L'un de ces aspects secondaires du développement logiciel est l'octroi de licences de code. Pour certains développeurs, les licences semblent être une forêt quelque peu sombre, ils essaient de ne pas y entrer et soit ne comprennent pas les différences et les règles de licence en général, soit ils les connaissent plutôt superficiellement, c'est pourquoi ils peuvent commettre divers types de violations. La plus courante de ces violations est la copie (réutilisation) et la modification du code en violation des droits de son auteur.
Toute aide aux gens commence par la recherche de la situation actuelle - premièrement, la collecte de données est nécessaire pour la possibilité d'une automatisation supplémentaire, et deuxièmement, leur analyse nous permettra de découvrir ce que les gens font exactement de mal. Dans cet article, je décrirai une telle étude: je vous présenterai les principaux types de licences logicielles (ainsi que plusieurs rares, mais notables), je parlerai de l'analyse du code et de la recherche d'emprunts dans une grande quantité de données, et je donnerai des conseils sur la manière de gérer correctement les licences dans le code et évitez les erreurs courantes.
Une introduction aux licences de code
Sur Internet, et même sur Habré , il existe déjà des descriptions détaillées des licences, nous nous limiterons donc à un bref aperçu du sujet nécessaire pour comprendre l'essence de l'étude.
Nous ne parlerons que de la licence de logiciels open source . Premièrement, cela est dû au fait que c'est dans ce paradigme que l'on peut facilement trouver un grand nombre de données disponibles, et deuxièmement, le terme même de «logiciel open source»peut être trompeur. Lorsque vous téléchargez et installez un programme propriétaire commun à partir du site Web de la société, vous êtes invité à accepter les termes de la licence. Bien sûr, vous ne les lisez généralement pas, mais en général, vous comprenez qu'il s'agit de la propriété intellectuelle de quelqu'un. En même temps, lorsque les développeurs entrent dans un projet sur GitHub et voient tous les fichiers source, l'attitude à leur égard est complètement différente: oui, il y a une sorte de licence là-bas, mais c'est open source , et le logiciel est open source , ce qui signifie que vous pouvez simplement prendre et fais ce que tu veux, non? Malheureusement, tout n'est pas si simple.
Comment fonctionne la licence? Commençons par la division la plus générale des droits:
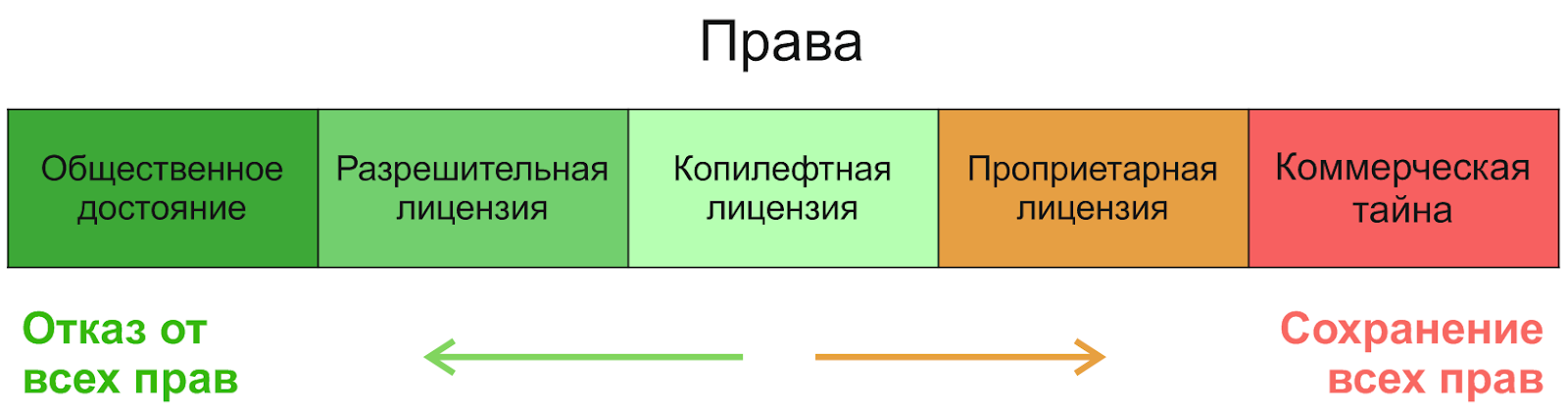
Si vous allez de droite à gauche, le premier sera un secret commercial, suivi de licences propriétaires - nous ne les considérerons pas. Dans le domaine des logiciels open source, on distingue trois catégories (en termes de degré d'augmentation des libertés): les licences restrictives ( copyleft ), les licences non restrictives ( permissives , permissives) et le domaine public.(qui n'est pas une licence, mais une manière d'accorder des droits). Pour comprendre la différence entre eux, il est utile de savoir pourquoi ils sont même apparus. Le concept du domaine public est aussi vieux que le monde - le créateur refuse complètement tout droit et lui permet de faire ce qu'il veut avec son produit. Cependant, curieusement, de cette liberté naît la non-liberté - après tout, une autre personne peut prendre une telle création, la modifier légèrement et faire «n'importe quoi» avec elle - y compris la fermer et la vendre. Les licences open source Copyleft ont été créées précisément pour protéger la liberté - de leur position dans l'image, vous pouvez voir qu'elles sont destinées à maintenir un équilibre: permettre l'utilisation, le changement et la distribution du produit, mais pas le verrouiller, le laisser libre. De plus, même si l'auteur ne se soucie pas du scénario de clôture et de vente,les concepts du domaine public diffèrent d'un pays à l'autre et peuvent donc créer des complications juridiques. Pour les éviter, de simples licences permissives sont utilisées.
