Cet article est une extension du précédent: Automatiser Jira Analytics avec Apache NiFi . Maintenant, je voudrais développer notre vision du reportage sur Jira Software et l'expérience de sa mise en œuvre en utilisant R. Le langage ici, bien sûr, n'est pas un dogme. Aujourd'hui, tout est un concept. L'image est empruntée ici .

Imaginons un tracker de tâches. Quelles données puis-je, en tant qu'analyste, en extraire? Ou une plate-forme d'analyse prête à l'emploi? Le nombre de tâches pour la période, les statistiques de journalisation, la ventilation de base en projets, quelques photos sur la productivité des employés ... et c'est tout, désinvolte.
Mais tout ce qui est fait est mis en graisse. Par conséquent, vous pouvez probablement choisir quelque chose de plus global: ce que fait l'équipe et dans quelle direction elle évolue.
Oui, nous l'avons fait. Cependant, ce n'était pas sans l'aide de PM d'abord.
Réorganisation du tracker de tâches
Bien sûr, chaque Jira spécifique est très différent des autres. Et notre solution n'est peut-être pas la plus efficace pour vous, ni même applicable du tout.
Je vous demande de ne considérer cela que comme une idée d'organiser un tracker de tâches, en utilisant l'exemple de notre société de sous-traitance.
Nous n'avons fait que deux mouvements.
Premier et plus simple. Il a été admis que toutes les tâches dans une même direction doivent être liées à l'épopée , bien sûr . Les épopées sont les plus gros objets de Jira, représentant plusieurs problèmes. Ils aident à construire la hiérarchie et la structure et peuvent également couvrir plusieurs sprints et versions.
Un peu plus sur le second. Nous pourrons avoir une vue d'ensemble et répondre aux questions stratégiques sile workflow sera présenté comme une sorte de flux auquel chaque collaborateur contribue . Pour cela, dans notre cas, le concept IT4IT est parfaitement adapté, avec son modèle de fonctionnement basé sur une chaîne de valeur à quatre flux: en fait, qu'avons-nous fait. Profitant d'IT4IT, nous avons ajouté un composant de tâche à Jira. Nous avons les éléments suivants:

- Service au portefeuille (demande et sélection) - l'étape de "picking", recherche, choix de service, technologie.
- Demande de déploiement ( planification et conception) - discussion, planification du développement, développement de services, services.
- Request to Deploy (Develop) - développement d'un service, service de quelque chose.
- Demande de déploiement (déploiement) - déploiement de quelque chose.
- Demande de déploiement (test) - test d'un service, d'un service.
- Request to Fulfill - l'étape de l'exploitation des services développés, la fourniture de services.
- Détecter pour corriger (corriger) - correction, amélioration des services et services internes.
- Détecter pour corriger (Monitor & Feedback) - la même chose, seulement + communication avec le client.
À ce stade, le plus difficile est peut-être de convaincre les employés qu'un élément supplémentaire du tracker n'est pas pour rien et qu'il doit être rempli correctement.
Analyse de données dans R
Il ne devrait plus y avoir d’obstacles à la mise en œuvre des rapports. Je formulerai la similitude des savoirs traditionnels.
Étant donné qu'au début de chaque semaine, l'équipe se réunit pour le mit pour la planification, le rapport devrait être hebdomadaire. Il est important pour nous de voir des statistiques sur l'apparition et l'avancement des tâches, la journalisation des employés et la contribution de chacun d'entre eux à l'image globale. Répondez à la question: que fait l'équipe - en termes d'épopées et de composants.
Sachant ce que nous devons obtenir, nous allons décharger les données. Grâce à l'API Jira, nous demandons tous les problèmes (problèmes) qui ont été mis à jour la semaine dernière. Nous en extrayons les clés et chargeons l'historique de journalisation (journal de travail) et l'historique des modifications (changelog) pour chaque tâche. Des perversions avec surcharge sont nécessaires pour contourner les restrictions d'apish.
Ensuite, la zone de responsabilité R commence, car le prétraitement des données reçues est un composant du script de génération de rapport.
