
L'équipe investit beaucoup de travail, d'efforts et de ressources dans chaque changement dans le jeu: parfois, le développement d'une nouvelle fonctionnalité ou d'un nouveau niveau prend plusieurs mois. La tâche de l'analyste est de minimiser les risques liés à la mise en œuvre de tels changements et d'aider l'équipe à prendre la bonne décision concernant le développement futur du projet.
Lors de l'analyse des décisions, il est important d'être guidé par des données statistiquement significatives qui correspondent aux préférences du public, plutôt que par des hypothèses intuitives. Les tests A / B aident à obtenir ces données et à les évaluer.
6 étapes «faciles» des tests A / B
Pour le terme de recherche «A / B testing» ou «split testing», la plupart des sources proposent quelques étapes «simples» pour réussir un test. Il y a six étapes de ce type dans ma stratégie.
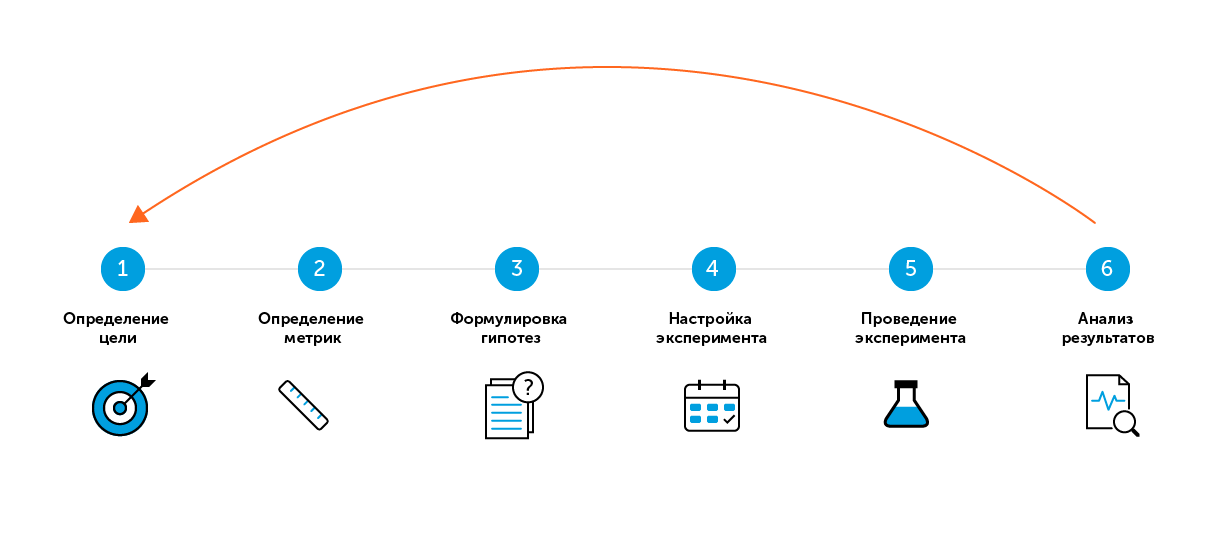
À première vue, tout est simple:
- il y a groupe A, contrôle, aucun changement dans le jeu;
- il y a le groupe B, test, avec des changements. Par exemple, de nouvelles fonctionnalités ont été ajoutées, la difficulté des niveaux a été augmentée, le tutoriel a été modifié;
- exécutez le test et voyez quelle variante a les meilleures performances.
En pratique, c'est plus difficile. Pour que l'équipe mette en œuvre la meilleure solution, je dois, en tant qu'analyste, répondre à ma confiance dans les résultats des tests. Traitons les difficultés étape par étape.
Étape 1. Déterminez l'objectif
D'une part, nous pouvons tester tout ce qui vient à l'esprit de chaque membre de l'équipe - de la couleur du bouton aux niveaux de difficulté du jeu. La capacité technique de réaliser des tests fractionnés est intégrée à nos produits au stade de la conception.
D'autre part, il est important de prioriser toutes les suggestions pour améliorer le jeu en fonction du niveau de l'effet sur la métrique cible. Par conséquent, nous élaborons d'abord un plan pour lancer le split testing de l'hypothèse la plus prioritaire à la moindre.
Nous essayons de ne pas exécuter plusieurs tests A / B en parallèle afin de comprendre exactement laquelle des nouvelles fonctionnalités a affecté la métrique cible. Il semble qu'avec cette stratégie, il faudra plus de temps pour tester toutes les hypothèses. Mais la priorisation aide à éliminer les hypothèses peu prometteuses au stade de la planification.