Alors, quelle est la différence entre les licences permissives et copyleft? Comme tout dans notre sujet, cette question est assez spécifique, et il y a des exceptions, mais si vous simplifiez, les licences permissives n'imposent pas de restrictions sur la licence du produit modifié. Autrement dit, vous pouvez prendre un tel produit, le modifier et le mettre dans un projet sous une licence différente, même propriétaire. La principale différence avec le domaine public ici est le plus souvent l'obligation de préserver la paternité et la mention de l'auteur original. Les licences permissives les plus connues sont les licences MIT, BSD et Apache .... De nombreuses études indiquent que le MIT est la licence open source la plus courante en général, et notent également la croissance significative de la popularité de la licence Apache-2.0 depuis sa création en 2004 (par exemple, l' étude pour Java ).
Les licences Copyleft imposent le plus souvent des restrictions sur la distribution et la modification des sous-produits - vous obtenez un produit avec certains droits, et vous devez «l'exécuter plus loin», donnant à tous les utilisateurs les mêmes droits. Cela signifie généralement une obligation de redistribuer le logiciel sous la même licence et de donner accès au code source. Sur la base de cette philosophie, Richard Stallman a créé la première et la plus populaire licence de copyleft, la GNU General Public License (GPL). C'est elle qui assure la protection maximale de la liberté pour les futurs utilisateurs et développeurs. Je recommande de lire l'histoire du mouvement de Richard Stallman pour le logiciel libre, c'est très intéressant.
Il existe une difficulté avec les licences de copyleft - elles sont traditionnellement divisées en copyleft fort et faible . Un copyleft fort est exactement ce qui est décrit ci-dessus, tandis qu'un copyleft faible offre diverses concessions et exceptions pour les développeurs. L'exemple le plus célèbre d'une telle licence est la GNU Lesser General Public License (LGPL): comme son ancienne version, il vous permet de modifier et de redistribuer le code uniquement si vous conservez cette licence, mais lors de la liaison dynamique (en l'utilisant comme bibliothèque dans une application), cette exigence peut être omise. En d'autres termes, si vous voulez emprunter le code source à partir d'ici ou changer quelque chose, observez le copyleft, mais si vous voulez simplement l'utiliser comme bibliothèque de liens dynamiques, vous pouvez le faire n'importe où.
Maintenant que nous avons compris les licences elles-mêmes, nous devons parler de leur compatibilité , car c'est en elle (ou plutôt en son absence) que résident les violations que nous voulons empêcher. Quiconque s'est déjà intéressé à ce sujet devrait avoir rencontré des schémas de compatibilité de licence comme celui-ci:

D'un seul coup d'œil à un tel schéma, tout désir de comprendre les licences peut disparaître. En effet, il existe de nombreuses licences open source , une liste assez exhaustive peut être trouvée, par exemple, ici . Dans le même temps, comme vous le verrez ci-dessous dans les résultats de notre étude, vous devez connaître un montant très limité (en raison de leur répartition extrêmement inégale), et encore moins de règles dont il faut se souvenir afin de respecter toutes leurs conditions. Le vecteur général de ce schéma est assez simple: à la source de tout se trouve le domaine public, derrière il y a des licences permissives, puis un copyleft faible, et enfin, un copyleft fort, et les licences sont compatibles «droit»: dans un projet copyleft, on peut réutiliser le code sous une licence permissive, mais pas l'inverse - tout est logique.
Ici, la question peut se poser: que faire si le code n'a pas de licence? Quelles règles suivre alors? Ce code peut-il être copié? C'est en fait une question très importante. Probablement, si le code est écrit sur une clôture, il peut être considéré comme du domaine public, et s'il est écrit sur du papier dans une bouteille, qui a été clouée sur une île déserte (sans droit d'auteur), alors il peut être simplement pris et utilisé. En ce qui concerne les grandes plates-formes bien établies telles que GitHub ou StackOverflow, les choses ne sont pas si simples, car en les utilisant simplement, vous acceptez automatiquement leurs conditions d'utilisation. Pour l'instant, laissons juste une note à ce sujet dans notre tête et y revenons plus tard - à la fin, c'est peut-être une rareté et il n'y a pratiquement pas de code sans licence?
Énoncé du problème et méthodologie
Alors, maintenant que nous connaissons le sens de tous les termes, soyons clairs sur ce que nous voulons savoir.
- Quelle est la fréquence de copie de code dans les logiciels open source? Y a-t-il de nombreux clones dans le code parmi les projets open source ?
- Sous quelles licences existe-t-il? Quelles sont les licences les plus courantes? Le fichier contient-il plusieurs licences à la fois?
- Quels sont les emprunts possibles les plus courants, c'est-à-dire les transferts de code d'une licence à une autre?
- Quelles sont les violations possibles les plus courantes, c'est-à-dire les transitions de code interdites par les termes de la licence d'origine ou de la licence destinataire?
