Pourquoi l'avons-nous créé?
Pendant longtemps, chez Rambler Group, nous avons utilisé une architecture de réseau de centre de données à trois niveaux, dans laquelle chaque projet ou composant d'infrastructure vivait dans un vlan dédié. Tout le trafic - à la fois entre les vlans et entre les centres de données - passait par des équipements de niveau périphérique.
Les équipements de périphérie sont des routeurs coûteux capables d'exécuter de nombreuses fonctions différentes, par conséquent, les ports qu'il contient sont également coûteux. Au fil du temps, le trafic horizontal a augmenté (machine à machine - par exemple, réplication de base de données, demandes à divers services, etc.) et, à un moment donné, le problème de l'utilisation des ports sur les routeurs frontaliers s'est posé.
L'une des principales fonctions de ces appareils est le filtrage du trafic. En conséquence, il est également devenu plus difficile de gérer l'ACL: il fallait tout faire manuellement, et l'exécution de la tâche par le service adjacent prenait également du temps. Un temps supplémentaire a été consacré à la configuration des ports au niveau d'accès. Il était nécessaire d'effectuer non seulement des actions manuelles des mêmes NOC, mais également d'identifier les problèmes de sécurité potentiels, car les hôtes changent d'emplacement, respectivement, ils peuvent obtenir un accès illégal aux vlans d'autres personnes.
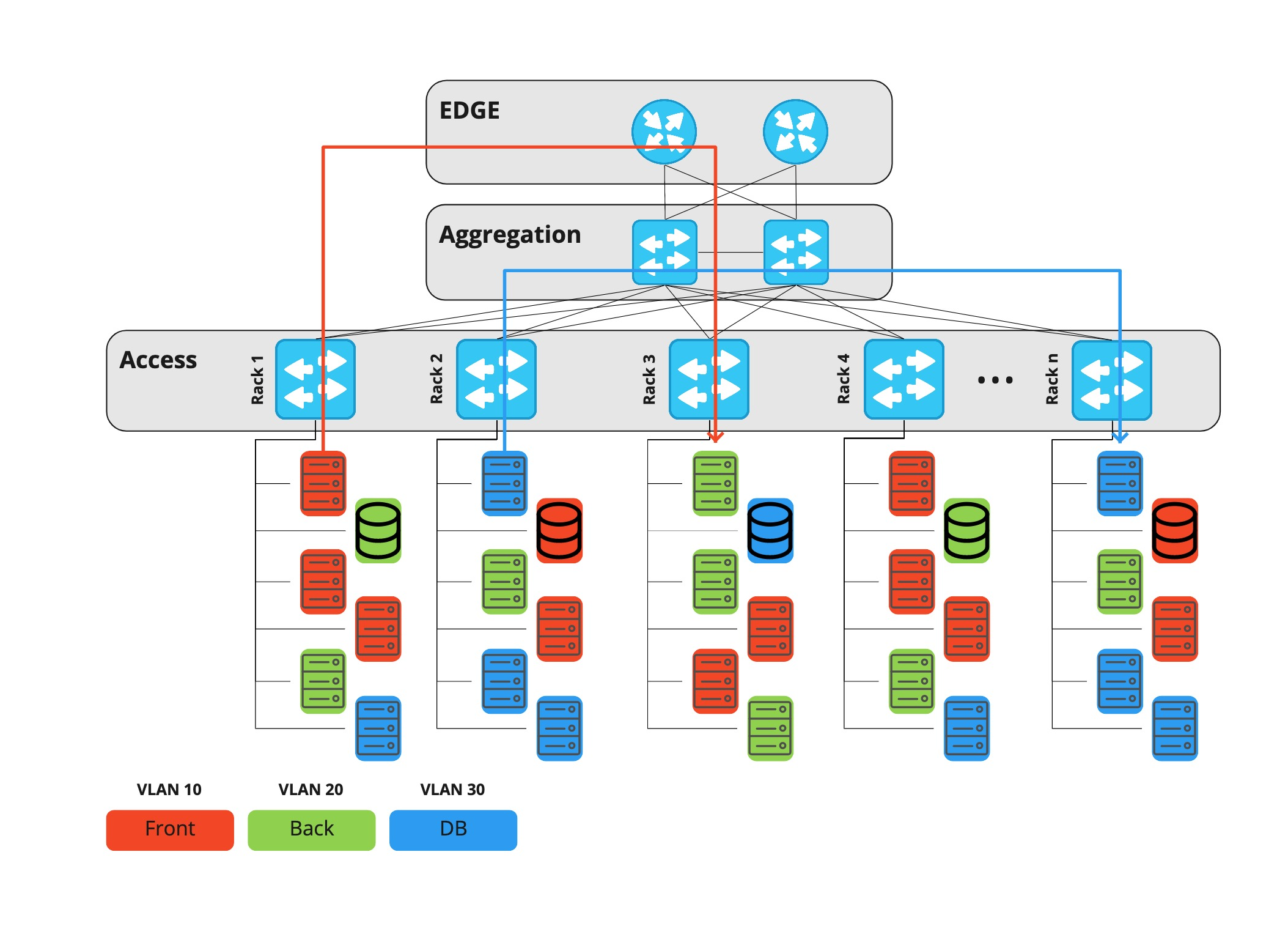
Le moment est venu de changer quelque chose et les réseaux Clos ou, comme on les appelle aussi, les usines IP sont venus à la rescousse.

Malgré la similitude externe, la différence fondamentale entre cette architecture et la précédente est que chaque périphérique, y compris la couche feuille, agit comme un routeur et que la passerelle par défaut pour le serveur est Top-of-Rack. Ainsi, le trafic horizontal entre tous les hôtes de différents projets peut désormais passer par la couche de colonne vertébrale, et non par le bord.
