Prologue
Commençons par la programmation logique et le langage Prolog. Les connaissances sur le sujet y sont présentées comme un ensemble de faits et de règles. Les faits décrivent la connaissance immédiate. Les faits sur les clients (identifiant, nom et adresse e-mail) et les factures (identifiant de compte, client, date, montant dû et montant payé) de l'exemple de l'article précédent ressembleraient à ceci
client(1, "John", "john@somewhere.net").
bill(1, 1,"2020-01", 100, 50).Les règles décrivent des connaissances abstraites qui peuvent être déduites d'autres règles et faits. La règle se compose d'une tête et d'un corps. En tête de la règle, vous devez spécifier son nom et une liste d'arguments. Le corps d'une règle est une liste de prédicats connectés par des opérations logiques AND (spécifié par une virgule) et OR (spécifié par un point-virgule). Les prédicats peuvent être des faits, des règles ou des prédicats intégrés tels que des opérations de comparaison, des opérations arithmétiques, etc. La relation entre les arguments de la tête de règle et les arguments des prédicats dans son corps est définie à l'aide de variables booléennes - si la même variable est à la position de deux arguments différents, Cela signifie que ces arguments sont identiques. Une règle est considérée comme vraie lorsque l'expression logique du corps de règle est vraie. Le modèle de domaine peut être défini comme un ensemble de règles de référencement:
unpaidBill(BillId, ClientId, Date, AmoutToPay, AmountPaid) :- bill(BillId, ClientId, Date, AmoutToPay, AmountPaid), AmoutToPay < AmountPaid.
debtor(ClientId, Name, Email) :- client(ClientId, Name, Email), unpaidBill(BillId, ClientId, _, _, _).Nous avons établi deux règles. Dans la première, nous affirmons que toutes les factures dont le montant est inférieur au montant dû sont des factures impayées. Dans le second, le débiteur est un client qui a au moins une facture impayée.
La syntaxe de Prolog est très simple: l'élément principal du programme est la règle, les principaux éléments de la règle sont les prédicats, les opérations logiques et les variables. Dans la règle, l'attention se concentre sur les variables - elles jouent le rôle d'un objet du monde modélisé et les prédicats décrivent leurs propriétés et les relations entre elles. Dans la définition de la règle de débiteur, nous déclarons que si les objets ClientId, Name et Email sont liés par une relation client et unpaidBill, ils seront également liés par une relation de débiteur. Prolog est utile lorsqu'un problème est formulé sous la forme d'un ensemble de règles, d'énoncés ou d'énoncés logiques. Par exemple, lorsque vous travaillez avec de la grammaire en langage naturel, des compilateurs, dans des systèmes experts, lors de l'analyse de systèmes complexes tels que des ordinateurs, des réseaux informatiques, des objets d'infrastructure. Complexe,Les systèmes de règles alambiqués sont mieux décrits explicitement et laissés au runtime Prolog pour les traiter automatiquement.
Prolog est basé sur une logique de premier ordre (avec certains éléments de logique d'ordre supérieur inclus). L'inférence est effectuée à l'aide d'une procédure appelée résolution SLD (résolution de clause sélective linéaire définie). Simplifié, son algorithme est un arbre traversant toutes les solutions possibles. La procédure d'inférence trouve toutes les solutions pour le premier prédicat du corps de règle. Si le prédicat actuel de la base de connaissances est représenté uniquement par des faits, les solutions sont celles qui correspondent aux liaisons actuelles des variables aux valeurs. Si par des règles, une vérification récursive de leurs prédicats imbriqués est requise. Si aucune solution n'est trouvée, la branche de recherche actuelle échoue. Ensuite, une nouvelle branche est créée pour chaque solution partielle trouvée. Dans chaque branche, la procédure d'inférence lie les valeurs trouvées à des variables,inclus dans le prédicat actuel et recherche récursivement une solution pour la liste restante de prédicats. Le travail se termine lorsque la fin de la liste de prédicats est atteinte. La recherche d'une solution peut entrer dans une boucle sans fin dans le cas de définition récursive de règles. Le résultat de la procédure de recherche est une liste de toutes les liaisons possibles de valeurs à des variables booléennes.
