
Cet article peut être vu comme une refonte du matériel de restauration grâce à un apprentissage en profondeur pour mes amis ou débutants. J'ai écrit plus de 10 articles sur les approches de la restauration d'image utilisant l'apprentissage en profondeur. Le moment est venu pour un aperçu rapide de ce que les lecteurs de ces articles ont appris, ainsi que pour la rédaction d'une introduction rapide pour les débutants qui veulent s'amuser avec nous.
Terminologie

Figure: 1. Un exemple d'image d'entrée endommagée (à gauche) et de résultat de restauration (à droite). Image tirée de la page Github de l'auteur L'
entrée corrompue illustrée à la figure 1 identifie généralement: a) les pixels ou trous non valides et manquants comme des pixels situés dans des zones à remplir; b) pixels réels corrects, restants que nous pouvons utiliser pour combler les pixels manquants Notez que nous pouvons prendre les pixels corrects et remplir les espaces associés correspondants.
introduction
Le moyen le plus simple de remplir les parties manquantes consiste à copier et coller. L'idée clé est d'abord de rechercher les morceaux les plus similaires d'une image à partir de ses pixels restants, ou de les trouver dans un grand ensemble de données avec des millions d'images, puis d'insérer directement les morceaux dans les morceaux manquants. Cependant, l'algorithme de recherche peut prendre du temps et comprend des métriques de mesure de distance générées manuellement. La généralisation de l'algorithme et son efficacité doivent encore être améliorées.
Avec les approches d'apprentissage en profondeur à l'ère du Big Data, nous avons des approches basées sur les données pour les restaurations d'apprentissage en profondeur, avec ces approches, nous générons des pixels perdus avec une bonne cohérence et des textures fines. Jetons un coup d'œil à 10 approches d'apprentissage en profondeur bien connues de la restauration d'image. Je suis sûr que vous pouvez comprendre les autres articles lorsque vous comprenez ces 10. Commençons.
Encodeur de contexte (premier algorithme de restauration basé sur le GAN, 2016)

Figure: 2. Architecture de réseau du codeur contextuel (CE).
L'encodeur de contexte (CE, 2016) [1] est la première implémentation d'une restauration basée sur le GAN. Ce travail couvre les concepts de base utiles des tâches de restauration. Le concept de «contexte» est associé à la compréhension de l'image en tant que telle, l'essence de l'idée de codeur est entièrement connectée couches par canaux (la couche intermédiaire du réseau est représentée sur la figure 2). Semblable à une couche standard entièrement connectée, le point principal est que tous les emplacements d'éléments sur la couche précédente contribueront à chaque emplacement d'élément sur la couche actuelle. Ainsi, le réseau apprend la relation entre tous les arrangements des éléments et obtient une représentation sémantique plus profonde de l'image entière. CE est considéré comme une référence, vous pouvez en savoir plus à ce sujet dans mon article [ ici ].
MSNPS ( )

