
Il s'agit d'une traduction du deuxième article d'une série sur la confidentialité différentielle.
La semaine dernière, dans le premier article de cette série - « Confidentialité différentielle - Analyser les données tout en préservant la confidentialité (Introduction à la série) » - nous avons examiné les concepts de base et les utilisations de la confidentialité différentielle. Aujourd'hui, nous examinerons les options possibles pour la construction de systèmes, en fonction du modèle de menace attendu.
Déployer un système qui répond aux principes de confidentialité différentielle n'est pas une tâche triviale. À titre d'exemple, dans notre prochain article, nous examinerons un programme Python simple qui implémente l'ajout de bruit de Laplace directement dans une fonction qui traite des données sensibles. Mais pour que cela fonctionne, nous devons collecter toutes les données requises sur un serveur.
Et si le serveur est piraté? Dans ce cas, la confidentialité différentielle ne nous aidera pas, car elle ne protège que les données obtenues à la suite du travail du programme!
Lors du déploiement de systèmes basés sur les principes de la confidentialité différentielle, il est important de prendre en compte le modèle de menace: de quels adversaires nous voulons protéger le système. Si ce modèle inclut des attaquants capables de compromettre complètement un serveur avec des données sensibles, nous devons alors changer le système afin qu'il puisse résister à de telles attaques.
Autrement dit, les architectures des systèmes qui respectent la confidentialité différentielle doivent prendre en compte à la fois la confidentialité et la sécurité . La confidentialité contrôle ce qui peut être récupéré à partir des données renvoyées par le système. Et la sécurité peut être considérée comme la tâche inverse: c'est le contrôle de l'accès à une partie des données, mais elle ne donne aucune garantie quant à leur contenu.
Modèle de confidentialité différentiel central
Le modèle de menace le plus couramment utilisé dans le travail de confidentialité différentielle est le modèle de confidentialité différentielle central (ou simplement «confidentialité différentielle centrale»).
Le composant principal - le magasin de données de confiance (conservateur de données de confiance) . Chaque source lui transmet ses données confidentielles, et il les collecte en un seul endroit (par exemple, sur un serveur). Un référentiel est approuvé si nous supposons qu'il traite nos données sensibles par lui-même, ne les transfère à personne et ne peut être compromis par personne. En d'autres termes, nous pensons qu'un serveur avec des données sensibles ne peut pas être compromis.
Dans le cadre du modèle central, nous ajoutons généralement du bruit aux réponses aux requêtes (nous examinerons l'implémentation de Laplace dans le prochain article). L'avantage de ce modèle est la possibilité d'ajouter la valeur de bruit la plus faible possible, maintenant ainsi la précision maximale permise par les principes de confidentialité différentielle. Vous trouverez ci-dessous un diagramme du processus. Nous avons placé une barrière de confidentialité entre le magasin de données de confiance et l'analyste afin que seuls les résultats qui répondent aux critères de confidentialité différentiels spécifiés puissent sortir. Ainsi, l'analyste n'est pas obligé de faire confiance.
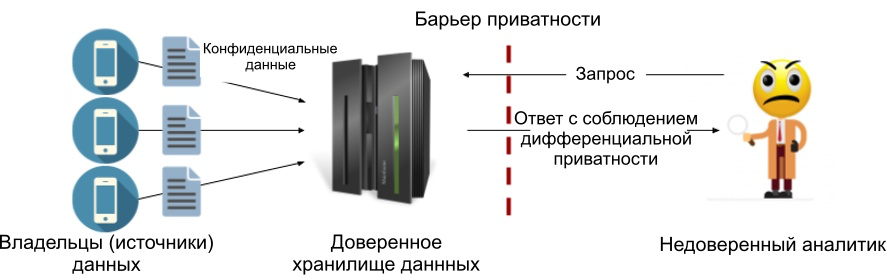
Figure 1: Le modèle de confidentialité différentiel central.
L'inconvénient du modèle central est qu'il nécessite un magasin de confiance, et beaucoup d'entre eux ne le sont pas. En fait, le manque de confiance dans le consommateur des données est généralement la principale raison de l'utilisation de principes de confidentialité différents.
Modèle de confidentialité différentielle locale
Le modèle de confidentialité différentielle locale vous permet de vous débarrasser du magasin de données de confiance: chaque source de données (ou propriétaire de données) ajoute du bruit à leurs données avant de les transférer vers le magasin. Cela signifie que le stockage ne contiendra jamais d'informations sensibles, ce qui signifie qu'il n'y a pas besoin de sa procuration. La figure ci-dessous montre le périphérique du modèle local: dans celui-ci, une barrière de confidentialité se trouve entre chaque propriétaire des données et le stockage (qui peut ou non être fiable).
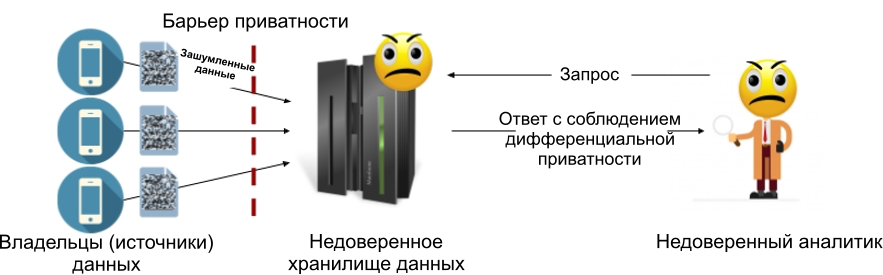
Figure 2: Modèle de confidentialité différentielle locale.