Dans l'exemple ci-dessus pour la règle de débiteur, la règle de résolution trouvera d'abord une solution pour le prédicat client et l'associera aux booléens: ClientId = 1, Name = "John", Email = "john@somewhere.net". Ensuite, pour cette variante de valeurs variables, une solution sera effectuée pour le prochain prédicat unpaidBill. Pour ce faire, vous devez d'abord trouver des solutions pour le prédicat de facturation, à condition que ClientId = 1. Le résultat sera des liaisons pour les variables BillId = 1, Date = "2020-01", AmoutToPay = 100, AmountPaid = 50. À la fin, AmoutToPay <AmountPaid sera vérifié dans le prédicat de comparaison intégré.
Réseaux sémantiques
Les réseaux sémantiques sont l'un des moyens les plus populaires de représenter les connaissances. Le Web sémantique est un modèle d'information d'un domaine sous la forme d'un graphe orienté. Les sommets du graphe correspondent aux concepts du domaine, et les arcs définissent les relations entre eux.
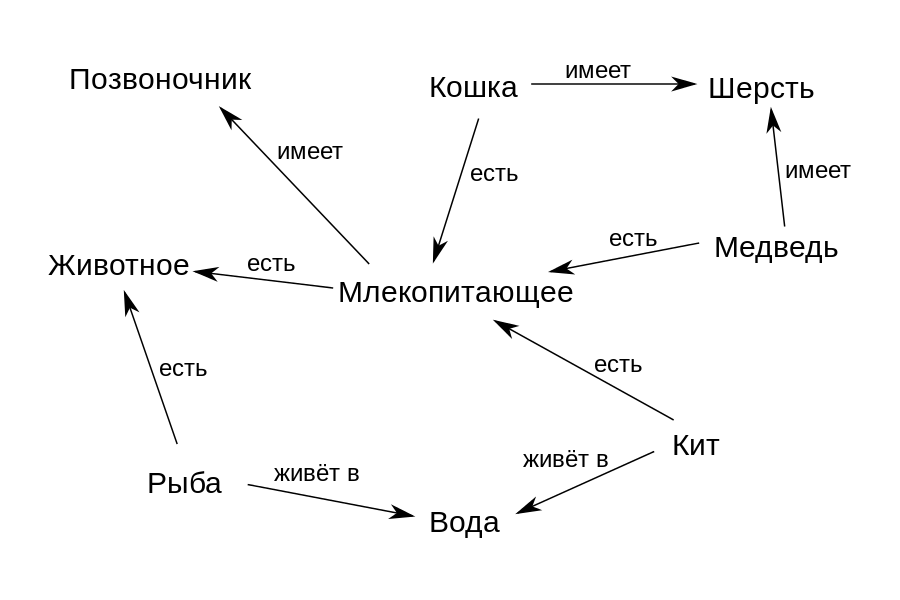
Par exemple, selon le graphique de la figure ci-dessus, le concept de «baleine» est lié par la relation «est» («est») avec le concept de «mammifère» et «vit dedans» avec le concept «d'eau». Ainsi, nous pouvons définir formellement la structure du domaine - quels concepts il comprend et comment ils sont liés les uns aux autres. Et puis un tel graphique peut être utilisé pour trouver des réponses aux questions et en tirer de nouvelles connaissances. Par exemple, nous pouvons déduire la connaissance que "Whale" "a" "Spine" si nous décidons que la relation "is" dénote une relation classe-sous-classe, et la sous-classe "Whale" devrait hériter de toutes les propriétés de sa classe "Mammal".
