Pendant longtemps, je n'ai écrit aucun article et, je pense, il est temps d'écrire comment les connaissances en science des données, obtenues lors de la formation de la spécialisation bien connue de Yandex et MIPT "Machine Learning and Data Analysis", ont été utiles. Certes, pour être honnête, il convient de noter que les connaissances n'ont pas été pleinement acquises - la spécialité n'est pas terminée :) Cependant, il est déjà possible de résoudre de simples problèmes commerciaux réels. Ou est-ce nécessaire? Cette question sera répondue en quelques paragraphes.
Donc, aujourd'hui, dans cet article, je vais raconter au cher lecteur ma première expérience de participation à un concours ouvert. Je tiens à signaler tout de suite que mon objectif du concours n'était pas de remporter de prix. Le seul désir était de m'essayer dans le monde réel :) Oui, en plus il se trouve que le sujet du concours ne recoupe pratiquement pas le matériel des cours passés. Cela a ajouté quelques complications, mais avec lui, la concurrence est devenue encore plus intéressante et précieuse l'expérience acquise à partir de là.
Par tradition, je désignerai qui peut être intéressé par l'article. Premièrement, si vous avez déjà terminé les deux premiers cours de la spécialisation ci-dessus et que vous souhaitez vous essayer à des problèmes pratiques, mais que vous êtes timide et craignez que cela ne fonctionne pas et que vous vous moquiez de vous, etc. Après avoir lu l'article, ces craintes, je l'espère, seront dissipées. Deuxièmement, vous résolvez peut-être un problème similaire et ne savez pas du tout par où entrer. Et voici un prêt-à-l'emploi sans prétention, comme le disent les vrais datainters, une base de référence :)
Ici, nous aurions déjà dû esquisser le plan de recherche, mais nous allons faire une petite digression et essayer de répondre à la question du premier paragraphe - si un débutant en datainting a besoin de s'essayer à de telles compétitions. Les opinions divergent sur ce point. Personnellement, mon avis est nécessaire! Laissez-moi vous expliquer pourquoi. Il y a plusieurs raisons, je ne vais pas tout énumérer, j'indiquerai les plus importantes. Premièrement, ces concours contribuent à consolider les connaissances théoriques dans la pratique. Deuxièmement, dans ma pratique, presque toujours, l'expérience acquise dans des conditions proches du combat, motive très fortement pour de nouveaux exploits. Troisièmement, et c'est la chose la plus importante - pendant le concours, vous avez la possibilité de communiquer avec d'autres participants dans des discussions spéciales, vous n'avez même pas à communiquer, vous pouvez simplement lire ce que les gens écrivent et cela a) conduit souvent à des réflexions intéressantes surquels autres changements apporter à l'étude; et b) donne confiance pour valider ses propres idées, surtout si elles sont exprimées dans le chat. Ces avantages doivent être abordés avec une certaine prudence, pour qu'il n'y ait pas de sentiment d'omniscience ...
Maintenant, un peu sur la façon dont j'ai décidé de participer. J'ai appris l'existence de la compétition quelques jours avant qu'elle ne commence. La première pensée est «eh bien, si j'avais eu connaissance du concours il y a un mois, je me serais préparé, mais j'aurais étudié quelques matériaux supplémentaires qui pourraient être utiles pour mener des recherches, sinon, sans préparation, je ne peux pas respecter le délai ...», le second la pensée «en fait, ce qui pourrait ne pas fonctionner si l'objectif n'est pas un prix, mais la participation, d'autant plus que les participants dans 95% des cas parlent russe, plus il y a des discussions spéciales pour la discussion, il y aura une sorte de webinaires des organisateurs. En fin de compte, il sera possible de voir des datasinists en direct de toutes bandes et tailles ... ". Comme vous l'avez deviné, la deuxième pensée a gagné, et ce n'a pas été en vain - juste quelques jours de travail acharné et j'ai eu une expérience précieuse, bien que simple,mais tout à fait une tâche commerciale. Par conséquent, si vous êtes sur le point de conquérir les hauteurs de la science des données et de voir la compétition à venir, oui dans votre langue maternelle, avec un support dans les chats et que vous avez du temps libre - n'hésitez pas pendant longtemps - essayez et que la force vous accompagne! Sur une note positive, nous passons à la tâche et au plan de recherche.
Noms correspondants
Nous ne nous torturerons pas et ne proposerons pas une description du problème, mais nous donnerons le texte original du site Web de l'organisateur du concours.
Une tâche
Lors de la recherche de nouveaux clients, SIBUR doit traiter des informations sur des millions de nouvelles entreprises provenant de diverses sources. Dans le même temps, les noms des sociétés peuvent avoir des orthographes différentes, contenir des abréviations ou des erreurs, être affiliées à des sociétés déjà connues du SIBUR.
Pour traiter plus efficacement les informations sur les clients potentiels, SIBUR a besoin de savoir si les deux noms sont liés (c'est-à-dire appartiennent à la même entreprise ou à des sociétés affiliées).
Dans ce cas, SIBUR pourra utiliser des informations déjà connues sur la société elle-même ou sur les sociétés affiliées, ne pas dupliquer les appels à la société ou ne pas perdre de temps sur des sociétés non pertinentes ou des filiales de concurrents.
L'exemple d'apprentissage contient des paires de noms provenant de différentes sources (y compris des noms personnalisés) et du balisage.
Le balisage a été obtenu en partie à la main, en partie de manière algorithmique. En outre, le balisage peut contenir des erreurs. Vous allez créer un modèle binaire qui prédit si deux noms sont liés. La métrique utilisée dans cette tâche est F1.
Dans cette tâche, il est possible et même nécessaire d'utiliser des sources de données ouvertes pour enrichir l'ensemble de données ou trouver des informations supplémentaires importantes pour identifier les sociétés affiliées.
Informations supplémentaires sur la tâche
Découvrez-moi pour plus d'informations
, . , : , , Sibur Digital, , Sibur international GMBH , “ International GMBH” .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source , . — . .
, - – . , , - , , , .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
, , , .. crowdsource
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source
open source , . — . .
, - – . , , - , , , .
Les données
train.csv - ensemble de formation
test.csv - ensemble de test
sample_submission.csv - exemple de solution au format correct
Nommer baseline.ipynb - code
baseline_submission.csv - solution de base
Veuillez noter que les organisateurs du concours ont pris soin de la jeune génération et ont publié une solution de base au problème, ce qui donne une qualité f1 d'environ 0,1. C'est la première fois que je participe à des concours et la première fois que je vois ça :)
Donc, après nous être familiarisés avec la tâche elle-même et les exigences de sa solution, passons au plan de solution.
Plan de résolution de problèmes
Mise en place des instruments techniques
Chargons les bibliothèques
Écrivons des fonctions auxiliaires
Prétraitement des données
… -. !
50 & Drop it smart.
Calculons la distance de Levenshtein
Calculons la distance de Levenshtein normalisée
Visualisez les caractéristiques
Comparez les mots dans le texte pour chaque paire et générez un grand nombre de caractéristiques
Comparez les mots du texte avec des mots des noms des 50 principales marques de portefeuille dans les industries pétrochimique et de la construction. Prenons le deuxième gros tas de fonctionnalités. Deuxième CHIT
Préparation des données pour l'alimentation du modèle
Mise en place et formation du modèle
Résultats du concours
Sources d'information
Maintenant que nous nous sommes familiarisés avec le plan de recherche, passons à sa mise en œuvre.