- Quelle est l'origine possible de fragments de code individuels? Quelle est la probabilité que ce morceau de code ait été copié en violation?
Pour réaliser une telle analyse, nous avons besoin:
- Créez un ensemble de données à partir d'un grand nombre de projets open source.
- Trouvez des clones d'extraits de code parmi eux.
- Identifiez les clones qui peuvent vraiment être empruntés.
- Pour chaque fragment de code, définissez deux paramètres - sa licence et l'heure de sa dernière modification, qui est nécessaire pour savoir quel fragment d'une paire de clones est le plus ancien et lequel est plus jeune, et donc - qui pourrait potentiellement copier de qui.
- Déterminez quelles transitions possibles entre les licences sont autorisées et lesquelles ne le sont pas.
- Analysez toutes les données obtenues afin de répondre aux questions ci-dessus.
Examinons maintenant de plus près chaque étape.
Collecte de données
Il est très pratique pour nous qu'aujourd'hui, il soit facile d'accéder à beaucoup d'open source en utilisant GitHub. Il contient non seulement le code lui-même, mais également l'historique de ses modifications, ce qui est très important pour cette étude: afin de savoir qui pourrait copier le code à partir de qui, vous devez savoir quand chaque fragment a été ajouté au projet.
Pour collecter des données, vous devez choisir le langage de programmation étudié. Le fait est que les clones sont recherchés dans le cadre d'un langage de programmation: en parlant d'une violation de licence, il est plus difficile d'évaluer la réécriture d'un algorithme existant dans un autre langage. Ces concepts complexes sont protégés par des brevets, alors que dans nos recherches, nous parlons de copie et de modification plus typiques. Nous avons choisi Java car c'est l'un des langages les plus utilisés et particulièrement populaire dans le développement de logiciels commerciaux - auquel cas les violations de licence potentielles sont particulièrement importantes.
Nous avons pris comme base les archives publiques Git existantes, qui au début de 2018 rassemblaient tous les projets sur GitHub qui comptaient plus de 50 étoiles. Nous avons sélectionné tous les projets qui ont au moins une ligne en Java et les avons téléchargés avec un historique complet des modifications. Après avoir filtré les projets qui ont été déplacés ou qui ne sont plus disponibles, 23 378 projets occupent environ 1,25 To d'espace disque.
De plus, pour chaque projet, nous avons vidé la liste des fourches et trouvé des paires de fourches dans notre ensemble de données - cela est nécessaire pour un filtrage plus poussé, car nous ne sommes pas intéressés par les clones entre les fourches. Il y avait 324 projets au total avec des fourches à l'intérieur du jeu de données.
Trouver des clones
Pour trouver des clones, c'est-à-dire des morceaux de code similaires, vous devez également prendre des décisions. Tout d'abord, nous devons décider dans quelle mesure et dans quelle mesure nous sommes intéressés par un code similaire. Traditionnellement, il existe 4 types de clones (du plus précis au moins précis):
- Les clones identiques sont exactement les mêmes morceaux de code qui ne peuvent différer que par des décisions stylistiques, telles que des retraits, des lignes vides et des commentaires.
- Les clones renommés incluent le premier type, mais peuvent en outre différer dans les noms de variable et d'objet.
- Les clones proches incluent tous les éléments ci-dessus, mais peuvent contenir des modifications plus importantes, telles que l'ajout, la suppression ou le déplacement d'expressions, dans lesquelles les fragments sont toujours similaires.
- , — , ( ), ().
Nous nous intéressons à la copie et à la modification, nous ne considérons donc que les clones des trois premiers types.
La deuxième décision importante est la taille des clones à rechercher. Des fragments de code identiques peuvent être recherchés parmi des fichiers, des classes, des méthodes, des expressions individuelles ... Dans notre travail, nous avons pris la méthode comme base , car il s'agit de la granularité de recherche la plus équilibrée: souvent les gens ne copient pas le code dans des fichiers entiers, mais dans de petits fragments, mais en même temps la méthode - c'est toujours une unité logique complète.
Sur la base des solutions sélectionnées, pour trouver des clones, nous avons utilisé SourcererCC - un outil qui recherche des clones en utilisant la méthode du sac de mots: chaque méthode est représentée comme une liste de fréquences de jetons (mots-clés, noms et littéraux), après quoi ces ensembles sont comparés, et si plus d'une certaine proportion de jetons dans deux méthodes coïncident (une telle proportion est appelée le seuil de similitude), alors une telle paire est considérée comme un clone. Malgré la simplicité de cette méthode (il existe des méthodes beaucoup plus complexes basées sur l'analyse d'arbres syntaxiques de méthodes et même de leurs graphes de dépendance de programme), son principal avantage est l' évolutivité : avec une telle quantité de code, comme la nôtre, il est important que la recherche de clones se fasse très rapidement ...
Nous avons utilisé différents seuils de similitude pour trouver différents clones, et également mené une recherche séparée avec un seuil de similitude de 100%, dans lequel seuls des clones identiques ont été identifiés. En outre, une taille minimale de la méthode étudiée a été définie pour éliminer les morceaux de code triviaux et génériques qui pourraient ne pas être empruntés.