RDF
Le web sémantique est une tentative de construire un réseau sémantique global basé sur les ressources du World Wide Web en standardisant la présentation des informations sous une forme adaptée au traitement machine. Pour cela, des informations sont en outre intégrées dans les pages HTML sous la forme d'attributs spéciaux de balises HTML, ce qui permet de décrire la signification de leur contenu sous la forme d'une ontologie - un ensemble de faits, de concepts abstraits et de relations entre eux.
L'approche standard pour décrire le modèle sémantique des ressources WEB est RDF (Resource Description Framework ou Resource Description Framework). Selon lui, tous les énoncés doivent avoir la forme d'un triplet «sujet - prédicat - objet». Par exemple, la connaissance du concept de "Baleine" sera présentée comme suit: "Baleine" est un sujet, "vit dans" - un prédicat, "Eau" - un objet. L'ensemble complet de telles déclarations peut être décrit à l'aide d'un graphe orienté, les sujets et les objets sont ses sommets, et les prédicats sont des arcs, les arcs de prédicat sont dirigés des objets vers les sujets. Par exemple, l'ontologie de l'exemple animal peut être décrite comme suit:
@prefix : <...some URL...>
@prefix rdf: <http://www.w3.org/1999/02/rdf-schema#>
@prefix rdfs: <http://www.w3.org/2000/01/22-rdf-syntax-ns#>
:Whale rdf:type :Mammal;
:livesIn :Water.
:Fish rdf:type :Animal;
:livesIn :Water.Cette notation s'appelle Turtle et est destinée à être lisible par l'homme. Mais la même chose peut être écrite aux formats XML, JSON ou en utilisant des balises et des attributs d'un document HTML. Bien que dans la notation Turtle, les prédicats et les objets puissent être regroupés par sujet pour la lisibilité, au niveau sémantique, chaque triplet est indépendant.
RDF est utile dans les cas où le modèle de données est complexe et contient un grand nombre de types d'objets et de relations entre eux. Par exemple, Wikipedia donne accès au contenu de ses articles au format RDF. Les faits décrits dans les articles sont structurés, leurs propriétés et leurs relations sont décrites, y compris les faits d'autres articles.
RDFS
Un modèle RDF est un graphe; par défaut, aucune sémantique supplémentaire n'y est incluse. Chacun peut interpréter les liens du graphique comme bon lui semble. Vous pouvez y ajouter des liens standard en utilisant RDF Schema - un ensemble de classes et de propriétés pour construire des ontologies au-dessus de RDF. RDFS vous permet de décrire les relations standard entre les concepts, comme l'appartenance d'une ressource à une certaine classe, la hiérarchie entre les classes, la hiérarchie des propriétés et de restreindre les types possibles de sujet et d'objet.
Par exemple, l'instruction
:Mammal rdfs:subClassOf :Animal.précise que "Mammifère" est une sous-classe du concept "Animal" et hérite de toutes ses propriétés. En conséquence, le concept de "baleine" peut également être attribué à la classe "animal". Mais pour cela, il est nécessaire de souligner que les concepts "Mammifère" et "Animal" sont des classes:
:Animal rdf:type rdfs:Class.
:Mammal rdf:type rdfs:Class.En outre, le prédicat peut définir des restrictions sur les valeurs possibles de son sujet et de son objet.
Déclaration
:livesIn rdfs:range :Environment.indique que l'objet de la relation «vit dans» doit toujours être une ressource appartenant à la classe «Environnement». Par conséquent, nous devons ajouter une déclaration selon laquelle le concept d '«eau» est une sous-classe du concept d' «environnement»:
:Water rdf:type :Environment.
:Environment rdf:type rdfs:ClassRDFS vous permet de décrire le schéma de données - pour énumérer les classes, les propriétés, définir leur hiérarchie et les restrictions sur leurs valeurs. Et RDF doit remplir ce schéma de faits concrets et définir la relation entre eux. Maintenant, nous pouvons poser une question sur ce graphique. Cela peut être fait dans un langage de requête spécial SPARQL, qui ressemble à SQL:
SELECT ?creature
WHERE {
?creature rdf:type :Animal;
:livesIn :Water.
