Dans cet article, je vais aborder un sujet un peu plus complexe et intéressant (du moins pour moi, le développeur de l'équipe de recherche): la recherche en texte intégral. Nous ajouterons un nœud Elasticsearch à notre région de conteneur, apprendrons à créer un index et à rechercher dans le contenu, en prenant les descriptions de cinq mille films de TMDB 5000 Movie Dataset comme données de test.... Nous apprendrons également à créer des filtres de recherche et à creuser un peu le classement.
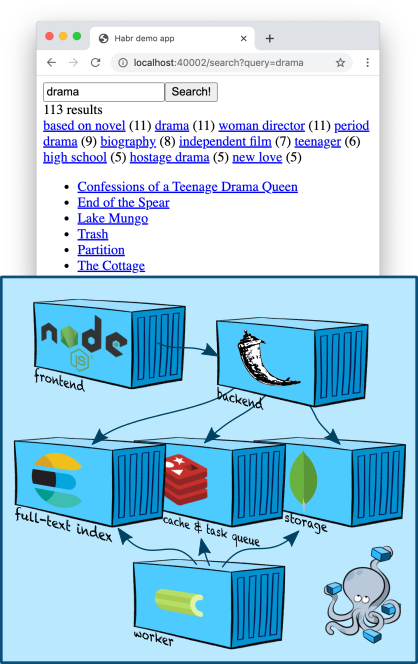
Infrastructure: Elasticsearch
Elasticsearch est un magasin de documents populaire qui peut créer des index de texte intégral et, en règle générale, est utilisé spécifiquement comme moteur de recherche. Elasticsearch ajoute au moteur Apache Lucene sur lequel il est basé, le partitionnement, la réplication, une API JSON pratique et un million de détails supplémentaires qui en ont fait l'une des solutions de recherche en texte intégral les plus populaires.
Ajoutons un nœud Elasticsearch au nôtre
docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
La variable d'environnement
discovery.type=single-nodeindique à Elasticsearch de se préparer à travailler seul, plutôt que de rechercher d'autres nœuds et de fusionner avec eux dans un cluster (c'est le comportement par défaut).
Notez que nous publions le port 9200 vers l'extérieur, même si notre application y va à l'intérieur du réseau créé par docker-compose. Ceci est purement pour le débogage: de cette façon, nous pouvons accéder à Elasticsearch directement à partir du terminal (jusqu'à ce que nous trouvions un moyen plus intelligent - plus d'informations ci-dessous).
Ajouter le client Elasticsearch dans notre câblage n'est pas difficile - le bon, Elastic fournit un client Python minimaliste .
Indexage
Dans le dernier article, nous avons mis nos principales entités - "cartes" dans une collection MongoDB. Nous sommes en mesure de récupérer rapidement leur contenu à partir d'une collection par identifiant, car MongoDB a construit un index direct pour nous - il utilise des arbres B pour cela .
Nous sommes maintenant confrontés à la tâche inverse - par le contenu (ou ses fragments) pour obtenir les identifiants des cartes. Par conséquent, nous avons besoin d'un index inversé . C'est là qu'Elasticsearch est utile!
Le schéma général de construction d'un index ressemble généralement à ceci.
- Créez un nouvel index vide avec un nom unique, configurez-le selon vos besoins.
- Nous parcourons toutes nos entités dans la base de données et les mettons dans un nouvel index.
- Nous commutons la production afin que toutes les requêtes commencent à aller vers le nouvel index.
- Suppression de l'ancien index. Ici, à volonté - vous voudrez peut-être stocker les derniers index, de sorte que, par exemple, il serait plus pratique de déboguer certains problèmes.
Créons le squelette d'un indexeur, puis allons plus en détail à chaque étape.
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# .
# .
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# .
# .
self.create_empty_cards_index(index_name)
# .
#
# .
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
Indexation: création d'un index
Un index dans Elasticsearch est créé par une simple requête PUT à
/-ou, dans le cas de l'utilisation d'un client Python (dans notre cas), en appelant
elasticsearch_client.indices.create(index_name, {
...
})
Le corps de la requête peut contenir trois champs.
- Description des alias (
"aliases": ...). Le système d'alias vous permet de savoir quel index est actuellement à jour du côté d'Elasticsearch; nous en parlerons ci-dessous. - Paramètres (
"settings": ...). Lorsque nous sommes de grands joueurs avec une vraie production, nous pourrons configurer la réplication, le partitionnement et d'autres joies SRE ici. - Schéma de données (
"mappings": ...). Ici, nous pouvons spécifier quel type de champs dans les documents que nous allons indexer, pour lesquels de ces champs nous avons besoin d'indices inverses, pour quelles agrégations doivent être prises en charge, etc.