Cette recherche a nécessité jusqu'à 66 jours de calculs continus, 38,6 millions de méthodes ont été identifiées, dont seulement 11,7 millions ont dépassé le seuil de taille minimale, et dont 7,6 millions ont participé au clonage. Un total de 1,2 milliard de paires de clones a été trouvé.
Heure de la dernière modification
Pour une analyse plus approfondie, nous n'avons sélectionné que des paires de clones entre projets , c'est-à-dire des paires de fragments de code similaires qui se trouvent dans différents projets. Du point de vue des licences, nous ne sommes pas très intéressés par les fragments de code au sein d'un même projet: il est considéré comme une mauvaise pratique de répéter son propre code, mais ce n'est pas interdit. Au total, il y avait environ 561 millions de paires inter-projets, soit environ la moitié de toutes les paires. Ces paires comprenaient 3,8 millions de méthodes, pour lesquelles il était nécessaire de déterminer l'heure de la dernière modification. Pour ce faire, la commande git blame a été appliquée à chaque fichier (qui s'est avéré être 898000, car il peut y avoir plus d'une méthode dans les fichiers) , ce qui donne l'heure de la dernière modification pour chaque ligne du fichier.
Nous avons donc l'heure de la dernière modification pour chaque ligne de la méthode, mais comment déterminer l'heure de la dernière modification de l'ensemble de la méthode? Cela semble évident - vous prenez l'heure la plus récente et l'utilisez: après tout, cela montre vraiment quand la méthode a été modifiée pour la dernière fois. Cependant, pour notre tâche, une telle définition n'est pas idéale. Prenons un exemple:
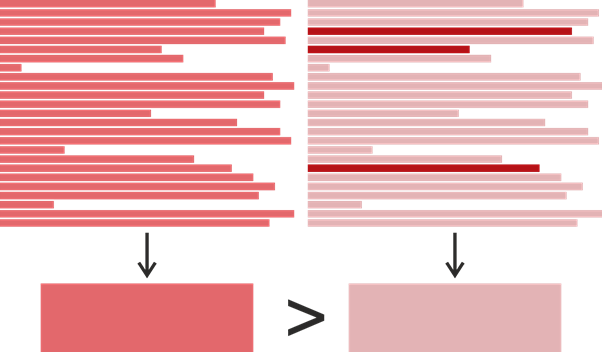
Supposons que nous ayons trouvé un clone sous la forme de quelques fragments de 25 lignes chacun. Une couleur plus saturée signifie ici une heure de modification ultérieure. Disons que le fragment de gauche a été écrit à un moment en 2017, et dans le fragment de droite, 22 lignes ont été écrites en 2015, et trois ont été modifiées en 2019. Il s'avère que le fragment de droite a été modifié plus tard, mais si nous voulions déterminer qui pouvait copier de qui, il serait plus logique de supposer le contraire: le fragment de gauche a emprunté le fragment de droite, et le fragment de droite a légèrement changé plus tard. Sur cette base, nous avons défini l'heure de la dernière modification d'un morceau de code comme l' heure la plus fréquente de la dernière modification de ses lignes individuelles. Si soudainement il y en avait plusieurs, une plus tardive était choisie.
Fait intéressant, le plus ancien morceau de code de notre ensemble de données a été écrit dès avril 1997, à l'aube même de Java, et il a trouvé un clone réalisé en 2019!
Définition des licences
La deuxième étape et la plus importante consiste à déterminer la licence pour chaque bloc. Pour cela, nous avons utilisé le schéma suivant. Pour commencer, à l'aide de l'outil Ninka , la licence indiquée directement dans l'en-tête du fichier a été déterminée. S'il y en a une, elle est considérée comme une licence pour chaque méthode (Ninka est capable de reconnaître plusieurs licences en même temps). Si rien n'est spécifié dans le fichier ou si des informations insuffisantes sont spécifiées (par exemple, uniquement les droits d'auteur), la licence de l'ensemble du projet auquel appartient le fichier a été utilisée. Les données à ce sujet étaient contenues dans l'archive publique Git originale, sur la base de laquelle nous avons collecté un ensemble de données, et ont été déterminées à l'aide d'un autre outil - Go License Detector . Si la licence n'est pas dans le fichier ou dans le projet, ces méthodes ont été marquées commeGitHub , car ils sont alors soumis aux conditions d'utilisation de GitHub (où toutes nos données ont été téléchargées).
Après avoir défini toutes les licences de cette manière, nous pouvons enfin répondre à la question de savoir quelles licences sont les plus populaires. Nous avons trouvé 94 licences différentes au total . Nous fournissons ici des statistiques pour les fichiers afin de compenser les éventuels plis dus aux fichiers très volumineux avec de nombreuses méthodes.
La principale caractéristique de ce calendrier est la répartition inégale la plus forte des licences. Trois zones peuvent être vues dans le graphique: deux «licences» avec plus de 100 000 fichiers, dix autres avec 10 à 100 000 et une longue traîne de licences avec moins de 10 000 fichiers.