Nous obtenons les données qui reflètent le mieux l'effet de changements spécifiques et nous ne perdons pas de temps à mettre en place des tests aux effets discutables.
Nous discutons définitivement du plan de lancement avec l'équipe, car le centre d'intérêt change à différentes étapes du cycle de vie du produit. Au début du projet, il s'agit généralement de Rétention D1 - le pourcentage de joueurs qui sont revenus au jeu le lendemain de son installation. À des étapes ultérieures, il peut s'agir de mesures de rétention ou de monétisation: conversion, ARPU et autres.
Exemple.Les mesures de rétention nécessitent une attention particulière après la publication d'un projet dans le lancement progressif. À ce stade, soulignons l'un des problèmes possibles: la rétention D1 n'atteint pas le niveau de référence de l'entreprise pour un genre de jeu particulier. Il est nécessaire d'analyser l'entonnoir de passage des premiers niveaux. Disons que vous avez remarqué une forte baisse de joueurs entre le début et l'achèvement du 3e niveau - un faible taux d'achèvement du 3e niveau.
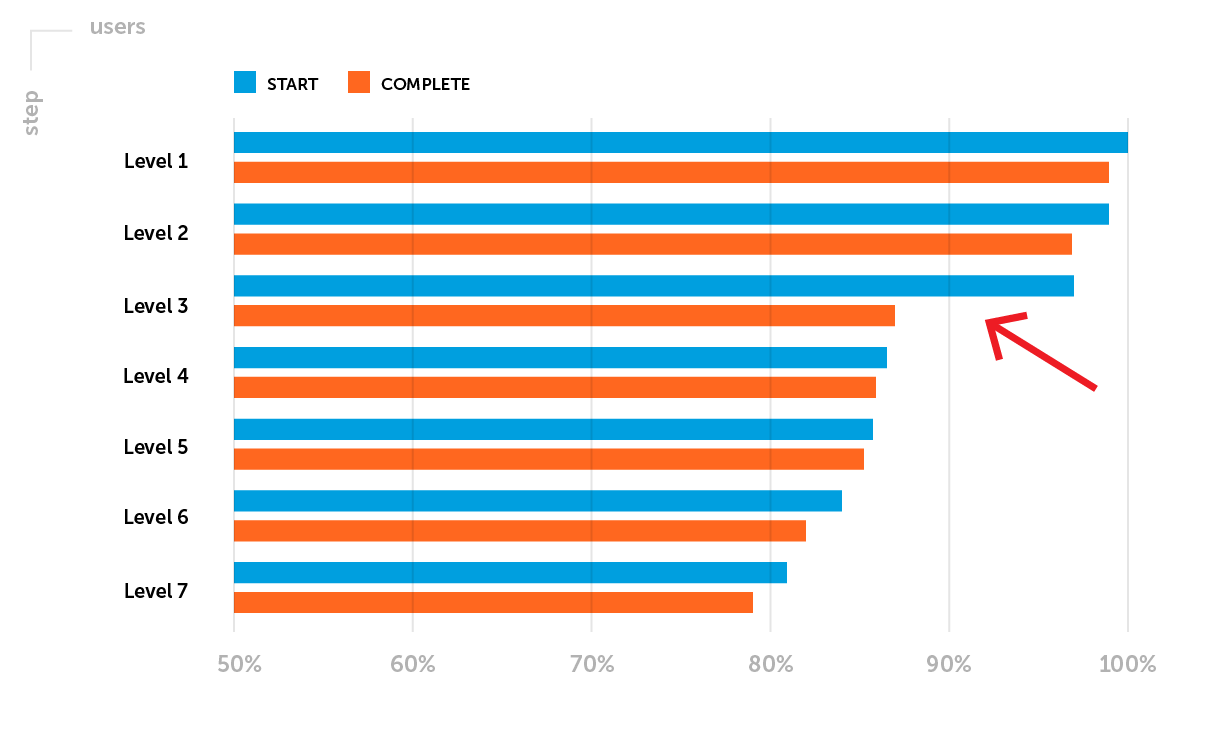
Le but du test A / B prévu : augmenter la rétention D1 en augmentant la proportion de joueurs ayant réussi le niveau 3.
