- Commençons. Je parlerai de la journalisation pratique et de l'infrastructure autour de la journalisation que vous pouvez déployer pour vous permettre de vivre avec votre application et son cycle de vie.

Qu'est-ce qu'on fait? Nous allons construire une petite application, notre startup. Ensuite, nous mettrons en œuvre une connexion de base, ceci est une petite partie du rapport, ce que Python fournit prêt à l'emploi. Et puis le plus important - nous analyserons les problèmes typiques que nous rencontrons lors du débogage, du déploiement et des outils pour les résoudre.
Petit avertissement: j'utiliserai des mots comme stylo et locale. Laissez-moi expliquer. «Handle» est peut-être l'argot yandex, il désigne votre API, API http ou gRPC ou toute autre combinaison de lettres avant APU. "Locale", c'est quand je développe sur un ordinateur portable. Il semble que j'ai raconté tous les mots que je ne contrôle pas.
Application de librairie
Commençons. Notre startup est "Bookstore". La principale caractéristique de cette application sera la vente de livres, c'est tout ce que nous voulons faire. Puis un peu de garniture. L'application sera écrite en Flask. Tous les extraits de code, tous les outils sont génériques et extraits de Python, ils peuvent donc être intégrés dans la plupart de vos applications. Mais dans notre discours, ce sera Flask.
Personnages: moi, le développeur, les managers et mon cher collègue Erast. Toutes les coïncidences sont accidentelles.
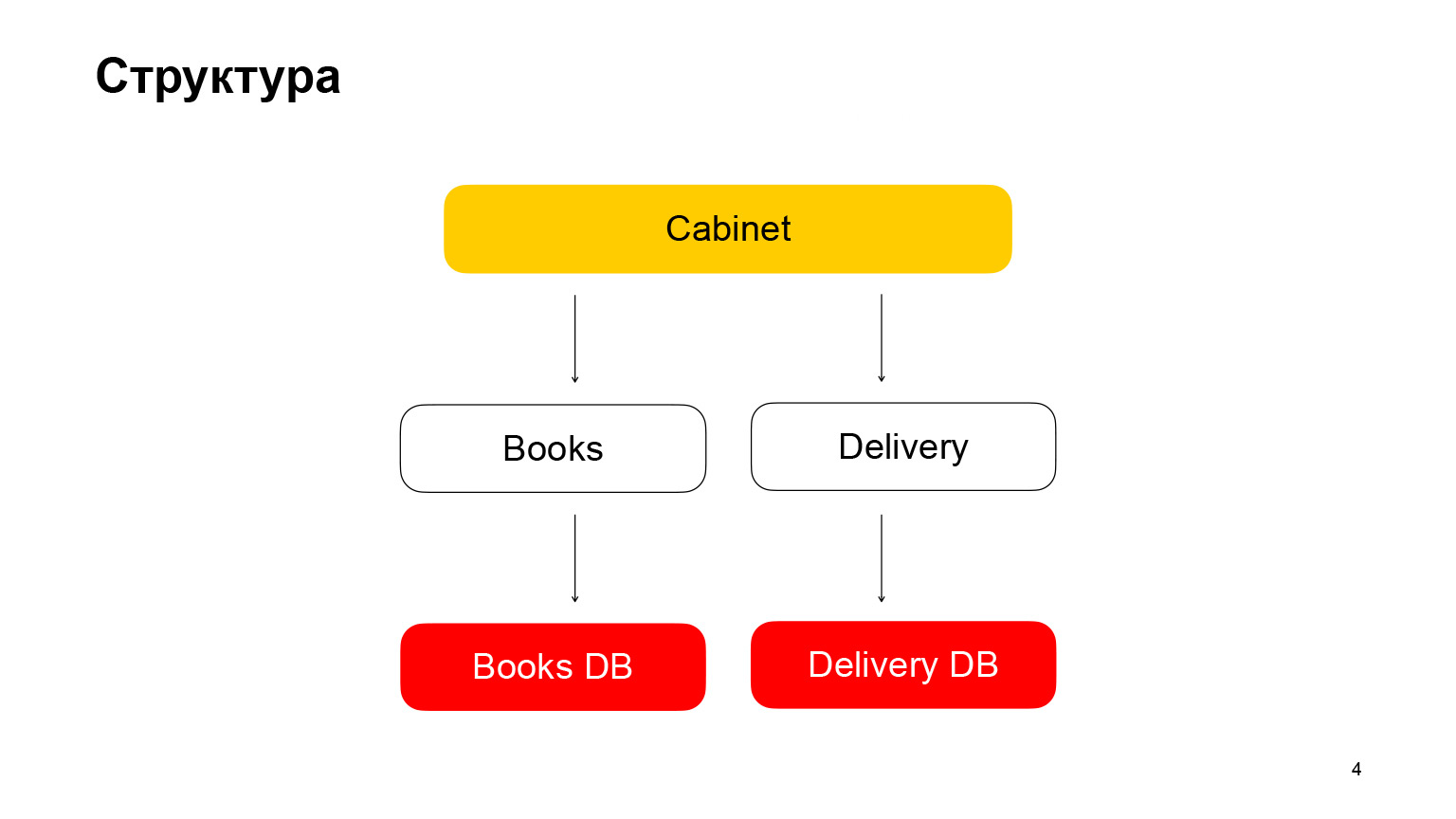
Parlons un peu de la structure. Il s'agit d'une application d'architecture de microservice. Le premier service est Books, un stockage de livres avec des métadonnées de livres. Il utilise la base de données PostgreSQL. Le deuxième microservice est un microservice de livraison qui stocke des métadonnées sur les commandes des utilisateurs. Le cabinet est le backend du cabinet. Nous n'avons pas d'interface, ce n'est pas nécessaire dans notre rapport. Le Cabinet regroupe les demandes, les données du service livre et du service de livraison.

Je vais vous montrer le code pour les descripteurs de ces services, API Books. Ce handle saisit les données de la base de données, les sérialise, les transforme en JSON et les restitue.

Allons plus loin. Service de livraison. La poignée est exactement la même. Nous récupérons les données de la base de données, les sérialisons et les envoyons.

Et le dernier bouton est le bouton du cabinet. Il a un code légèrement différent. Le gestionnaire d'armoire demande des données au service de livraison et au service de livre, agrège les réponses et donne à l'utilisateur ses commandes. Tout. Nous avons rapidement compris la structure de l'application.
Journalisation de base dans l'application
Parlons maintenant de la journalisation de base, celle que nous avons vue. Commençons par la terminologie.

Que nous donne Python? Quatre entités principales de base:
- Logger, le point d'entrée pour l'enregistrement de votre code. Vous allez utiliser une sorte de Logger, écrire logging.INFO, et c'est tout. Votre code ne saura plus rien de l'endroit où le message est allé et de ce qui lui est arrivé ensuite. L'entité Handler est déjà responsable de cela.
- Le gestionnaire traite votre message, décide où l'envoyer: vers la sortie standard, vers un fichier ou vers le courrier de quelqu'un d'autre.
- Le filtre est l'une des deux entités auxiliaires. Supprime les messages du journal. Un autre cas d'utilisation courant est le bourrage de données. Par exemple, dans votre message, vous devez ajouter un attribut. Le filtre peut également vous aider.
- Le formateur apporte votre message à la forme souhaitée.