Considérons d'abord les plus populaires, pour lesquelles nous présentons les deux premiers domaines dans une échelle linéaire:
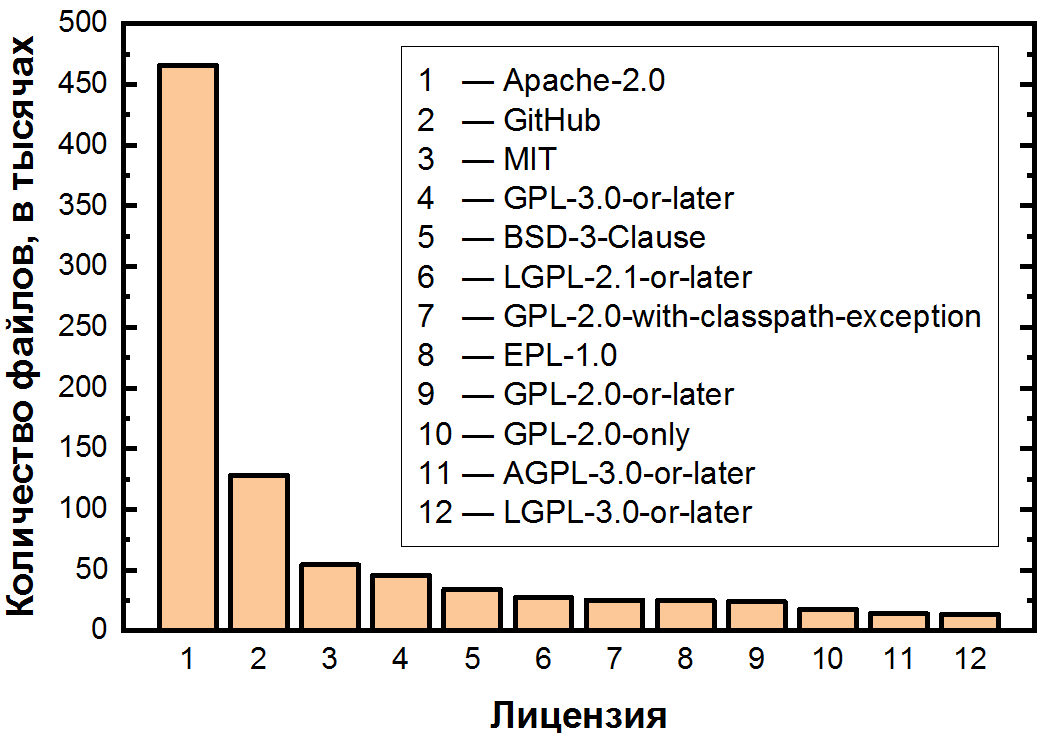
On peut voir des inégalités même parmi les licences les plus populaires. Apache-2.0, la plus équilibrée de toutes les licences permissives, occupe la première place par une énorme marge; elle couvre un peu plus de la moitié de tous les fichiers.
Elle est suivie de l'absence notoire de licence, et nous devons encore l'analyser plus en détail, car cette situation est si courante même parmi les dépôts moyens et grands (plus de 50 étoiles). Cette circonstance est très importante, car le simple téléchargement du code sur GitHub ne le rend pas ouvert.- et s'il y a quelque chose de pratique et que vous devez vous rappeler de cet article, alors c'est ça. En téléchargeant votre code sur GitHub, vous acceptez les conditions d'utilisation, qui stipulent que votre code peut être consulté et forké. Cependant, à l'exception de cela, tous les droits sur le code restent avec l'auteur, par conséquent, la distribution, la modification et même l'utilisation nécessitent une autorisation explicite. Il s'avère que non seulement tout open source n'est pas totalement gratuit, mais même pas tout le code sur GitHub n'est pas entièrement open source! Et comme il y a beaucoup de code de ce type (14% des fichiers, et parmi les projets les moins populaires qui ne sont pas inclus dans l'ensemble de données, probablement encore plus), cela peut être la cause d'un nombre important de violations.
Dans le top cinq, nous voyons également les licences permissives déjà mentionnées du MIT et BSD, ainsi que le copyleft GPL-3.0 ou version ultérieure. Les licences de la famille GPL diffèrent non seulement par un nombre important de versions (pas si mal), mais aussi par le post-scriptum «ou plus récent», qui permet à l'utilisateur d'utiliser les termes de cette licence ou de ses versions ultérieures. Cela conduit à une autre question: parmi ces 94 licences, il existe clairement des «familles» similaires - lesquelles sont les plus importantes?
En troisième lieu, il y a les licences GPL - il y en a 8 types dans la liste. Cette famille est la plus importante, car ensemble, ils couvrent 12,6% des fichiers, juste derrière Apache-2.0 et l'absence de licence. En deuxième lieu, de manière inattendue, BSD. En plus de la version 3 du paragraphe traditionnel et même les versions 2 et 4 paragraphe, il y a trèslicences spécifiques - seulement 11 pièces. Celles-ci incluent, par exemple, le BSD 3-Clause No Nuclear License , qui est un BSD régulier avec 3 clauses, auquel il est indiqué ci-dessous que ce logiciel ne doit pas être utilisé pour créer ou exploiter quoi
que ce soit de nucléaire: Vous reconnaissez que ce logiciel n'est pas conçu, autorisé ou destiné à être utilisé dans la conception, la construction, l'exploitation ou l'entretien de toute installation nucléaire.
La plus diversifiée est la famille de licences Creative Commons, que vous pouvez lire ici . Il y en avait jusqu'à 13, et ils valent également la peine d'être parcourus pour une raison importante: tout le code de StackOverflow est sous licence CC-BY-SA.