Étape 2. Définition des métriques
Avant de commencer le test A / B, nous déterminons le paramètre surveillé - nous sélectionnons la métrique, les changements dans lesquels montreront si la nouvelle fonctionnalité du jeu est plus efficace que la première.
Il existe deux types de métriques:
- quantitatif - la durée moyenne de la session, la valeur du contrôle moyen, le temps nécessaire pour terminer le niveau, la quantité d'expérience, etc.
- qualité - Rétention, taux de conversion et autres.
Le type de métrique influe sur le choix de la méthode et des outils pour évaluer la signification des résultats.
Il est probable que la fonctionnalité testée n'affectera pas une cible, mais un certain nombre de mesures. Par conséquent, nous examinons les changements en général, mais n'essayons pas de trouver «quoi que ce soit» lorsqu'il n'y a pas de signification statistique dans l'évaluation de la métrique cible.
Selon l'objectif de la première étape, pour le prochain test A / B, nous évaluerons le taux d'achèvement du 3ème niveau - une métrique qualitative.
Étape 3. Formulez une hypothèse
Chaque test A / B teste une hypothèse générale, qui est formulée avant le lancement. Nous répondons à la question: à quels changements attendons-nous dans le groupe test? Le libellé ressemble généralement à ceci:
"Nous nous attendons à ce que (l'impact) provoquera (un changement)"
Les méthodes statistiques fonctionnent de manière opposée - nous ne pouvons pas les utiliser pour prouver que l'hypothèse est correcte. Par conséquent, après avoir formulé une hypothèse générale, deux hypothèses statistiques sont déterminées. Ils aident à comprendre que la différence observée entre le groupe témoin A et le groupe test B est un accident ou le résultat de changements.
Dans notre exemple:
- Hypothèse nulle ( H0 ): la réduction de la difficulté de niveau 3 n'affectera pas la proportion d'utilisateurs qui réussissent le niveau 3. Le taux d'achèvement du niveau 3 pour les groupes A et B n'est pas vraiment différent et les différences observées sont aléatoires.
- Hypothèse alternative ( H1 ): réduire la difficulté du niveau 3 augmentera la proportion d'utilisateurs qui réussissent le niveau 3. Le taux d'achèvement du niveau 3 est plus élevé dans le groupe B que dans le groupe A, et ces différences sont le résultat de changements.
À ce stade, en plus de formuler une hypothèse, il est nécessaire d'évaluer l'effet attendu.
Hypothèse: "Nous prévoyons qu'une diminution de la complexité du 3ème niveau entraînera une augmentation du taux d'achèvement du 3ème niveau de 85% à 95%, soit de plus de 11%."
(95% -85%) / 85% = 0,117 => 11,7%
Dans cet exemple, lors de la détermination du taux d'achèvement attendu du niveau 3, nous visons à le rapprocher du taux d'achèvement moyen des niveaux de départ.
Étape 4. Mise en place de l'expérience
1. Définissez les paramètres des groupes A / B avant de commencer l'expérience: pour quel public nous lançons le test, pour quelle proportion de joueurs, quels paramètres nous définissons dans chaque groupe.
2. Nous vérifions la représentativité de l'échantillon dans son ensemble et l'homogénéité des échantillons dans les groupes. Vous pouvez pré-exécuter un test A / A pour évaluer ces paramètres - un test dans lequel les groupes de test et de contrôle ont la même fonctionnalité. Le test A / A permet de s'assurer que les métriques cibles ne sont pas statistiquement significatives dans les deux groupes. En cas de différences, un test A / B avec de tels paramètres - taille de l'échantillon et niveau de confiance - ne peut pas être exécuté.
L'échantillon ne sera pas parfaitement représentatif, mais nous prêtons toujours attention à la structure des utilisateurs en fonction de leurs caractéristiques - nouvel / ancien utilisateur, niveau dans le jeu, pays. Tout est lié à l'objectif du test A / B et est négocié à l'avance. Il est important que la structure des utilisateurs de chaque groupe soit conditionnellement la même.
Il y a deux pièges potentiellement dangereux ici:
- Des métriques élevées dans les groupes pendant l'expérience peuvent être une conséquence de l'attraction d'un bon trafic. Le trafic est bon si les taux d'engagement sont élevés. Le mauvais trafic est la cause la plus fréquente de baisse des métriques.