Mise en place des instruments techniques
Chargement des bibliothèques
En fait, tout est simple ici, nous allons d'abord installer les bibliothèques manquantes
Installez la bibliothèque pour déterminer la liste des pays, puis supprimez-les du texte
pip install pycountry
Installer une bibliothèque pour déterminer la distance de Levenshtein entre les mots du texte les uns avec les autres et avec les mots de différentes listes
pip install strsimpy
Nous installerons la bibliothèque, à l'aide de laquelle nous translittérerons le texte russe en latin
pip install cyrtranslit
Extraire les bibliothèques
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslitÉcrivons des fonctions auxiliaires
Il est recommandé de spécifier la fonction sur une seule ligne au lieu de copier un gros morceau de code. Nous le ferons, presque toujours.
Je ne dirai pas que la qualité du code dans les fonctions est excellente. Dans certains endroits, il devrait certainement être optimisé, mais à des fins de recherche rapide, seule la précision des calculs sera suffisante.
Ainsi, la première fonction convertit le texte en minuscules
Le code
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()Les quatre fonctions suivantes permettent de visualiser l'espace des entités étudiées et leur capacité à séparer les objets par des étiquettes cibles - 0 ou 1.
Le code
# statistic table for analyse float values (it needs to make histogramms and boxplots)
def data_statistics(data,analyse,title_print):
data0 = data[data['target']==0][analyse]
data1 = data[data['target']==1][analyse]
data_describe = pd.DataFrame()
data_describe['target_0'] = data0.describe()
data_describe['target_1'] = data1.describe()
data_describe = data_describe.T
if title_print == 'yes':
print ('\033[1m' + ' ',analyse,'\033[m')
elif title_print == 'no':
None
return data_describe
# histogramms for float values
def hist_fz(data,data_describe,analyse,size):
print ()
print ('\033[1m' + 'Information about',analyse,'\033[m')
print ()
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
min_data = data_describe['min'].min()
max_data = data_describe['max'].max()
data0_mean = data_describe.loc['target_0']['mean']
data0_median = data_describe.loc['target_0']['50%']
data0_min = data_describe.loc['target_0']['min']
data0_max = data_describe.loc['target_0']['max']
data0_count = data_describe.loc['target_0']['count']
data1_mean = data_describe.loc['target_1']['mean']
data1_median = data_describe.loc['target_1']['50%']
data1_min = data_describe.loc['target_1']['min']
data1_max = data_describe.loc['target_1']['max']
data1_count = data_describe.loc['target_1']['count']
print ('\033[4m' + 'Analyse'+ '\033[m','No duplicates')
figure(figsize=size)
sns.distplot(data_0,color='darkgreen',kde = False)
plt.scatter(data0_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data0_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data0_count,
' Min:', round(data0_min,2),
' Max:', round(data0_max,2),
' Mean:', round(data0_mean,2),
' Median:', round(data0_median,2))
print ()
print ('\033[4m' + 'Analyse'+ '\033[m','Duplicates')
figure(figsize=size)
sns.distplot(data_1,color='darkred',kde = False)
plt.scatter(data1_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data1_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data_1.count(),
' Min:', round(data1_min,2),
' Max:', round(data1_max,2),
' Mean:', round(data1_mean,2),
' Median:', round(data1_median,2))
# draw boxplot
def boxplot(data,analyse,size):
print ('\033[4m' + 'Analyse'+ '\033[m','All pairs')
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
figure(figsize=size)
sns.boxplot(x=analyse,y='target',data=data,orient='h',
showmeans=True,
meanprops={"marker":"o",
"markerfacecolor":"dimgray",
"markeredgecolor":"black",
"markersize":"14"},
palette=['palegreen', 'salmon'])
plt.ylabel('target', size=14)
plt.xlabel(analyse, size=14)
plt.show()
# draw graph for analyse two choosing features for predict traget label
def two_features(data,analyse1,analyse2,size):
fig = plt.subplots(figsize=size)
x0 = data[data['target']==0][analyse1]
y0 = data[data['target']==0][analyse2]
x1 = data[data['target']==1][analyse1]
y1 = data[data['target']==1][analyse2]
plt.scatter(x0,y0,c='green',marker='.')
plt.scatter(x1,y1,c='black',marker='+')
plt.xlabel(analyse1)
plt.ylabel(analyse2)
title = [analyse1,analyse2]
plt.title(title)
plt.show()La cinquième fonction est conçue pour générer une table de suppositions et d'erreurs de l'algorithme, mieux connue sous le nom de table de conjugaison.
En d'autres termes, après la formation du vecteur de prévisions, nous devons comparer la prévision avec les étiquettes cibles. Le résultat d'une telle comparaison devrait être un tableau de conjugaison pour chaque paire d'entreprises de l'échantillon de formation. Dans le tableau de conjugaison pour chaque paire, le résultat de l'appariement de la prévision à la classe de l'échantillon d'apprentissage sera déterminé. La classification correspondante est acceptée comme suit: «Vrai positif», «Faux positif», «Vrai négatif» ou «Faux négatif». Ces données sont très importantes pour analyser le fonctionnement de l'algorithme et prendre des décisions sur l'amélioration du modèle et de l'espace des fonctionnalités.
Le code
def contingency_table(X,features,probability_level,tridx,cvidx,model):
tr_predict_proba = model.predict_proba(X.iloc[tridx][features].values)
cv_predict_proba = model.predict_proba(X.iloc[cvidx][features].values)
tr_predict_target = (tr_predict_proba[:, 1] > probability_level).astype(np.int)
cv_predict_target = (cv_predict_proba[:, 1] > probability_level).astype(np.int)
X_tr = X.iloc[tridx]
X_cv = X.iloc[cvidx]
X_tr['predict_proba'] = tr_predict_proba[:,1]
X_cv['predict_proba'] = cv_predict_proba[:,1]
X_tr['predict_target'] = tr_predict_target
X_cv['predict_target'] = cv_predict_target
# make true positive column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false positive column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make true negative column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false negative column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
return X_tr,X_cvLa sixième fonction est conçue pour former la matrice de conjugaison. À ne pas confondre avec la table de couplage. Bien que l'un découle de l'autre. Tu verras tout plus loin
Le code
def matrix_confusion(X):
list_matrix = ['True_Positive','False_Positive','True_Negative','False_Negative']
tr_pos = X[list_matrix].sum().loc['True_Positive']
f_pos = X[list_matrix].sum().loc['False_Positive']
tr_neg = X[list_matrix].sum().loc['True_Negative']
f_neg = X[list_matrix].sum().loc['False_Negative']
matrix_confusion = pd.DataFrame()
matrix_confusion['0_algorythm'] = np.array([tr_neg,f_neg]).T
matrix_confusion['1_algorythm'] = np.array([f_pos,tr_pos]).T
matrix_confusion = matrix_confusion.rename(index={0: '0_target', 1: '1_target'})
return matrix_confusionLa septième fonction est conçue pour visualiser le rapport sur le fonctionnement de l'algorithme, qui comprend la matrice de conjugaison, les valeurs de la métrique précision, rappel, f1
Le code
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')En utilisant les huitième et neuvième fonctions, nous analysons l'utilité des caractéristiques pour le modèle utilisé de Light GBM en termes de valeur du coefficient `` Gain d'information '' pour chaque caractéristique étudiée
Le code
def table_gain_coef(model,features,start,stop):
data_gain = pd.DataFrame()
data_gain['Features'] = features
data_gain['Gain'] = model.booster_.feature_importance(importance_type='gain')
return data_gain.sort_values('Gain', ascending=False)[start:stop]
def gain_hist(df,size,start,stop):
fig, ax = plt.subplots(figsize=(size))
x = (df.sort_values('Gain', ascending=False)['Features'][start:stop])
y = (df.sort_values('Gain', ascending=False)['Gain'][start:stop])
plt.bar(x,y)
plt.xlabel('Features')
plt.ylabel('Gain')
plt.xticks(rotation=90)
plt.show()La dixième fonction est nécessaire pour former un tableau du nombre de mots correspondants pour chaque paire d'entreprises.
