
Votre entreprise souhaite-t-elle collecter et analyser des données pour étudier les tendances sans sacrifier la confidentialité? Ou peut-être utilisez-vous déjà divers outils pour le préserver et souhaitez approfondir vos connaissances ou partager votre expérience? Dans tous les cas, ce matériel est pour vous.
Qu'est-ce qui nous a poussé à lancer cette série d'articles? L'année dernière, le NIST a lancé l' espace de collaboration en ingénierie de la confidentialité- une plateforme de coopération, qui contient des outils open source, ainsi que des solutions et des descriptions de processus nécessaires à la conception de la confidentialité des systèmes et de la gestion des risques. En tant que modérateurs de cet espace, nous aidons le NIST à collecter les outils de confidentialité différentiels disponibles dans le domaine de l'anonymisation. Le NIST a également publié Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management et un plan d'action qui décrit un éventail de problèmes de confidentialité, y compris l'anonymisation. Nous voulons maintenant aider Collaboration Space à atteindre les objectifs fixés dans le plan d'anonymisation (désidentification). Enfin, aidez le NIST à développer cette série de publications en un guide plus détaillé de la confidentialité différentielle.
Chaque article commencera par des concepts de base et des exemples d'application pour aider les professionnels - tels que les propriétaires de processus métier ou les responsables de la confidentialité des données - à en apprendre suffisamment pour devenir dangereux (je plaisante). Après avoir passé en revue les bases, nous analyserons les outils disponibles et les approches utilisées, ce qui sera déjà utile pour ceux qui travaillent sur des implémentations spécifiques.
Nous commencerons notre premier article en décrivant les concepts et concepts clés de la confidentialité différentielle, que nous utiliserons dans les articles suivants.
Formulation du problème
Comment pouvez-vous étudier les données démographiques sans affecter des membres spécifiques de la population? Essayons de répondre à deux questions:
- Combien de personnes vivent dans le Vermont?
- Combien de personnes nommées Joe Near vivent dans le Vermont?
La première question concerne les propriétés de l'ensemble de la population et la seconde révèle des informations sur une personne spécifique. Nous devons être en mesure de déterminer les tendances pour l'ensemble de la population, sans permettre des informations sur un individu en particulier.
Mais comment répondre à la question "combien de personnes vivent dans le Vermont?" - que nous appellerons plus loin "enquête" - sans répondre à la deuxième question "Combien de personnes du nom de Joe Nier vivent dans le Vermont?" La solution la plus courante est la désidentification (ou anonymisation), qui consiste à supprimer toutes les informations d'identification de l'ensemble de données (ci-après, nous pensons que notre ensemble de données contient des informations sur des personnes spécifiques). Une autre approche consiste à autoriser uniquement les requêtes agrégées, par exemple avec une moyenne. Malheureusement, maintenant nous savons déjà qu'aucune des approches ne fournit la protection de la vie privée nécessaire. Les données anonymisées sont la cible d'attaques qui établissent des liens avec d'autres bases de données. L'agrégation protège la confidentialité uniquement lorsque la taille du groupe échantillonné estassez gros. Mais même dans de tels cas, des attaques réussies sont possibles [1, 2, 3, 4].
Confidentialité différentielle
La confidentialité différentielle [5, 6] est une définition mathématique du concept de «protection de la vie privée». Ce n'est pas un processus spécifique, mais plutôt une propriété qu'un processus peut posséder. Par exemple, vous pouvez calculer (prouver) qu'un processus donné répond aux principes de confidentialité différentielle.
En termes simples, pour chaque personne dont les données sont incluses dans l'ensemble de données analysé, la confidentialité différentielle garantit que le résultat de l'analyse différentielle de la confidentialité sera pratiquement indiscernable, que vos données soient ou non dans l'ensemble de données . L'analyse différentielle de la vie privée est souvent appelée mécanisme , et nous l'appellerons...
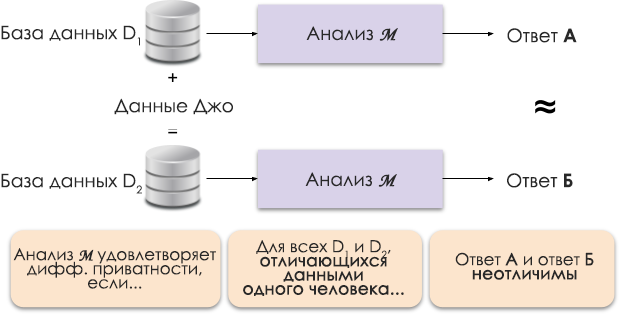
Figure 1: Représentation schématique de la confidentialité différentielle.