. 3. ( CE) (VGG-19).
(MSNPS, 2016) [3] peut être considéré comme une version étendue de CE [1]. Les auteurs de cet article ont utilisé un CE modifié pour prédire les parties manquantes dans une image et un réseau de texture pour décorer la prédiction afin d'améliorer la qualité des parties manquantes du modèle rempli. L'idée du réseau de texture est tirée de la tâche de transfert du style. Nous voulions styliser les pixels existants les plus similaires aux pixels générés pour améliorer le détail de la texture locale. Je dirais que ce travail est une première version d'une structure de réseau grossier à fin en deux étapes. Le premier réseau de contenu (c'est-à-dire ici CE) est responsable de la reconstruction / prédiction des parties manquantes, et le second réseau (c'est-à-dire le réseau de texture) est responsable de l'affinage des parties remplies.
En plus de la perte de reconstruction de pixel typique (c'est-à-dire la perte L1) et de la perte antagoniste standard, le concept de perte de texture proposé dans cet article joue un rôle important dans les travaux ultérieurs sur la restauration d'image. En fait, la perte de texture est associée à une perte de perception et à une perte de style, qui sont largement utilisées dans de nombreuses tâches de génération d'images telles que le transfert de style neuronal. Pour en savoir plus sur cet article, vous pouvez vous référer à mon précédent post [ ici ].
GLCIC (jalon dans la restauration du Deep Learning, 2017)
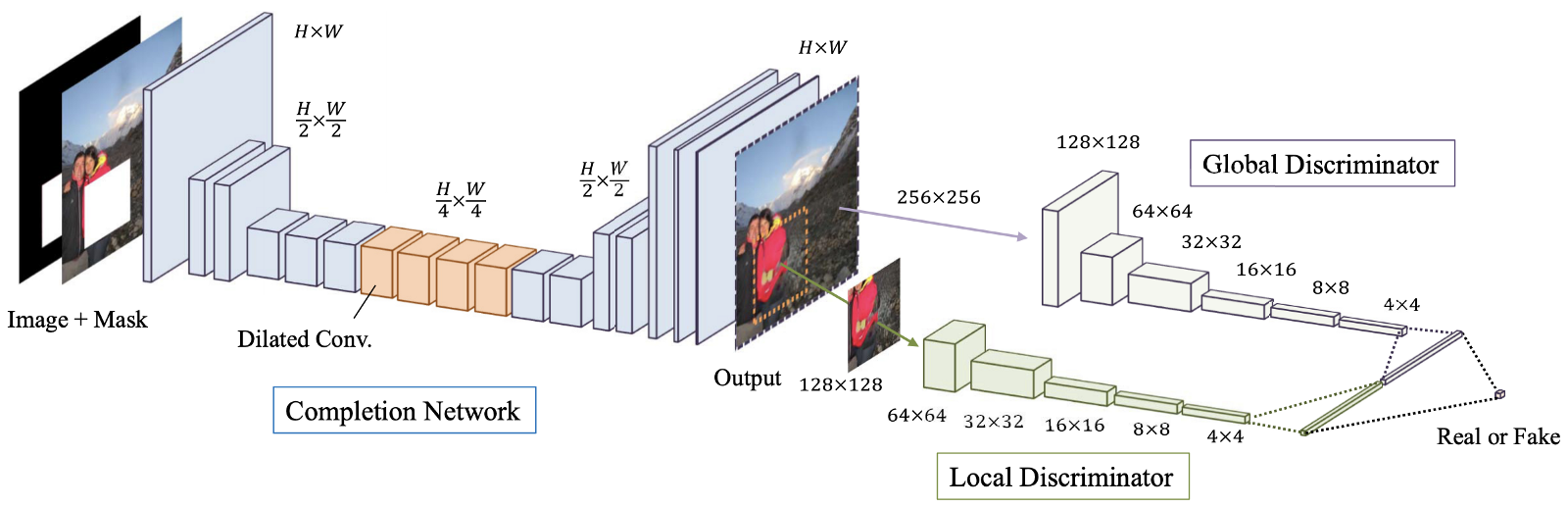
Figure: 4. Un aperçu du modèle proposé, qui consiste en un réseau de terminaux (réseau «Générateur»), ainsi que des discriminateurs globaux et locaux. L'
achèvement d'image globalement et localement cohérent (GLCIC, 2017) [4] est une étape importante dans la restauration d'image d'apprentissage en profondeur car il définit un réseau convolutif étendu entièrement convolutif pour cette zone et est en fait une architecture de réseau typique dans la restauration d'image. En utilisant des convolutions avancées, le réseau est capable de comprendre le contexte d'une image sans utiliser de couches coûteuses entièrement connectées, et peut donc gérer des images de différentes tailles.
En plus du réseau entièrement convolutif à convolutions étendues, deux discriminateurs à deux échelles ont également été formés avec le réseau de générateurs. Le discriminateur global regarde l'image entière, tandis que le discriminateur local regarde la zone centrale remplie. Avec des discriminateurs à la fois globaux et locaux, l'image remplie a une meilleure cohérence globale et locale. Notez que la plupart des articles les plus récents sur la restauration d'image suivent cette conception de discriminateur multi-échelles. Si vous êtes intéressé, veuillez lire mon précédent post [ ici ] pour plus d'informations.
Restauration basée sur un patch GAN (variante GLCIC, 2018)