Il n'y a rien d'intelligent dedans, il vous suffit d'analyser les JSON qui proviennent de l'API et de ne laisser que les propriétés nécessaires (éléments dans Jira). Le seul moment, lors du traitement du journal des modifications, nous ne sommes intéressés que par les changements d'état de la tâche, le reste peut être supprimé en toute sécurité.
Et enfin, nous sommes arrivés à l'analyse.
Découvrez combien de tâches ont été ouvertes, étaient en cours, clôturées et reportées au cours de la semaine écoulée. Jetez un œil au code R:
#
this_week_opened <- jira_changelog_data %>%
filter(issue_type != "Epic") %>%
filter(as.Date(issue_created) >= start_date) %>%
filter(as.Date(issue_created) <= end_date) %>%
select(key, issue_created) %>% unique() %>% nrow()
#
this_week_processed <- jira_worklog_data %>%
filter(as.Date(started) >= start_date) %>%
filter(as.Date(started) <= end_date) %>%
select(key) %>% unique() %>% nrow()
#
this_week_closed <- jira_changelog_data %>%
filter(issue_type != "Epic") %>%
filter(as.Date(issue_resolutiondate) >= start_date) %>%
filter(as.Date(issue_resolutiondate) <= end_date) %>%
select(key, issue_created) %>% unique() %>% nrow()
# /
this_week_holded <- issue_history %>%
filter(change_date >= start_date) %>%
filter(change_date <= end_date) %>%
filter(toString == "Hold" | toString == "Backlog") %>%
select(key) %>% unique() %>% nrow()Cela vous rappelle-t-il le pseudocode? Et si je dis que l'opérateur ' %>% ' transfère les données de la fonction précédente à la suivante. Et la dernière modification de la chaîne entière sera enregistrée dans une variable. Imaginez, nous venons de grimper au seuil d'entrée en R!
Êtes-vous déjà tombé amoureux de lui? Ensuite, si vous le souhaitez, j'ajouterai quelques informations supplémentaires.
Mots de Wikipedia:
En général, en tant que langage de programmation, R est assez simple et même primitif. Sa plus grande force est son expansion illimitée avec des packages.
La livraison de base R comprend un ensemble de packages de base et, au total, en 2019, plus de 15316 packages sont disponibles.
Et la dernière chose pour aujourd'hui. Cette année, R est entré dans le top 10 des langues les plus populaires au monde ( preuve ). Je suis fier de lui.
Veuillez me pardonner cette retraite. Je peux parler de R pendant des heures. C'est juste qu'il est complètement enveloppé de mythes, et j'aime les détruire - un passe-temps, vous savez.
Revenons au rapport. Ayant les nombres requis, nous les visualisons. Après cela, nous faisons la journalisation des employés. Voici à quoi ressemble cette partie avec nous: je continuerai à vous montrer les images finales du même rapport réel. Notre secteur d'activité est reflété dans le graphique suivant. Il vous permet également d'évaluer la charge de travail des employés ayant des activités opérationnelles. Et voici une ventilation de toutes les tâches par composant. Il donne la réponse à la question de savoir ce que nous faisons. Je complète le tableau avec des chiffres.