- Hétérogénéité de l'échantillon. Disons que le projet de notre exemple est développé pour un public anglophone. Cela signifie que nous devons éviter une situation où davantage d'utilisateurs de pays où l'anglais n'est pas la langue prédominante tomberont dans l'un des groupes.
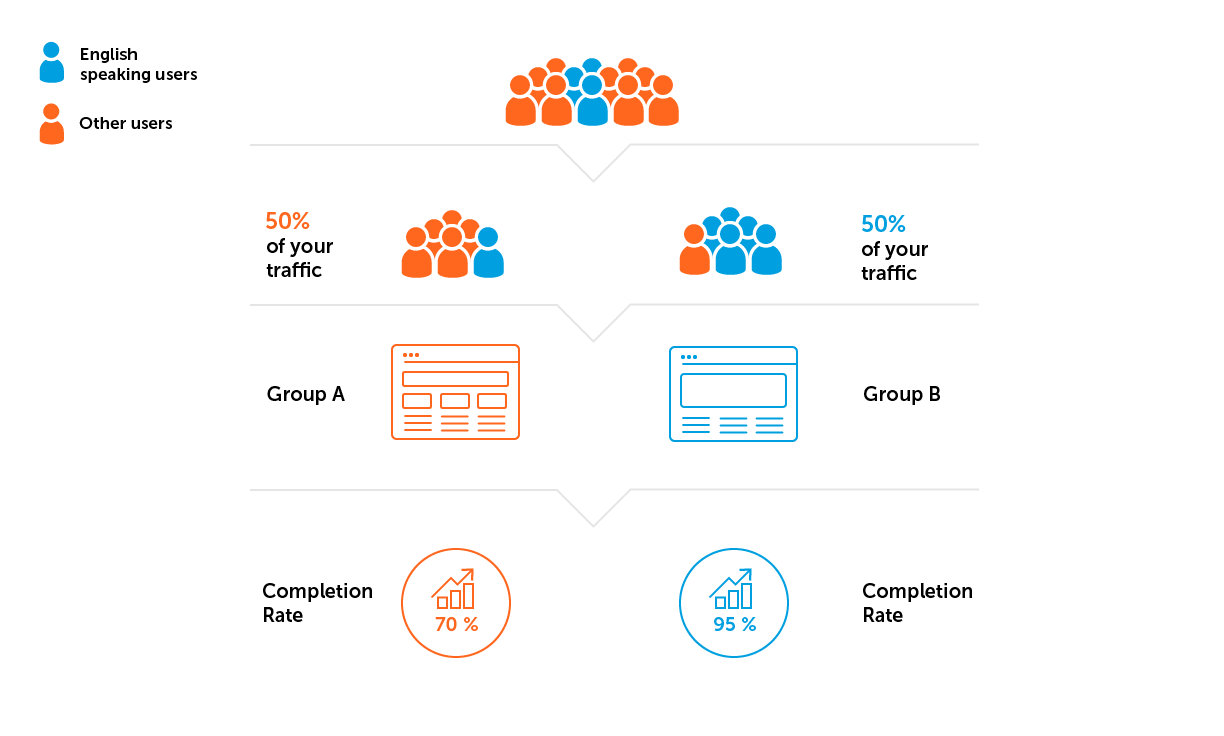
3. Calculez la taille de l'échantillon et la durée de l'expérience.
Il semblerait que le moment soit transparent, compte tenu de l'énorme ensemble de calculatrices en ligne.
Cependant, leur utilisation nécessite la saisie d'informations initiales spécifiques. Pour sélectionner l'option de calculatrice en ligne appropriée, souvenez-vous des types de données et comprenez les termes suivants.
- Grand public - tous les utilisateurs auxquels les conclusions du test A / B seront distribuées à l'avenir.
- Échantillon - utilisateurs qui sont réellement testés. Sur la base des résultats de l'analyse de l'échantillon, des conclusions sont tirées sur le comportement de l'ensemble de la population générale.
- , . — , , , .
- , . .
- (α) — , (0), .
- (1-α) — , , .
- (1-β) — , , .
La combinaison de ces paramètres vous permet de calculer la taille d'échantillon requise dans chaque groupe et la durée du test.
Dans une calculatrice en ligne, vous pouvez jouer avec les données d'entrée pour comprendre la nature de leurs relations.
