Je dois noter qu'un mois après avoir pris connaissance de cette technologie, j'ai commencé à utiliser des antidépresseurs. On ne sait pas avec certitude si NiFi a été le déclencheur ou la goutte d'eau, ainsi que son implication dans ce fait. Mais, puisque j'ai entrepris d'esquisser tout ce qui attend un potentiel débutant sur cette voie, je me dois d'être le plus franc possible.
A l'heure où, techniquement, Apache NiFi est un lien puissant entre différents services (il échange des données entre eux, leur permettant de s'enrichir et de les modifier en cours de route), je le regarde du point de vue d'un analyste . En effet, NiFi est un outil ETL très pratique. En particulier, en équipe, nous nous concentrons sur la construction de leur architecture SaaS.
L'expérience de l'automatisation de l'un de mes flux de travail, à savoir la formation et la distribution de rapports hebdomadaires sur Jira Software , je souhaite la divulguer dans cet article. En passant, je décrirai et publierai également la méthodologie d'analyse du tracker de tâches, qui répond clairement à la question - que font les employés - je décrirai et publierai également dans un proche avenir.
Malgré le dévouement de cet article aux débutants, je pense qu'il est correct et utile que des architectes plus expérimentés (gourous, pour ainsi dire) le revoient dans des crommentions ou partagent leurs cas d'utilisation de NiFi dans divers domaines d'activité. Beaucoup de gars, dont moi, vous remercieront.
Le concept Apache NiFi en bref.
Apache NiFi est un produit open source pour l'automatisation et le contrôle des flux de données entre les systèmes. Pour commencer, il est important de réaliser immédiatement deux choses.
La première est la zone Low Code. Ce que je veux dire? On suppose que toutes les manipulations avec des données à partir du moment où elles entrent dans NiFi jusqu'à l'extraction peuvent être effectuées à l'aide d'outils standard (processeurs). Pour les cas particuliers, il existe un processeur pour exécuter des scripts à partir de bash.
Cela suggère que faire quelque chose en NiFi est mal - c'est assez difficile (mais j'ai réussi! - c'est le deuxième point). Difficile car n'importe quel processeur vous bottera tout de suite - Où envoyer les erreurs? Que faire avec eux? Combien de temps à attendre? Et là tu m'as laissé un peu d'espace! Avez-vous lu attentivement la documentation? etc.

Le deuxième (clé) est le concept de programmation en streaming, et rien de plus. Ici, personnellement, je ne l'ai pas immédiatement compris (s'il vous plaît, ne jugez pas). Ayant de l'expérience en programmation fonctionnelle en R, j'ai formé à mon insu des fonctions en NiFi. En fin de compte - refaire - mes collègues m'ont dit quand ils ont vu mes vaines tentatives pour faire de ces «fonctions» des amis.
Je pense que la théorie est suffisante pour aujourd'hui, apprenons tout de la pratique mieux. Formulons une similitude de spécification technique pour les analyses hebdomadaires Jira.
- Obtenez le journal de travail et l'historique des changements de la graisse pour la semaine.
- Affichez les statistiques de base pour cette période et répondez à la question: que faisait l'équipe?
- Envoyez le rapport au patron et aux collègues.
Afin d'apporter plus d'avantages au monde, je ne me suis pas arrêté à une période hebdomadaire et j'ai développé un processus avec la possibilité de télécharger une quantité beaucoup plus grande de données.
Découvrons-le.
Les premiers pas. Récupérer les données de l'API
Apache NiFi n'a pas une telle chose comme un projet séparé. Nous n'avons qu'un espace de travail commun et la possibilité d'y former des groupes de processus. Cela suffit amplement.
Recherchez le groupe de processus dans la barre d'outils et créez le groupe Jira_report. Accédez au groupe et commencez à créer le flux de travail. La plupart des processeurs à partir desquels il peut être assemblé nécessitent une connexion en amont. En termes simples, il s'agit d'un déclencheur sur lequel le processeur se déclenchera. Par conséquent, il est logique que tout le flux commence par un déclencheur régulier - en NiFi, il s'agit du processeur GenerateFlowFile. Qu'est-ce qu'il fait. Crée un fichier de diffusion en continu composé d'un ensemble d'attributs et de contenu. Les attributs sont des paires clé / valeur de chaîne associées au contenu.