C'est là que nous en avons terminé avec la terminologie, nous ne reviendrons pas à la journalisation directement en Python, avec les classes de base. Mais voici un exemple de configuration de notre application, qui est déployée sur les trois services. Il y a deux blocs principaux et importants pour nous: les formateurs et les gestionnaires. Pour les formateurs, il existe un exemple, que vous pouvez voir ici, un modèle pour la façon dont le message sera affiché.
Dans les gestionnaires, vous pouvez voir le logging.StreamHandler est utilisé. Autrement dit, nous vidons tous nos journaux sur la sortie standard. Voilà, nous en avons terminé.
Problème 1. Les journaux sont dispersés
Passons aux problèmes. Pour commencer, le premier problème: les logs sont dispersés.
Un peu de contexte. Nous avons rédigé notre application, le bonbon est déjà prêt. Nous pouvons gagner de l'argent avec. Nous le déployons en production. Bien sûr, il existe plusieurs serveurs. Selon nos estimations prudentes, notre application la plus complexe nécessite environ trois ou quatre voitures, et ainsi de suite pour chaque service.
Maintenant la question. Le directeur accourt vers nous et demande: "C'est cassé là-bas, au secours!" Tu cours. Tout est enregistré pour vous, c'est génial. Vous allez à la première machine à écrire, regardez - il n'y a rien là pour votre demande. Allez à la deuxième voiture - rien. Etc. C'est mauvais, il faut y remédier d'une manière ou d'une autre.

Formalisons le résultat que nous voulons voir. Je veux que les journaux soient au même endroit. C'est une exigence simple. Un peu plus cool, c'est que je veux rechercher les journaux. Autrement dit, oui, il se trouve au même endroit et je peux déchirer, mais ce serait cool s'il y avait des outils, des fonctionnalités intéressantes en plus d'un simple grap.
Et je ne veux pas écrire. C'est Erast qui aime écrire du code. Je ne parle pas de ça, j'ai fait un produit tout de suite. Autrement dit, vous voulez moins de code supplémentaire, utilisez un ou deux fichiers, lignes, et c'est tout.

La solution qui peut être utilisée est Elasticsearch. Essayons de le soulever. Quels sont les avantages d'Elasticsearch? Ceci est une interface de recherche de journal. Il y a une interface prête à l'emploi, ce n'est pas une console pour vous, mais le seul lieu de stockage. Autrement dit, nous avons rempli la principale exigence. Nous n'aurons pas besoin d'aller aux serveurs.
Dans notre cas, ce sera une intégration assez simple, et avec la version récente, Elasticsearch a un nouvel agent qui est responsable de la plupart des intégrations. Ils y ont scié en intégration. Très cool. J'ai écrit une conférence plus tôt et utilisé filebeat, tout aussi simple. C'est simple pour les journaux.
Un peu sur Elasticsearch. Je ne veux pas faire de publicité, mais il existe de nombreuses fonctionnalités supplémentaires. Par exemple, la chose intéressante est la recherche de journal en texte intégral hors de la boîte. Ça a l'air très cool. Pour l'instant, ces avantages nous suffisent. Nous le fixons.
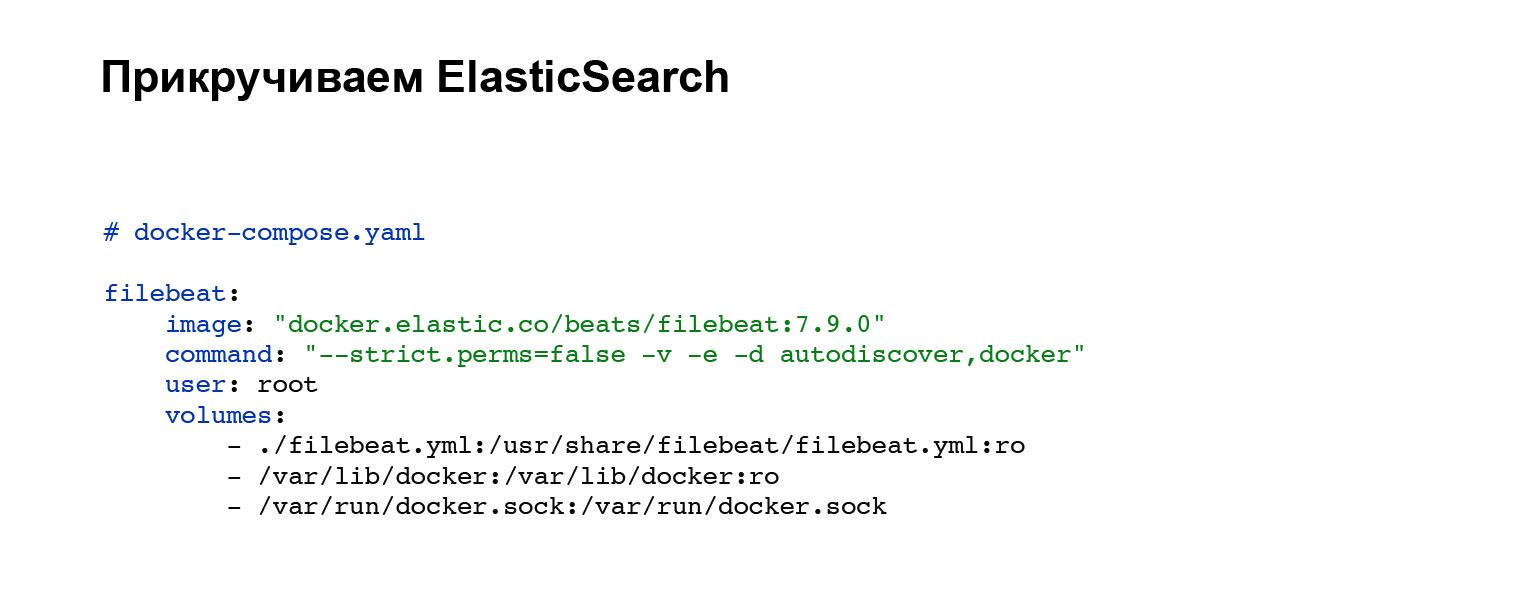
Tout d'abord, nous devrons déployer un agent qui enverra nos journaux à Elasticsearch. Vous enregistrez un compte avec Elasticsearch, puis ajoutez à votre docker-compose. Si vous n'avez pas de docker-compose, vous pouvez soulever avec des poignées ou sur votre système. Dans notre cas, le bloc de code suivant est ajouté, intégration dans docker-compose. Tout, le service est configuré. Et vous pouvez voir le fichier de configuration filebeat.yml dans le bloc volumes.

