La surveillance des points de terminaison et des API internes de Kubernetes peut être problématique, en particulier si l'objectif est de tirer parti de l'infrastructure automatisée en tant que service. Chez Smarkets, nous n'avons pas encore atteint cet objectif, mais heureusement, nous en sommes déjà assez proches. J'espère que notre expérience dans ce domaine aidera d'autres personnes à mettre en œuvre quelque chose de similaire.
Nous avons toujours rêvé que les développeurs seraient en mesure de surveiller n'importe quelle application ou service hors de la boîte. Avant de passer à Kubernetes, cette tâche était effectuée soit à l'aide de métriques Prometheus, soit à l'aide de statsd, qui envoyait des statistiques à l'hôte sous-jacent, où elles étaient converties en métriques Prometheus. Alors que nous continuons à exploiter Kubernetes, nous avons commencé à séparer les clusters, et nous voulions faire en sorte que les développeurs puissent exporter des métriques directement vers Prometheus via des annotations de service. Hélas, ces métriques n'étaient disponibles qu'au sein du cluster, c'est-à-dire qu'elles ne pouvaient pas être collectées globalement.
Ces limitations constituaient le goulot d'étranglement de notre configuration pré-Kubernetes. Au final, ils ont obligé à repenser l'architecture et la manière de surveiller les services. Ce voyage sera discuté ci-dessous.
Le point de départ
Pour les métriques liées à Kubernetes, nous utilisons deux services qui fournissent des métriques:
-
kube-state-metricsgénère des métriques pour les objets Kubernetes en fonction des informations des serveurs API K8; -
kube-eagleexporte les métriques Prometheus pour les pods: leurs demandes, leurs limites, leur utilisation.
Il est possible (et nous le faisons depuis un certain temps) d'exposer des services avec des métriques en dehors du cluster ou d'ouvrir une connexion proxy à l'API, mais les deux options n'étaient pas idéales, car elles ralentissaient le travail et n'offraient pas l'indépendance et la sécurité nécessaires des systèmes.
En règle générale, une solution de surveillance a été déployée, consistant en un cluster central de serveurs Prometheus s'exécutant dans Kubernetes et collectant des métriques à partir de la plate-forme elle-même, ainsi que des métriques Kubernetes internes à partir de ce cluster. La principale raison pour laquelle cette approche a été choisie est que lors de la transition vers Kubernetes, nous avons collecté tous les services dans le même cluster. Après avoir ajouté des clusters Kubernetes supplémentaires, notre architecture ressemblait à ceci:
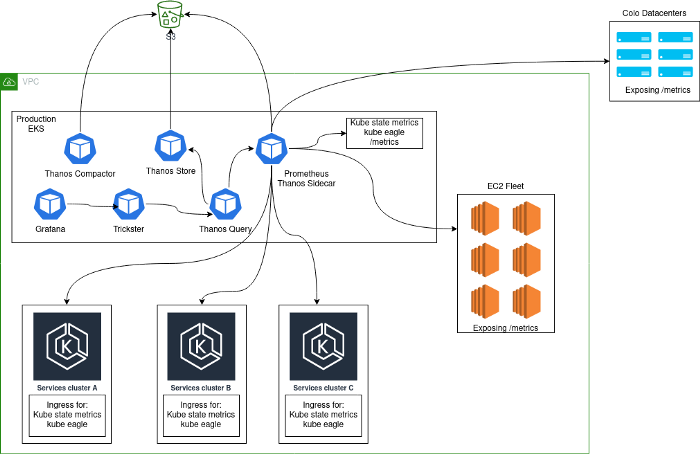
Problèmes
Une telle architecture ne peut pas être qualifiée de stable, efficace ou productive: après tout, les utilisateurs pourraient exporter des métriques statistiques à partir d'applications, ce qui a conduit à une cardinalité incroyablement élevée de certaines métriques. Vous connaissez peut-être des problèmes similaires si l'ordre de grandeur suivant vous semble familier.
Lors de l'analyse d'un bloc Prometheus de 2 heures:
- 1,3 million de métriques;
- 383 noms d'étiquettes;
- la cardinalité maximale par métrique est de 662 000 (la plupart des problèmes sont précisément à cause de cela).
Cette cardinalité élevée est principalement due à l'exposition des minuteries statsd qui incluent des chemins HTTP. Nous savons que ce n'est pas idéal, mais ces métriques sont utilisées pour suivre les bogues critiques dans les déploiements Canary.