De plus, au même niveau de colonne vertébrale, nous pouvons connecter les centres de données les uns aux autres, et pas plus de quatre périphériques réseau se trouvent maintenant sur le chemin entre deux serveurs. Les équipements de périphérie de cette architecture ne sont nécessaires que pour connecter les opérateurs de télécommunications et autorisent uniquement le trafic vertical (vers et depuis Internet).
La principale caractéristique du réseau Klose est qu'il ne dispose pas d'un endroit où vous pouvez filtrer le trafic entre les hôtes. Par conséquent, cette fonction doit être exécutée directement sur le serveur. Un pare-feu centralisé est un programme qui filtre le trafic sur l'hôte lui-même qui reçoit le trafic.
Exigences
La nécessité de mettre en œuvre un pare-feu centralisé a été dictée par plusieurs facteurs à la fois:
- les consommateurs finaux et
- infrastructure existante.
Par conséquent, les conditions requises pour la demande étaient les suivantes:
- Le pare-feu doit pouvoir fonctionner et créer des règles sur l'hôte et les machines virtuelles. De plus, la liste des règles ne doit pas différer de l'environnement dans lequel le pare-feu est exécuté. Autrement dit, les règles sont identiques.
- . , – ssh, ( Prometheus), .
- , -.
- , – .
- .
- : « , ».
Le cloud du groupe Rambler est assez dynamique: des machines virtuelles sont créées et supprimées, des serveurs sont installés et démontés. Par conséquent, nous n'utilisons pas d'accès point à point, notre infrastructure a le concept de «groupe hôte».
Un groupe d'hôtes est un balisage pour un groupe de serveurs qui décrit de manière unique leur rôle. Par exemple news-prod-coolstream-blue.
Cela conduit à une autre exigence: les utilisateurs doivent travailler avec des entités de haut niveau - groupes hôtes, projets, etc.
Idée et mise en œuvre
Tulling Un
pare-feu centralisé est une chose vaste et complexe qui nécessite une configuration d'agent. La recherche de problèmes peut prendre plus de cinq minutes, de sorte qu'un outil est apparu avec l'agent et le serveur, qui indique à l'utilisateur si l'agent est configuré correctement et ce qui doit être corrigé. Par exemple, une exigence importante pour un hôte est l'existence d'un enregistrement DNS dans le groupe d'hôtes ou PTR. L'outil vous dira tout cela et bien plus encore ( ses fonctions sont décrites ci-dessous ).