Parmi les licences les plus rares, il y en a quelques-unes notables, par exemple,Do What The F * ck You Want To Public License (WTFPL) , qui couvre 529 fichiers et vous permet de faire exactement ce que le nom indique avec le code. Il y a aussi, par exemple, la licence Beerware , qui permet également de faire n'importe quoi et encourage l'auteur à acheter une bière lors d'une réunion. Dans notre ensemble de données, nous avons également rencontré une variante de cette licence, que nous n'avons trouvée nulle part ailleurs: la licence Sushiware . Elle encourage donc l'auteur à acheter des sushis.
Une autre situation curieuse est celle où plusieurs licences se trouvent dans un fichier (notamment dans le fichier). Dans notre ensemble de données, il n'y a que 0,9% de ces fichiers. 7,4 mille fichiers sont couverts par deux licences à la fois, et un total de 74 paires différentes de ces licences ont été trouvées. 419 fichiers sont couverts par jusqu'à trois licences, et il y a 8 triplets de ce type. Et enfin,un fichier de notre ensemble de données mentionne quatre licences différentes dans l'en-tête.
Emprunts possibles
Maintenant que nous avons parlé des licences, nous pouvons discuter de la relation entre elles. La première chose à faire est de supprimer les clones qui ne sont pas des emprunts possibles . Permettez-moi de vous rappeler que pour le moment, nous avons essayé de prendre cela en compte de deux manières: la taille minimale des fragments de code et l'exclusion des clones dans un projet. Nous allons maintenant filtrer trois autres types de paires:
- Nous ne sommes pas intéressés par les paires entre la fourche et l'original (ainsi que, par exemple, entre deux fourches du même projet) - pour cela, nous les avons collectées.
- Nous ne sommes pas non plus intéressés par les clones entre différents projets appartenant à la même organisation ou utilisateur (puisque nous supposons que le droit d'auteur est partagé au sein de la même organisation).
- Enfin, en vérifiant manuellement un nombre anormalement élevé de clones entre deux projets, nous avons trouvé des miroirs significatifs (ce sont aussi des fourches indirectes), c'est-à-dire des projets identiques téléchargés dans des référentiels indépendants.
Curieusement, jusqu'à 11,7% des paires restantes sont des clones identiques avec un seuil de similitude de 100% - peut-être intuitivement, il semble qu'il devrait y avoir du code moins absolument identique sur GitHub.
Nous traitons toutes les paires restantes après ce filtrage comme suit:
- Nous comparons l'heure de la dernière modification de deux méthodes dans une paire.
- , : .
- , «» «» . , 2015 MIT, 2018 — Apache-2.0, MIT → Apache-2.0.
Au final, nous avons résumé le nombre de paires pour chaque emprunt potentiel et les avons triées par ordre décroissant:
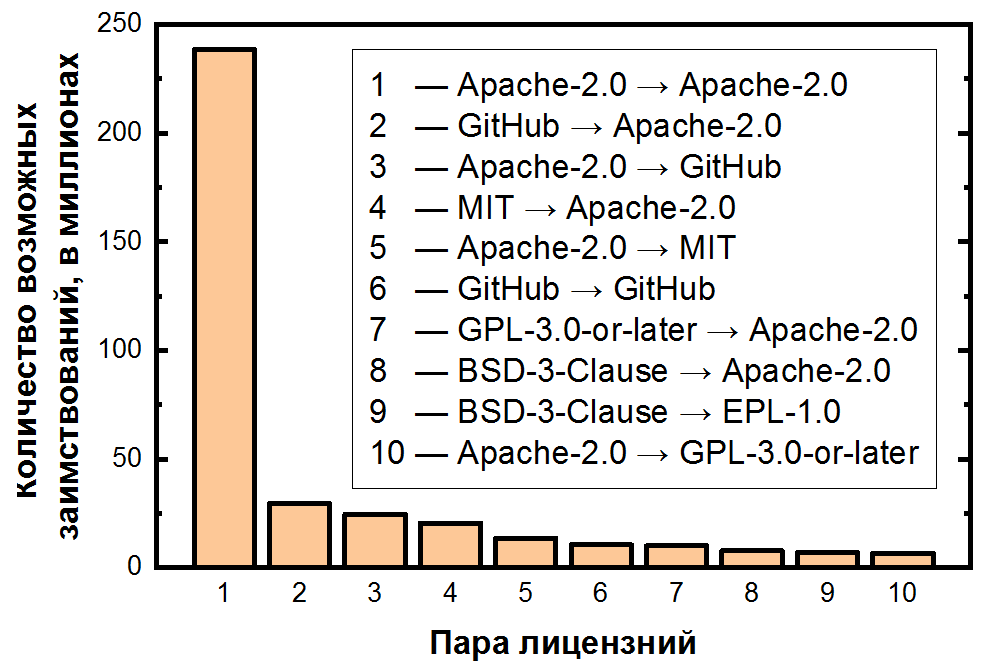