En période de calme, environ 40 000 métriques étaient collectées par seconde, mais leur nombre pouvait atteindre 180 000 en l'absence de problème.
Certaines requêtes spécifiques pour les métriques à cardinalité élevée ont provoqué un manque de mémoire (prévisible) de Prometheus - une situation très frustrante lorsque Prometheus est utilisé pour alerter et évaluer les déploiements Canary.
Un autre problème était qu'avec trois mois de données stockées sur chaque instance Prometheus, le temps de démarrage (relecture WAL) était très élevé, ce qui entraînait généralement le routage de la même requête vers une deuxième instance Prometheus et " l'a déjà laissé tomber.
Pour résoudre ces problèmes, nous avons implémenté Thanos et Trickster:
- Thanos a permis à moins de données d'être stockées dans Prometheus et a réduit le nombre d'incidents causés par une utilisation excessive de la mémoire. À côté du conteneur, Prometheus Thanos exécute un conteneur side-car qui stocke des blocs de données dans S3, où ils sont ensuite compressés par thanos-compact. Ainsi, avec l'aide de Thanos, le stockage de données à long terme en dehors de Prometheus a été mis en œuvre.
- Trickster, pour sa part, agit comme un proxy inverse et un cache pour les bases de données de séries chronologiques. Cela nous a permis de mettre en cache jusqu'à 99,53% de toutes les demandes. La plupart des demandes proviennent de tableaux de bord fonctionnant sur des postes de travail / téléviseurs, d'utilisateurs avec des panneaux de contrôle ouverts et d'alertes. Un proxy qui ne peut générer que des delta dans des séries chronologiques est idéal pour ce type de charge de travail.
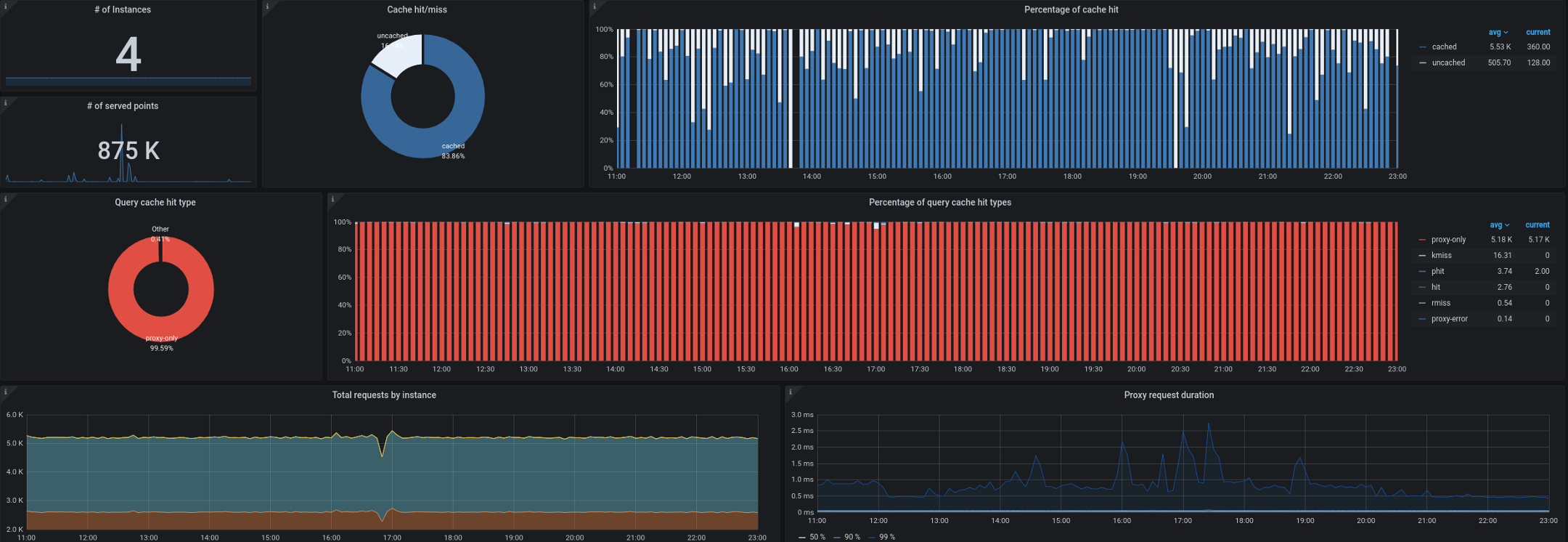
Nous avons également commencé à avoir des problèmes pour collecter des métriques d'état de kube en dehors du cluster. Comme vous vous en souvenez, nous devions souvent traiter jusqu'à 180 000 métriques par seconde, et la collecte ralentissait même lors de la définition de 40 000 métriques dans une seule métrique kube-state-metrics d'entrée. Nous avons un intervalle cible de 10 secondes pour collecter les métriques, et pendant les périodes de forte charge, ce SLA était souvent violé par la collecte à distance de kube-state-metrics ou kube-eagle.