Cette fonction peut également être utilisée pour former un tableau de mots NON correspondants.
Le code
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum La onzième fonction transcrit le texte russe dans l'alphabet latin
Le code
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
.
, , , . , ,
<spoiler title="">
<source lang="python">def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return datareturn text_transliterate Les
treizième et quatorzième fonctions sont nécessaires pour afficher et générer la table de distance de Levenshtein et d'autres indicateurs importants.
De quel type de tableau s'agit-il, quelles sont les métriques et comment se forme-t-il? Regardons comment la table est formée étape par étape:
- Étape 1. Définissons les données dont nous aurons besoin. ID de paire, finition de texte - Les deux colonnes, liste des noms de portefeuille (50 principales sociétés pétrochimiques et de construction).
- Étape 2. Dans la colonne 1, dans chaque paire de chaque mot, nous mesurons la distance de Levenshtein à chaque mot de la liste des noms de détention, ainsi que la longueur de chaque mot et le rapport de la distance à la longueur.
- 3. , 0.4, id , .
- 4. , 0.4, .
- 5. , ID , — . id ( id ). .
- Étape 6. Collez le tableau résultant avec le tableau de recherche.
Une caractéristique importante: le
calcul prend beaucoup de temps en raison du code écrit à la hâte
Le code
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return dataPrétraitement des données
D'après ma petite expérience, c'est le prétraitement des données au sens large de cette expression qui prend plus de temps. Allons dans l'ordre.
Charger des données
Tout est très simple ici. Chargeons les données et remplaçons le nom de la colonne par le libellé cible "is_duplicate" par "target". C'est pour faciliter l'utilisation des fonctions - certaines d'entre elles ont été écrites dans des recherches antérieures et elles utilisent le nom de la colonne avec l'étiquette cible comme "cible".
Le code
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})Regardons les données
Les données ont été chargées. Voyons combien d'objets sont au total et à quel point ils sont équilibrés.
Le code
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
print ('Balance is', round(100*target_1/target_0,2),'%')Tableau №1 "Balance des marques"

Il y a beaucoup d'objets - près de 500 mille et ils ne sont pas du tout équilibrés. Autrement dit, sur près de 500 000 objets, moins de 4 000 au total ont une étiquette cible de 1 (moins de 1%).
Jetons un œil au tableau lui-même. Regardons les cinq premiers objets étiquetés 0 et les cinq premiers objets étiquetés 1.
Le code
display(text_train[text_train['target']==0].head(5))
display(text_train[text_train['target']==1].head(5))Tableau n ° 2 "Les 5 premiers objets de la classe 0", tableau n ° 3 "Les 5 premiers objets de la classe 1"
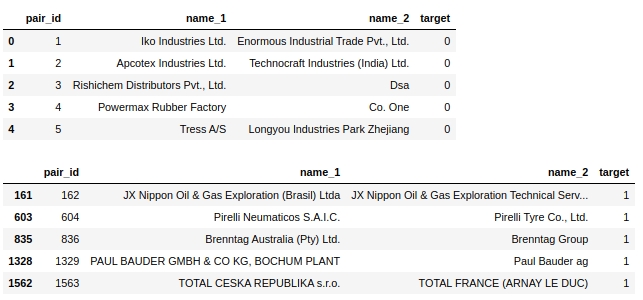
Quelques étapes simples se suggèrent immédiatement: ramener le texte dans un seul registre, supprimer les mots vides, tels que 'ltd', supprimer les pays et en même temps les noms géographiques objets.
En fait, quelque chose comme ça peut être résolu dans ce problème - vous effectuez un prétraitement, assurez-vous qu'il fonctionne comme il se doit, exécutez le modèle, regardez la qualité et analysez sélectivement les objets sur lesquels le modèle est erroné. C'est ainsi que j'ai fait mes recherches. Mais dans l'article lui-même, la solution finale est donnée et la qualité de l'algorithme après chaque prétraitement n'est pas comprise, à la fin de l'article nous procéderons à une analyse finale. Sinon, l'article serait de taille indescriptible :)
Faisons des copies
Pour être honnête, je ne sais pas pourquoi je fais ça, mais pour une raison quelconque, je le fais toujours. Je vais le faire cette fois aussi
Le code
baseline_train = text_train.copy()
baseline_test = text_test.copy()Convertir tous les caractères du texte en minuscules
Le code
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)Supprimer les noms de pays
Il est à noter que les organisateurs du concours sont de grands compagnons! En plus de la mission, ils ont donné un ordinateur portable avec une base de référence très simple, dans laquelle était fourni, y compris le code ci-dessous.
Le code
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)Supprimer les signes et les caractères spéciaux
Le code
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)Supprimer les numéros
La suppression des chiffres du texte directement sur le front, dans la première tentative, a grandement gâché la qualité du modèle. Je vais donner le code ici, mais en fait il n'a pas été utilisé.
Notez également que jusqu'à présent, nous avons effectué la transformation directement sur les colonnes qui nous ont été données. Créons maintenant de nouvelles colonnes pour chaque prétraitement. Il y aura plus de colonnes, mais si quelque part à un certain stade du prétraitement un échec se produit, ce n'est pas grave, vous n'avez pas besoin de tout faire depuis le tout début, car nous aurons des colonnes de chaque étape du prétraitement.
Un code qui a gâché la qualité. Vous devez être plus délicat
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Supprimons ... la première liste de mots vides. Manuellement!
Il est maintenant suggéré de définir et de supprimer les mots vides de la liste de mots dans les noms de sociétés.
Nous avons compilé la liste sur la base d'un examen manuel de l'échantillon de formation. Logiquement, une telle liste devrait être compilée automatiquement en utilisant les approches suivantes:
- tout d'abord, utilisez les 10 mots les plus courants (20 50 100).
- deuxièmement, pour utiliser des bibliothèques de mots vides standard dans différentes langues. Par exemple, les désignations de formes organisationnelles et juridiques d'organisations dans diverses langues (LLC, PJSC, CJSC, ltd, gmbh, inc, etc.)
- troisièmement, il est logique de compiler une liste de noms de lieux dans différentes langues
Nous reviendrons sur la première option pour compiler automatiquement une liste des mots les plus fréquemment rencontrés, mais pour l'instant nous nous intéressons au prétraitement manuel.
Le code
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', '', '', '', '', '', '', '', '', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Vérifions sélectivement que nos mots vides ont bien été supprimés du texte.
Le code
baseline_train[baseline_train.name_1_non_stop_words.str.contains("factory")].head(3)Tableau 4 «Contrôle sélectif du code pour supprimer les mots

vides » Tout semble fonctionner. Suppression de tous les mots vides séparés par un espace. Ce que nous voulions. Passer à autre chose.
Transformons le texte russe dans l'alphabet latin
J'utilise ma fonction auto-écrite et ma bibliothèque cyrtranslit pour cela. Cela semble fonctionner. Vérifié manuellement.