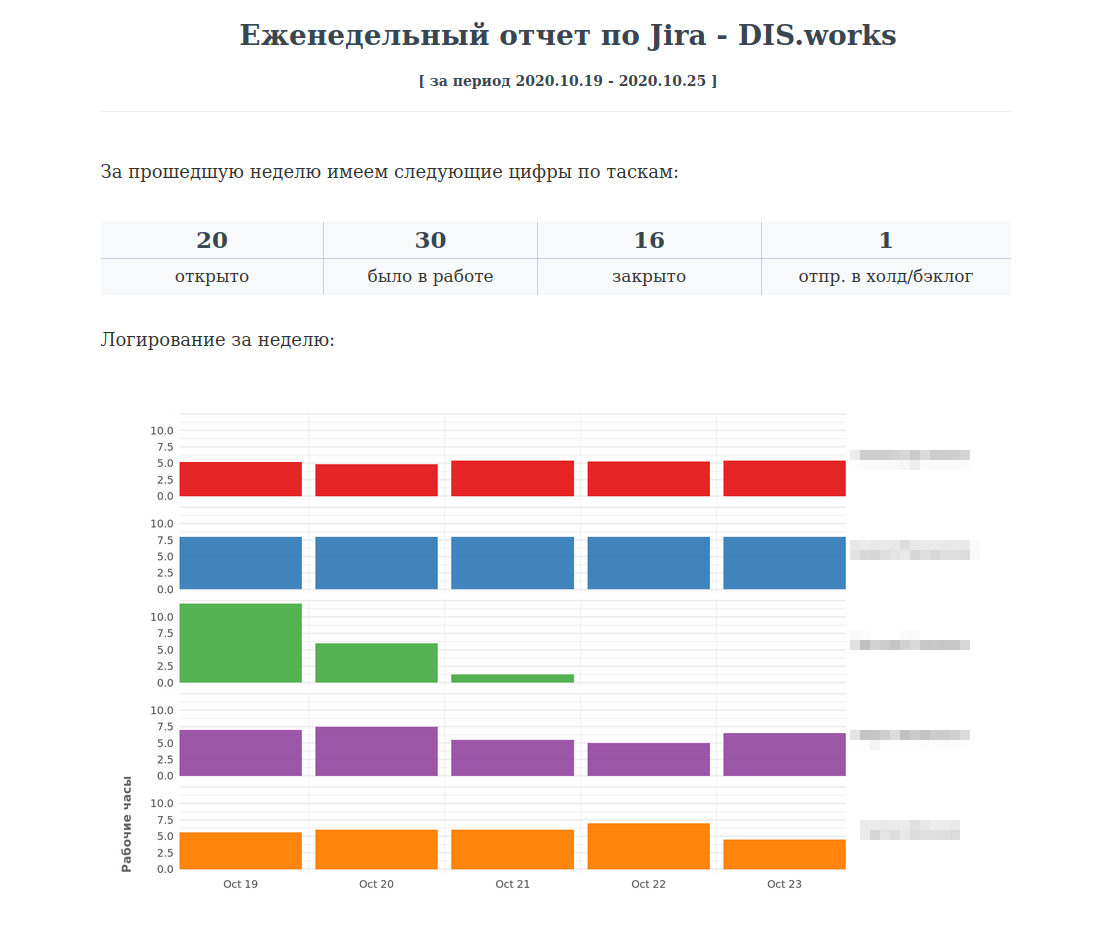


Eh bien, la contribution promise de chaque employé à la vue d'ensemble donnée ci-dessus.
Je suis sûr que vous remarquerez immédiatement où se trouve notre développeur et où est l'administrateur. Nous recherchions cette clarté. Le vrai rapport est également complété par un résumé du mouvement des tâches. Il s'agit d'un ajout aux statistiques générales affichées au tout début, avec les noms des tâches et les noms des personnes en charge.

Générer un rapport
Pour configurer la génération automatique de rapports, par exemple, les lundis à partir d'un script R, vous pouvez utiliser le package cronR , c'est extrêmement simple.
Avec nous, tout est plus compliqué et élégant. Nous avons utilisé Apache NiFi pour télécharger des données de l'API Jira chaque semaine, exécuter le script de génération de rapport et envoyer un rapport à tous les employés par e-mail . Ce sujet est si vaste qu'il mérite un article séparé .
Conclusion
Le nombre d'implémentations de Jira Software, ainsi que le nombre d'entreprises où il est utilisé, est important. Dans le même temps, chaque boss a besoin de sa propre base de métriques pour une gestion tactiquement correcte. Oui, il existe eazyBI et d'autres plugins pour l'analyse Jira, mais le résultat est comme acheter un costume dans le magasin au lieu d'un sur mesure personnalisé.
Le rapport considéré est cousu selon des modèles. Selon le patron, il fournit une vision stratégique de ce que fait l'unité ou l'équipe . J'espère que cet article vous aidera à mettre en œuvre quelque chose de similaire chez vous.
Merci.