Un exemple . Utilisons la calculatrice Optimizely pour calculer la taille de l'échantillon pour un taux de conversion de 1%. Considérez que la taille de l'effet attendu est de 5% à un niveau de confiance de 95% (l'indicateur est calculé comme 1-α). Veuillez noter que dans l'interface de ce calculateur, le terme Signification statistique est utilisé pour signifier «niveau de confiance» à un niveau de signification de 5%.
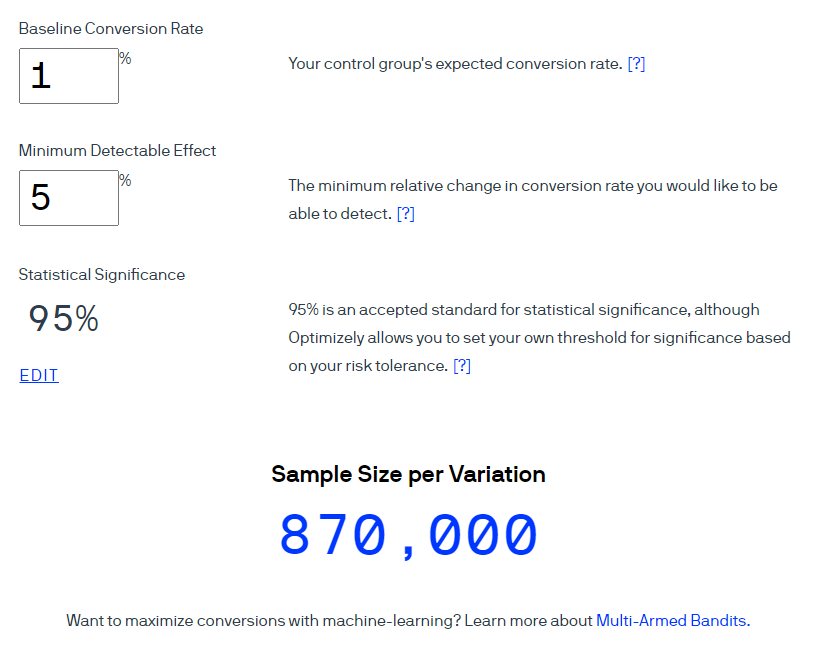
Optimizely affirme que 870 000 utilisateurs devraient être inclus dans chaque groupe.
Conversion de la taille de l'échantillon en durée approximative du test - deux calculs simples.
Calcul # 1. Taille de l'échantillon × nombre de groupes dans l'expérience = nombre total d'utilisateurs requis
Calcul # 2. Nombre total d'utilisateurs requis ÷ nombre moyen d'utilisateurs par jour = nombre approximatif de jours de l'expérience
Si le premier groupe requiert 870 000 utilisateurs, alors le total le nombre d'utilisateurs sera de 1 740 000. Compte tenu du trafic de 1 000 joueurs par jour, le test devrait durer 1 740 jours. Cette durée n'est pas justifiée. À ce stade, nous révisons généralement l'hypothèse, les données de base et la pertinence du test.
Dans notre exemple avec une amélioration de niveau 3, la conversion est la proportion de ceux qui ont réussi le niveau 3. Autrement dit, le taux de conversion est de 85%, nous voulons augmenter cet indicateur d'au moins 11%. Avec un niveau de confiance de 95%, nous obtenons 130 utilisateurs par groupe.

Avec le même volume de trafic de 1000 utilisateurs, le test, en gros, peut être complété en moins d'une journée. Cette conclusion est fondamentalement erronée, car elle ne prend pas en compte la saisonnalité hebdomadaire. Le comportement des utilisateurs diffère selon les jours de la semaine, par exemple, il peut changer les jours fériés. Et dans certains projets, cette influence est très forte, dans d'autres, elle est à peine perceptible. Ce n'est pas une condition nécessaire dans tous les projets et pas pour tous les tests, mais sur les projets avec lesquels j'ai travaillé, la saisonnalité hebdomadaire des KPI a toujours été observée.
Par conséquent, nous arrondissons la durée du test à des semaines pour tenir compte de la saisonnalité. Le plus souvent, notre cycle de test dure une à deux semaines, selon le type de test A / B.
Étape 5. Réalisation d'une expérience
Après avoir démarré un test A / B, vous voulez immédiatement regarder les résultats, mais la plupart des sources interdisent strictement de le faire afin d'exclure le problème de peeking. Pour expliquer l'essence du problème en termes simples, à mon avis, personne n'a réussi jusqu'à présent. Les auteurs de tels articles fondent leurs preuves sur l'évaluation des probabilités, divers résultats de la modélisation mathématique, qui entraînent le lecteur dans la zone des «formules mathématiques complexes». Leur principale conclusion est un fait presque indiscutable: ne regardez pas les données tant que l'échantillon requis n'a pas été typé et que le nombre de jours requis s'est écoulé après le début du test. En conséquence, de nombreuses personnes interprètent mal le problème du "regard" et suivent les recommandations à la lettre.