Le code
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])Regardons une paire avec l'id 353150. Dans celle-ci, la deuxième colonne ("nom_2") a le mot "Michelin", après prétraitement le mot est déjà écrit comme ceci "mishlen" (voir la colonne "name_2_transliterated"). Pas tout à fait correct, mais clairement meilleur.
Le code
pair_id = 353150
baseline_train[baseline_train['pair_id']==353150]Tableau numéro 5 "Vérification sélective du code pour la translittération"

Commençons la compilation automatique d'une liste des 50 mots les plus courants et laissez tomber intelligemment. Premier CHIT
Titre un peu délicat. Jetons un coup d'œil à ce que nous allons faire ici.
Tout d'abord, nous combinerons le texte des première et deuxième colonnes en un seul tableau et compterons pour chaque mot unique le nombre de fois où il se produit.
Deuxièmement, choisissons le top 50 de ces mots. Et il semblerait que vous puissiez les supprimer, mais non. Ces mots peuvent contenir les noms des exploitations («total», «knauf», «shell», ...), mais c'est une information très importante et elle ne peut pas être perdue, car nous allons l'utiliser plus loin. Par conséquent, nous allons opter pour un tour de triche (interdit). Pour commencer, sur la base d'une étude minutieuse et sélective de l'échantillon de formation, nous établirons une liste des noms des exploitations fréquemment rencontrées. La liste ne sera pas complète, sinon ce ne serait pas du tout juste :) Mais puisque nous ne sommes pas à la recherche d'un prix, pourquoi pas. Ensuite, nous comparerons le tableau des 50 mots les plus fréquents avec la liste des noms de fonds et supprimerons de la liste les mots qui correspondent aux noms des fonds.
La deuxième liste de mots vides est maintenant terminée. Vous pouvez supprimer des mots du texte.
Mais avant cela, je voudrais insérer une petite remarque concernant la liste de triche des noms de holding. Le fait que nous ayons dressé une liste des noms des exploitations sur la base d'observations nous a rendu la vie beaucoup plus facile. Mais en fait, nous aurions pu compiler une telle liste d'une manière différente. Par exemple, vous pouvez prendre les notes des plus grandes entreprises des secteurs de la pétrochimie, de la construction, de l'automobile et autres, les combiner et prendre les noms des participations à partir de là. Mais pour les besoins de nos recherches, nous nous limiterons à une approche simple. Cette approche est interdite au sein de la compétition! De plus, les organisateurs du concours, le travail des candidats pour les places primées sont contrôlés pour les techniques interdites. Faites attention!
Le code
list_top_companies = ['arlanxeo', 'basf', 'bayer', 'bdp', 'bosch', 'brenntag', 'contitech',
'daewoo', 'dow', 'dupont', 'evonik', 'exxon', 'exxonmobil', 'freudenberg',
'goodyear', 'goter', 'henkel', 'hp', 'hyundai', 'isover', 'itochu', 'kia', 'knauf',
'kraton', 'kumho', 'lusocopla', 'michelin', 'paul bauder', 'pirelli', 'ravago',
'rehau', 'reliance', 'sabic', 'sanyo', 'shell', 'sherwinwilliams', 'sojitz',
'soprema', 'steico', 'strabag', 'sumitomo', 'synthomer', 'synthos',
'total', 'trelleborg', 'trinseo', 'yokohama']
# drop top 50 common words (NAME 1 & NAME 2) exept names of top companies
# first: make dictionary of frequency every word
list_words = baseline_train['name_1_transliterated'].to_string(index=False).split() +\
baseline_train['name_2_transliterated'].to_string(index=False).split()
freq_words = {}
for w in list_words:
freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame
df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
df_freq.columns = ['word','frequency']
df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
drop_list = list(set(df_freq_agg[0:50]['word'].to_string(index=False).split()) - set(list_top_companies))
# # check list of top 50 common words
# print (drop_list)
# drop the top 50 words
baseline_train['name_1_finish'] =\
baseline_train['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_finish'] =\
baseline_train['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_finish'] =\
baseline_test['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_finish'] =\
baseline_test['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
C'est là que nous en avons terminé avec le prétraitement des données. Commençons par générer de nouvelles fonctionnalités et évaluer visuellement leur capacité à séparer les objets par 0 ou 1.
Génération et analyse de fonctionnalités
Calculons la distance de Levenshtein
Utilisons la bibliothèque strsimpy et dans chaque paire (après tout le prétraitement), nous calculerons la distance Levenshtein entre le nom de l'entreprise et le nom de l'entreprise dans la deuxième colonne.
Le code
# create feature with LEVENSTAIN DISTANCE
levenshtein = Levenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["levenstein"] = baseline_train.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)
baseline_test["levenstein"] = baseline_test.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)Calculons la distance de Levenshtein normalisée
Tout est le même que ci-dessus, seulement nous compterons la distance normalisée.
En-tête de spoiler
# create feature with NORMALIZATION LEVENSTAIN DISTANCE
normalized_levenshtein = NormalizedLevenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["norm_levenstein"] = baseline_train.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)
baseline_test["norm_levenstein"] = baseline_test.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)Nous avons compté, et maintenant nous visualisons
Visualiser les fonctionnalités
Regardons la distribution du trait 'levenstein'
Le code
data = baseline_train
analyse = 'levenstein'
size = (12,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Graphiques # 1 "Histogramme et boîte avec une moustache pour évaluer la signification d'une caractéristique"
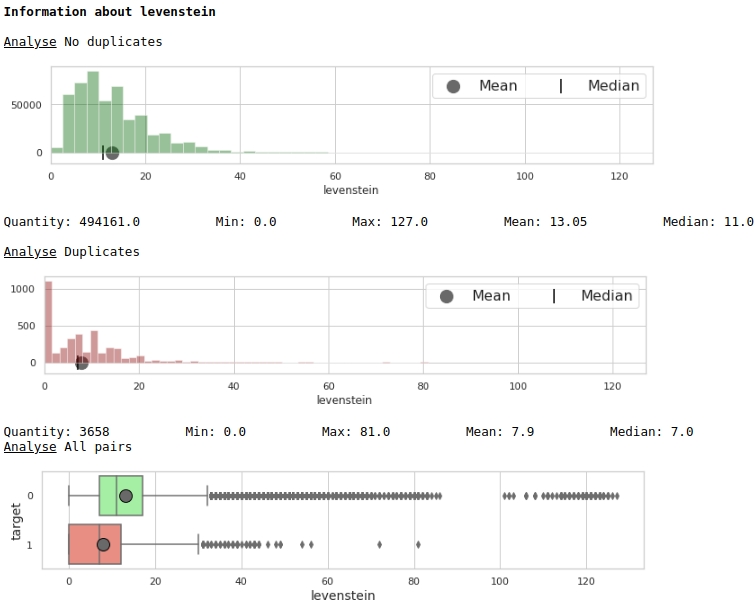
À première vue, une métrique peut baliser des données. Evidemment pas très bon, mais ça peut être utilisé.
Regardons la distribution du trait 'norm_levenstein'
En-tête de spoiler
data = baseline_train
analyse = 'norm_levenstein'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Graphiques №2 "Histogramme et boîte avec une moustache pour évaluer la signification du signe"

Déjà mieux. Voyons maintenant comment les deux entités combinées diviseront l'espace en objets 0 et 1.