Pare-feu unifié
Nous essayons de respecter le principe suivant: l'application qui configure le pare-feu sur l'hôte doit être la seule pour ne pas avoir de «règles de clignotement». Autrement dit, si le serveur dispose déjà de son propre outil de personnalisation (par exemple, si les règles sont configurées par un autre agent), alors notre application n'y appartient pas. Eh bien, la condition inverse fonctionne également: s'il y a notre agent de pare-feu, alors lui seul définit les règles - voici le principe du contrôle total.
Le pare-feu n'est pas iptables
Comme vous le savez, iptables est juste un utilitaire de ligne de commande pour travailler avec netfilter. Pour porter le pare-feu sur différentes plates-formes (Windows, systèmes BSD), l'agent et le serveur fonctionnent avec leur propre modèle. Plus d'informations ci-dessous, dans la section "Architecture" .
L'agent n'essaye pas de résoudre les erreurs logiques
Comme indiqué ci-dessus, l'agent ne prend aucune décision. Si vous souhaitez fermer le port 443, sur lequel votre serveur HTTP est déjà en cours d'exécution, pas de problème, fermez-le!
Architecture
Il est difficile de proposer quelque chose de nouveau dans l'architecture d'une telle application.
- Nous avons un agent, il configure les règles sur l'hôte.
- Nous avons un serveur, il donne des règles définies par l'utilisateur.
- Nous avons une bibliothèque et des outils.
- Nous avons un résolveur de haut niveau - il change les adresses IP en groupes d'hôtes / projets et vice versa. Plus d'informations sur tout cela ci - dessous .
Rambler Group possède de nombreux hôtes et encore plus de machines virtuelles, et tous, d'une manière ou d'une autre, appartiennent à une entité:
- VLAN
- Réseau
- Projet
- Groupe hôte.
Ce dernier décrit l'appartenance de l'hôte au projet et son rôle. Par exemple, news-prod-backend-api, où: news - project; prod - son env, dans ce cas c'est la production; backend - rôle; api est une balise personnalisée arbitraire.
Le
résolveur de pare-feu fonctionne au niveau du réseau et / ou du transport, et les groupes d'hôtes et les projets sont des entités de haut niveau. Par conséquent, pour "se faire des amis" et comprendre à qui appartient l'hôte (ou la machine virtuelle), vous devez obtenir une liste d'adresses - nous avons appelé ce composant "High Level Resolver". Il change les noms de haut niveau en un ensemble d'adresses (en termes de résolveur, il est "contenu") et, inversement, une adresse en nom de l'entité ("contient").
Bibliothèque - Core
Pour l'unification et l'unification de certains composants, une bibliothèque est apparue, elle s'appelle aussi Core. Il s'agit d'un modèle de données avec ses propres contrôleurs et vues qui vous permettent de le remplir et de le lire. Cette approche simplifie considérablement le code côté serveur et agent, et permet également de comparer les règles actuelles sur l'hôte avec les règles reçues du serveur.
Nous avons plusieurs sources pour remplir le modèle:
- fichiers de règles (deux types différents: simplifiés et décrivant complètement la règle)
- règles reçues du serveur
- règles reçues de l'hôte lui-même.
Agent
Agent n'est pas une liaison sur iptables, mais une application autonome qui fonctionne à l'aide d'un wrapper sur les bibliothèques C libiptc, libxtables. L'agent lui-même ne prend aucune décision, mais configure uniquement les règles sur l'hôte.
Le rôle de l'agent est minimal: lire les fichiers de règles (y compris ceux par défaut), récupérer les données du serveur (s'il est configuré pour un fonctionnement à distance), fusionner les règles en un seul ensemble, vérifier si elles diffèrent de l'état précédent et, si elles sont différentes, appliquer.