} Cette requête nous renverra 2 valeurs: "Whale" et "Fish".
Un exemple de publications précédentes avec des comptes et des clients peut être implémenté approximativement comme suit. Avec RDF, vous pouvez décrire un schéma de données et le remplir de valeurs:
:Client1 :name "John";
:email "john@somewhere.net".
:Client2 :name "Mary";
:email "mary@somewhere.net".
:Bill_1 :client :Client1;
:date "2020-01";
:amountToPay 100;
:amountPaid 50.
:Bill_2 :client :Client2;
:date "2020-01";
:amountToPay 80;
:amountPaid 80.Mais les concepts abstraits tels que «débiteur» et «factures impayées» du premier article de cette série incluent les opérations arithmétiques et la comparaison. Ils ne rentrent pas dans la structure statique du réseau sémantique de concepts. Ces concepts peuvent être exprimés à l'aide de requêtes SPARQL:
SELECT ?clientName ?clientEmail ?billDate ?amountToPay ?amountPaid
WHERE {
?client :name ?clientName;
:email ?clientEmail.
?bill :client ?client;
:date ?billDate;
:amountToPay ?amountToPay;
:amountPaid ?amountPaid.
FILTER(?amountToPay > ?amountPaid).
}La clause WHERE est une liste de motifs triples et de conditions de filtre. Les variables booléennes peuvent être substituées en triplets, dont le nom commence par "?" La tâche de l'exécuteur de requête est de trouver toutes les valeurs possibles des variables pour lesquelles tous les modèles de triplets seraient contenus dans le graphique et les conditions de filtrage seraient satisfaites.
Contrairement à Prolog, où les règles peuvent être utilisées pour construire d'autres règles, en RDF une requête ne fait pas partie du Web sémantique. Une demande ne peut pas être référencée en tant que source de données pour une autre demande. Certes, SPARQL a la capacité de représenter les résultats des requêtes sous forme de graphique. Vous pouvez donc essayer de combiner les résultats de la requête avec le graphique d'origine et exécuter la nouvelle requête sur le graphique combiné. Mais une telle décision irait clairement au-delà de l'idéologie de RDF.
HIBOU
Un composant important des technologies du Web sémantique est OWL (Web Ontology Language) - un langage pour décrire les ontologies. Avec le vocabulaire RDFS, vous ne pouvez exprimer que les relations les plus élémentaires entre les concepts - la hiérarchie des classes et des relations. OWL propose un vocabulaire beaucoup plus riche. Par exemple, vous pouvez spécifier que deux classes (ou deux entités) sont équivalentes (ou différentes). Cette tâche est souvent rencontrée lors de la combinaison d'ontologies.
Vous pouvez créer des classes composites basées sur l'intersection, l'union ou l'ajout d'autres classes:
- Lorsqu'elles sont intersectées, toutes les instances d'une classe composite doivent également s'appliquer à toutes les classes source. Par exemple, «Mammifère marin» doit être à la fois «Mammifère» et «Habitant marin» en même temps.
- . , , «» «», «» «». «».
- , . , «» «».
- . , .
- — , .
De telles expressions qui vous permettent de lier des concepts sont appelées des constructeurs.
OWL vous permet également de définir de nombreuses propriétés de relation importantes:
- Transitivité. Si les relations P (x, y) et P (y, z) sont vérifiées, alors la relation P (x, z) est également satisfaite. Des exemples de telles relations sont "Plus" - "Moins", "Parent" - "Enfant", etc.
- Symétrie. Si la relation P (x, y) est satisfaite, alors la relation P (y, x) est également satisfaite. Par exemple, une relation relative.