Nous avons mis en place les processus afin que nous puissions voir des données à jour pour le suivi des projets KPI sur une base quotidienne. Dans des tableaux de bord pré-préparés, nous suivons la progression de l'expérimentation dès le début: nous vérifions si les groupes sont recrutés uniformément, s'il y a des problèmes critiques après le démarrage du test qui peuvent affecter les résultats, etc.
La règle principale est de ne pas tirer de conclusions prématurées. Toutes les conclusions sont formulées conformément à la conception établie du test A / B et sont résumées dans un rapport détaillé. Nous suivons l'évolution de l'indicateur depuis le lancement du test A / B.
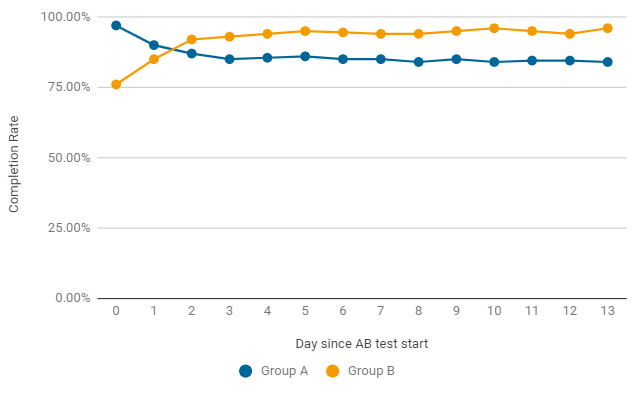
Un exemple, comme dans le test A / B, le taux d'achèvement peut changer de jour en jour.Dans les deux premiers jours après le lancement, la version du jeu a gagné sans changement (groupe A), mais cela s'est avéré être juste un accident. Déjà après le deuxième jour, l'indicateur du groupe B obtient des résultats toujours meilleurs. Pour terminer le test, il faut non seulement une signification statistique, mais aussi une stabilité, nous attendons donc la fin du test.
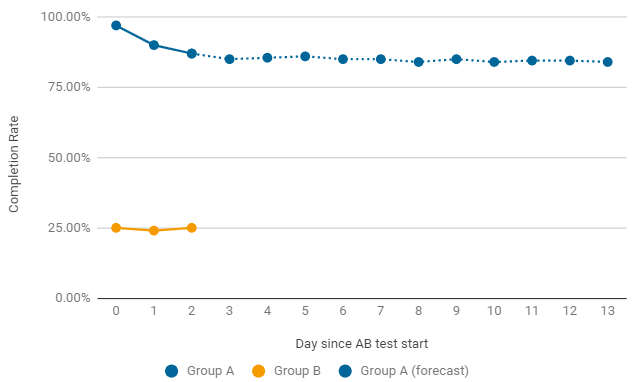
Un exemple de cas où il vaut la peine de mettre fin prématurément à un test A / B. Si, après le lancement, l'un des groupes donne des tarifs extrêmement bas, on cherche immédiatement les raisons d'une telle baisse. Les plus courantes sont les erreurs dans la configuration et les paramètres du niveau de jeu. Dans ce cas, le test en cours se termine prématurément et un nouveau avec des correctifs est lancé.
Étape 6. Analyse des résultats
Le calcul des paramètres clés n'est pas particulièrement difficile, mais l'évaluation de l'importance des résultats obtenus est un problème distinct.
Les calculatrices en ligne peuvent être utilisées pour tester la signification statistique des résultats lors de l'évaluation des mesures de qualité telles que la rétention et la conversion.
Mes 3 meilleurs calculateurs en ligne pour des tâches comme celle-ci:
- Les outils Awesome A / B d'Evan sont l'un des plus populaires. Il met en œuvre plusieurs méthodes pour évaluer la signification d'un test. Lors de son utilisation, vous devez comprendre clairement l'essence de chaque paramètre saisi, interpréter indépendamment les résultats et formuler des conclusions.
- , A/B Testguide. , . — , .
- A/B Testing Calculator Neilpatel. -, .