Voici un exemple de filebeat.yml. Ici, nous avons mis en place une recherche automatique des journaux des conteneurs docker qui tournent à proximité. Le choix de ces logs a été personnalisé. Par condition, vous pouvez définir, accrocher des étiquettes sur vos conteneurs, et en fonction de cela, vos journaux ne seront envoyés qu'à partir de certains conteneurs. Les processeurs: le bloc add_docker_metadata est simple. Nous ajoutons un peu plus d'informations sur vos logs dans le contexte du docker aux logs. Facultatif, mais cool.
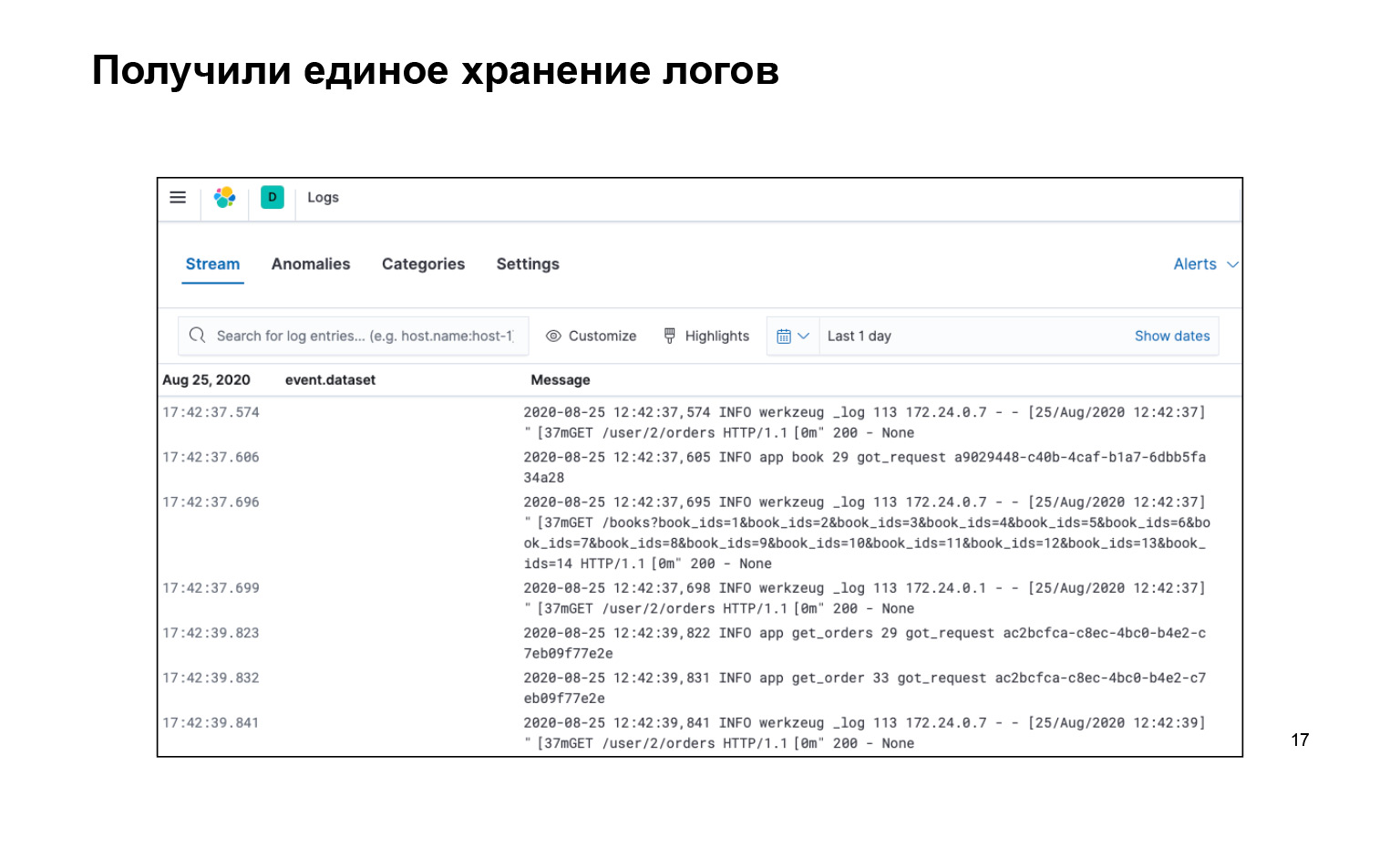
Qu'avons nous? C'est tout ce que nous avons écrit, tout le code, très cool. Dans le même temps, nous avons tous les journaux au même endroit et il y a une interface. Nous pouvons rechercher nos logs, voici la barre de recherche. Ils sont livrés. Et vous pouvez même l'activer en direct pour que le flux vole vers nos journaux dans l'interface, et nous l'avons vu.

Ici, j'aurais moi-même demandé: pourquoi, comment boucler quelque chose? Qu'est-ce qu'une recherche de journal, que peut-on y faire?
Oui, hors de la boîte dans cette approche, lorsque nous avons des journaux de texte, il y a un petit gag: nous pouvons définir une requête par le texte, par exemple message: users. Cela nous imprimera tous les journaux qui ont la sous-chaîne users. Vous pouvez utiliser des astérisques, la plupart des autres caractères génériques Unix. Mais il semble que ce ne soit pas suffisant, je veux rendre les choses plus difficiles pour que nous puissions nous réchauffer plus tôt dans Nginx, comme nous le pouvons.

Retournons un peu d'Elasticsearch et essayons de le faire non pas avec Elasticsearch, mais avec une approche différente. Considérons les journaux structurels. C'est alors que chacune de vos entrées de journal n'est pas simplement une ligne de texte, mais un objet sérialisé avec des attributs que n'importe lequel de vos systèmes tiers peut sérialiser pour obtenir un objet prêt à l'emploi.
Quels sont les avantages de cela? C'est un format de données uniforme. Oui, les objets peuvent avoir différents attributs, mais tout système externe peut lire JSON et recevoir une sorte d'objet.
Une sorte de frappe. Cela simplifie l'intégration avec d'autres systèmes: pas besoin d'écrire des désérialiseurs. Et les désérialiseurs sont un autre point. Vous n'avez pas besoin d'écrire des textes prosaïques dans l'application. Exemple: "L'utilisateur est venu avec tel ou tel spécialiste de l'identification, avec telle ou telle commande." Et tout cela doit être écrit à chaque fois.
Cela m'a dérangé. Je veux écrire: "Une demande est arrivée." De plus: «Untel, untel, untel, untel», très simple, très de style informatique.

Allons-nous en. Soyons d'accord: nous nous connecterons au format JSON, c'est un format simple. Elasticsearch est immédiatement pris en charge, filebeat, que nous sérialisons et essayons de classer. Ce n'est pas très difficile. Tout d'abord, vous ajoutez le fichier de paramètres de la bibliothèque pythonjsonlogger au bloc de formatage JSONFormatter, où nous stockons la configuration. Cela peut être un endroit différent de votre système. Et puis dans l'attribut de format, vous passez les attributs que vous souhaitez ajouter à votre objet.
Le bloc ci-dessous est un bloc de configuration qui est ajouté à filebeat.yml. Ici, prête à l'emploi, il existe une interface filebeat pour analyser les journaux JSON. Très cool. C'est tout. Vous n'avez rien d'autre à écrire pour cela. Et maintenant, vos journaux ressemblent à des objets.
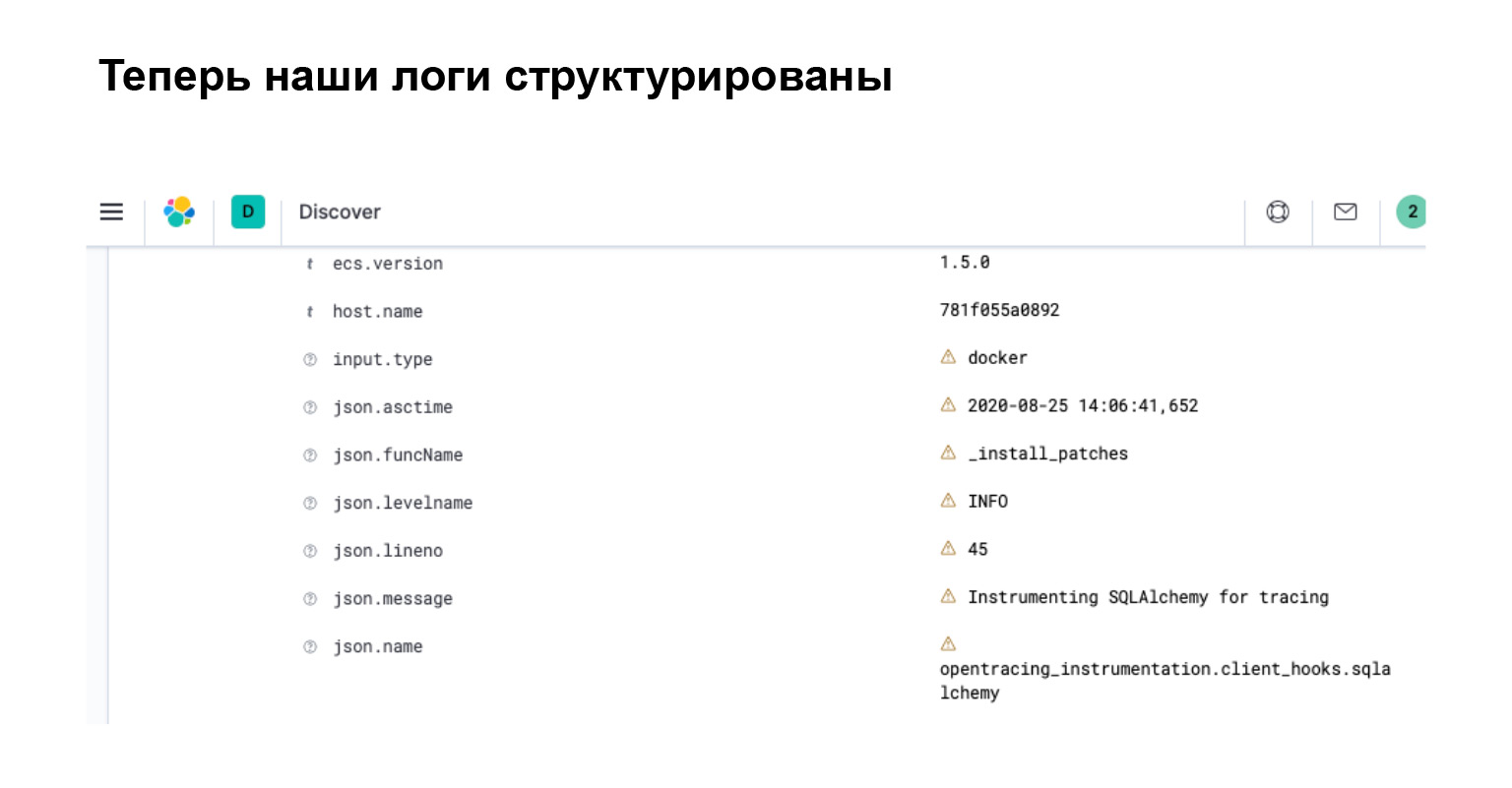
Qu'avons-nous obtenu dans Elasticsearch? Dans l'interface, vous voyez immédiatement que votre journal est devenu un objet avec des attributs séparés, grâce auxquels vous pouvez rechercher, créer des filtres et effectuer des requêtes complexes.