- Dépendance fonctionnelle. Si les relations P (x, y) et P (x, z) sont vérifiées, alors les valeurs de y et z doivent être identiques. Un exemple est la relation Père - une personne ne peut pas avoir deux pères différents.
- Inversion des relations. Vous pouvez spécifier que si la relation P1 (x, y) est satisfaite, alors une autre relation P2 (y, x) doit être remplie. Un exemple d'une telle relation est la relation parent-enfant.
- Chaînes de relations. Vous pouvez définir que si A est associé à une propriété avec B et B - avec C, alors A (ou C) appartient à une classe donnée. Par exemple, si A a un père à B et que le père B a son père C, alors A est le petit-fils de C.
Vous pouvez également définir des restrictions sur les valeurs des arguments des relations. Par exemple, spécifiez que les arguments doivent toujours appartenir à une certaine classe, ou qu'une classe doit avoir au moins une relation d'un type donné, ou limitez le nombre de relations de ce type pour elle. Vous pouvez également spécifier que toutes les instances liées par une relation donnée à une valeur donnée appartiennent à une classe spécifique.
OWL est désormais l'outil standard de facto pour la construction d'ontologies. Ce langage est mieux adapté à la construction d'ontologies volumineuses et complexes que RDFS. La syntaxe OWL vous permet d'exprimer des propriétés plus différentes des concepts et les relations entre eux. Mais il introduit également un certain nombre de restrictions supplémentaires, par exemple, le même concept ne peut pas être déclaré simultanément à la fois en tant que classe et en tant qu'instance d'une autre classe. Les ontologies OWL sont plus strictes, plus standardisées et donc plus lisibles. Si RDFS est juste quelques classes supplémentaires au-dessus d'un graphe RDF, alors OWL a une base mathématique différente - la logique de description. En conséquence, des procédures d'inférence formelles deviennent disponibles qui vous permettent d'extraire de nouvelles informations des ontologies OWL, de vérifier leur cohérence et de répondre aux questions.
La logique descriptive est une partie de la logique du premier ordre. Seuls les prédicats à une place (par exemple, un concept appartient à une classe), les prédicats à deux places (un concept a une propriété et sa valeur), ainsi que les constructeurs de classe et les propriétés de relation, répertoriés ci-dessus, y sont autorisés. Toutes les autres expressions de la logique du premier ordre dans la logique descriptive ont été supprimées. Par exemple, les déclarations selon lesquelles le concept de «facture impayée» appartient à la classe «facture», le concept de «facture» a les propriétés «montant à payer» et «montant payé» sera acceptable. Mais affirmer que le concept de propriété «Facture impayée» «Montant à payer» devrait être supérieur à la propriété «Montant payé» ne fonctionnera pas. Cela nécessite une règle qui inclut un prédicat pour comparer ces propriétés. Malheureusement,Les constructeurs d'OWL ne vous permettent pas de faire cela.
Ainsi, l'expressivité de la logique descriptive est inférieure à celle de la logique du premier ordre. Mais d'un autre côté, les algorithmes d'inférence en logique descriptive sont beaucoup plus rapides. De plus, il possède la propriété de décidabilité - la solution peut être trouvée garantie dans un temps fini. On pense qu'en pratique un tel vocabulaire est tout à fait suffisant pour construire des ontologies complexes et volumineuses, et OWL est un bon compromis entre expressivité et efficacité de l'inférence.
Il convient également de mentionner SWRL (Semantic Web Rule Language), qui combine la possibilité de créer des classes et des propriétés en OWL avec des règles d'écriture dans une version limitée du langage Datalog. Le style de ces règles est le même que dans Prolog. SWRL prend en charge les prédicats intégrés pour la comparaison, les mathématiques, la chaîne, la date et la manipulation de liste. C'est exactement ce qui nous manquait pour implémenter le concept de «facture impayée» à l'aide d'une seule expression.