Un autre rôle important de l'agent est de ne pas transformer l'hôte en citrouille lors de l'installation initiale ou lors de la réception d'une réponse invalide du serveur. Pour éviter cela, nous fournissons un ensemble de règles dans le package par défaut, telles que ssh, la surveillance des accès, etc. Si l'agent de pare-feu reçoit un code de réponse autre que le 200e code de réponse, l'agent n'essaiera pas d'effectuer une action et quittera l'état précédent. Mais il ne protège pas contre les erreurs logiques, si vous refusez l'accès sur les ports 80, 443, alors l'agent continuera à faire son travail, même lorsque le service Web est en cours d'exécution sur l'hôte.
Tulza
Tulza est destiné aux administrateurs système et aux développeurs qui gèrent le projet. L'objectif est incroyablement simple: en un clic, récupérez toutes les données sur le travail de l'agent. L'utilitaire est capable de vous renseigner sur:
- le démon de l'agent est-il en cours d'exécution
- y a-t-il un enregistrement PTR pour l'hôte
- .
Ces informations sont suffisantes pour diagnostiquer les problèmes à un stade précoce.
Server
Server est application + base de données. Toute la logique du travail est réalisée par lui. Une caractéristique importante du serveur est qu'il ne stocke pas les adresses IP. Le serveur ne fonctionne qu'avec des objets de premier niveau - noms de groupe d'hôtes, projet, etc.
Les règles de la base sont les suivantes: Action: Accepter Src: projet-B, projet-C Dst: Projet-B Proto: tcp Ports: 80, 443.
Comment le serveur comprend-il quelles règles donner et à qui? Il découle des exigences que les règles doivent être identiques quel que soit l'endroit où l'agent s'exécute, qu'il s'agisse d'un hôte ou d'une machine virtuelle.
Une demande d'un agent arrive toujours au serveur avec une valeur - une adresse IP. Il est important de se rappeler que chaque agent demande les règles pour lui-même, c'est-à-dire qu'il est la destination.
Pour faciliter la compréhension du fonctionnement du serveur, envisagez le processus d'obtention des règles d'hôte appartenant à un projet.
Le résolveur entre en jeu en premier. Sa tâche est de changer l'adresse IP en nom d'hôte, puis de découvrir quelle entité contient cet hôte. HL-Resolver répond au serveur que l'hôte est contenu dans le projet A. HL-Resolver fait référence à la source de données (que nous n'avons pas mentionnée auparavant). Datasource est une sorte de base de connaissances d'entreprise sur les serveurs, les projets, les groupes d'hôtes, etc.
Ensuite, le serveur recherche toutes les règles du projet avec destination = nom du projet. Comme nous ne contenons pas d'adresses dans la base de données, nous devons renommer les noms de projet en noms d'hôte, puis en adresses, de sorte que la demande est à nouveau envoyée à la source de données via le résolveur. HL-Resoler renvoie une liste d'adresses, après quoi l'agent reçoit une liste prête de règles.
Si notre destination est un hôte avec des machines virtuelles, le même script est exécuté non seulement pour l'hôte, mais également pour chaque machine virtuelle sur celui-ci.
Voici un diagramme qui montre un cas simple: un hôte (matériel ou machine virtuelle) reçoit les règles pour l'hôte dans Project-A.

Communiqués
Il n'est pas difficile de deviner qu'avec une gestion centralisée du pare-feu, vous pouvez également tout interrompre de manière centralisée. Par conséquent, les versions de l'agent et du serveur sont effectuées par étapes.
Pour le serveur - Blue-Green + A / B testing
Blue-Green est une stratégie de déploiement qui implique deux groupes d'hôtes. Et la commutation se fait par portions 1,3,5,10 ... 100%. ainsi, si des problèmes surviennent avec la nouvelle version, seule une petite partie des services en souffrira.
Pour un agent, Canary
Canary (ou déploiement Canary) est quelque peu similaire aux tests A / B. Nous ne mettons à jour que certains des agents et examinons les métriques. Si tout va bien, nous prenons un autre morceau plus gros et ainsi de suite jusqu'à 100%.
Conclusion
En conséquence, nous avons créé un libre-service pour les ingénieurs système, qui vous permet de gérer l'accès au réseau à partir d'un point. Ainsi, nous:
- HTTP-API
- .