Maintenant, nous ne sommes intéressés que par le schéma, et nous l'avons très simple:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
Nous avons marqué le champ
name, ainsi textque le texte en anglais. Un analyseur est une entité dans Elasticsearch qui traite le texte avant de le stocker dans l'index. Dans le cas de l' englishanalyseur, le texte sera divisé en jetons le long des limites des mots ( détails ), après quoi les jetons individuels seront lemmatisés selon les règles de la langue anglaise (par exemple, le mot treessera simplifié en tree), les lemmes trop généraux (en quelque sorte the) seront supprimés et les lemmes restants seront placés dans l'index inversé.
Le domaine est un
tagspeu plus compliqué. Un typekeywordsuppose que les valeurs de ce champ sont des constantes de chaîne qui n'ont pas besoin d'être traitées par l'analyseur; l'indice inverse sera construit à partir de leurs valeurs «brutes» - sans tokenisation ni lemmatisation. Mais Elasticsearch créera des structures de données spéciales afin que les agrégations puissent être lues par les valeurs de ce champ (par exemple, afin que, simultanément à la recherche, vous puissiez savoir quelles balises ont été trouvées dans les documents qui satisfont la requête de recherche, et en quelle quantité). C'est parfait pour les champs qui sont essentiellement enum; nous utiliserons cette fonctionnalité pour créer des filtres de recherche sympas.
Mais pour que le texte des balises puisse également être recherché par recherche de texte, nous lui ajoutons un sous-champ
"text", configuré par analogie avec nameettextci-dessus - en substance, cela signifie qu'Elasticsearch créera un autre champ "virtuel" sous le nom dans tous les documents qu'il reçoit tags.text, dans lequel il copiera le contenu tags, mais l'indexera selon des règles différentes.
Indexation: remplissage de l'index
Pour indexer un document, il suffit de faire une requête PUT
/-/_create/id-ou, lors de l'utilisation d'un client Python, d'appeler simplement la méthode requise. Notre implémentation ressemblera à ceci:
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
Faites attention au terrain
tags. Bien que nous l'ayons décrit comme contenant un mot-clé, nous n'envoyons pas une seule chaîne, mais une liste de chaînes. Elasticsearch prend en charge cela; notre document sera situé à l'une des valeurs.
Indexation: changement d'index
Pour implémenter une recherche, nous devons connaître le nom de l'index entièrement construit le plus récent. Le mécanisme d'alias nous permet de conserver ces informations du côté d'Elasticsearch.
Un alias est un pointeur vers zéro ou plusieurs index. L'API Elasticsearch vous permet d'utiliser un nom d'alias au lieu d'un nom d'index lors de la recherche (POST
/-/_searchau lieu de POST /-/_search); dans ce cas, Elasticsearch recherchera tous les index pointés par l'alias.
Nous allons créer un alias appelé
cards, qui pointera toujours vers l'index actuel. En conséquence, le passage à l'indice réel après l'achèvement de la construction ressemblera à ceci:
def switch_current_cards_index(self, new_index_name: str):
try:
# , .
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# , - .
# , .
remove_actions = []
#
# .
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
Je n'entrerai pas plus en détail sur l'API d'alias; tous les détails se trouvent dans la documentation .
Ici, il est nécessaire de faire une remarque que dans un service réel très chargé, un tel commutateur peut être assez pénible et il peut être judicieux de faire un préchauffage préliminaire - chargez le nouvel index avec une sorte de pool de requêtes utilisateur enregistrées.
Tout le code qui implémente l'indexation se trouve dans ce commit .
Indexation: ajout de contenu
Pour la démonstration de cet article, j'utilise les données du jeu de données TMDB 5000 Movie . Pour éviter les problèmes de droits d'auteur, je ne fournis que le code de l'utilitaire qui les importe depuis un fichier CSV, que je vous suggère de télécharger vous-même depuis le site Web de Kaggle. Après le téléchargement, exécutez simplement la commande
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
pour créer cinq mille cartes de films et une équipe
docker-compose exec backend python -m tools.build_index
pour créer un index. Veuillez noter que la dernière commande ne construit pas réellement l'index, mais met uniquement la tâche dans la file d'attente des tâches, après quoi elle sera exécutée sur le travailleur - j'ai discuté de cette approche plus en détail dans le dernier article .
docker-compose logs workervous montrer comment le travailleur a essayé!