Le principe de la confidentialité différentielle est illustré à la figure 1. La réponse A est calculée sans les données de Joe et la réponse B avec ses données. Et il est soutenu que les deux réponses seront indiscernables. Autrement dit, quiconque regarde les résultats ne sera pas en mesure de dire dans quel cas les données de Joe ont été utilisées et dans quel cas elles ne l'ont pas été.
Nous contrôlons le niveau de confidentialité requis en modifiant le paramètre de confidentialité ε, également appelé perte de confidentialité ou budget de confidentialité. Plus la valeur ε est petite, moins les résultats se distinguent et plus les données des individus sont sécurisées.
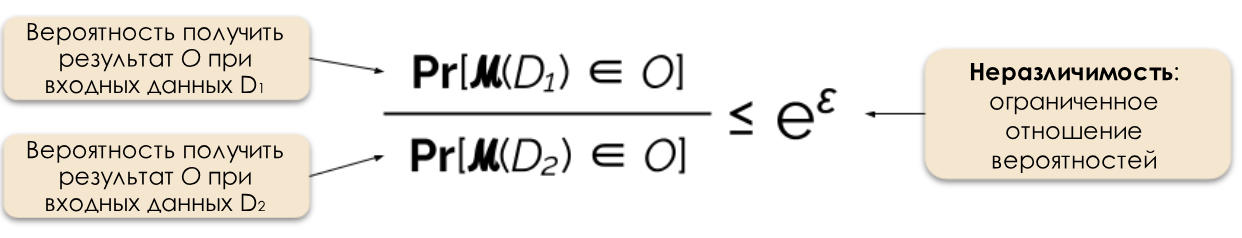
Figure 2: Définition formelle de la confidentialité différentielle.
Souvent, nous pouvons répondre à une demande avec une confidentialité différentielle en ajoutant un bruit aléatoire à la réponse. La difficulté consiste à déterminer exactement où et combien de bruit ajouter. L'un des mécanismes de pollution sonore les plus populaires est le mécanisme de Laplace [5, 7].
Des demandes de confidentialité accrues nécessitent plus de bruit pour satisfaire une valeur epsilon spécifique de confidentialité différentielle. Et ce bruit supplémentaire peut réduire l'utilité des résultats obtenus. Dans les prochains articles, nous aborderons plus en détail la confidentialité et le compromis entre confidentialité et utilité.
Avantages de la confidentialité différentielle
La confidentialité différentielle présente plusieurs avantages importants par rapport aux techniques précédentes.
- , , ( ) .
- , .
- : , . , . , .
En raison de ces avantages, l'application de méthodes de confidentialité différentielles dans la pratique est préférable à certaines autres méthodes. Le revers de la médaille est que cette méthodologie est assez nouvelle et qu'il n'est pas facile de trouver des outils, des normes et des approches éprouvées en dehors de la communauté de recherche universitaire. Cependant, nous pensons que la situation s'améliorera dans un proche avenir en raison de la demande croissante de solutions fiables et simples pour préserver la confidentialité des données.
Et après?
Abonnez-vous à notre blog et nous publierons très bientôt la traduction du prochain article, qui décrit les modèles de menaces à prendre en compte lors de la construction de systèmes de confidentialité différentielle, ainsi que les différences entre les modèles centraux et locaux de confidentialité différentielle.
Sources
[1] Garfinkel, Simson, John M. Abowd et Christian Martindale. "Comprendre les attaques de reconstruction de base de données sur les données publiques." Communications de l'ACM 62.3 (2019): 46-53.
[2] Gadotti, Andrea et al. "Quand le signal est dans le bruit: exploiter le bruit collant de Diffix." 28e Symposium sur la sécurité USENIX (USENIX Security 19). 2019.
[3] Dinur, Irit et Kobbi Nissim. "Révéler des informations tout en préservant la confidentialité." Actes du vingt-deuxième colloque ACM SIGMOD-SIGACT-SIGART sur les principes des systèmes de bases de données. 2003.
[4] Sweeney, Latanya. "Des données démographiques simples identifient souvent les gens de manière unique." Santé (San Francisco) 671 (2000): 1-34.
[5] Dwork, Cynthia et al. "Calibrage du bruit à la sensibilité dans l'analyse de données privées." Conférence sur la théorie de la cryptographie. Springer, Berlin, Heidelberg, 2006.
[6] Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O'Brien, Thomas Steinke et Salil Vadhan. « Confidentialité différentielle: une introduction pour un public non technique. »Vand. J. Ent. & Tech. L. 21 (2018): 209.
[7] Dwork, Cynthia et Aaron Roth. "Les fondements algorithmiques de la confidentialité différentielle." Fondements et tendances de l'informatique théorique 9, no. 3-4 (2014): 211-407.