Le code
data = baseline_train
analyse1 = 'levenstein'
analyse2 = 'norm_levenstein'
size = (14,6)
two_features(data,analyse1,analyse2,size)Graphique n ° 3 "Diagramme de dispersion" Un
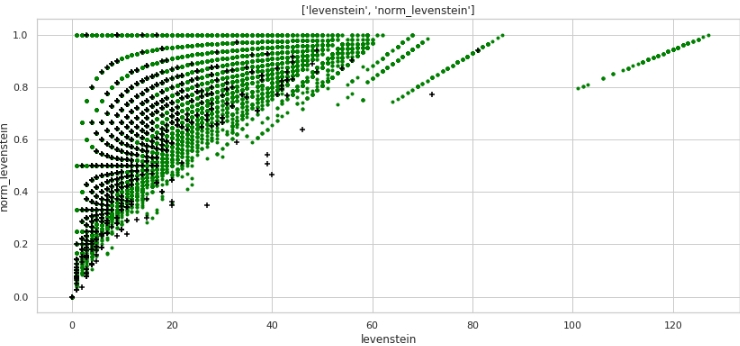
très bon balisage est obtenu. Ce n'est donc pas en vain que nous avons tellement prétraité les données :)
Tout le monde comprend qu'horizontalement - les valeurs de la métrique "levenstein", et verticalement - les valeurs de la métrique "norm_levenstein", et les points vert et noir sont des objets 0 et 1. Passons à autre chose.
Comparons les mots dans le texte pour chaque paire et générons un grand nombre de fonctionnalités
Ci-dessous, nous comparerons les mots dans les noms de sociétés. Créons les fonctionnalités suivantes:
- une liste de mots qui sont dupliqués dans les colonnes # 1 et # 2 de chaque paire
- une liste de mots qui ne sont PAS dupliqués
Sur la base de ces listes de mots, nous créerons les fonctionnalités que nous intégrerons au modèle entraîné:
- nombre de mots en double
- nombre de mots NON dupliqués
- somme de caractères, mots en double
- somme de caractères, PAS de mots en double
- longueur moyenne des mots en double
- longueur moyenne des mots NON dupliqués
- le rapport du nombre de doublons au nombre de NON en double
Le code ici n'est probablement pas très convivial, car, encore une fois, il a été écrit à la hâte. Mais cela fonctionne, mais il faudra une recherche rapide.
Le code
# make some information about duplicates and differences for TRAIN
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_train.shape[0]):
list1 = list(baseline_train[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_train[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TRAIN
baseline_train['duplicate'] = duplicates
baseline_train['difference'] = difference
baseline_train['duplicate_count'] = duplicate_count
baseline_train['duplicate_sum'] = duplicate_sum
baseline_train['duplicate_mean'] = baseline_train['duplicate_sum'] / baseline_train['duplicate_count']
baseline_train['duplicate_mean'] = baseline_train['duplicate_mean'].fillna(0)
baseline_train['dif_count'] = dif_count
baseline_train['dif_sum'] = dif_sum
baseline_train['dif_mean'] = baseline_train['dif_sum'] / baseline_train['dif_count']
baseline_train['dif_mean'] = baseline_train['dif_mean'].fillna(0)
baseline_train['ratio_duplicate/dif_count'] = baseline_train['duplicate_count'] / baseline_train['dif_count']
# make some information about duplicates and differences for TEST
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_test.shape[0]):
list1 = list(baseline_test[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_test[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TEST
baseline_test['duplicate'] = duplicates
baseline_test['difference'] = difference
baseline_test['duplicate_count'] = duplicate_count
baseline_test['duplicate_sum'] = duplicate_sum
baseline_test['duplicate_mean'] = baseline_test['duplicate_sum'] / baseline_test['duplicate_count']
baseline_test['duplicate_mean'] = baseline_test['duplicate_mean'].fillna(0)
baseline_test['dif_count'] = dif_count
baseline_test['dif_sum'] = dif_sum
baseline_test['dif_mean'] = baseline_test['dif_sum'] / baseline_test['dif_count']
baseline_test['dif_mean'] = baseline_test['dif_mean'].fillna(0)
baseline_test['ratio_duplicate/dif_count'] = baseline_test['duplicate_count'] / baseline_test['dif_count']
Nous visualisons certains des signes.
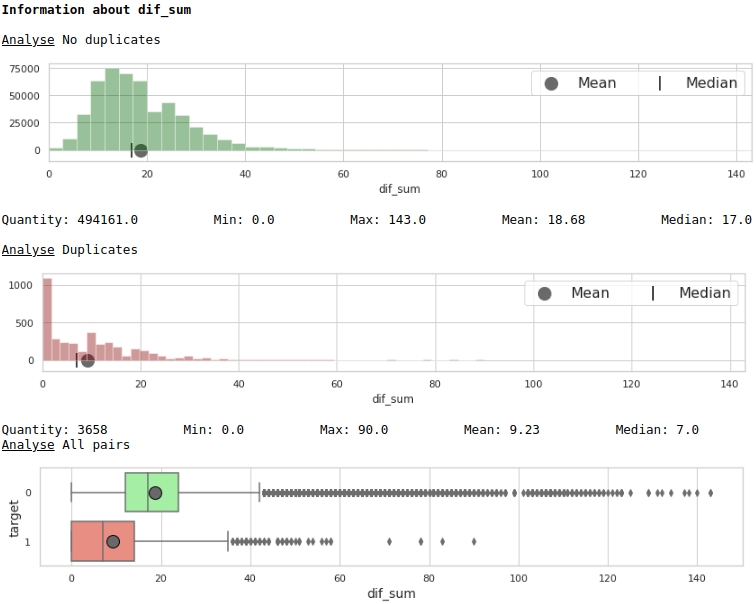
Le code
data = baseline_train
analyse = 'dif_sum'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Graphiques n ° 4 "Histogramme et encadré avec une moustache pour apprécier la signification du signe"
Le code
data = baseline_train
analyse1 = 'duplicate_mean'
analyse2 = 'dif_mean'
size = (14,6)
two_features(data,analyse1,analyse2,size)Graph №5 "Diagramme de dispersion"
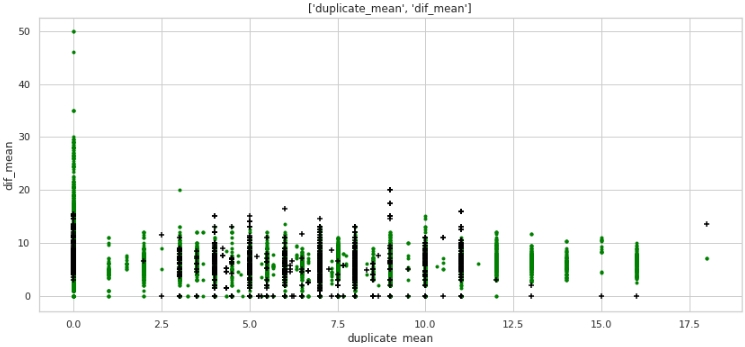
Ce que non, mais le balisage. Notez que beaucoup d'entreprises avec une étiquette cible de 1 n'ont aucun doublon dans le texte, et aussi beaucoup d'entreprises avec des doublons dans leurs noms, en moyenne plus de 12 mots, appartiennent à des entreprises avec une étiquette cible de 0.
Jetons un coup d'œil aux données tabulaires, préparons une requête pour Dans le premier cas: il n'y a aucun doublon dans le nom des entreprises, mais les entreprises sont les mêmes.