Avant de commencer, en fait, la recherche, nous voulons voir de nos propres yeux si quelque chose est écrit dans Elasticsearch, et si oui, à quoi ça ressemble!
Le moyen le plus direct et le plus rapide de le faire est d'utiliser l'API HTTP Elasticsearch. Commençons par vérifier où pointe l'alias:
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
Génial, l'index existe! Regardons cela de près:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
Enfin, jetons un coup d'œil à son contenu:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
Au total, notre index est de 4704 documents, et dans le champ
hits(que j'ai sauté car il est trop grand), vous pouvez même voir le contenu de certains d'entre eux. Succès!
Un moyen plus pratique de parcourir le contenu de l'index et généralement toutes sortes de soins avec Elasticsearch serait d'utiliser Kibana . Ajoutons le conteneur à
docker-compose.yml:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
Après une seconde fois,
docker-compose upnous pouvons aller à Kibana à l'adresse localhost:5601(attention, le serveur risque de ne pas démarrer rapidement) et, après une courte configuration, visualiser le contenu de nos index dans une jolie interface web.
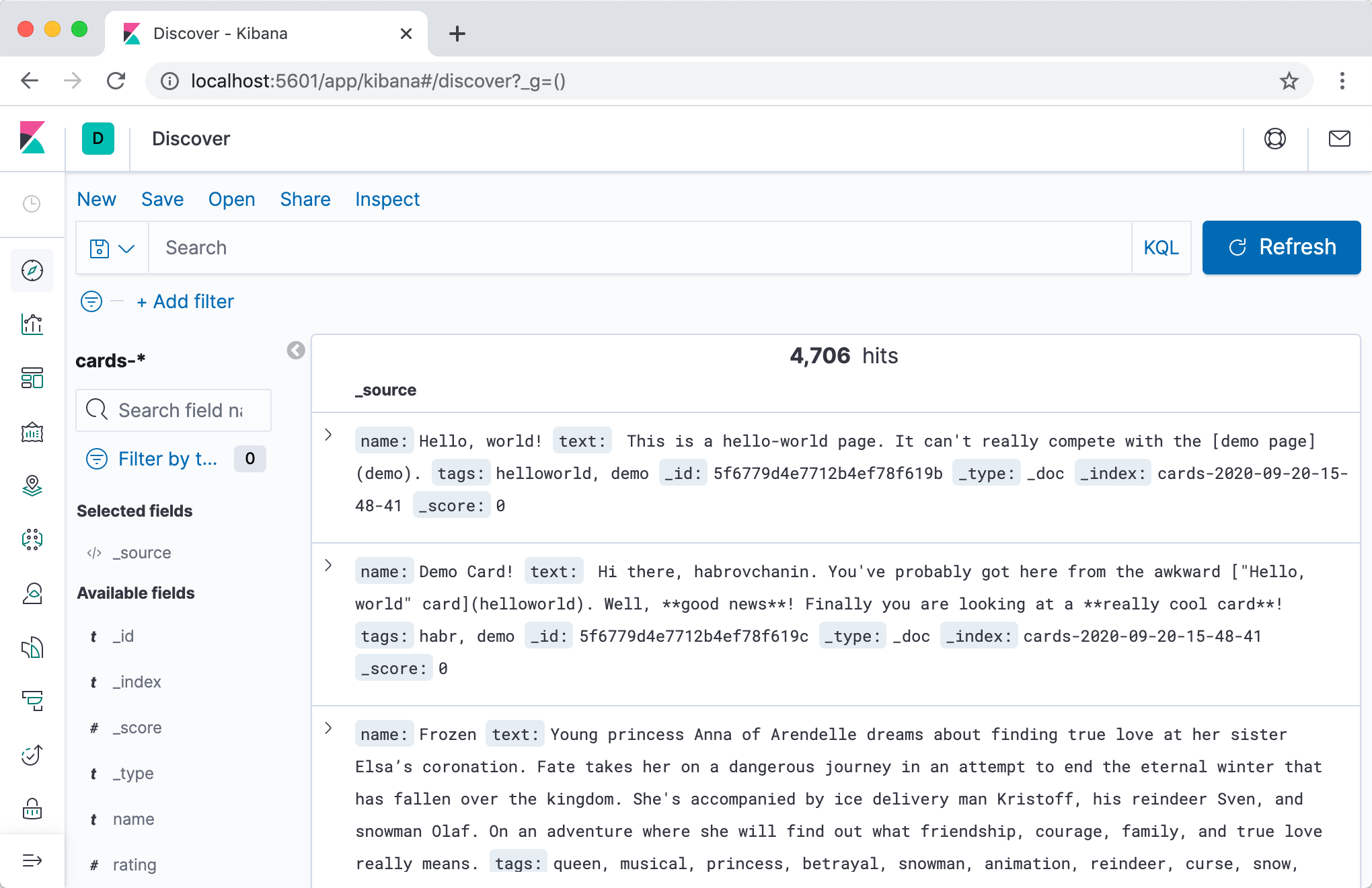
Je recommande vivement l'onglet Outils de développement - pendant le développement, vous devrez souvent effectuer certaines requêtes dans Elasticsearch, et en mode interactif avec saisie automatique et mise en forme automatique, c'est beaucoup plus pratique.