Le modèle local de confidentialité différentielle évite le problème principal du modèle central: si l'entrepôt de données est compromis, alors les pirates n'auront accès qu'aux données bruyantes qui répondent déjà aux exigences de la confidentialité différentielle. C'est la raison principale pour laquelle le modèle local a été choisi pour des systèmes tels que Google RAPPOR [1] et le système de collecte de données d'Apple [2].
Mais d'autre part? Le modèle local est moins précis que le modèle central. Dans le modèle local, chaque source ajoute indépendamment du bruit pour satisfaire ses propres conditions de confidentialité différentielles, de sorte que le bruit total de tous les participants est beaucoup plus élevé que le bruit dans le modèle central.
Au final, cette approche n'est justifiée que pour les requêtes avec une tendance (signal) très persistante. Apple, par exemple, utilise un modèle local pour estimer la popularité des emoji, mais le résultat n'est utile que pour les emoji les plus populaires (où la tendance est la plus prononcée). En règle générale, ce modèle n'est pas utilisé pour des requêtes plus complexes, telles que celles utilisées par le recensement américain [10] ou l'apprentissage automatique.
Modèles hybrides
Les modèles central et local présentent à la fois des avantages et des inconvénients, et l’effort principal est maintenant d’en tirer le meilleur parti.
Par exemple, vous pouvez utiliser le modèle de mélange implémenté dans le système Prochlo [4]. Il contient un magasin de données non approuvé, de nombreux propriétaires de données individuels et plusieurs mélangeurs partiellement approuvés .... Chaque source ajoute d'abord une petite quantité de bruit à ses données, puis l'envoie à l'agitateur, qui ajoute plus de bruit avant de l'envoyer à l'entrepôt de données. En fin de compte, il est peu probable que les agitateurs «s'entendent» (ou soient compromis en même temps) avec le magasin de données ou entre eux, donc un peu de bruit ajouté par les sources suffira à garantir la confidentialité. Chaque agitateur peut gérer plusieurs sources, tout comme le modèle central, de sorte qu'une petite quantité de bruit garantira la confidentialité de l'ensemble de données résultant.
Le modèle d'agitateur est un compromis entre les modèles locaux et centraux: il ajoute moins de bruit que local, mais plus que central.
Vous pouvez également combiner la confidentialité différentielle avec la cryptographie, comme dans le calcul multipartite sécurisé (MPC) ou le cryptage entièrement homomorphique (FHE). FHE permet des calculs avec des données chiffrées sans les déchiffrer au préalable, et MPC permet à un groupe de participants d'exécuter en toute sécurité des requêtes sur des sources distribuées sans exposer leurs données. Calcul des fonctions privées différentiellesl'utilisation de l'informatique crypto-sécurisée (ou simplement sécurisée) est un moyen prometteur d'atteindre la précision du modèle central avec tous les avantages du local. De plus, dans ce cas, l'utilisation de l'informatique sécurisée élimine le besoin de disposer d'un stockage fiable. Des travaux récents [5] montrent des résultats encourageants de la combinaison de MPC et de confidentialité différentielle, absorbant la plupart des avantages des deux approches. Certes, dans la plupart des cas, les calculs sécurisés sont plusieurs ordres de grandeur plus lents que les calculs effectués localement, ce qui est particulièrement important pour les grands ensembles de données ou les requêtes complexes. L'informatique sécurisée est actuellement en phase de développement actif, donc ses performances augmentent rapidement.
Donc?
Dans le prochain article, nous examinerons notre premier outil open-source pour mettre en pratique des concepts de confidentialité différentiels. Regardons d'autres outils, à la fois disponibles pour les débutants et applicables à de très grandes bases de données, comme celles du US Census Bureau. Nous essaierons de calculer les données démographiques conformément aux principes de confidentialité différentielle.
Abonnez-vous à notre blog et ne manquez pas la traduction du prochain article. Très bientôt.
Sources
[1] Erlingsson, Úlfar, Vasyl Pihur et Aleksandra Korolova. "Rappor: réponse ordinale de préservation de la vie privée agrégeable au hasard." Dans Actes de la conférence ACM SIGSAC 2014 sur la sécurité informatique et des communications, pp. 1054-1067. 2014.
[2] Apple Inc. «Présentation technique de la confidentialité différentielle Apple». Consulté le 31/07/2020. https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel, Simson L., John M. Abowd et Sarah Powazek. "Problèmes rencontrés lors du déploiement de la confidentialité différentielle." Dans les actes de l'atelier 2018 sur la vie privée dans la société électronique, p. 133-137. 2018.
[4] Bittau, Andrea, Úlfar Erlingsson, Petros Maniatis, Ilya Mironov, Ananth Raghunathan, David Lie, Mitch Rudominer, Ushasree Kode, Julien Tinnes et Bernhard Seefeld. "Prochlo: une confidentialité renforcée pour les analyses dans la foule." Dans Proceedings of the 26th Symposium on Operating Systems Principles, pp. 441-459. 2017.
[5] Roy Chowdhury, Amrita, Chenghong Wang, Xi He, Ashwin Machanavajjhala et Somesh Jha. «Cryptes: Confidentialité différentielle assistée par cryptage sur des serveurs non approuvés». Dans Actes de la conférence internationale ACM SIGMOD 2020 sur la gestion des données, pp. 603-619. 2020.