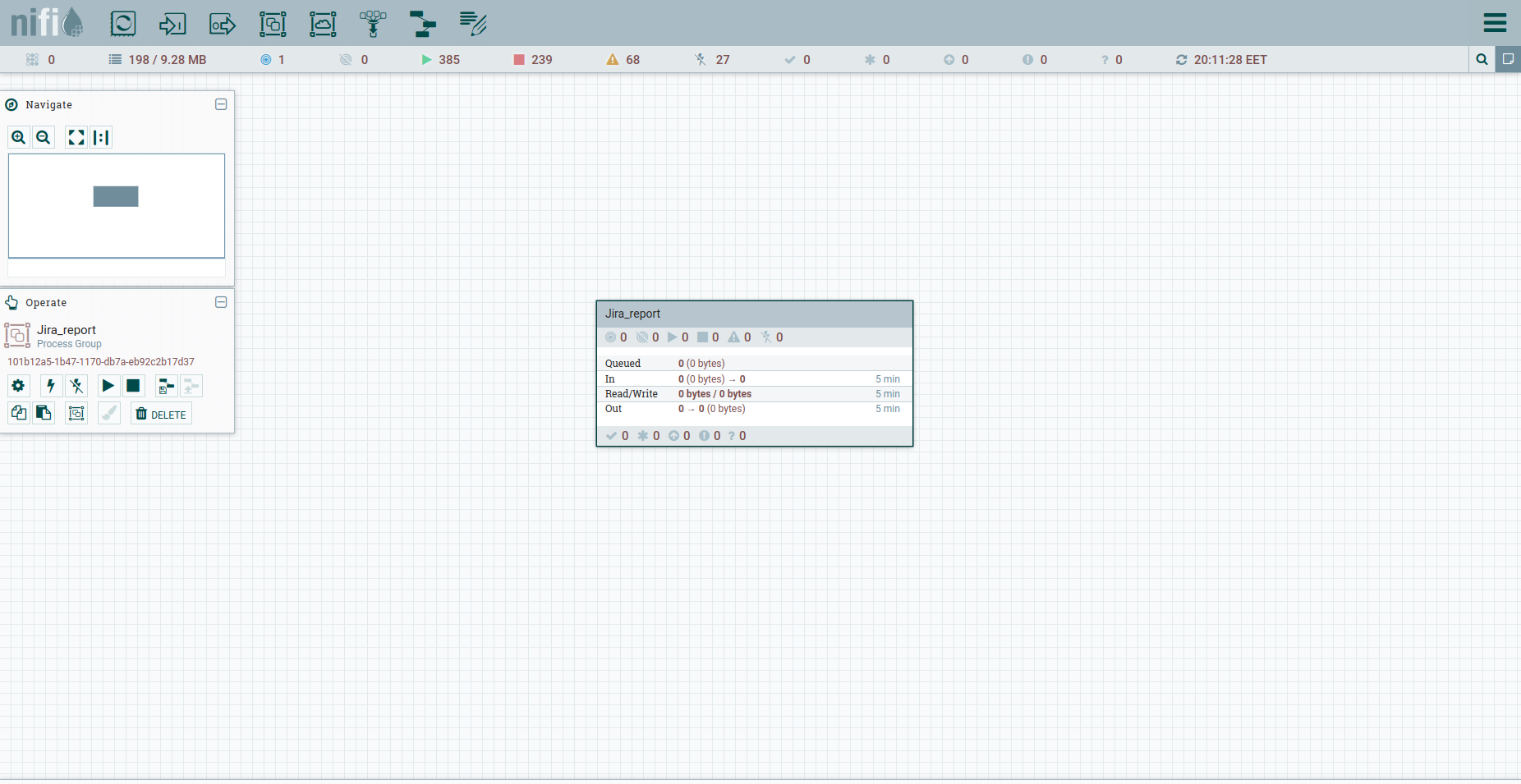
Le contenu est un fichier normal, un ensemble d'octets. Imaginez que le contenu est une pièce jointe à un FlowFile.
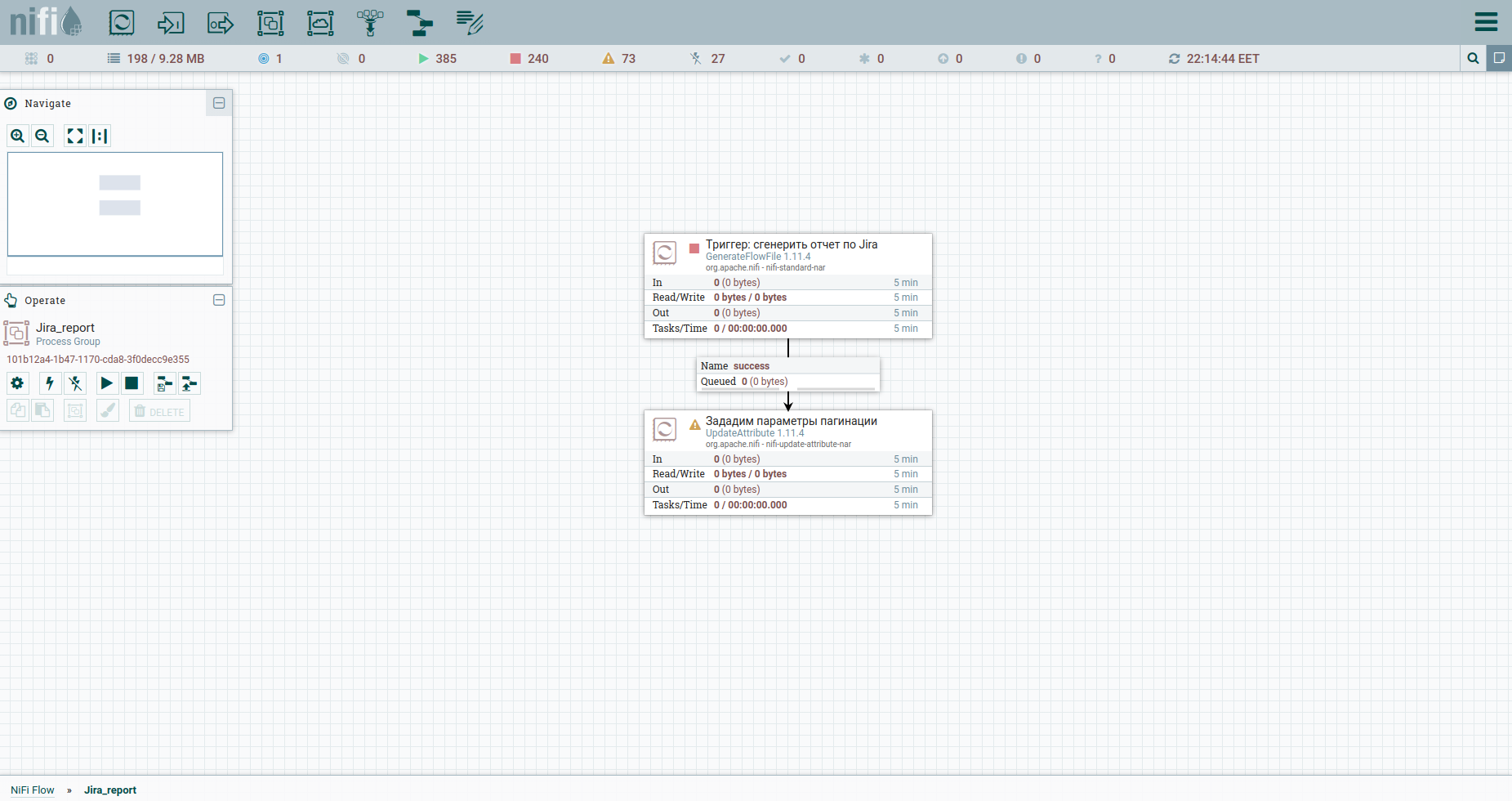
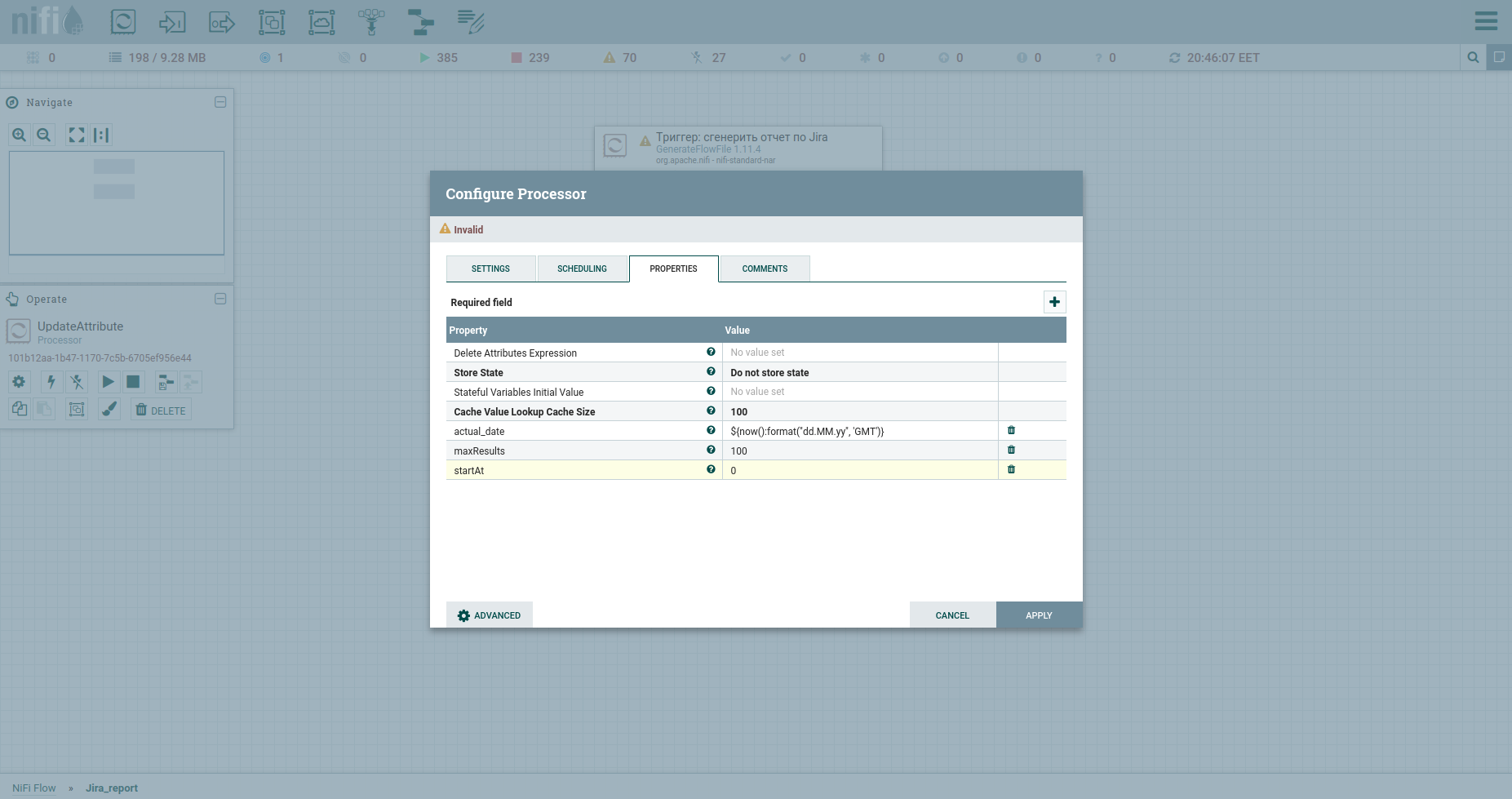
Nous faisons Ajouter un processeur → GenerateFlowFile. Dans les paramètres, tout d'abord, je recommande fortement de définir le nom du processeur (c'est une bonne tonalité) - l'onglet Paramètres. Autre point: par défaut, GenerateFlowFile génère des fichiers de flux en continu. Il est peu probable que vous en ayez jamais besoin. Nous augmentons immédiatement le calendrier d'exécution, par exemple, jusqu'à 60 secondes - l'onglet Planification. De plus, dans l'onglet Propriétés, nous indiquerons la date de début de la période de rapport - l'attribut report_from avec une valeur au format - aaaa / mm / jj. Selon la documentation de l'API Jira, nous avons une limite sur les problèmes de déchargement - pas plus de 1000. Par conséquent, pour obtenir toutes les tâches, nous devrons former une requête JQL, qui spécifie les paramètres de pagination: startAt et maxResults.