Le code
baseline_train[
baseline_train['duplicate_mean']==0][
baseline_train['target']==1].drop(
['duplicate', 'difference',
'name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated'],axis=1)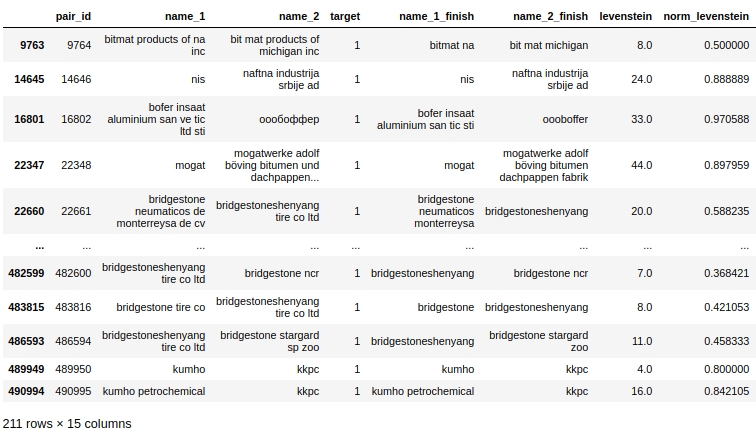
De toute évidence, il y a une erreur système dans notre traitement. Nous n'avons pas tenu compte du fait que les mots peuvent être orthographiés non seulement avec des erreurs, mais aussi simplement ensemble ou, au contraire, séparément lorsque cela n'est pas nécessaire. Par exemple, paire # 9764. Dans la première colonne «bitmat» dans le deuxième «bit mat» et maintenant ce n'est pas un double, mais la société est la même. Ou un autre exemple, paire # 482600 «bridgestoneshenyang» et «bridgestone».
Que pourrait-on faire. La première chose qui m'est venue à l'esprit était de comparer non pas directement sur le front, mais en utilisant la métrique de Levenshtein. Mais ici aussi, une embuscade nous attend: la distance entre «bridgestoneshenyang» et «bridgestone» ne sera pas petite. La lemmatisation viendra peut-être à la rescousse, mais encore une fois, on ne sait pas immédiatement comment les noms des entreprises peuvent être lemmatisés. Ou vous pouvez utiliser le coefficient de Tamimoto, mais laissons ce moment à des camarades plus expérimentés et passons à autre chose.
Comparons les mots du texte avec les mots des noms des 50 plus grandes marques holding dans les industries de la pétrochimie, de la construction et autres. Prenons le deuxième grand groupe de fonctionnalités. Deuxième CHIT
En fait, il y a deux violations des règles de participation au concours:
- -, , «duplicate_name_company»
- -, . , .
Les deux techniques sont interdites par les règles du concours. Vous pouvez contourner l'interdiction. Pour ce faire, vous devez compiler une liste de noms de holding non pas manuellement en fonction d'une vue sélective de l'échantillon d'apprentissage, mais automatiquement - à partir de sources externes. Mais alors, premièrement, la liste des fonds s'avérera longue et la comparaison des mots proposés dans le travail prendra très, bien, juste beaucoup de temps, et deuxièmement, cette liste doit encore être compilée :) Par conséquent, à des fins de simplicité de recherche, nous vérifierons dans quelle mesure la qualité du modèle s'améliorera avec ces signes. Pour l'avenir - la qualité augmente tout simplement incroyable!
Avec la première méthode, tout semble clair, mais la seconde approche nécessite des explications.
Déterminons donc la distance de Levenshtein entre chaque mot de chaque ligne de la première colonne avec le nom de l'entreprise et chaque mot de la liste des principales entreprises pétrochimiques (et pas seulement).
Si le rapport de la distance de Levenshtein à la longueur du mot est inférieur ou égal à 0,4, nous déterminons le rapport de la distance de Levenshtein au mot sélectionné dans la liste des principales entreprises à chaque mot de la deuxième colonne - le nom de la deuxième entreprise.
Si le deuxième coefficient (le rapport de la distance à la longueur du mot dans la liste des principales entreprises) s'avère inférieur ou égal à 0,4, nous fixons les valeurs suivantes dans le tableau:
- Levenshtein distance d'un mot de la liste des entreprises n ° 1 à un mot de la liste des meilleures entreprises
- Levenshtein distance d'un mot de la liste des entreprises n ° 2 à un mot de la liste des meilleures entreprises
- longueur d'un mot de la liste n ° 1
- longueur d'un mot de la liste n ° 2
- longueur de mot de la liste des meilleures entreprises
- le rapport de la longueur d'un mot de la liste # 1 à la distance
- le rapport de la longueur d'un mot de la liste n ° 2 à la distance
Il peut y avoir plus d'une correspondance sur une ligne, choisissons le minimum d'entre eux (fonction d'agrégation).
Je voudrais à nouveau attirer votre attention sur le fait que la méthode proposée pour générer des fonctionnalités est assez gourmande en ressources et qu'en cas d'obtention d'une liste d'une source externe, un changement dans le code de compilation des métriques sera nécessaire.
Le code
# create information about duplicate name of petrochemical companies from top list
list_top_companies = list_top_companies
dp_train = []
for i in list(baseline_train['duplicate']):
dp_train.append(''.join(list(set(i) & set(list_top_companies))))
dp_test = []
for i in list(baseline_test['duplicate']):
dp_test.append(''.join(list(set(i) & set(list_top_companies))))
baseline_train['duplicate_name_company'] = dp_train
baseline_test['duplicate_name_company'] = dp_test
# replace name duplicate to number
baseline_train['duplicate_name_company'] =\
baseline_train['duplicate_name_company'].replace('',0,regex=True)
baseline_train.loc[baseline_train['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
baseline_test['duplicate_name_company'] =\
baseline_test['duplicate_name_company'].replace('',0,regex=True)
baseline_test.loc[baseline_test['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
# create some important feature about similar words in the data and names of top companies for TRAIN
# (levenstein distance, length of word, ratio distance to length)
baseline_train = dist_name_to_top_list_make(baseline_train,
'name_1_finish','name_2_finish',list_top_companies)
# create some important feature about similar words in the data and names of top companies for TEST
# (levenstein distance, length of word, ratio distance to length)
baseline_test = dist_name_to_top_list_make(baseline_test,
'name_1_finish','name_2_finish',list_top_companies)
Regardons l'utilité des fonctionnalités à travers le prisme des graphiques
Le code
data = baseline_train
analyse = 'levenstein_dist_w1_top_w_min'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)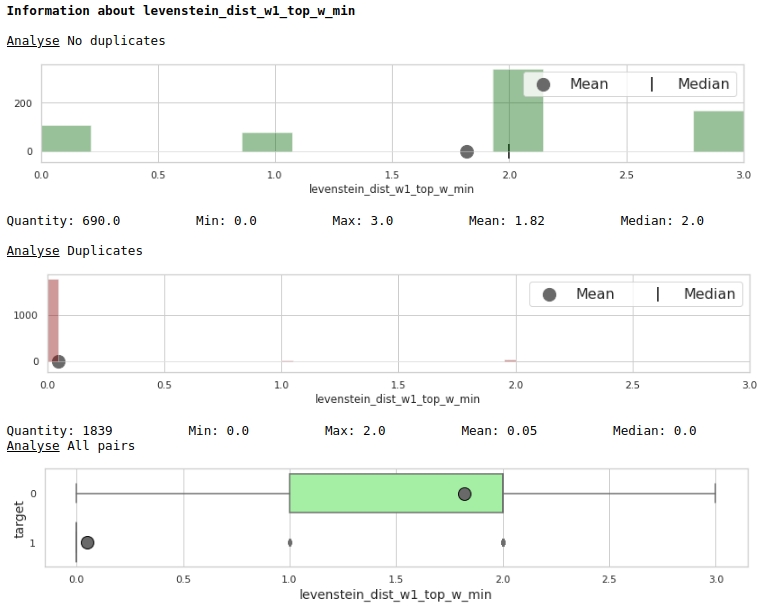
Très bien.