Résumons. Maintenant, nos journaux ont une structure. Ils sont faciles à utiliser et vous pouvez écrire des requêtes intelligentes. Elasticsearch est conscient de cette structure car il a analysé tous ces attributs. Et dans kibana, qui est une interface pour Elasticsearch, vous pouvez filtrer ces journaux à l'aide d'un langage de requête spécialisé fourni par Elasticsearch.
Et c'est plus facile que de pagayer. Grep a un langage plutôt compliqué et cool. Il y a beaucoup à écrire. Beaucoup de choses peuvent être simplifiées dans kibana. Avec cela réglé.
Problème 2. Freins
Le problème suivant concerne les freins. Dans l'architecture des microservices, il y a toujours et partout des freins.

Voici un petit contexte, je vais vous raconter une histoire. Le manager, le personnage principal de notre projet, vient en courant vers moi et me dit: «Hé, hé, le bureau ralentit! Danya, sauve, aide! "
On ne sait encore rien, on grimpe dans nos logs dans Elasticsearch. Mais laissez-moi vous dire ce qui s'est réellement passé.

Erast a ajouté une fonctionnalité. Dans les livres, nous affichons désormais non pas l'identifiant de l'auteur, mais son nom directement dans l'interface. Très cool. Il l'a fait avec le code suivant. Un petit bout de code, rien de compliqué. Qu'est-ce qui pourrait mal se passer?
Avec un œil averti, vous pouvez dire que vous ne pouvez pas faire cela avec SQLAlchemy, et avec un autre ORM aussi. Vous devez faire un pré-cache ou autre chose pour ne pas aller dans la base de données avec une petite sous-requête dans une boucle. Un problème désagréable. Il semble qu'une telle erreur ne devrait pas du tout être autorisée.
Laisse moi te dire. J'avais de l'expérience: nous travaillions avec Django, et nous avions un pré-cache personnalisé implémenté dans notre projet. Tout s'est bien passé pendant de nombreuses années. À un moment donné, Erast et moi avons décidé: suivons le rythme, mettons à jour Django. Naturellement, Django ne sait rien de notre cache personnalisé et l'interface a changé. Prikash tomba silencieusement. Cela n'a pas été pris lors des tests. Le même problème, c'était juste plus difficile à attraper.
Quel est le problème? Comment puis-je vous aider à résoudre le problème?

Laissez-moi vous dire ce que j'ai fait avant de commencer à résoudre le problème de trouver des freins.
La première chose que je fais est d'aller sur Elasticsearch, nous l'avons déjà, cela aide, il n'est pas nécessaire de faire le tour des serveurs. Je vais aux journaux, à la recherche des journaux du cabinet. Je trouve de longues requêtes. Je le joue sur un ordinateur portable et je vois que ce n'est pas le bureau qui se retient. Ralentit les livres.
Je cours dans les journaux de livres, trouve des requêtes problématiques - en fait, nous l'avons déjà. Je reproduis des livres de la même manière sur un ordinateur portable. Code très compliqué - je ne comprends rien. Je commence à déboguer. Les horaires sont assez difficiles à saisir. Pourquoi? Il est assez difficile de définir cela en interne dans SQLAlchemy. J'écris des enregistreurs de temps personnalisés, je localise et corrige le problème.
Cela m'a fait mal. Difficile, désagréable. J'ai pleuré. J'aimerais que ce processus de recherche d'un problème soit plus rapide et plus pratique.
Formalisons nos problèmes. Il est difficile de rechercher dans les journaux ce qui ralentit, car notre journal est un journal d'événements indépendants. Nous devons écrire des minuteries personnalisées qui nous montrent combien de blocs de code ont été exécutés. De plus, il n'est pas clair comment enregistrer les horaires des systèmes externes: par exemple, ORM ou des bibliothèques de requêtes. Nous devons intégrer nos minuteries à l'intérieur ou avec une sorte de Wrapper, mais nous ne saurons pas pourquoi cela ralentit à l'intérieur. Compliqué.