Options
Tout en réfléchissant à la manière d'améliorer l'architecture, nous avons examiné trois options différentes:
- Prometheus + Cortex ( https://github.com/cortexproject/cortex );
- Réception de Prometheus + Thanos ( https://thanos.io );
- Prometheus + VictoriaMetrics ( https://github.com/VictoriaMetrics/VictoriaMetrics ).
Des informations détaillées à leur sujet et une comparaison des caractéristiques peuvent être trouvées sur Internet. Dans notre cas particulier (et après des tests sur des données à cardinalité élevée), VictoriaMetrics était clairement le gagnant.
Décision
Prométhée
Dans un effort pour améliorer l'architecture décrite ci-dessus, nous avons décidé d'isoler chaque cluster Kubernetes en tant qu'entité distincte et d'en faire partie Prometheus. Désormais, tout nouveau cluster est livré avec une surveillance "prête à l'emploi" et des métriques disponibles dans les tableaux de bord globaux (Grafana). Pour cela, les services kube-eagle, kube-state-metrics et Prometheus ont été intégrés dans les clusters Kubernetes. Prometheus a ensuite été configuré avec des étiquettes externes pour identifier le cluster et
remote_writeindiqué insertdans VictoriaMetrics (voir ci-dessous).
VictoriaMétrie
La base de données de séries temporelles VictoriaMetrics implémente les protocoles Graphite, Prometheus, OpenTSDB et Influx. Il prend non seulement en charge PromQL, mais lui ajoute également de nouvelles fonctionnalités et modèles, évitant ainsi la refactorisation des requêtes Grafana. De plus, ses performances sont incroyables.
Nous avons déployé VictoriaMetrics en mode cluster et l'avons divisé en trois composants distincts:
1. Stockage VictoriaMetrics (vmstorage)
Ce composant est responsable du stockage des données importées
vminsert. Nous nous sommes limités à trois répliques de ce composant, combinées dans un StatefulSet Kubernetes.
./vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
Insertion VictoriaMetrics (vminsert)
Ce composant reçoit les données des déploiements avec Prometheus et les transmet à
vmstorage. Le paramètre replicationFactor=2réplique les données sur deux des trois serveurs. Ainsi, si l'une des instances vmstoragerencontre des problèmes ou redémarre, il reste une copie disponible des données.
./vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
VictoriaMetrics sélectionner (vmselect)
Accepte les demandes PromQL de Grafana (Trickster) et demande des données brutes à partir de
vmstorage. Actuellement, nous avons désactivé cache ( search.disableCache), car l'architecture contient Trickster, qui est responsable de la mise en cache; par conséquent, il doit vmselecttoujours récupérer les dernières données complètes.
/vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
La grande image
L'implémentation actuelle ressemble à ceci:
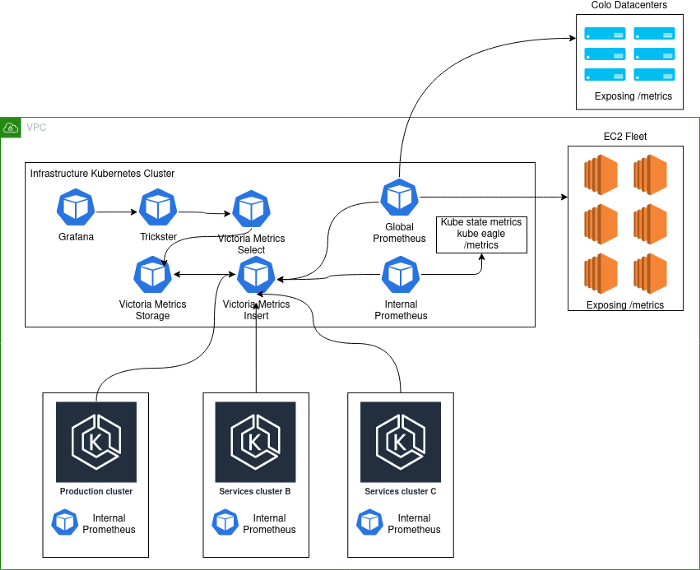
Notes de schéma:
- Production- . , K8s . - , . .