Un exemple . Pour l'analyse de tels tests A / B, nous disposons d'un tableau de bord qui affiche toutes les informations nécessaires pour tirer des conclusions, et met automatiquement en évidence le résultat avec un changement significatif de la cible.

Voyons comment utiliser des calculatrices pour tirer des conclusions sur ce test A / B.
Donnée initiale:
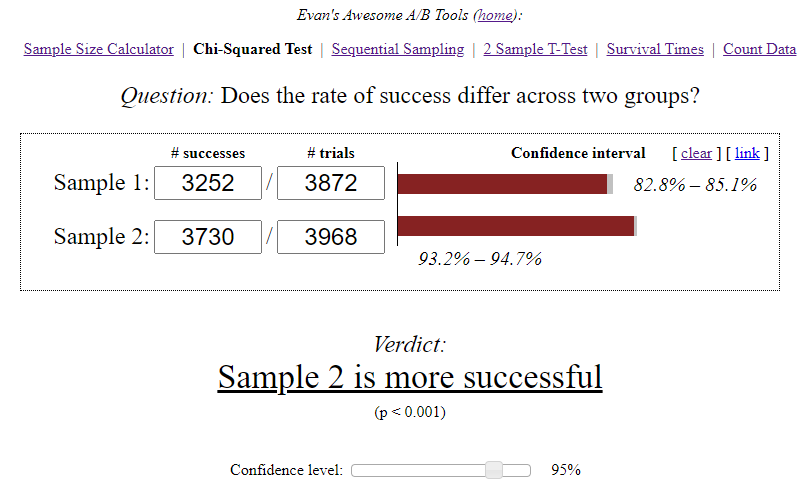
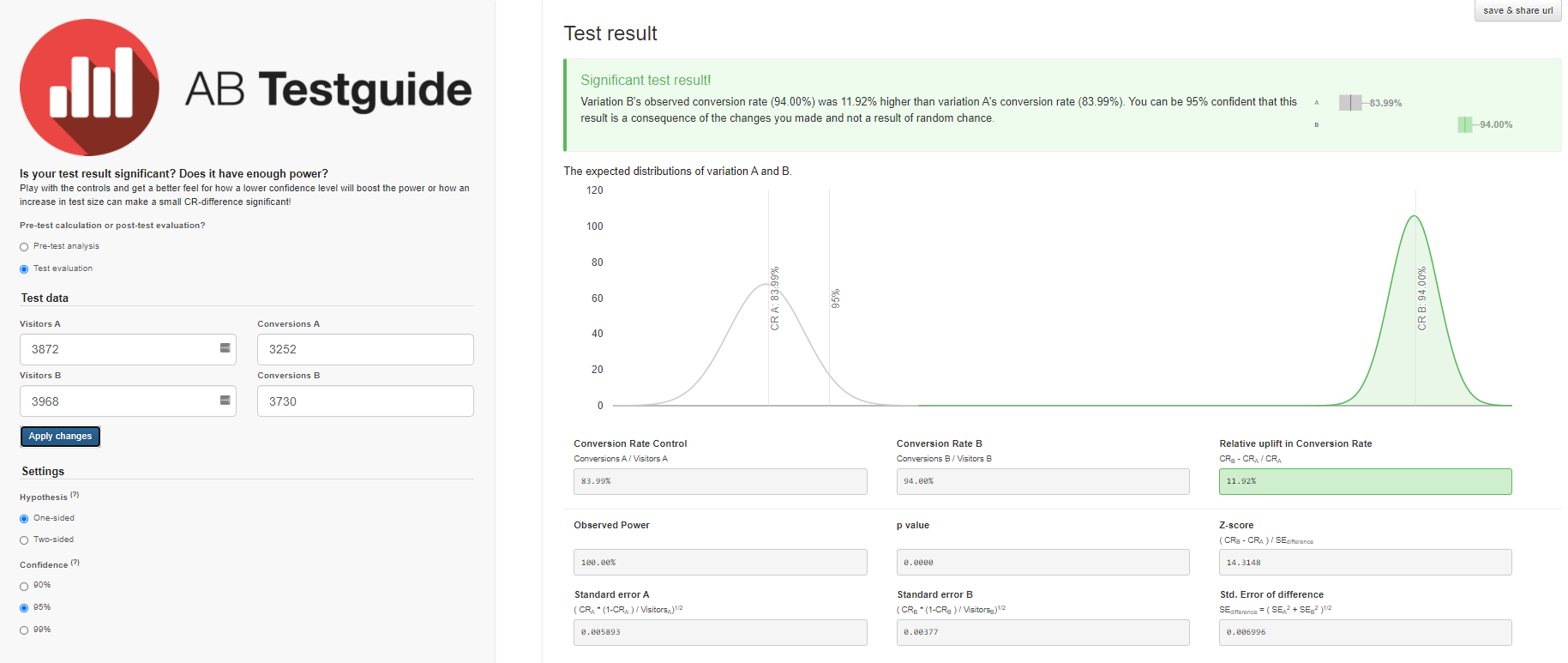
- Dans le groupe A, sur 3870 utilisateurs qui ont commencé le niveau 3, seuls 3252 utilisateurs l'ont réussi, soit 84%.