Une bonne solution que j'ai trouvée est Jaeger. Il s'agit d'une implémentation du protocole d'opentracing, implémentons donc le traçage.
Que donne Jaeger? C'est une interface conviviale avec des requêtes de recherche. Vous pouvez filtrer les requêtes longues ou le faire par balises. Une représentation visuelle du flux des demandes, une très belle photo, je la montrerai un peu plus tard.
Les horaires sont déconnectés de la boîte. Vous n'avez rien à faire avec eux. Si vous avez besoin de vérifier la quantité d'un bloc personnalisé en cours d'exécution, vous pouvez l'envelopper dans des minuteries fournies par Jaeger. Très confortablement.
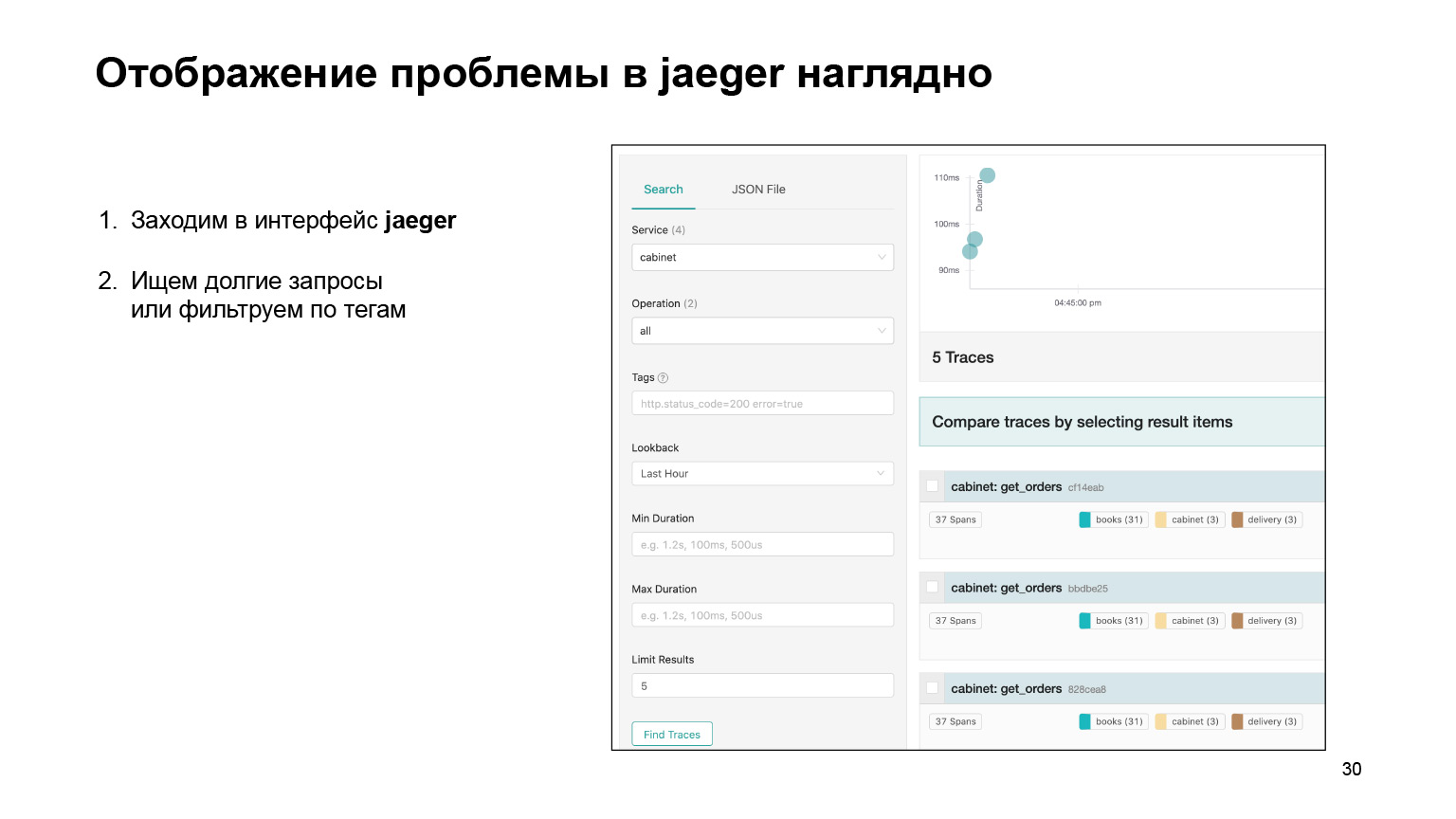
Voyons comment il était possible de trouver le problème dans l'interface et de le localiser là-bas. Nous entrons dans l'interface Jaeger. Voici à quoi ressemblent nos demandes. Nous pouvons rechercher des demandes pour un compte ou un autre service. Nous filtrons immédiatement les requêtes longues. Nous nous intéressons aux longs, ils sont assez difficiles à trouver dans les journaux. Nous obtenons leur liste.
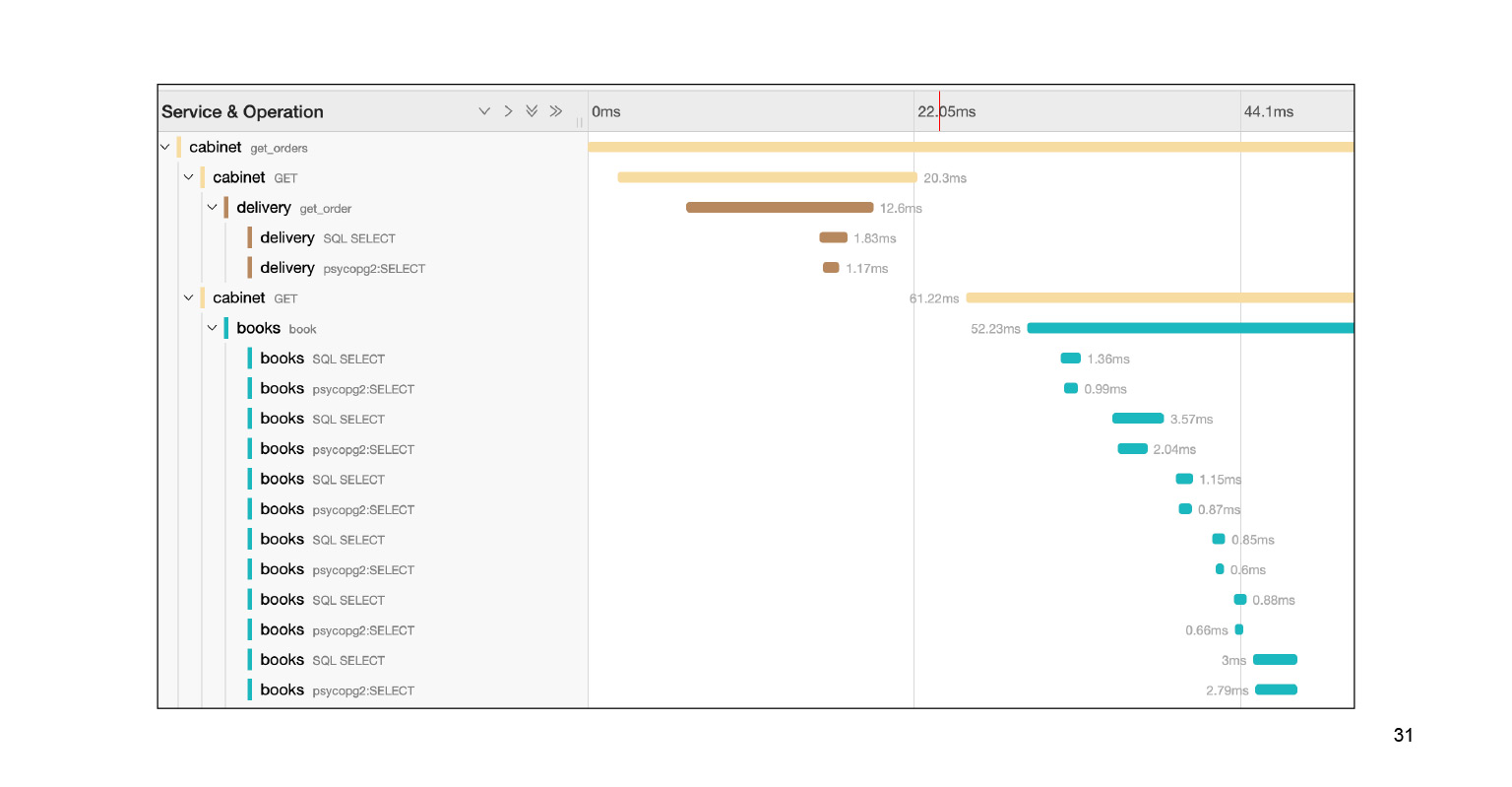
Nous tombons dans cette requête, et nous voyons une grande toile de pied de sous-requêtes SQL. Nous pouvons clairement voir comment ils ont été exécutés dans le temps, quel bloc de code était responsable de quoi. Très cool. De plus, dans le contexte de notre problème, ce n'est pas le journal entier. Il y a encore une grande toile à deux ou trois glissières vers le bas. Nous avons localisé le problème assez rapidement à Jaeger. Après avoir résolu le problème, que peut nous aider le contexte fourni par Jaeger?
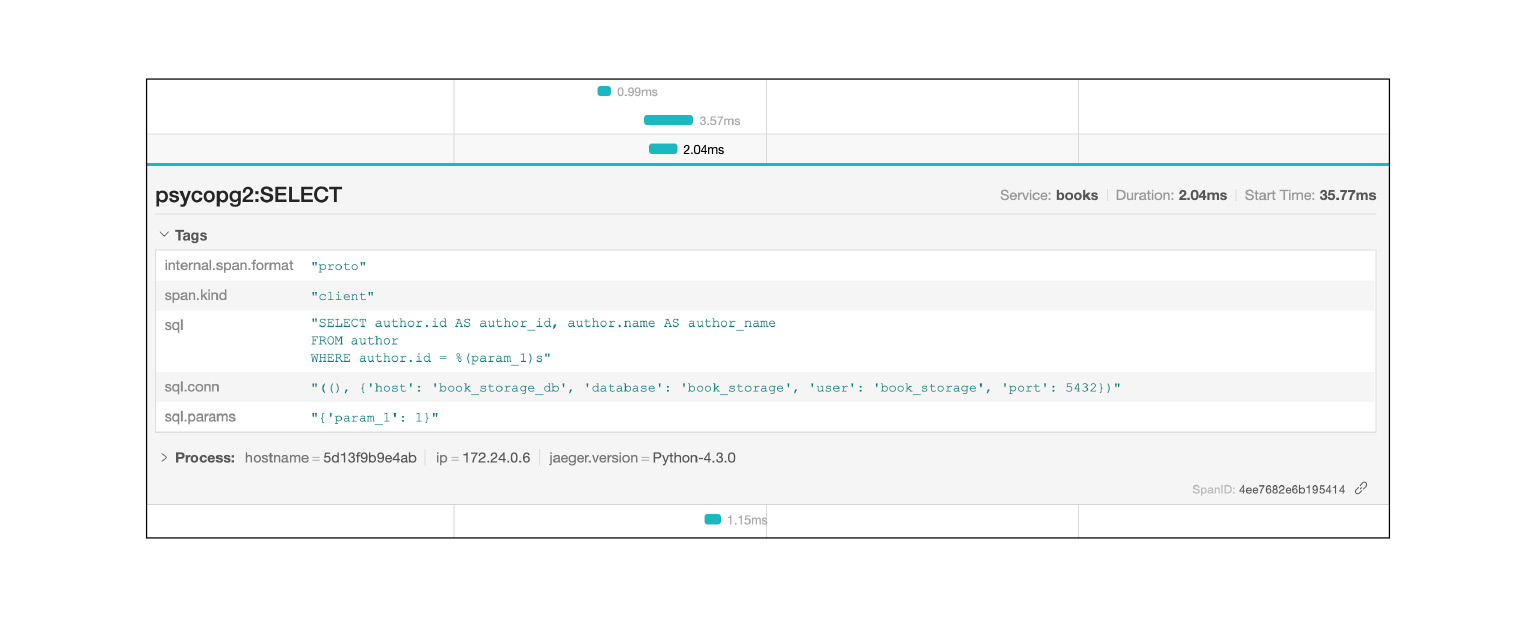
Jaeger enregistre, par exemple, les requêtes SQL: vous pouvez voir quelles requêtes sont répétées. Très rapide et cool.
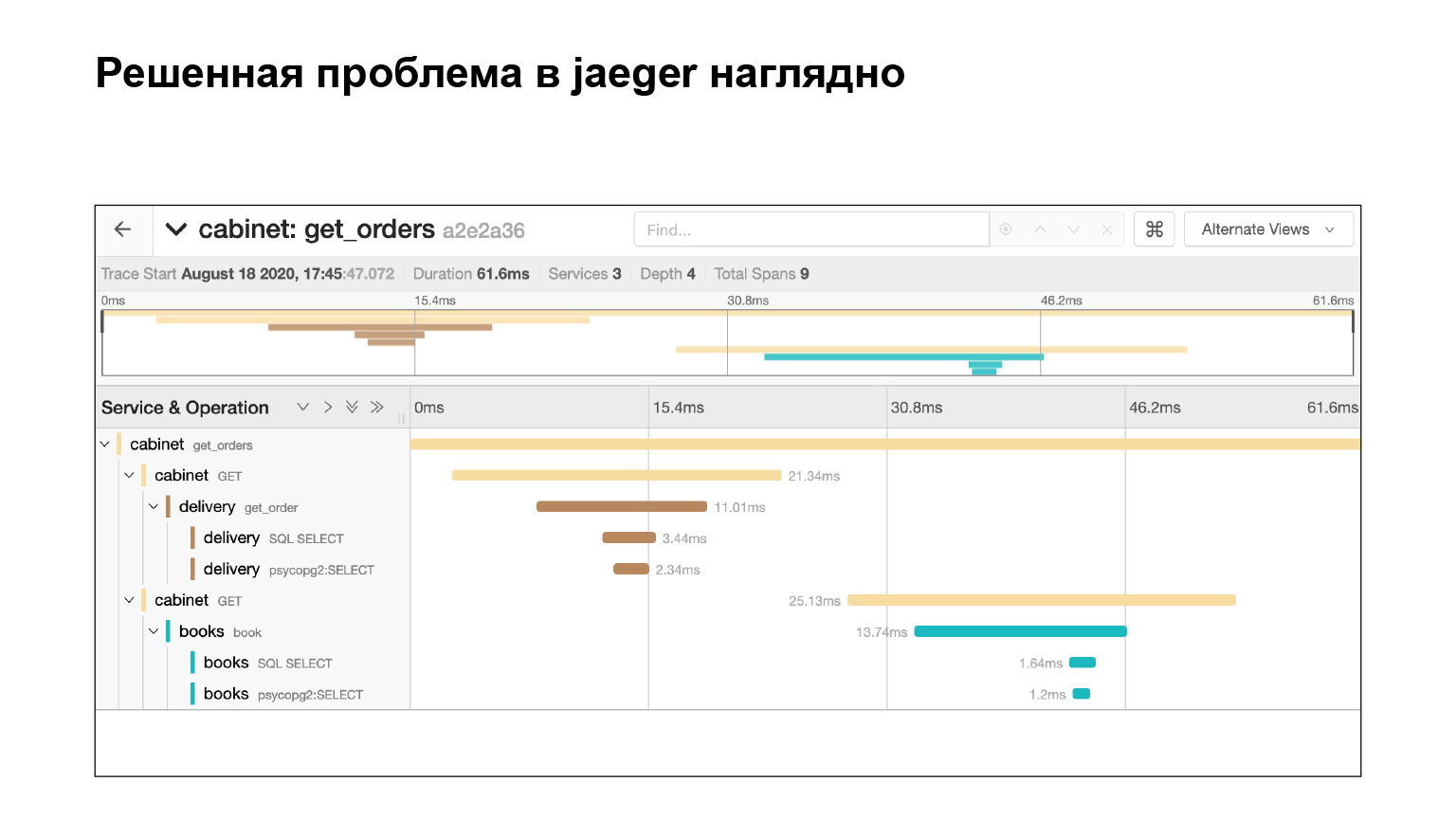
Nous avons résolu le problème et voyons immédiatement chez Jaeger que tout va bien. Nous vérifions par la même requête que nous n'avons plus de sous-requêtes. Pourquoi? Supposons que nous vérifions la même requête, déterminez le timing - regardez dans Elasticsearch combien de temps la requête a été exécutée. Ensuite, nous verrons l'heure. Mais cela ne garantit pas qu'il n'y a pas eu de sous-requêtes. Et ici on le voit, cool.