Définissons-les avec des attributs à l'aide du processeur UpdateAttribute. Dans le même temps, nous fixerons la date de génération du rapport. Nous en aurons besoin plus tard. Vous avez probablement remarqué l'attribut actual_date. Sa valeur est définie à l'aide du langage d'expression. Attrapez une feuille de triche cool dessus. C'est tout, nous pouvons former JQL en gras - nous indiquerons les paramètres de pagination et les champs obligatoires. Par la suite, ce sera le corps de la requête HTTP, par conséquent, nous l'enverrons au contenu. Pour ce faire, nous utilisons le processeur ReplaceText et spécifions sa valeur de remplacement quelque chose comme ceci:
{"startAt": ${startAt}, "maxResults": ${maxResults}, "jql": "updated >= '2020/11/02'", "fields":["summary", "project", "issuetype", "timespent", "priority", "created", "resolutiondate", "status", "customfield_10100", "aggregatetimespent", "timeoriginalestimate", "description", "assignee", "parent", "components"]}Remarquez comment les liens d'attributs sont écrits.
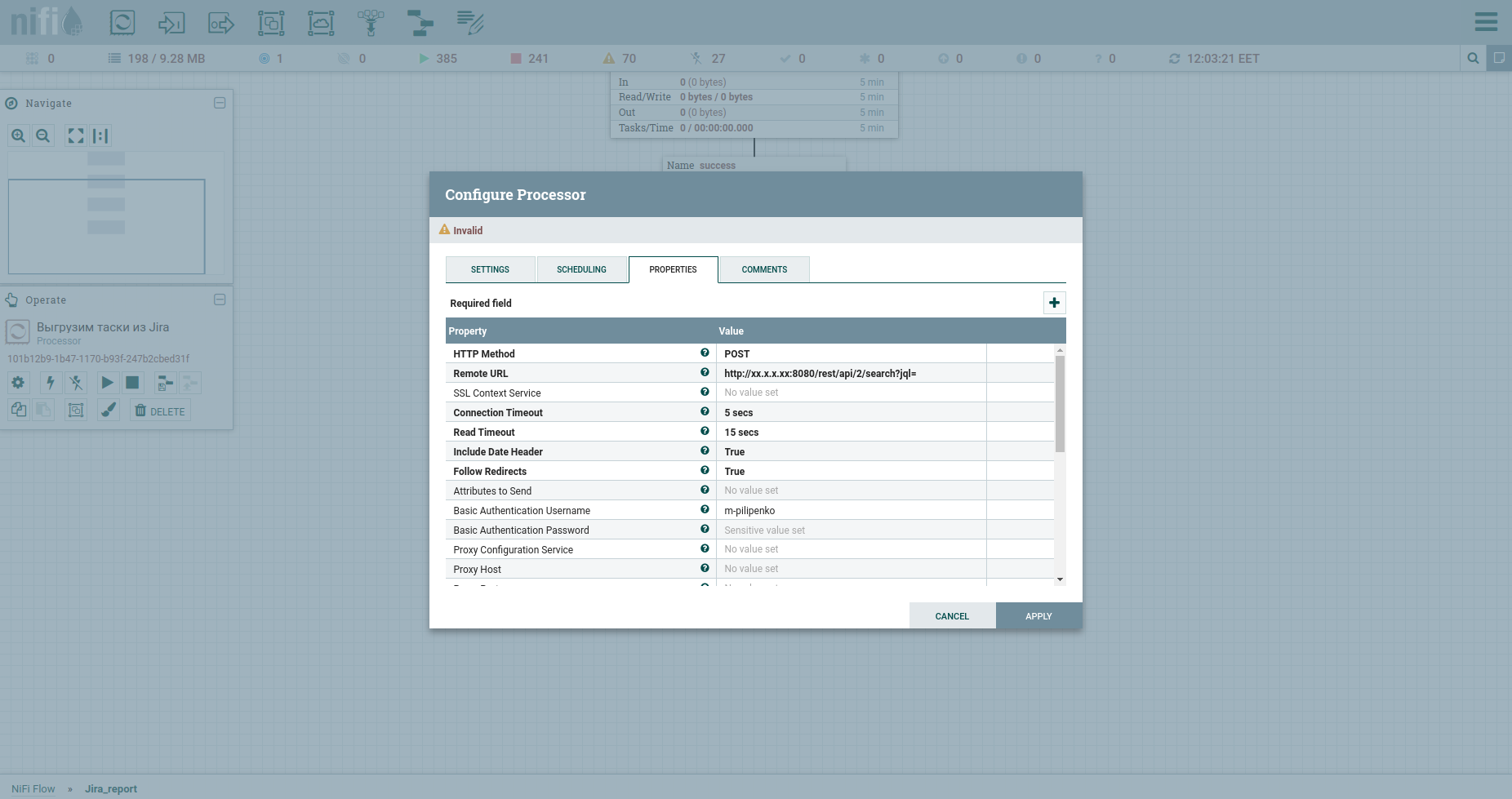
Félicitations, nous sommes prêts à faire une requête HTTP. Le processeur InvokeHTTP s'adaptera ici. Au fait, il peut tout faire ... Je veux dire les méthodes GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS. Modifions ses propriétés comme suit:
Méthode HTTP, nous avons POST.
L'URL distante de notre fat inclut l'IP, le port et / rest / api / 2 / search? Jql =.
Le nom d'utilisateur d'authentification de base et le mot de passe d'authentification de base sont les informations d'identification de Fat.
Changez le Content-Type en application / json b mis true dans le corps du message d'envoi, ce qui signifie envoyer le JSON qui proviendra du processeur précédent dans le corps de la requête.
APPLIQUER.
La réponse de l'apish sera un fichier JSON qui sera inclus dans le contenu. Nous nous intéressons à deux choses: le champ total contenant le nombre total de tâches dans le système et le tableau issues, qui en contient déjà certaines. Analysons la réponse et familiarisons-nous avec le processeur EvaluateJsonPath.
Si JsonPath pointe vers un objet, le résultat de l'analyse sera écrit dans l'attribut du fichier de flux. Voici un exemple - le champ total et l'écran suivant. Dans le cas où JsonPath pointe vers un tableau d'objets, à la suite de l'analyse, le fichier de flux sera divisé en un ensemble avec un contenu correspondant à chaque objet. Voici un exemple - le champ de problème. Nous mettons un autre EvaluateJsonPath et écrivons: Property - issue, Value - $ .issue.

Désormais, notre flux ne sera plus composé d'un seul fichier, mais de plusieurs. Le contenu de chacun d'entre eux contiendra JSON avec des informations sur une tâche spécifique.
Passez. Rappelez-vous que nous avons mis maxResults à 100? Après l'étape précédente, nous aurons cent premiers tasoks. Obtenons plus et implémentons la pagination.
Pour ce faire, augmentons le numéro de la tâche de démarrage de maxResults. Utilisons à nouveau UpdateAttribute: nous allons spécifier l'attribut startAt et lui attribuer une nouvelle valeur $ {startAt: plus ($ {maxResults})}.