- Dans le groupe B, sur 3968 utilisateurs, 3730 ont réussi le niveau, soit 94%.
Le calculateur des Awesome A / B Tools d'Evan a calculé l'intervalle de confiance pour chaque option, en tenant compte de la taille de l'échantillon et du niveau de signification choisi.
Conclusions indépendantes:
- A — 84,00%, 82,8%—85,1%. B — 94,00%, 93,2%—94,7%. (94%-84%)/84% = 0,119 => 12%
- 12% , A. — , . 95%.
- .
Nous obtiendrons des résultats similaires avec le calculateur A / B Testguide . Mais ici, vous pouvez déjà jouer avec les paramètres, obtenir un résultat graphique et formuler des conclusions.
Si vous avez peur de tant de paramètres, que vous n'avez ni envie ni besoin de gérer la variété des données calculées par la calculatrice, vous pouvez utiliser la calculatrice de test A / B de Neilpatel .
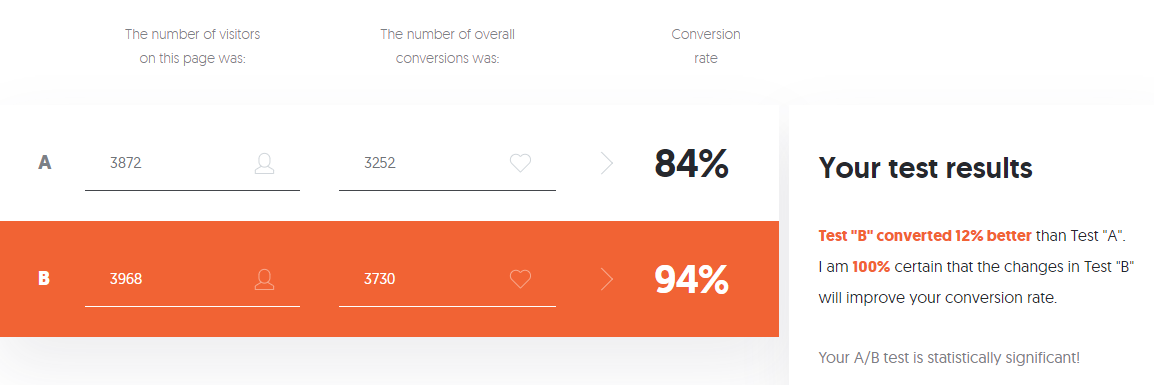
Chaque calculateur en ligne a ses propres critères et algorithmes, qui peuvent ne pas prendre en compte toutes les fonctionnalités de l'expérience. En conséquence, des questions et des doutes surgissent dans l'interprétation des résultats. De plus, si la métrique cible est quantitative - vérification moyenne ou durée moyenne de la première session - les calculatrices en ligne répertoriées ne sont plus applicables et des méthodes d'évaluation plus avancées sont nécessaires.
Je rédige un rapport détaillé sur chaque test A / B, j'ai donc sélectionné et mis en œuvre des méthodes et des critères adaptés à mes tâches pour évaluer la signification statistique des résultats.
Conclusion
Le test A / B est un outil qui ne donne pas une réponse sans ambiguïté à la question "Quelle option est la meilleure?", Mais vous permet seulement de réduire l'incertitude sur la manière de trouver des solutions optimales. Lors de sa réalisation, les détails sont importants à toutes les étapes de la préparation, chaque inexactitude coûte des ressources et peut avoir un impact négatif sur la fiabilité des résultats. J'espère que cet article vous a été utile et vous aide à éviter les erreurs dans les tests A / B.