Implémentons Jaeger. Vous n'avez pas besoin de beaucoup de code. Vous ajoutez des dépendances pour l'opentracing, pour Flask. Maintenant sur le code que nous faisons.
Le premier bloc de code est la configuration du client Jaeger.
Ensuite, nous mettons en place l'intégration avec Flask, Django ou tout autre framework intégrant.
install_all_patches est la toute dernière ligne de code et la plus intéressante. Nous corrigeons la plupart des intégrations externes en interagissant avec MySQL, Postgres, la bibliothèque de requêtes. Nous corrigeons tout cela, et c'est pourquoi dans l'interface Jaeger, nous voyons immédiatement toutes les requêtes avec SQL et les services auxquels notre service requis est allé. Très cool. Et vous n'avez pas eu besoin d'écrire beaucoup. Nous venons d'écrire install_all_patches. La magie!
Qu'avons nous? Vous n'avez plus besoin de collecter les événements à partir des journaux. Comme je l'ai dit, les journaux sont des événements disparates. Dans Jaeger, c'est un grand événement dont vous voyez la structure. Jaeger vous permet d'attraper les goulots d'étranglement dans votre application. Vous recherchez simplement de longues requêtes et vous pouvez analyser ce qui ne va pas.
Problème 3. Erreurs
Le dernier problème, ce sont les erreurs. Oui, je suis rusé. Je ne vais pas vous aider à vous débarrasser des erreurs de l'application, mais je vais vous dire ce que vous pouvez faire ensuite.