Eh bien, nous ne pouvons pas nous passer d'un contrôle pour atteindre le nombre maximum de tâches - le processeur RouteOnAttribute. Les paramètres sont les suivants: Et boucle. Au total, le cycle fonctionnera tant que le numéro de la tâche de démarrage est inférieur au nombre total de tâches. À la sortie de celui-ci - un ruisseau de tasoks. Voici à quoi ressemble le processus maintenant:
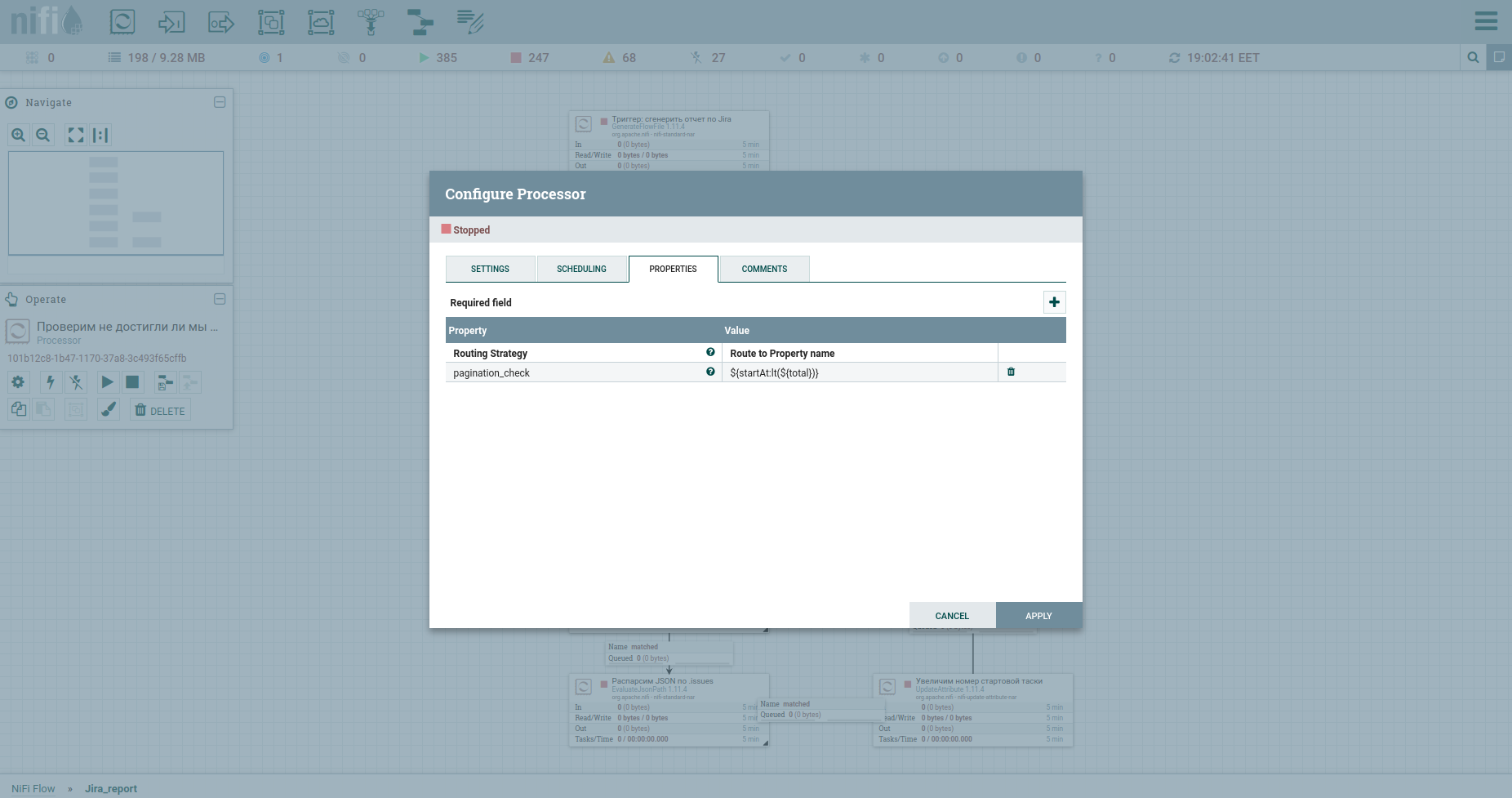

Oui, mes amis, je sais - vous en avez assez de lire mes commentaires sur chaque case. Vous voulez comprendre le principe lui-même. Je n'ai rien contre.
Cette section devrait permettre à un débutant absolu d'entrer plus facilement dans NiFi. Ensuite, ayant en main un modèle généreusement présenté par mes soins, il ne sera pas difficile de se plonger dans les détails.
Galopez à travers l'Europe. Téléchargement d'un journal de travail, etc.
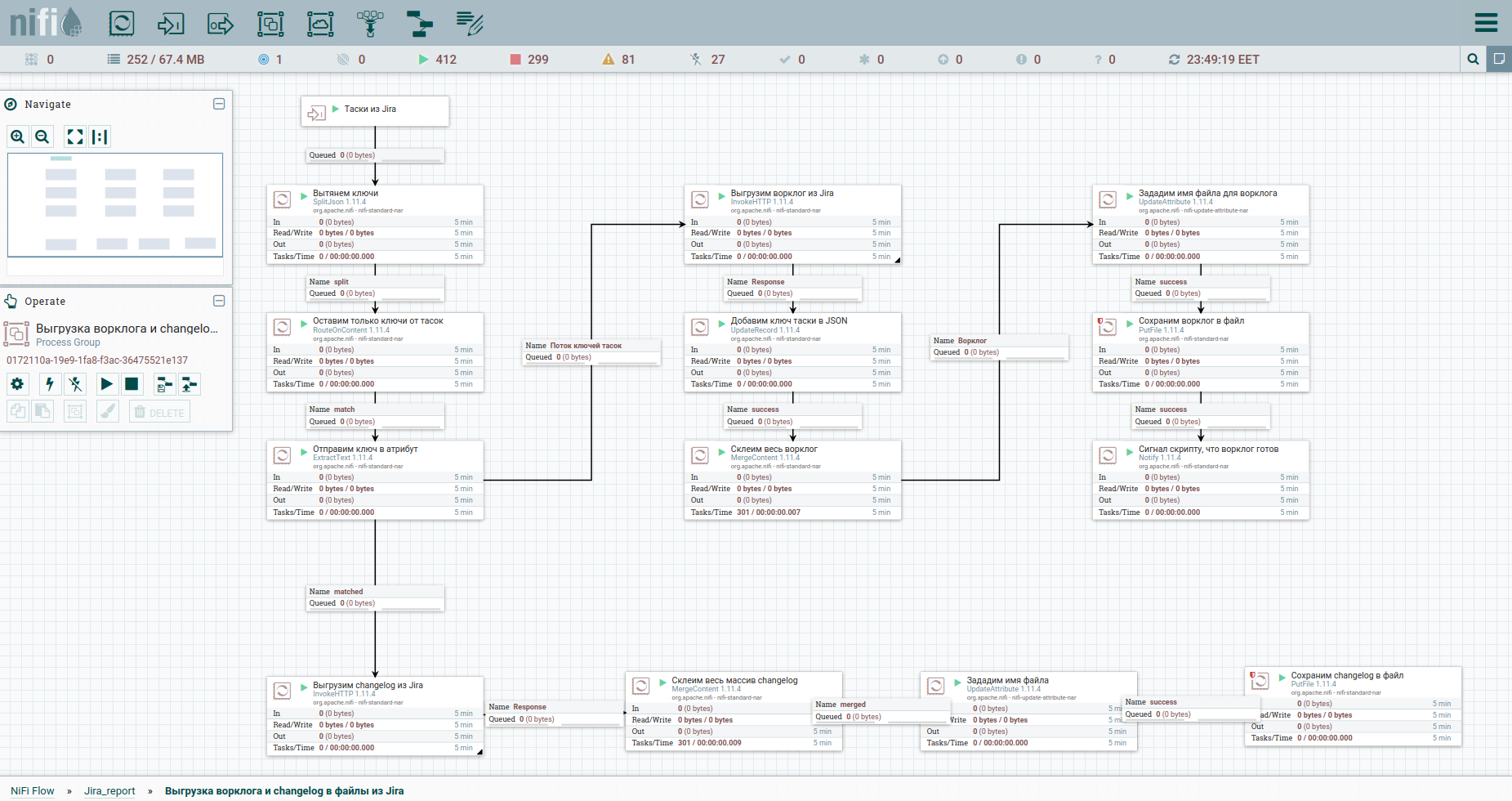
Eh bien, accélérons. Comme on dit, trouvez les différences: pour une meilleure perception, j'ai déplacé le processus de déchargement du journal de travail et l'historique des changements dans un groupe séparé. La voici: Pour contourner les limitations lors du déchargement automatique d'un journal de travail de Jira, il est conseillé de se référer à chaque tâche séparément. C'est pourquoi nous avons besoin de leurs clés. La première colonne convertit simplement le flux de tasoks en un flux de clés. Ensuite, nous nous tournons vers l'apish et enregistrons la réponse. Il nous sera pratique d'organiser le journal de travail et le journal des modifications pour toutes les tâches sous la forme de documents séparés. Par conséquent, nous allons utiliser le processeur MergeContent et coller avec lui le contenu de tous les fichiers de flux.