Flore-2
Comme alternative aux réseaux sémantiques, considérez une technologie telle que les frames. Un cadre est une structure qui décrit un objet complexe, une image abstraite, un modèle de quelque chose. Il se compose d'un nom, d'un ensemble de propriétés (caractéristiques) et de leurs valeurs. La valeur de la propriété peut être un autre cadre. En outre, la propriété peut avoir une valeur par défaut. Une fonction de calcul de sa valeur peut être attachée à une propriété. Un cadre peut également inclure des procédures de service, y compris des gestionnaires pour de tels événements, comme la création, la suppression d'un cadre, la modification de la valeur des propriétés, etc. Une propriété importante des cadres est la capacité d'hériter. Le cadre enfant comprend toutes les propriétés des cadres parents.
Le système de trames liées forme un réseau sémantique très similaire à un graphe RDF. Mais dans les tâches de création d'ontologies, les cadres ont été supplantés par OWL, qui est maintenant le standard de facto. OWL est plus expressif, a une base théorique plus avancée - la logique descriptive formelle. Contrairement à RDF et OWL, dans lesquels les propriétés des concepts sont décrites indépendamment les unes des autres, dans le modèle de cadre, le concept et ses propriétés sont considérés comme un tout unique - le cadre. Alors que dans les modèles RDF et OWL, les sommets du graphe contiennent les noms des concepts, et les arêtes contiennent leurs propriétés, alors dans le modèle de cadre, les sommets du graphe contiennent des concepts avec toutes leurs propriétés, et les arêtes contiennent des liens entre leurs propriétés ou des relations d'héritage entre concepts.
En cela, le modèle de cadre est très proche du modèle de programmation orienté objet. Ils sont largement identiques, mais ont une portée différente - les cadres visent à modéliser un réseau de concepts et de relations entre eux, et la POO - à modéliser le comportement des objets, leur interaction les uns avec les autres. Par conséquent, la POO fournit des mécanismes supplémentaires pour cacher les détails d'implémentation d'un composant aux autres, limitant l'accès aux méthodes et aux champs d'une classe.
Les langages de cadrage modernes (tels que KL-ONE, PowerLoom, Flora-2) combinent les types de données composites du modèle objet avec la logique du premier ordre. Dans ces langages, vous pouvez non seulement décrire la structure des objets, mais également opérer avec ces objets dans des règles, créer des règles décrivant les conditions d'appartenance d'un objet à une classe donnée, etc. Les mécanismes d'héritage et de composition des classes reçoivent une interprétation logique, qui devient disponible pour une utilisation par des procédures d'inférence. Ces langages sont plus expressifs que OWL et ne sont pas limités aux prédicats à deux places.
A titre d'exemple, essayons d'implémenter notre exemple avec des débiteurs dans le langage Flora-2... Ce langage comprend 3 composants: la logique de trame F-logique, qui combine les trames et la logique du premier ordre, la logique d'ordre supérieur HiLog, qui fournit des outils pour former des déclarations sur la structure d'autres instructions et la méta-programmation, et la logique de changement de logique transactionnelle, qui permet sous forme logique décrire les changements de données et les effets secondaires des calculs. Désormais, nous ne nous intéressons qu'à la logique de trame F-logic . Pour commencer, nous l'utiliserons pour déclarer la structure des cadres qui décrivent les concepts (classes) de clients et de débiteurs:
client[|name => \string,
email => \string
|].
bill[|client => client,
date => \string,
amountToPay => \number,
amountPaid => \number,
amountPaid -> 0
|].Nous pouvons maintenant déclarer des instances (objets) de ces concepts:
client1 : client[name -> 'John', email -> 'john@somewhere.net'].
client2 : client[name -> 'Mary', email -> 'mary@somewhere.net'].
bill1 : bill[client -> client1,
date -> '2020-01',
amountToPay -> 100
].
bill2 : bill[client -> client2,
date -> '2020-01',
amountToPay -> 80,
amountPaid -> 80
].Le symbole «->» signifie la relation de l'attribut avec une valeur spécifique dans l'objet et la valeur par défaut dans la déclaration de classe. Dans notre exemple, le champ amountPaid de la classe de facturation a une valeur par défaut de zéro. Le symbole «:» signifie la création d'une entité de la classe: client1 et client2 sont des entités de la classe client.