Chercher
Après toutes les préparations incroyablement ennuyeuses, il est temps pour nous d'ajouter des fonctionnalités de recherche à notre application Web!
Divisons cette tâche non triviale en trois étapes et discutons chacune séparément.
- Ajoutez un composant
Searcherresponsable de la logique de recherche au backend . Il formera une requête à Elasticsearch et convertira les résultats en plus digestes pour notre backend. - Ajoutez un point de terminaison à l'API (handle / route / comment l'appelez-vous dans votre entreprise?) Qui
/cards/searcheffectue la recherche. Il appellera la méthode du composantSearcher, traitera les résultats et les renverra au client. - Implémentons l'interface de recherche sur le frontend. Il contactera
/cards/searchlorsque l'utilisateur aura décidé ce qu'il souhaite rechercher et affichera les résultats (et, éventuellement, des contrôles supplémentaires).
Recherche: nous implémentons
Il n'est pas si difficile d'écrire un gestionnaire de recherche que d'en concevoir un. Décrivons le résultat de la recherche et l'interface du gestionnaire et expliquons pourquoi c'est ceci et non différent.
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
Certaines choses sont évidentes. Par exemple, la pagination. Nous sommes une jeune startup ambitieuse et
Certains sont moins évidents. Par exemple, une liste d'identifiants, pas de cartes en conséquence. Elasticsearch stocke tous nos documents par défaut et les renvoie dans les résultats de recherche. Ce comportement peut être désactivé pour économiser sur la taille de l'index de recherche, mais pour nous, il s'agit clairement d'une optimisation prématurée. Alors pourquoi ne pas retourner les cartes tout de suite? Réponse: cela violerait le principe de la responsabilité unique. Peut-être qu'un jour nous mettrons en place une logique complexe dans le gestionnaire de cartes qui traduit les cartes dans d'autres langues, en fonction des paramètres de l'utilisateur. Exactement à ce moment, les données sur la page de la fiche et les données dans les résultats de la recherche seront dispersées, car nous oublierons d'ajouter la même logique au gestionnaire de recherche. Et ainsi de suite.
L'implémentation de cette interface est si simple que j'étais trop paresseux pour écrire cette section :-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any #
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query
# ( match
# query, ).
"multi_match": {
"query": query,
# ^ – .
# , .
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
En fait, nous allons simplement à l'API Elasticsearch et extrayons soigneusement les identifiants des cartes trouvées du résultat.
L'implémentation du point de terminaison est également assez triviale:
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# ,
# ,
# .
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
La mise en œuvre du frontend utilisant ce point de terminaison, bien que volumineuse, est généralement assez simple et dans cet article je ne veux pas m'étendre dessus. Le code entier peut être visualisé dans ce commit .

Jusqu'ici tout va bien, passons à autre chose.
 Recherche: ajout de filtres
Recherche: ajout de filtres
La recherche dans le texte est cool, mais si vous avez déjà cherché des ressources sérieuses, vous avez probablement vu toutes sortes de goodies comme des filtres.
Nos descriptions de films de la base de données TMDB 5000 ont des balises en plus des titres et des descriptions, alors implémentons des filtres par balises pour la formation. Notre objectif est sur la capture d'écran: lorsque vous cliquez sur un tag, seuls les films avec ce tag doivent rester dans les résultats de la recherche (leur numéro est indiqué entre parenthèses à côté).

Pour implémenter des filtres, nous devons résoudre deux problèmes.