Préparation des données pour la soumission au modèle
Nous avons un grand tableau et nous n'avons pas besoin de toutes les données pour l'analyse. Regardons les noms des colonnes de la table.
Le code
baseline_train.columns
Sélectionnons les colonnes que nous analyserons.
Fixons la graine pour la reproductibilité du résultat.
Le code
# fix some parameters
features = ['levenstein','norm_levenstein',
'duplicate_count','duplicate_sum','duplicate_mean',
'dif_count','dif_sum','dif_mean','ratio_duplicate/dif_count',
'duplicate_name_company',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min'
]
seed = 42Avant d'entraîner enfin le modèle sur toutes les données disponibles et d'envoyer la solution pour vérification, il est logique de tester le modèle. Pour ce faire, nous divisons l'ensemble d'entraînement en entraînement conditionnel et test conditionnel. Nous en mesurerons la qualité et si cela nous convient, nous enverrons la solution au concours.
Le code
# provides train/test indices to split data in train/test sets
split = StratifiedShuffleSplit(n_splits=1, train_size=0.8, random_state=seed)
tridx, cvidx = list(split.split(baseline_train[features],
baseline_train["target"]))[0]
print ('Split baseline data train',baseline_train.shape[0])
print (' - new train data:',tridx.shape[0])
print (' - new test data:',cvidx.shape[0])Mise en place et formation du modèle
Nous utiliserons un arbre de décision de la bibliothèque Light GBM comme modèle.
Cela n'a aucun sens de trop enrouler les paramètres. Nous regardons le code.
Le code
# learning Light GBM Classificier
seed = 50
params = {'n_estimators': 1,
'objective': 'binary',
'max_depth': 40,
'min_child_samples': 5,
'learning_rate': 1,
# 'reg_lambda': 0.75,
# 'subsample': 0.75,
# 'colsample_bytree': 0.4,
# 'min_split_gain': 0.02,
# 'min_child_weight': 40,
'random_state': seed}
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train.iloc[tridx][features].values,
baseline_train.iloc[tridx]["target"].values)Le modèle a été réglé et formé. Regardons maintenant les résultats.
Le code
# make predict proba and predict target
probability_level = 0.99
X = baseline_train
tridx = tridx
cvidx = cvidx
model = model
X_tr, X_cv = contingency_table(X,features,probability_level,tridx,cvidx,model)
train_matrix_confusion = matrix_confusion(X_tr)
cv_matrix_confusion = matrix_confusion(X_cv)
report_score(train_matrix_confusion,
cv_matrix_confusion,
baseline_train,
tridx,cvidx,
X_tr,X_cv)
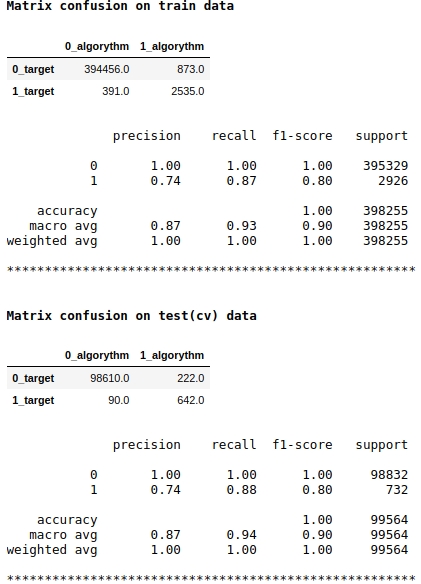
Notez que nous utilisons la métrique de qualité f1 comme score du modèle. Cela signifie qu'il est logique d'ajuster le niveau de probabilité de classer un objet en classe 1 ou 0. Nous avons choisi le niveau de 0,99, c'est-à-dire que si la probabilité est égale ou supérieure à 0,99, l'objet sera classé en classe 1, en dessous de 0,99 - en classe 0. C'est un point important - vous pouvez améliorer considérablement la vitesse une astuce si simple, pas délicate.
La qualité semble être pas mal. Sur un échantillon de test conditionnel, l'algorithme a commis des erreurs lors de la définition de 222 objets de classe 0 et sur 90 objets appartenant à la classe 0, il a commis une erreur et les a affectés à la classe 1 (voir Confusion de matrice sur les données de test (cv)).
Voyons quels signes étaient les plus importants et lesquels ne l'étaient pas.
Le code
start = 0
stop = 50
size = (12,6)
tg = table_gain_coef(model,features,start,stop)
gain_hist(tg,size,start,stop)
display(tg)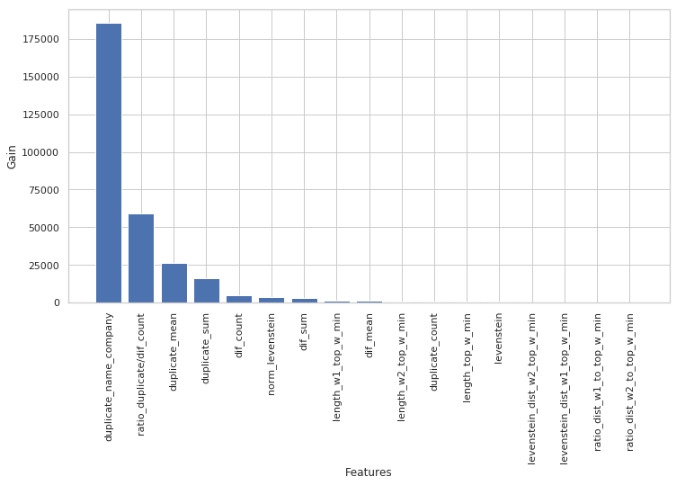
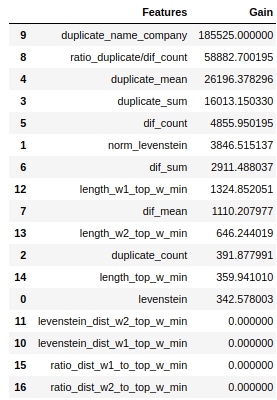
Notez que nous avons utilisé le paramètre «gain» et non le paramètre «split» pour évaluer la signification des caractéristiques. Ceci est important car, dans une version très simplifiée, le premier paramètre signifie la contribution de la fonction à la diminution de l'entropie, et le second indique combien de fois la fonction a été utilisée pour marquer l'espace.
À première vue, la fonctionnalité que nous faisons depuis très longtemps, "levenstein_dist_w1_top_w_min", s'est avérée peu informative - sa contribution est de 0. Mais ce n'est qu'à première vue. Il est presque complètement dupliqué dans la signification avec l'attribut "duplicate_name_company". Si vous supprimez "duplicate_name_company" et laissez "levenstein_dist_w1_top_w_min", alors le second attribut remplacera le premier et la qualité ne changera pas. Vérifié!
En général, un tel signe est pratique, en particulier lorsque vous avez des centaines de fonctionnalités et un modèle avec un tas de cloches et de sifflets et 5000 itérations. Vous pouvez supprimer des fonctionnalités par lots et voir la qualité augmenter grâce à cette action non rusée. Dans notre cas, la suppression des fonctionnalités n'affectera pas la qualité.