ici la dépendance est encore plus extrême: les emprunts possibles de code dans Apache-2.0 représentent plus de la moitié de toutes les paires de clones, et les 10 premières paires de licences couvrent déjà plus de 80% des clones. Il est également important de noter que les deuxième et troisième paires les plus fréquentes traitent des fichiers sans licence - également une conséquence claire de leur fréquence. Pour les cinq licences les plus populaires, vous pouvez afficher les transitions sous forme de carte thermique:
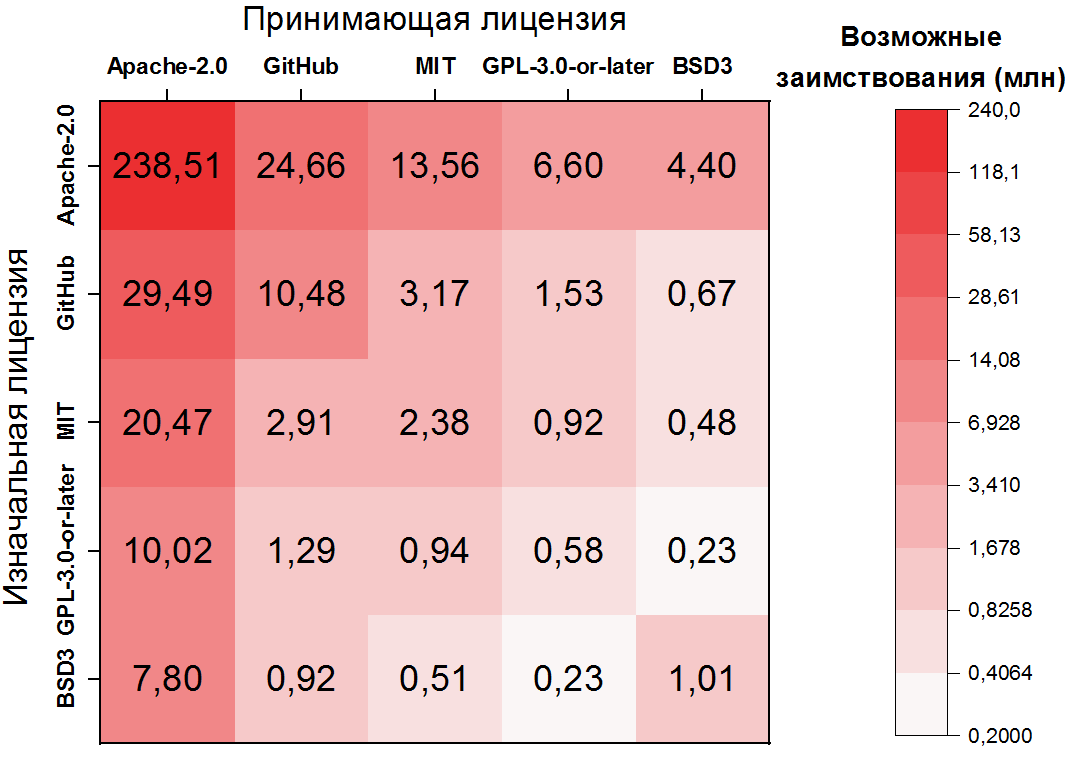
Possibles violations de licence
La prochaine étape de notre recherche consiste à identifier les paires de clones qui sont des violations potentielles , c'est-à-dire des emprunts qui ne respectent pas les termes des licences d'origine et d'hôte. Pour ce faire, vous devez marquer les paires de licences mentionnées ci-dessus comme des transitions autorisées ou interdites . Ainsi, par exemple, la transition la plus populaire ( Apache-2.0 → Apache-2.0 ) est bien sûr autorisée, mais la seconde ( GitHub → Apache-2.0 ) est interdite. Mais il y en a très, très nombreux, il y en a des milliers.
Pour faire face à cela, rappelez-vous que les 10 premières paires de licences rendues couvrent 80% de toutes les paires de clones. En raison de cette inégalité, il s'est avéré suffisant de marquer manuellement seulement 176 paires de licences pour couvrir 99% des paires de clones, ce qui nous a semblé une précision tout à fait acceptable. Parmi ces couples, nous avons considéré quatre types de couples interdits:
- Copier à partir de fichiers sans licence (GitHub). Comme déjà mentionné, une telle copie nécessite l'autorisation directe de l'auteur du code, et nous supposons que dans la grande majorité des cas, ce n'est pas le cas.
- La copie dans des fichiers sans licence est également interdite, car il s'agit essentiellement d'effacer, de supprimer des licences. Les licences permissives comme Apache-2.0 ou BSD permettent de réutiliser le code dans d'autres licences (y compris les licences propriétaires), mais même celles-ci nécessitent que la licence d'origine soit conservée dans le fichier.
- .
- (, Apache-2.0 → GPL-2.0).
Toutes les autres rares paires de licences couvrant 1% des clones ont été marquées comme permissives (afin de ne blâmer personne inutilement), à l'exception de celles où le code sans licence apparaît (qui ne peut jamais être copié).
En conséquence, après la majoration, il s'est avéré que 72,8% des emprunts sont des emprunts autorisés et 27,2% sont interdits. Les graphiques suivants présentent les licences les plus violées et les plus violentes .

Sur la gauche se trouvent les licences les plus violées, c'est-à-dire les sources du plus grand nombre de violations possibles. Parmi eux, la première place est occupée par les fichiers sans licence, ce qui est une note pratique importante - vous devez surveiller de près les fichiers sans licence.... On peut se demander ce que fait la licence permissive Apache-2.0 dans cette liste. Cependant, comme le montre la carte thermique ci-dessus, environ 25 millions d'emprunts interdits sont des emprunts à un fichier sans licence, c'est donc une conséquence de sa popularité.