- Apprenez à comprendre sur demande quel ensemble de filtres est disponible. Nous ne voulons pas afficher toutes les valeurs de filtre possibles sur chaque écran, car il y en a beaucoup et la plupart conduiront à un résultat vide; vous devez comprendre les balises des documents trouvés sur demande et, idéalement, laisser le N le plus populaire.
- Pour apprendre, en effet, à appliquer un filtre - pour ne laisser dans les résultats de recherche que les documents avec des balises, le filtre par lequel l'utilisateur a choisi.
La seconde dans Elasticsearch est simplement implémentée via l'API de requête (voir les termes de requête ), la première via un mécanisme d'agrégation légèrement moins trivial .
Nous devons donc savoir quelles balises se trouvent dans les cartes trouvées et être en mesure de filtrer les cartes avec les balises nécessaires. Tout d'abord, mettons à jour la conception du gestionnaire de recherche:
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
Passons maintenant à la mise en œuvre. La première chose à faire est de créer une agrégation par le champ
tags:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
Désormais, dans le résultat de la recherche d'Elasticsearch, un champ viendra à
aggregationspartir duquel, à l'aide d'une clé, TAGS_AGGREGATION_NAMEnous pouvons obtenir des compartiments contenant des informations sur les valeurs du champ tagspour les documents trouvés et la fréquence à laquelle elles se produisent. Extrayons ces données et renvoyons-les comme prévu ci-dessus:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
L'ajout d'une application de filtrage est la partie la plus simple:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
Les sous-requêtes incluses dans la clause must sont obligatoires, mais elles seront également prises en compte lors du calcul de la vitesse des documents et, en conséquence, du classement; si jamais nous ajoutons des conditions supplémentaires aux textes, il vaut mieux les ajouter ici. Les sous-requêtes de la clause de filtrage filtrent uniquement sans affecter la vitesse et le classement.
Il reste à mettre en œuvre
_make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
Encore une fois, je ne m'attarderai pas sur la partie frontale; tout le code est dans ce commit .
Variant
Ainsi, notre recherche recherche les cartes, les filtre en fonction d'une liste de balises donnée et les affiche dans un certain ordre. Mais lequel? La commande est très importante pour une recherche pratique, mais tout ce que nous avons fait lors de notre contentieux en termes de commande a été laissé entendre à Elasticsearch qu'il est plus rentable de trouver des mots dans l'en-tête de la carte que dans la description ou les balises en précisant la priorité
^3dans la requête multi-match.
Malgré le fait que, par défaut, Elasticsearch classe les documents avec une formule assez délicate basée sur TF-IDF, pour notre startup imaginaire ambitieuse, cela ne suffit guère. Si nos documents sont des marchandises, nous devons être en mesure de rendre compte de leurs ventes; s'il s'agit d'un contenu généré par l'utilisateur, être capable de prendre en compte sa fraîcheur, etc. Mais nous ne pouvons pas simplement trier par le nombre de ventes / date d'ajout, car alors nous ne prendrons pas en compte la pertinence par rapport à la requête de recherche.
Le classement est un domaine technologique vaste et déroutant qui ne peut pas être couvert dans une section à la fin de cet article. Je passe donc ici aux gros traits; Je vais essayer de vous dire dans les termes les plus généraux comment le classement de qualité industrielle peut être organisé dans la recherche, et je vais révéler quelques détails techniques sur la façon dont il peut être implémenté avec Elasticsearch.
La tâche de classement est très complexe, il n'est donc pas surprenant que l'une des principales méthodes modernes de résolution de ce problème soit l'apprentissage automatique. L'application des technologies d'apprentissage automatique au classement est appelée collectivement apprendre à classer .
Un processus typique ressemble à ceci.
Nous décidons de ce que nous voulons classer . Nous mettons les entités qui nous intéressent dans l'index, apprenons à obtenir un top raisonnable (par exemple, un tri et une coupure simples) de ces entités pour une requête de recherche donnée, et maintenant nous voulons apprendre à la classer de manière plus intelligente.
Déterminer comment nous voulons nous classer... Nous décidons sur quelle caractéristique nous voulons classer nos résultats en fonction des objectifs commerciaux de notre service. Par exemple, si nos entités sont des produits que nous vendons, nous pouvons souhaiter les trier par ordre décroissant de probabilité d'achat; si les mèmes - par probabilité d'aimer ou de partager, et ainsi de suite. Nous ne savons bien sûr pas comment calculer ces probabilités - au mieux nous pouvons estimer, et même alors seulement pour les anciennes entités pour lesquelles nous avons suffisamment de statistiques - mais nous allons essayer d'apprendre au modèle à les prédire sur la base de signes indirects.