Le contexte. Vous pouvez dire: «Danya, nous enregistrons des erreurs, nous avons des alertes pour cinq cents, nous les avons configurées. Qu'est-ce que vous voulez? Nous nous sommes connectés, nous nous connectons et nous enregistrerons et déboguerons.
Vous ne connaissez pas l'importance de l'erreur à partir des journaux. Quelle est l'importance? Ici, vous avez une erreur cool et l'erreur de connexion à la base de données. La base s'est effondrée. Je voudrais voir immédiatement que cette erreur n'est pas si importante, et s'il n'y a pas de temps, ignorez-la, mais corrigez la plus importante.
Le taux d'erreur est un contexte qui peut nous aider à le déboguer. Comment suivre les erreurs? Continuons, nous avons eu une erreur il y a un mois, et maintenant elle est réapparue. J'aimerais trouver immédiatement une solution et la corriger ou comparer son apparence avec l'une des versions.
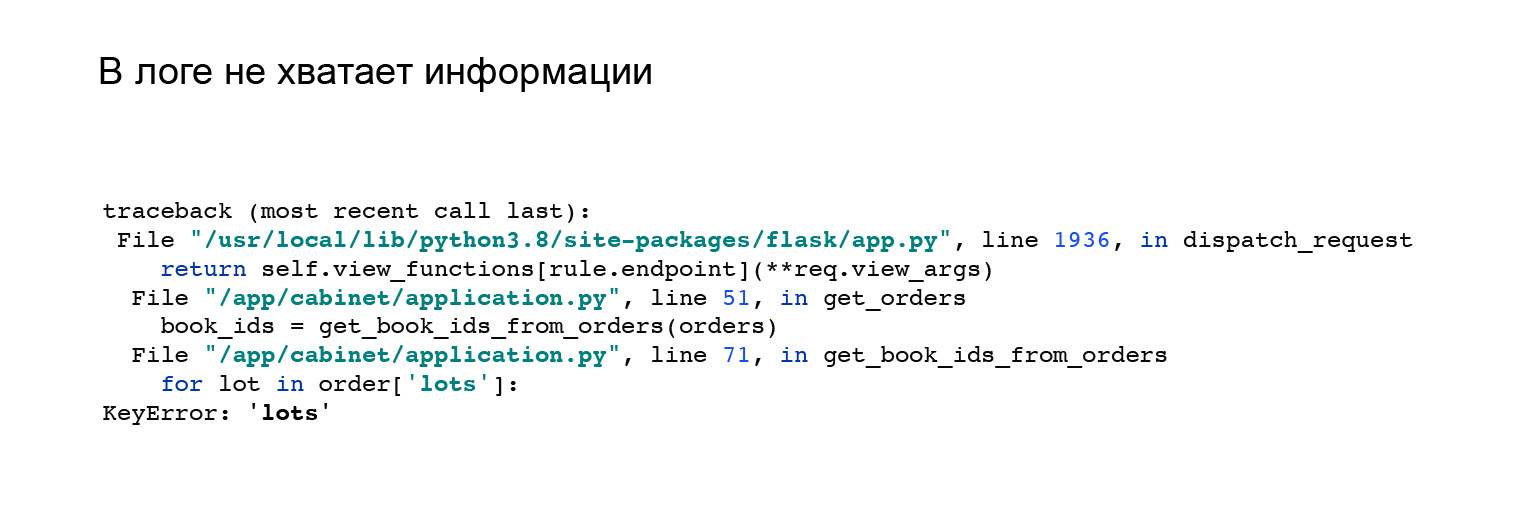
Voici un bon exemple. Quand j'ai vu l'intégration avec Jaeger, j'ai un peu changé mon API. J'ai changé le format de la réponse de l'application. J'ai eu cette erreur. Mais il n'est pas clair pourquoi je n'ai pas de clé, beaucoup dans l'objet de commande, et il n'y a rien qui puisse m'aider. Comme, voyez l'erreur ici, reproduisez-la et détectez-la vous-même.