Sur la droite se trouvent les licences copiées avec des violations, et ici, la plupart sont les mêmes Apache-2.0 et GitHub.
Origine des méthodes individuelles
Enfin, nous arrivons au dernier point de nos recherches. Pendant tout ce temps, nous avons parlé de paires de clones, comme il est d'usage dans de telles études. Cependant, il faut comprendre un certain caractère unilatéral, incomplet de tels jugements. Le fait est que si, par exemple, un morceau de code a 20 frères "plus âgés" (ou "parents", qui sait), alors les 20 paires seront considérées comme des emprunts potentiels. C'est pourquoi nous parlons d'emprunts «potentiels» et «possibles» - il est peu probable que l'auteur d'une méthode particulière l'ait emprunté à 20 endroits différents. Malgré cela, ce raisonnement peut être considéré comme un raisonnement sur les clones entre différentes licences.
Pour éviter de tels jugements incomplets, vous pouvez regarder la même image sous un angle différent. L'image de clonage est en fait un graphe orienté: toutes les méthodes sont des sommets dessus, qui sont reliés par des arêtes dirigées de senior à junior (si vous ne prenez pas en compte les méthodes datées du même jour). Dans les deux sections précédentes, nous avons examiné ce graphe du point de vue des arêtes: nous avons pris chaque arête et étudié ses sommets (en obtenant ces mêmes paires de licences). Regardons maintenant cela du point de vue des sommets. Chaque sommet (méthode) du graphe a des ancêtres (clones "seniors") et des descendants (clones "juniors"). Les liens entre eux peuvent également être divisés en «autorisés» et «interdits».
Sur cette base, chaque méthode peut être attribuée à l'une des catégories suivantes, dont les graphiques sont affichés dans l'image (ici, les lignes pleines indiquent les emprunts interdits et les lignes en pointillés - autorisées):

Deux des configurations présentées peuvent constituer une violation des conditions de licence:
- Une violation grave signifie que la méthode a des ancêtres et que toutes les transitions à partir de ceux-ci sont interdites. Cela signifie que si le développeur a effectivement copié le code, il l'a fait en violation des licences.
- Une violation faible signifie que la méthode a des ancêtres et que seuls certains d'entre eux sont derrière des transitions interdites. Cela signifie que le développeur peut avoir copié le code en violation de la licence.
Les autres configurations ne sont pas des violations:
- , , .
- — , — , .
- , , — , . , , — , . : , , , , ( , , ).
Alors, comment les méthodes sont-elles réparties dans notre ensemble de données?

Vous pouvez voir qu'environ un tiers des méthodes n'ont aucun clone, et un autre tiers n'a des clones que dans les projets liés. D'autre part, 5,4% des méthodes représentent une «violation légère» et 4% - une «violation grave». Bien que ces chiffres ne semblent pas très importants, il existe encore des centaines de milliers de méthodes dans des projets plus ou moins grands.
TL; DR
Étant donné que cet article contient de nombreux chiffres et graphiques empiriques, répétons nos principales conclusions:
- Il existe des millions de méthodes qui ont des clones, et il y a plus d'un milliard de paires entre elles.
- , Java- 50 , 94 , : Apache-2.0 . Apache-2.0 .
- , 27,2%, .
- 35,4% , 5,4% «» , 4% «» .
?
En conclusion, je voudrais expliquer pourquoi tout ce qui précède est nécessaire. J'ai au moins trois réponses.
Tout d'abord, c'est intéressant . Les licences sont aussi diverses que tous les autres aspects de la programmation. La liste des licences elle-même est assez curieuse en raison de la spécificité et de la rareté de certaines licences, les gens écrivent et travaillent avec elles de différentes manières. Cela s'applique sans aucun doute également aux clones dans le code et à la similitude du code en général. Il existe des méthodes avec des milliers de clones, et il existe des méthodes sans un seul, alors qu'en un coup d'œil, il n'est pas toujours facile de remarquer la différence fondamentale entre elles.
Deuxièmement, une analyse détaillée de nos résultats nous permet de formuler plusieurs conseils pratiques :
- - . Apache-2.0, MIT, BSD-3-Clause, GPL LGPL.
- : . - , , .
- GitHub, . . — , . : - , , , , . , .
Pour des descriptions claires des licences, ainsi que des conseils sur le choix d'une licence pour votre nouveau projet, vous pouvez vous tourner vers des services tels que tldrlegal ou choosealicense .
Enfin, les données obtenues peuvent être utilisées pour créer des outils . En ce moment, nos collègues développent un moyen de déterminer rapidement les licences à l'aide de méthodes d'apprentissage automatique (pour lesquelles vous avez juste besoin de beaucoup de licences spécifiques) et d'un plugin IDE qui permettra aux développeurs de suivre les dépendances dans leurs projets et de remarquer à l'avance d'éventuelles incompatibilités.
J'espère que vous avez appris quelque chose de nouveau dans cet article. Le respect des conditions de licence de base n'est pas si compliqué, et vous pouvez tout faire selon les règles avec un minimum d'effort. Éduquons, éduquons les autres et rapprochons-nous du rêve du «bon» logiciel open source ensemble!