant demander un accès anticipé.
Nouveaux développements de Google
En raison de la quarantaine, il y a cette année une véritable course au leadership dans le domaine de la visioconférence. Google Meet a partagé une étude de cas sur la création de son algorithme de suppression d'arrière-plan de haute qualité basé sur le cadre de Mediapipe (qui peut suivre le mouvement des yeux, de la tête et des mains).
Google a également lancé une nouvelle fonctionnalité pour le service YouTube Stories sur iOS qui améliore la qualité vocale. C'est un cas intéressant , car il existe plusieurs fois plus d'améliorateurs pour la vidéo que pour l'audio. Cet algorithme suit et enregistre les corrélations entre la parole et les marqueurs visuels, tels que les expressions faciales, les mouvements des lèvres, qu'il utilise ensuite pour séparer la parole des sons de fond, y compris les voix d'autres locuteurs.
La société a également présenté une nouvelle tentativedans le domaine de la reconnaissance de la langue des signes.
En parlant de logiciel de visioconférence, il convient également de mentionner les nouveaux algorithmes deepfake.
MakeItTalk
Récemment, le code de l'algorithme qui anime la photo, reposant uniquement sur le flux audio, a été publié en libre accès . Ceci est remarquable, car les algorithmes deepfake prennent généralement la vidéo en entrée.

Au-delà de la croyance
La nouvelle génération d'algorithmes deepfake se donne pour tâche de remplacer non seulement le visage, mais tout le corps, y compris la couleur des cheveux, le teint et la silhouette. Cette technologie sera principalement appliquée dans le domaine des achats en ligne, afin que vous puissiez utiliser des photos de produits fournis par la marque elle-même, sans avoir à louer des modèles individuels. Plus d'applications peuvent être vues dans la démo vidéo . Jusqu'à présent, cela ne semble pas convaincant, mais bientôt tout peut changer.
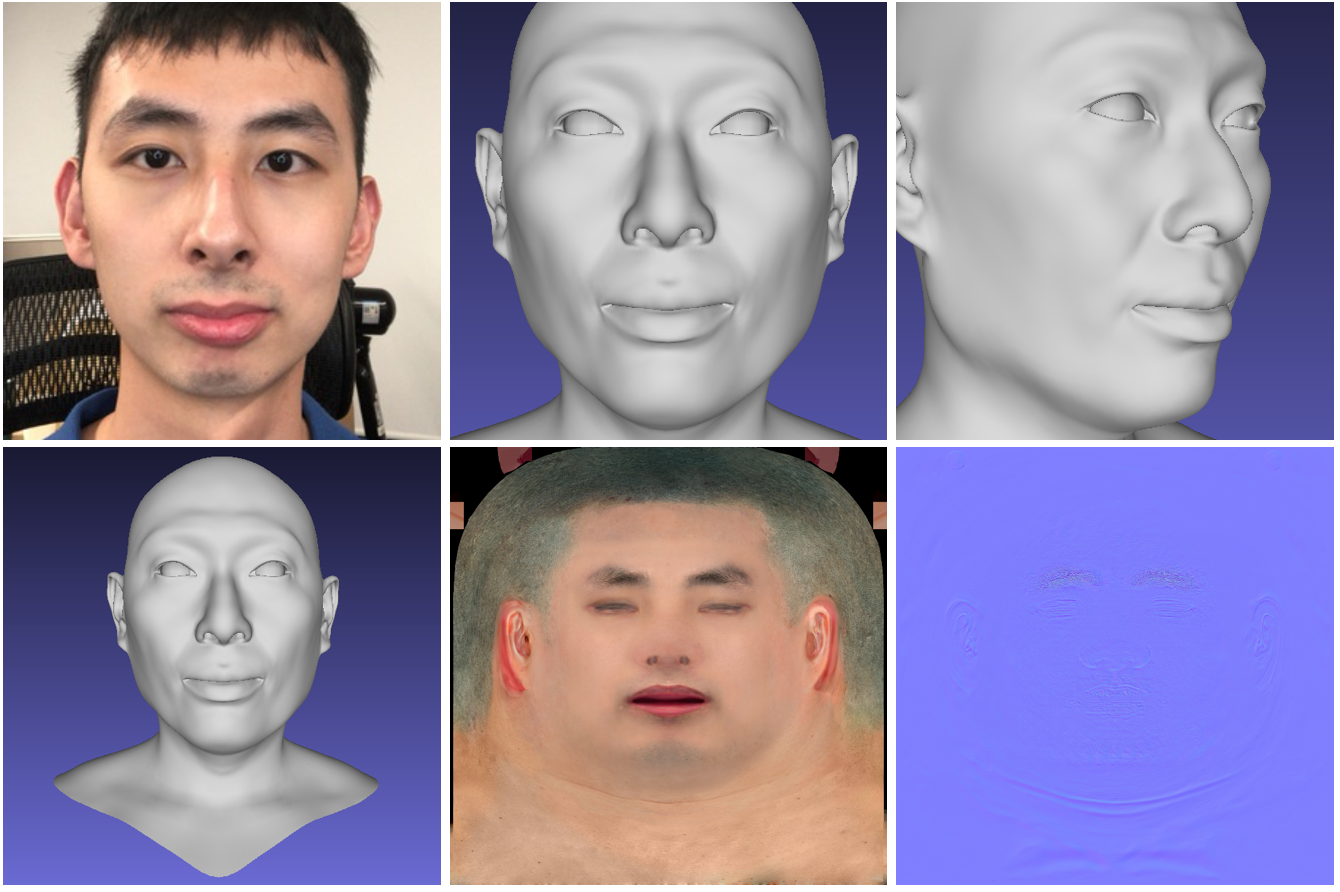
Visage 3D Hi-Fi
Le réseau neuronal génère un modèle 3D de haute qualité du visage d'une personne à partir de photographies. Le modèle accepte une courte vidéo d'une caméra RVB-D ordinaire comme entrée et produit un modèle 3D généré du visage. Le code du projet et le modèle 3DMM sont accessibles au public .

SkyAR
Les auteurs ont présenté une technologie open source pour remplacer le ciel par de la vidéo en temps réel, ce qui permet également de contrôler les styles. Des effets météorologiques tels que la foudre peuvent être générés sur la vidéo cible.
Le modèle de pipeline résout un certain nombre de tâches par étapes: la grille matte le ciel, suit les objets en mouvement, enveloppe et repeint l'image pour qu'elle corresponde au jeu de couleurs de la skybox.

Mer à travers
L'outil résout la tâche inhabituelle de restaurer les vraies couleurs dans les images sous-marines. Autrement dit, l'algorithme prend en compte la profondeur et la distance des objets afin de restaurer l'éclairage et d'éliminer l'eau des images. Jusqu'à présent, seuls les ensembles de données sont disponibles.
Modèle MIT pour diagnostiquer Covid-19
En conclusion, nous partagerons un cas intéressant sur un sujet pertinent: les chercheurs du MIT ont développé un modèle qui distingue les patients asymptomatiques atteints d'une infection à coronavirus des personnes en bonne santé utilisant des enregistrements de toux forcée.
Le modèle a été formé sur des dizaines de milliers de bandes audio d'échantillons de toux. Selon le MIT , l'algorithme identifie les personnes qui ont été confirmées comme ayant Covid-19 avec une précision de 98,5%.
Les autorités gouvernementales ont déjà approuvé la création de l'application. L'utilisateur pourra télécharger un enregistrement audio de sa toux et, en fonction du résultat, déterminer s'il est nécessaire de faire une analyse complète en laboratoire.
C'est tout, merci pour votre attention!