Implémentons la sentinelle. Il s'agit d'un outil de suivi des bogues qui nous aidera à résoudre des problèmes similaires et à trouver le contexte de l'erreur. Prenez la bibliothèque standard maintenue par les développeurs sentinelles. En quatre lignes de code, nous l'ajoutons à notre application. Tout.
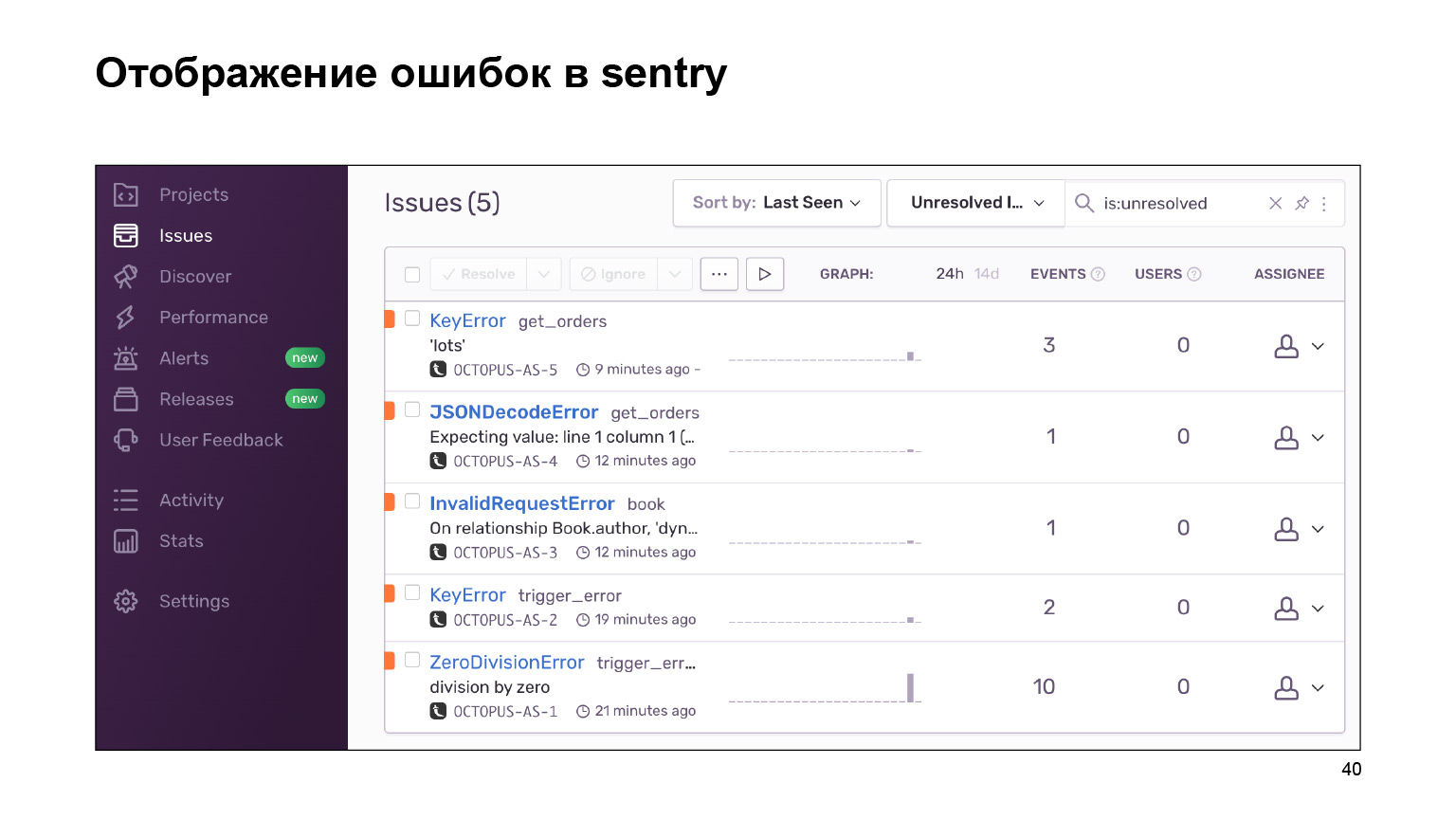
Qu'avons-nous obtenu en sortant? Voici un tableau de bord avec des erreurs qui peuvent être regroupées par projet et que vous pouvez suivre. Une énorme toile de journaux d'erreurs est regroupée en journaux identiques et similaires. Des statistiques leur sont fournies. Et vous pouvez également traiter ces erreurs en utilisant l'interface.
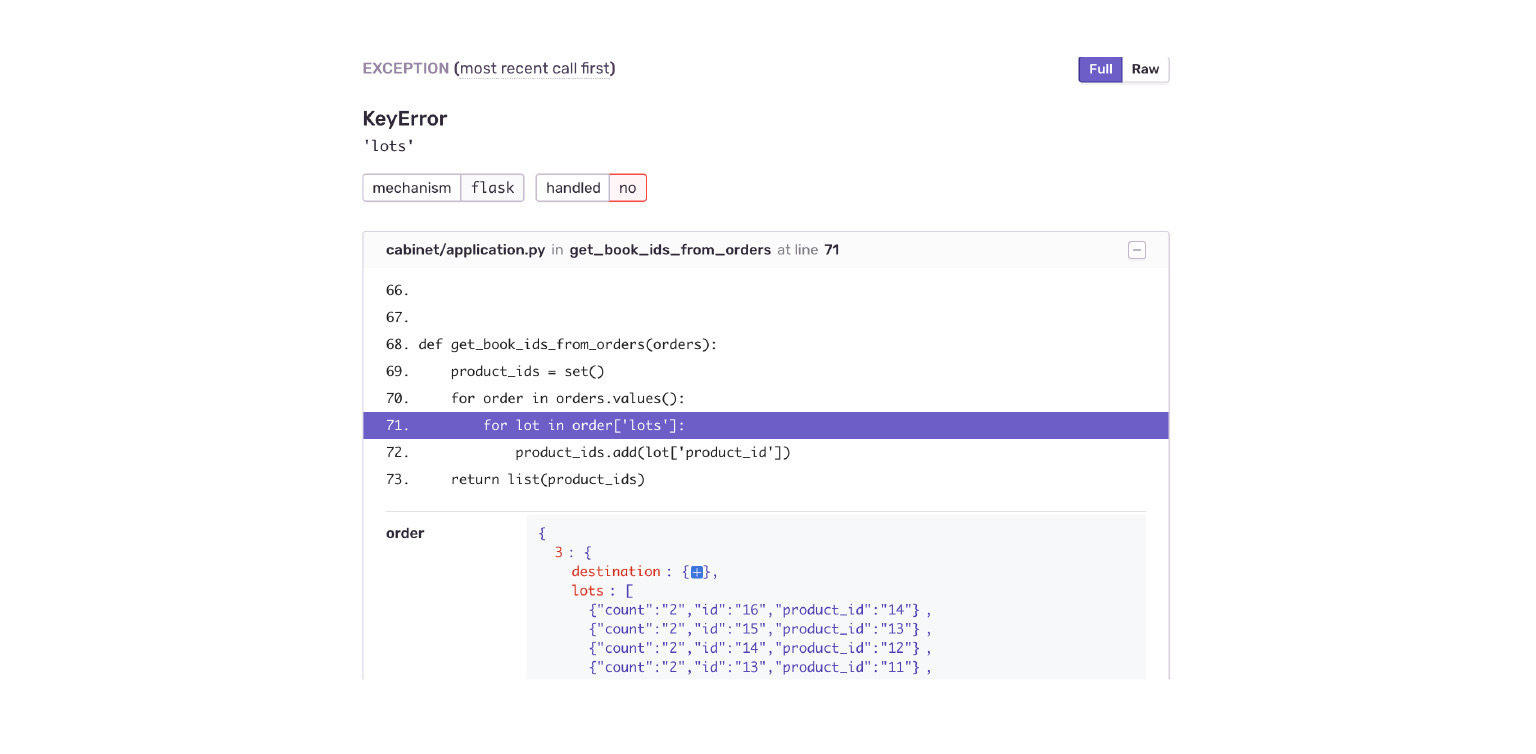
Regardons notre exemple. Tomber dans une KeyError. Nous voyons immédiatement le contexte de l'erreur, ce qui était dans l'objet de commande, ce qui n'y était pas. Je vois tout de suite par erreur que l'application Delivery m'a donné une nouvelle structure de données. Le cabinet n'est tout simplement pas prêt pour cela.

Que donne la sentinelle en plus de ce que j'ai listé? Formalisons.
Il s'agit du magasin d'erreurs où vous pouvez les rechercher. Il existe des outils pratiques pour cela. Il existe un regroupement des erreurs - par projets, par similitude. Sentry fournit des intégrations avec différents trackers. Autrement dit, vous pouvez suivre vos erreurs, travailler avec elles. Vous pouvez simplement ajouter la tâche à votre contexte et c'est tout. Cela aide au développement.
Statistiques d'erreur. Encore une fois, c'est facile à comparer avec le déploiement d'une version. Sentry vous aidera avec cela. Des événements similaires qui se sont produits à côté de l'erreur peuvent également vous aider à trouver et à comprendre ce qui l'a conduit.

Résumons. Nous avons rédigé une application simple mais répondant aux besoins. Il vous aide à le développer et à le maintenir dans son cycle de vie. Qu'avons-nous fait? Nous avons collecté les journaux dans un référentiel. Cela nous a donné l'opportunité de ne pas les chercher à différents endroits. De plus, nous avons maintenant une recherche dans les journaux et des fonctionnalités tierces, nos outils.
Traçage intégré. Nous pouvons désormais surveiller visuellement le flux de données dans notre application.
Et nous avons ajouté un outil pratique pour traiter les erreurs. Ils seront dans notre application, quels que soient nos efforts. Mais nous allons les réparer plus vite et mieux.
Que pouvez-vous ajouter d'autre? L'application elle-même est prête, il y a un lien, vous pouvez voir comment cela se fait. Toutes les intégrations y sont élevées. Par exemple, l'intégration avec Elasticsearch ou le traçage. Entrez et voyez.
Une autre chose intéressante que je n'ai pas eu le temps de couvrir est requests_id. Presque pas différent de trace_id, qui est utilisé dans les traces. Mais nous sommes responsables de requests_id, c'est sa caractéristique la plus importante. Le manager peut venir nous voir tout de suite avec requests_id, nous n'avons pas besoin de le chercher. Nous commencerons immédiatement à résoudre notre problème. Très cool.
Et n'oubliez pas que les outils que nous avons mis en œuvre sont des frais généraux. Ce sont des problèmes qui doivent être résolus pour chaque application. Vous ne pouvez pas implémenter sans réfléchir toutes nos intégrations, vous simplifier la vie, puis réfléchir à quoi faire avec une application inhibitrice.
Vérifiez-le. Si cela ne vous affecte pas, cool. Vous n'avez que les avantages et ne résolvez pas les problèmes avec les freins. N'oublie pas ça. Merci à tous pour votre écoute.