Extraire des signes... Nous proposons un ensemble de fonctionnalités pour nos entités qui pourraient nous aider à évaluer la pertinence des entités pour les requêtes de recherche. En plus du même TF-IDF, qui sait déjà calculer Elasticsearch pour nous, un exemple typique est le CTR (taux de clics): nous prenons les logs de notre service pendant tout le temps, pour chaque paire d'entité + requête de recherche nous comptons combien de fois l'entité est apparue dans les résultats de recherche pour cette requête et combien de fois il a été cliqué, nous divisons l'une par l'autre, et voilà - l'estimation la plus simple de la probabilité de clic conditionnelle est prête. Nous pouvons également proposer des traits spécifiques à l'utilisateur et des traits associés à une entité utilisateur pour personnaliser les classements. Après avoir trouvé des signes, nous écrivons du code qui les calcule, les met dans une sorte de stockage et sait comment les donner en temps réel pour une requête de recherche donnée, un utilisateur et un ensemble d'entités.
Rassembler un ensemble de données d'entraînement . Il existe de nombreuses options, mais toutes, en règle générale, sont formées à partir des journaux d'événements "bons" (par exemple, un clic puis un achat) et "mauvais" (par exemple, un clic et un retour au problème) dans notre service. Lorsque nous avons collecté un ensemble de données, qu'il s'agisse d'une liste d'énoncés «l'évaluation de la pertinence du produit X pour la requête Q est approximativement égale à P», d'une liste de paires «le produit X est plus pertinent pour le produit Y pour la requête Q» ou d'un ensemble de listes «pour la requête Q, les produits P 1 , P 2 , ... se classent correctement comme -que ", nous relevons les signes correspondants à toutes les lignes qui y apparaissent.
Nous formons le modèle . Voici tous les classiques du ML: train / test, hyperparamètres, recyclage,
Nous intégrons le modèle . Il nous reste à visser en quelque sorte le calcul du modèle à la volée pour tout le top, pour que les résultats déjà classés parviennent à l'utilisateur. Il existe de nombreuses options; à des fins d'illustration, je vais (encore) me concentrer sur un simple plugin Elasticsearch Learning to Rank .
Classement: Elasticsearch Learning to Rank Plugin
Elasticsearch Learning to Rank est un plugin qui ajoute à Elasticsearch la possibilité de calculer un modèle ML dans le SERP et de classer immédiatement les résultats en fonction des taux calculés. Cela nous aidera également à obtenir des fonctionnalités identiques à celles utilisées en temps réel, tout en réutilisant les capacités d'Elasticsearch (TF-IDF et autres).
Tout d'abord, nous devons connecter le plugin dans notre conteneur avec Elasticsearch. Nous avons besoin d'un simple Dockerfile
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
et les changements connexes
docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
Nous avons également besoin de la prise en charge des plugins dans le client Python. Avec étonnement, j'ai trouvé que la prise en charge de Python n'est pas complète avec le plug-in, donc spécialement pour cet article, je l'ai lavé . Ajoutez et mettez
elasticsearch_ltrà requirements.txtniveau le client dans le câblage:
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
Classement: signes de sciage
Chaque requête dans Elasticsearch renvoie non seulement une liste d'identifiants de documents trouvés, mais également certains d'entre eux bientôt (comment traduiriez-vous le mot score en russe?). Donc, s'il s'agit d'une requête de correspondance ou de correspondance multiple que nous utilisons, alors rapide est le résultat du calcul de la formule très délicate impliquant TF-IDF; si la requête booléenne est une combinaison de taux de requête imbriqués; si la requête de score de fonction- le résultat du calcul d'une fonction donnée (par exemple, la valeur d'un champ numérique dans un document), et ainsi de suite. Le plugin ELTR nous offre la possibilité d'utiliser la vitesse de n'importe quelle demande comme signe, nous permettant de combiner facilement des données sur la façon dont le document correspond à la demande (via une requête multi-correspondance) et des statistiques pré-calculées que nous mettons dans le document à l'avance (via la requête de score de fonction) ...
Puisque nous avons entre nos mains une base de données TMDB 5000, qui contient des descriptions de films et, entre autres, leurs notes, prenons la note comme une caractéristique précalculée exemplaire.