Nous pouvons maintenant déclarer que les concepts "Facture impayée" et "Débiteur" sont des sous-classes des concepts "Compte" et "Client":
unpaidBill :: bill.
debtor :: client.Le symbole '::' déclare une relation d'héritage entre les classes. La structure de la classe, les méthodes et les valeurs par défaut de tous ses champs sont héritées. Il reste à déclarer les règles spécifiant l'appartenance aux classes impayés et débiteurs:
?x : unpaidBill :- ?x : bill[amountToPay -> ?a, amountPaid -> ?b], ?a > ?b.
?x : debtor :- ?x : client, ?_ : unpaidBill[client -> ?x]. Le premier énoncé indique qu'une variable
?est une entité impayée s'il s'agit d'une entité de facturation et que son champ amountToPay est supérieur à amountPaid. Dans le second, ce qui ?appartient à la classe unpaidBill, si elle appartient à la classe client et qu'il existe au moins une entité de la classe unpaidBill dans laquelle la valeur du champ client est égale à une variable ?. Cette entité de la classe unpaidBill sera associée à une variable anonyme ?_dont la valeur n'est plus utilisée.
Vous pouvez obtenir une liste des débiteurs à l'aide de la requête:
?- ?x:debtor.Nous vous demandons de trouver toutes les valeurs liées à la classe débiteur. Le résultat sera une liste de toutes les valeurs possibles pour la variable
?x:
?x = client1La logique de trame combine la visibilité d'un modèle orienté objet avec la puissance de la programmation logique. Ce sera pratique lorsque vous travaillez avec des bases de données, modélisez des systèmes complexes, intégrez des données disparates - dans les cas où vous devez vous concentrer sur la structure des concepts.
SQL
Enfin, jetons un coup d'œil aux principales fonctionnalités de la syntaxe SQL. Dans la dernière publication, nous avons dit que SQL a une base théorique logique - le calcul relationnel, et avons envisagé la mise en œuvre d'un exemple avec des débiteurs dans LINQ. En termes de sémantique, SQL est proche des langages de cadrage et des modèles POO - dans un modèle de données relationnel, l'élément principal est une table, qui est perçue comme un tout, et non comme un ensemble de propriétés distinctes.
La syntaxe SQL correspond parfaitement à cette orientation de table. La demande est divisée en sections. Les entités du modèle, qui sont représentées par des tables, des vues et des requêtes imbriquées, ont été déplacées vers la section FROM. Les liens entre eux sont spécifiés à l'aide d'opérations JOIN. Les dépendances entre les champs et les autres conditions se trouvent dans les clauses WHERE et HAVING. Au lieu de variables booléennes qui lient les arguments de prédicat, nous opérons sur les champs de table directement dans la requête. Cette syntaxe décrit la structure du modèle de domaine plus clairement que la syntaxe Prolog "linéaire".