Jetons un coup d'œil à la table des compagnons. Tout d'abord, regardons les objets "Faux positifs", c'est-à-dire ceux que notre algorithme a déterminé comme étant les mêmes et les a assignés à la classe 1, mais en fait ils appartiennent à la classe 0.
Le code
X_cv[X_cv['False_Positive']==1][0:50].drop(['name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated', 'duplicate', 'difference',
'levenstein',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min',
'True_Positive','True_Negative','False_Negative'],axis=1)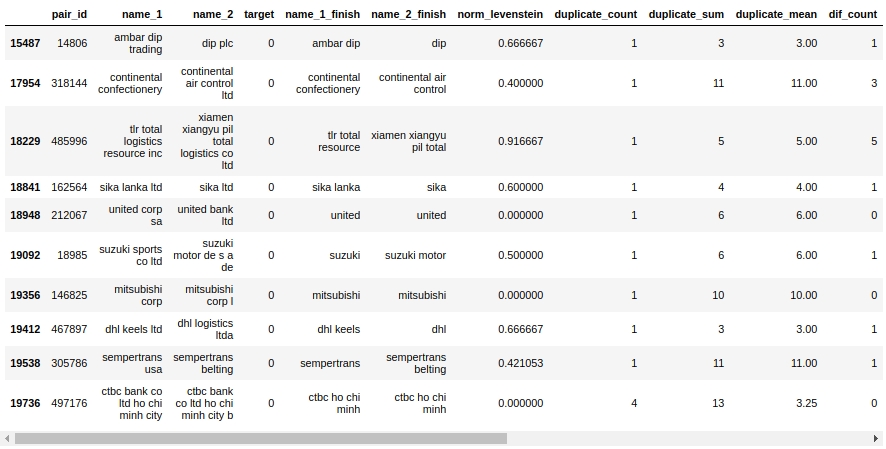
Ouais. Ici, une personne ne déterminera pas immédiatement 0 ou 1. Par exemple, paire # 146825 «mitsubishi corp» et «mitsubishi corp l». Les yeux disent que c'est la même chose, mais l'échantillon dit que ce sont des entreprises différentes. Qui croire?
Disons simplement qu'il était possible de sortir tout de suite - nous avons évincé. Nous laisserons le reste du travail à des camarades expérimentés :)
Téléchargeons les données sur le site Web de l'organisateur et découvrons l'évaluation de la qualité du travail.
Résultats du concours
Le code
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train[features].values,
baseline_train["target"].values)
sample_sub = pd.read_csv('sample_submission.csv', index_col="pair_id")
sample_sub['is_duplicate'] = (model.predict_proba(
baseline_test[features].values)[:, 1] > probability_level).astype(np.int)
sample_sub.to_csv('baseline_submission.csv')
Donc, notre vitesse, en tenant compte de la méthode interdite: 0,5999
Sans elle, la qualité se situait entre 0,3 et 0,4. Nous devons redémarrer le modèle pour plus de précision, mais je suis un peu trop paresseux :)
Résumons mieux l'expérience.
Premièrement, comme vous pouvez le voir, nous avons un code assez reproductible et une structure de fichiers assez adéquate. En raison de ma petite expérience, à un moment donné, j'ai eu beaucoup de bosses précisément parce que je remplissais le travail à la hâte, juste pour obtenir une vitesse plus ou moins agréable. En conséquence, le fichier s'est avéré être tel qu'après une semaine, il était déjà effrayant de l'ouvrir - rien n'est si clair. Par conséquent, mon message est le suivant: écrivez le code tout de suite et rendez le fichier lisible, de sorte que dans un an, vous puissiez revenir aux données, examiner d'abord la structure, comprendre quelles mesures ont été prises, puis pour que chaque étape puisse être facilement démontée. Bien sûr, si vous êtes débutant, au premier essai, le fichier ne sera pas beau, le code se cassera, il y aura des béquilles, mais si vous réécrivez périodiquement le code pendant le processus de recherche,puis après 5-7 fois de réécriture, vous serez vous-même surpris de voir à quel point le code est plus propre et peut-être même trouver des erreurs et améliorer la vitesse. N'oubliez pas les fonctions, cela rend le fichier très facile à lire.
Deuxièmement, après chaque traitement des données, vérifiez si tout s'est déroulé comme prévu. Pour ce faire, vous devez être capable de filtrer les tables dans les pandas. Il y a beaucoup de filtrage dans ce travail, utilisez-le pour la santé :)
Troisièmement, toujours, carrément toujours, dans les tâches de classification, forment à la fois un tableau et une matrice de conjugaison. À partir du tableau, vous pouvez facilement trouver sur quels objets l'algorithme est erroné. Pour commencer, essayez de remarquer ces erreurs qui sont appelées erreurs système, elles nécessitent moins de travail à corriger et donnent plus de résultats. Ensuite, dès que vous triez les erreurs système, passez aux cas particuliers. Par la matrice des erreurs, vous verrez où l'algorithme fait le plus d'erreurs: sur la classe 0 ou 1. De là, vous creuserez des erreurs. Par exemple, j'ai remarqué que mon arbre définit bien les classes 1, mais fait beaucoup d'erreurs sur la classe 0, c'est-à-dire que l'arbre "dit" souvent que cet objet est de classe 1, alors qu'en fait il est 0. J'ai supposé qu'il pourrait être associé au niveau de probabilité de classer un objet comme 0 ou 1. Mon niveau a été fixé à 0,9.L'augmentation du niveau de probabilité d'attribuer un objet à la classe 1 à 0,99 a rendu la sélection d'objets de classe 1 plus difficile et le tour est joué - notre vitesse a donné une augmentation significative.
Encore une fois, je note que le but de la participation au concours n'était pas de gagner une place, mais d'acquérir de l'expérience. Étant donné qu'avant le début du concours, je n'avais aucune idée de comment travailler avec des textes en apprentissage automatique, et au final, en quelques jours, j'ai eu un modèle simple mais toujours fonctionnel, alors nous pouvons dire que l'objectif a été atteint. De plus, pour tout samouraï novice dans le monde de la science des données, je pense qu'il est important d'acquérir de l'expérience, pas un prix, ou plutôt, l'expérience est le prix. N'ayez donc pas peur de participer à des compétitions, foncez, tout le monde est un castor!
Au moment de la publication de l'article, le concours n'est pas encore terminé. Sur la base des résultats de l'achèvement du concours, dans les commentaires de l'article, j'écrirai sur la vitesse maximale de la course, sur les approches et les fonctionnalités qui améliorent la qualité du modèle.
Et vous êtes un cher lecteur, si vous avez des idées sur la façon d'augmenter la vitesse en ce moment, écrivez dans les commentaires. Faites une bonne action :)
Sources d'informations, matériels auxiliaires
- "Github avec données et bloc-notes Jupyter"
- «Plateforme de compétition SIBUR CHALLENGE 2020»
- "Site de l'organisateur du concours SIBUR CHALLENGE 2020"
- "Bon article sur Habré" Principes de base du traitement du langage naturel pour le texte ""
- "Un autre bon article sur Habré" Comparaison de cordes floue: comprenez-moi si vous pouvez ""
- "Publication du magazine APNI"
- "Un article sur le coefficient de Tanimoto" La similarité des chaînes "n'est pas utilisée ici"