Dans ce commitJ'ai ajouté une infrastructure de base pour stocker des fonctionnalités sur le backend de notre application Web et pris en charge le chargement de la note à partir du fichier vidéo. Afin de ne pas vous forcer à lire un autre paquet de code, je décrirai le plus basique.
- Nous stockerons les fonctionnalités dans une collection séparée et les obtiendrons par un gestionnaire distinct. Décharger toutes les données dans une seule entité est une mauvaise pratique.
- Nous contacterons ce responsable au stade de l'indexation et placerons tous les signes disponibles dans les documents indexés.
- Pour connaître le schéma d'index, nous devons connaître la liste de toutes les fonctionnalités existantes avant de commencer à créer l'index. Nous allons coder en dur cette liste pour le moment.
- Comme nous n'allons pas filtrer les documents par valeurs de caractéristiques, mais que nous allons les extraire uniquement de documents déjà trouvés pour le calcul du modèle, nous désactiverons la construction d'indices inverses par de nouveaux champs avec une option
index: falsedans le schéma et économiserons un peu d'espace grâce à cela.
Classement: collecte de l'ensemble de données
Comme, d'une part, nous n'avons pas de production, et d'autre part, les marges de cet article sont trop petites pour une histoire sur la télémétrie, Kafka, NiFi, Hadoop, Spark et la création de processus ETL, je vais simplement générer des vues et des clics aléatoires pour nos cartes et une sorte de requêtes de recherche. Après cela, vous devrez calculer les caractéristiques des paires carte-demande résultantes.
Il est temps d'approfondir l'API du plugin ELTR. Pour calculer les fonctionnalités, nous devrons créer une entité de magasin de fonctionnalités (pour autant que je sache, il ne s'agit en fait que d'un index dans Elasticsearch dans lequel le plugin stocke toutes ses données), puis créer un ensemble de fonctionnalités - une liste de fonctionnalités avec une description de la façon de calculer chacune d'elles. Après cela, il nous suffira d'aller sur Elasticsearch avec une demande spéciale pour obtenir un vecteur de valeurs de fonctionnalités pour chaque entité trouvée en conséquence.
Commençons par créer un ensemble de fonctionnalités:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# feature store ,
# ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# feature set !
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
#
# ,
# ,
# .
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR
# , .
# , ,
# ,
# match query.
"name": "{{query}}"
}
}),
# , .
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
#
# function score.
# -
# , 0.
# (
# !)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
Maintenant - une fonction qui calcule les caractéristiques pour une requête et des cartes données:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# ,
# — ,
# .
# ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# — ,
# SLTR.
#
# feature set.
# ( ,
# filter, .)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# .
# , ,
#
# {{query}}.
"query": query
}
}
}
]
}
},
#
# .
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# (
# ) .
# ( ,
# , Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
Un script simple qui accepte CSV avec des demandes et des cartes d'identité en entrée et en sortie CSV avec les fonctionnalités suivantes:
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
Enfin, vous pouvez tout exécuter!
# feature set
docker-compose exec backend python -m tools.initialize_search_ranking
#
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
#
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
Maintenant, nous avons deux fichiers - avec des événements et des signes - et nous pouvons commencer la formation.
Classement: former et mettre en œuvre le modèle
Sautons les détails du chargement des ensembles de données (le script peut être consulté en entier dans ce commit ) et allons droit au but.
# backend/tools/train_model.py
...
if __name__ == "__main__":
args = parser.parse_args()
feature_names, features = read_features(args.features)
events = read_events(args.events)
# train test 4 1.
all_queries = set(events.keys())
train_queries = random.sample(all_queries, int(0.8 * len(all_queries)))
test_queries = all_queries - set(train_queries)
# DMatrix — , xgboost.
#
# . 1, ,
# 0, ( . ).
train_dmatrix = make_dmatrix(train_queries, events, feature_names, features)
test_dmatrix = make_dmatrix(test_queries, events, feature_names, features)