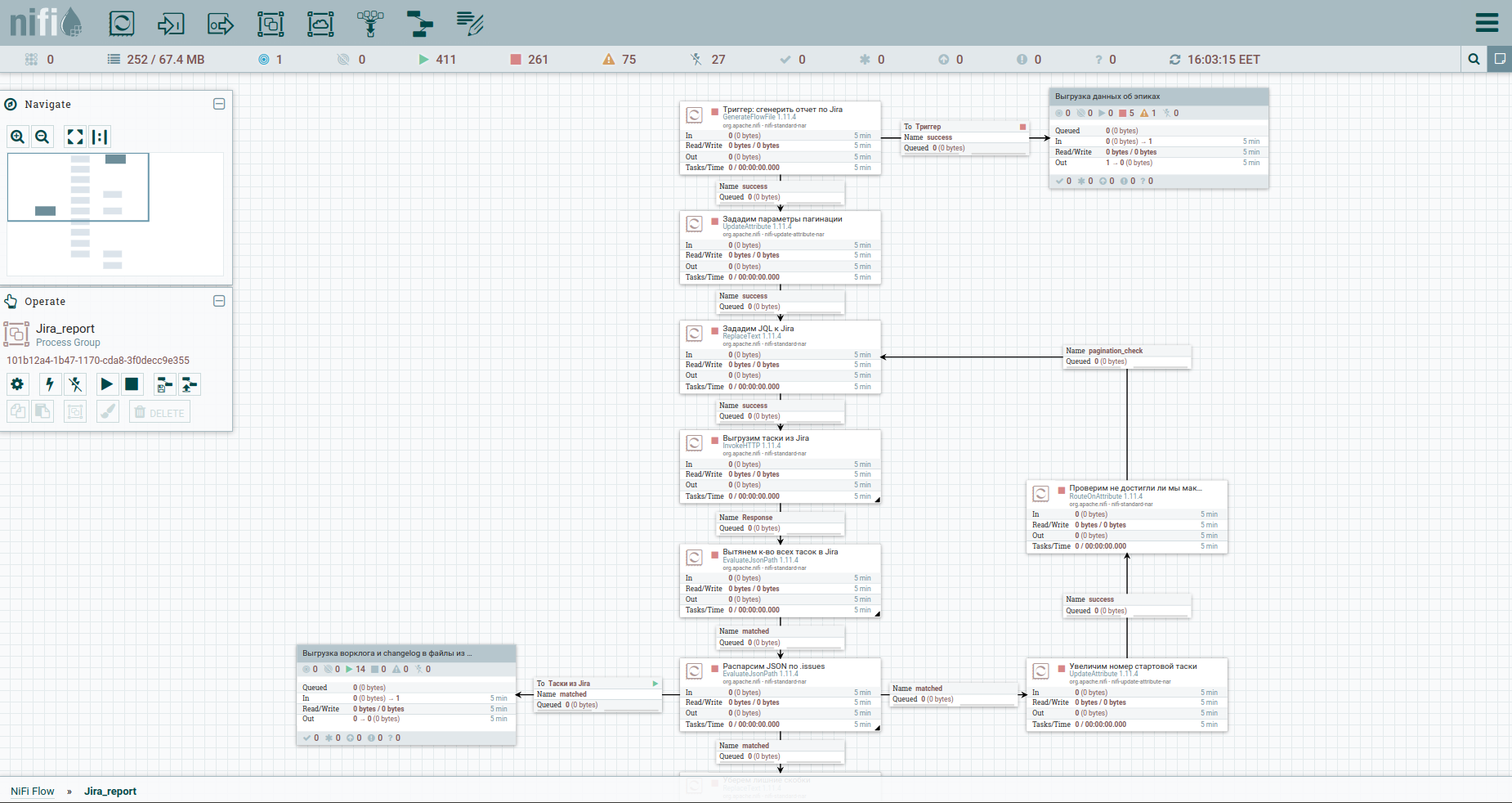
Également dans le modèle, vous remarquerez un groupe pour le déchargement des données par epics. Une épopée dans Jira est une tâche commune à laquelle beaucoup d'autres se lient. Ce groupe sera utile dans le cas où seule une partie des tâches est minée, afin de ne pas perdre d'informations sur les épopées de certaines d'entre elles.
La dernière étape. Génération de rapport et envoi par email
D'accord. Tous les points ont été déchargés et sont allés de deux manières: vers le groupe pour décharger le journal de travail et vers le script pour générer le rapport. Par ce dernier, nous avons un STDIN, nous devons donc rassembler toutes les tâches dans une pile. Nous ferons cela dans MergeContent, mais avant cela, nous corrigerons légèrement le contenu afin que le json final soit correct. Un processeur Wait intéressant est présent devant le carré de génération de script (ExecuteStreamCommand). Il attend un signal du processeur Notify, qui se trouve dans le groupe de déchargement du journal de travail, indiquant que tout est prêt et que vous pouvez passer à autre chose. Ensuite, nous exécutons le script de bash-a - ExecuteStreamCommand. Et nous envoyons le rapport via PutEmail à toute l'équipe.

Je vous parlerai en détail du script, ainsi que de l'expérience de mise en œuvre de l'analyse Jira Software dans notre entreprise dans un article séparé, qui sera prêt l'autre jour.
En bref, le reporting que nous avons développé fournit une vision stratégique de ce que fait une unité ou une équipe. Et c'est inestimable pour tout patron, vous devez être d'accord.