- deployment K8s Prometheus', VictoriaMetrics insert Kubernetes.
- Kubernetes deployment' Prometheus, . , , Kubernetes , . Global Prometheus EC2, colocation- -Kubernetes-.
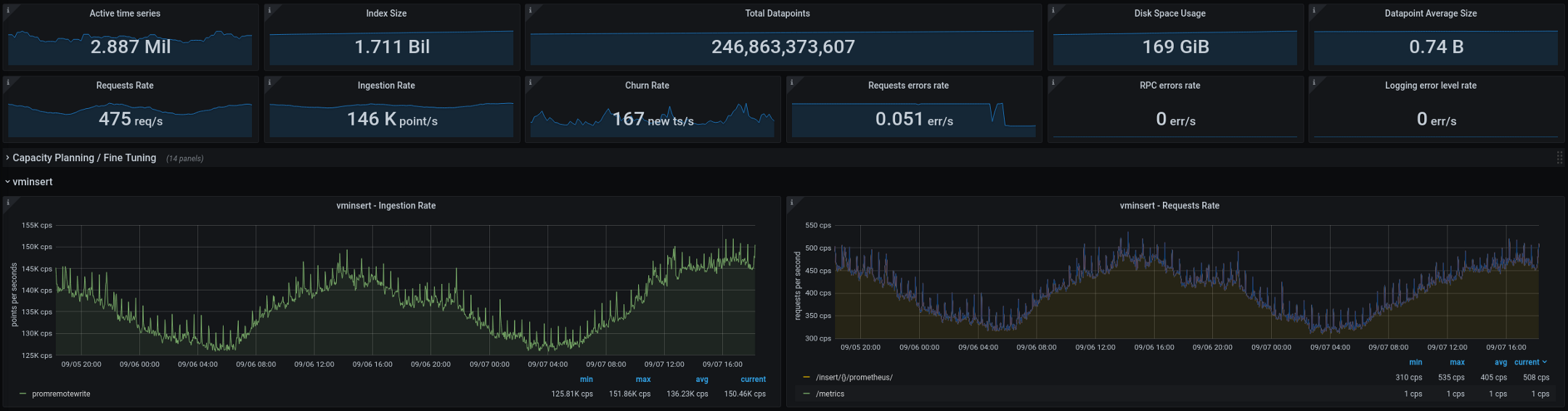
Voici les métriques que VictoriaMetrics est en train de traiter (totaux sur deux semaines, les graphiques montrent un écart de deux jours): La nouvelle architecture a bien fonctionné après avoir été transférée en production. Sur l'ancienne configuration, nous avions deux ou trois «explosions» de cardinalité toutes les deux semaines, sur la nouvelle, leur nombre tombait à zéro. C'est un excellent indicateur, mais il y a encore quelques choses que nous prévoyons d'améliorer dans les mois à venir:
- Réduisez la cardinalité des métriques en améliorant l'intégration de statsd.
- Comparez la mise en cache dans Trickster et VictoriaMetrics - vous devez évaluer l'impact de chaque solution sur l'efficacité et les performances. On soupçonne que Trickster peut être complètement abandonné sans rien perdre.
- Prometheus stateless- — stateful, . , StatefulSet', ( pod disruption budgets).
-
vmagent— VictoriaMetrics Prometheus- exporter'. , Prometheus , .vmagentPrometheus ( !).
Si vous avez des suggestions ou des idées pour les améliorations décrites ci-dessus, veuillez nous contacter . Si vous travaillez à améliorer la surveillance de Kubernetes, nous espérons que cet article, décrivant notre parcours difficile, vous a été utile.
PS du traducteur
Lisez aussi sur notre blog:
- « L'avenir de Prométhée et de l'écosystème du projet (2020) »;
- " Monitoring et Kubernetes " (revue et reportage vidéo);
- " Le dispositif et le mécanisme de l'opérateur Prometheus dans Kubernetes ."