# !
#
# ML,
# XGBoost.
param = {
"max_depth": 2,
"eta": 0.3,
"objective": "binary:logistic",
"eval_metric": "auc",
}
num_round = 10
booster = xgboost.train(param, train_dmatrix, num_round, evals=((train_dmatrix, "train"), (test_dmatrix, "test")))
# .
booster.dump_model(args.output, dump_format="json")
# , :
# ROC-.
xgboost.plot_importance(booster)
plt.figure()
build_roc(test_dmatrix.get_label(), booster.predict(test_dmatrix))
plt.show()
lancement
python backend/tools/train_search_ranking_model.py \
--events ~/Downloads/habr-app-demo-dataset-events.csv \
--features ~/Downloads/habr-app-demo-dataset-features.csv \
-o ~/Downloads/habr-app-demo-model.xgb
Veuillez noter que puisque nous avons exporté toutes les données nécessaires avec les scripts précédents, ce script n'a plus besoin d'être exécuté dans docker - il doit être exécuté sur votre machine, après avoir installé
xgboostet sklearn. De même, en production réelle, les scripts précédents devraient être exécutés quelque part où il y a un accès à l'environnement de production, mais celui-ci ne l'est pas.
Si tout est fait correctement, le modèle s'entraînera avec succès et nous verrons deux belles photos. Le premier est un graphique de la signification des caractéristiques: bien

que les événements aient été générés de manière aléatoire,
combined_tf_idfs'est avéré être beaucoup plus significatif que d'autres - parce que j'ai fait une astuce et abaissé artificiellement la probabilité d'un clic pour les cartes qui sont inférieures dans les résultats de recherche, classées à l'ancienne. Le fait que le modèle l'ait remarqué est un bon signe et un signe que nous n'avons pas commis d'erreurs complètement stupides dans le processus d'apprentissage.
Le deuxième graphique est la courbe ROC :

la ligne bleue est au-dessus de la ligne rouge, ce qui signifie que notre modèle prédit les étiquettes un peu mieux qu'un tirage au sort. (La courbe de l'ingénieur ML de l'ami de maman devrait presque toucher le coin supérieur gauche.)
La question est assez petite - nous ajoutons un script pour remplir le modèle , le remplissons et ajoutons un petit nouvel élément à la requête de recherche - rescoring:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -27,6 +30,19 @@ class ElasticsearchSearcher(Searcher):
"filter": list(self._make_filter_queries(tags, ids)),
}
},
+ "rescore": {
+ "window_size": 1000,
+ "query": {
+ "rescore_query": {
+ "sltr": {
+ "params": {
+ "query": query
+ },
+ "model": self.ranking_manager.get_current_model_name()
+ }
+ }
+ }
+ },
"aggregations": {
self.TAGS_AGGREGATION_NAME: {
"terms": {"field": "tags"}
Maintenant, après qu'Elasticsearch ait effectué la recherche dont nous avons besoin et classe les résultats avec son algorithme (assez rapide), nous prendrons les 1000 premiers résultats et les reclassifierons en utilisant notre formule (relativement lente) apprise par machine. Succès!
Conclusion
Nous avons pris notre application Web minimaliste et sommes passés de l'absence de fonction de recherche en soi à une solution évolutive avec de nombreuses fonctionnalités avancées. Ce n'était pas si facile à faire. Mais ce n'est pas si difficile non plus! L'application finale se trouve dans le référentiel sur Github dans une branche avec un nom modeste
feature/searchet nécessite Docker et Python 3 avec des bibliothèques d'apprentissage automatique pour fonctionner.
J'ai utilisé Elasticsearch pour montrer comment cela fonctionne en général, quels problèmes sont rencontrés et comment ils peuvent être résolus, mais ce n'est certainement pas le seul outil à choisir. Solr , les index de texte intégral PostgreSQL et d'autres moteurs méritent également votre attention lorsque vous choisissez sur quoi bâtir votre entreprise de
Et, bien sûr, cette solution ne prétend pas être complète et prête pour la production, mais est purement une illustration de la façon dont tout peut être fait. Vous pouvez l'améliorer presque à l'infini!
- Indexation incrémentielle. Lors de la modification de nos cartes,
CardManageril serait bon de les mettre immédiatement à jour dans l'index. Afin deCardManagerne pas savoir que nous avons aussi une recherche dans le service, et pour se passer de dépendances cycliques, il va falloir visser l' inversion de dépendance sous une forme ou une autre. - Pour l'indexation dans notre cas particulier, MongoDB est fourni avec Elasticsearch, vous pouvez utiliser des solutions toutes faites comme mongo-connector .
- , — Elasticsearch .
- , , .
- , , . -, -, - … !
- ( , ), ( ). , .
- , , .
- Orchestrer un cluster de nœuds avec partitionnement et réplication est un plaisir à part.
Mais pour garder l'article lisible en taille, je m'arrêterai là et vous laisserai seul avec ces défis. Merci pour l'attention!