Épilogue
Pourquoi vous épuiser si vous pouvez faire tout cela avec un script à la fois, demandez-vous. Oui, je suis d'accord, mais partiellement.
Apache NiFi ne simplifie pas le processus de développement, il simplifie l'opération. Nous pouvons arrêter n'importe quel fil à tout moment, faire une modification et recommencer.
De plus, NiFi nous donne une vue descendante des processus que vit l'entreprise. Dans le groupe suivant, j'aurai un autre script. Un autre sera le procès de mon collègue. Vous comprenez, non? L'architecture dans la paume de votre main. Comme notre patron le plaisante, nous implémentons Apache NiFi afin que nous puissions tous vous renvoyer plus tard, et j'étais le seul à appuyer sur les boutons. Mais c'est une blague.
Eh bien, dans cet exemple, les petits pains sous la forme d'une tâche de planification pour générer des rapports et envoyer des lettres sont également très, très agréables.
J'avoue, j'avais l'intention de déverser mon âme et de vous parler du râteau sur lequel j'ai marché dans le processus d'étude de la technologie - combien d'entre eux. Mais ici, c'est déjà long. Si le sujet est intéressant, faites-le moi savoir. En attendant, amis, merci et attendez-vous dans les commentaires.
Liens utiles
Un article ingénieux qui couvre Apache NiFi directement sur vos doigts et par lettres.
Un petit guide en russe.
Une feuille de triche pour Expression Language.
La communauté anglophone Apache NiFi est ouverte aux questions.
La communauté russophone Apache NiFi sur Telegram est plus vivante que tous les êtres vivants, entrez.