Comment je vois le style de syntaxe du langage de modélisation
En utilisant l'exemple de facture impayée, nous pouvons comparer des approches telles que la programmation logique (Prolog), la logique de trame (Flora-2), les technologies Web sémantiques (RDFS, OWL et SWRL) et le calcul relationnel (SQL). J'ai résumé leurs principales caractéristiques dans un tableau:
| Langue | Base mathématique | Orientation du style | Champ d'application |
|---|---|---|---|
| Prologue | Logique du premier ordre | Sur les règles | Systèmes basés sur des règles, correspondance de modèles. |
| RDFS | Graphique | Sur le lien entre les concepts | Schéma de données de ressources WEB |
| HIBOU | Logique descriptive | Sur le lien entre les concepts | Ontologies |
| SWRL | Une version simplifiée de la logique de premier ordre de Datalog | Sur les règles en plus des liens entre les concepts | Ontologies |
| Flore-2 | Cadres + logique de premier ordre | Sur les règles au-dessus de la structure d'objet | Bases de données, modélisation de systèmes complexes, intégration de données disparates |
| SQL | Calcul relationnel | Sur les structures de table | Base de données |
Vous devez maintenant trouver la base mathématique et le style de syntaxe d'un langage de modélisation conçu pour fonctionner avec des données semi-structurées et intégrer des données provenant de sources disparates, qui seraient combinées avec des langages de programmation fonctionnels et orientés objet à usage général.
Les langages les plus expressifs sont Prolog et Flora-2 - ils sont basés sur une logique de premier ordre complète avec des éléments de logique d'ordre supérieur. Les autres approches en sont des sous-ensembles. Sauf pour RDFS - cela n'a rien à voir avec la logique formelle. À ce stade, la logique du premier ordre à part entière me semble l'option privilégiée. Pour commencer, je prévois de m'y attarder. Mais l'option limitée sous la forme d'un calcul relationnel ou d'une logique de base de données déductive a également ses avantages. Il offre d'excellentes performances lorsque vous travaillez avec de grandes quantités de données. Il devrait être envisagé séparément à l'avenir. La logique descriptive semble trop limitée et incapable d'exprimer des relations dynamiques entre concepts.
De mon point de vue, pour travailler avec des données semi-structurées et intégrer des sources de données disparates, la logique de trame est plus appropriée que Prolog orienté règles, ou OWL, qui se concentre sur les liens et les classes de concepts. Le modèle de cadre décrit explicitement les structures des objets et attire l'attention sur eux. Dans le cas d'objets avec de nombreuses propriétés, la forme cadre est beaucoup plus lisible que les règles ou les triplets sujet-propriété-objet. L'héritage est également un mécanisme très utile qui peut réduire considérablement la quantité de code répétitif. Par rapport au modèle relationnel, la logique de trame vous permet de décrire de manière plus naturelle des structures de données complexes telles que des arbres et des graphiques. Et le plus important,la proximité du modèle cadre de description des connaissances avec le modèle POO permettra de les intégrer dans une langue de manière naturelle.
Je souhaite emprunter une structure de requête à SQL. La définition d'un concept peut avoir une forme complexe et il n'y a pas de mal à le décomposer en sections afin de mettre en valeur ses composantes et de faciliter la perception. De plus, pour la plupart des développeurs, la syntaxe SQL est assez familière.
Donc, je veux prendre la logique de trame comme base du langage de modélisation. Mais comme le but est de décrire des structures de données et d'intégrer des sources de données disparates, j'essaierai d'abandonner la syntaxe orientée règles et de la remplacer par une version structurée empruntée à SQL. L'élément principal du modèle de domaine sera un «concept» (concept). Dans sa définition, je souhaite inclure toutes les informations nécessaires pour extraire ses entités des données source:
- le nom du concept;
- un ensemble de ses attributs;
- () , ;
- , ;
- , .
La définition du concept ressemblera à une requête SQL. Et tout le modèle de domaine se présentera sous la forme de concepts interdépendants.
Je prévois de montrer la syntaxe résultante du langage de modélisation dans la prochaine publication. Pour ceux qui veulent se familiariser avec lui maintenant, il existe un texte intégral dans un style scientifique en anglais, disponible ici:
Programmation orientée ontologie hybride pour le traitement de données semi-structurées
Liens vers les publications précédentes:
Conception d'un langage de programmation multi-paradigme. Partie 1 - À quoi ça sert?
Nous concevons un langage de programmation multi-paradigme. Partie 2 - Comparaison de la construction de modèles en PL / SQL, LINQ et GraphQL