Figure: 5. Architecture proposée du discriminateur génératif ResNet et PGGAN.
La restauration basée sur des patchs utilisant des GAN [5] peut être considérée comme une variante de GLCIC [4]. En termes simples, deux concepts avancés, l'apprentissage résiduel [6] et PatchGAN [7], sont intégrés au GLCIC pour améliorer encore les performances. Les auteurs de cet article ont combiné jointure résiduelle et convolution étendue pour former un bloc résiduel étendu. Le discriminateur GAN traditionnel a été remplacé par le discriminateur PatchGAN pour promouvoir un meilleur détail de texture locale et une cohérence globale.
La principale différence entre le discriminateur GAN traditionnel et le discriminateur PatchGAN est que le discriminateur GAN traditionnel ne donne qu'une seule étiquette prédictive (0 à 1) pour indiquer le réalisme du signal d'entrée, tandis que le discriminateur PatchGAN donne une matrice d'étiquettes (également 0 à 1) ) pour indiquer le réalisme de chaque zone locale du signal d'entrée. Notez que chaque élément de matrice représente une zone locale de l'entrée. Vous pouvez également consulter un aperçu de l'apprentissage résiduel et de PatchGAN [en visitant mon article ].
Shift-Net (Deep Learning Copy and Paste, 2018)

Figure: 6. Architecture réseau Shift-Net. La couche de jointure par glissement est ajoutée à une résolution de 32x32.
Shift-Net [8] tire parti à la fois des CNN modernes basés sur les données et de la méthode traditionnelle "copier-coller" de repartitionnement profond des éléments en utilisant la couche de jointure par décalage proposée. Cet article a deux idées principales.
Premièrement, les auteurs ont proposé une perte de repère qui amène les éléments décodés des parties manquantes (compte tenu de la partie cachée de l'image) à se rapprocher des éléments codés des parties manquantes (compte tenu du bon état de l'image). En conséquence, le processus de décodage peut remplir les parties manquantes avec leur estimation raisonnable dans l'image en bon état (c'est-à-dire la source de vérité pour les parties manquantes).
Deuxièmement, la couche de jointure-décalage proposée permet au réseau d'emprunter efficacement les informations fournies par ses voisins les plus proches en dehors des parties manquantes pour affiner à la fois la structure sémantique globale et les détails de texture locale des parties générées. En termes simples, nous fournissons des liens pertinents pour affiner notre évaluation. Je pense que les lecteurs intéressés par la restauration d'images trouveront utile de consolider les idées suggérées dans cet article. Je vous recommande fortement de lire le post précédent [ ici ] pour plus de détails.
DeepFill v1 (Restauration d'image révolutionnaire, 2018)

Figure: 7. Architecture de réseau du cadre proposé.
La restauration générative avec une attention contextuelle (CA, 2018), également appelée DeepFill v1 ou CA [9], peut être considérée comme une version étendue ou une variante de Shift-Net [8]. Les auteurs développent l'idée du copier-coller et offrent une couche d'attention contextuelle qui est différentiable et entièrement convolutive.
Semblable à la couche join-shift dans [8], en faisant correspondre les éléments générés à l'intérieur des pixels manquants et les caractéristiques en dehors des pixels manquants, nous pouvons découvrir la contribution de tous les éléments en dehors des pixels manquants à chaque emplacement dans les pixels manquants. Par conséquent, la combinaison de tous les éléments extérieurs peut être utilisée pour affiner les éléments générés à l'intérieur des pixels manquants. Par rapport à la couche jointure-cisaillement, qui ne recherche que les fonctionnalités les plus similaires (c'est-à-dire une affectation dure et non différentiable), la couche CA de cet article utilise une affectation souple et différentiable, dans laquelle toutes les fonctionnalités ont leurs propres pondérations pour indiquer leur contribution à chaque endroit à l'intérieur des pixels manquants. Pour en savoir plus sur l'attention contextuelle, veuillez lire mon article précédent [ ici], vous y trouverez des exemples plus spécifiques.
GMCNN (CNN multi-colonnes pour la restauration d'image, 2018)

Figure: 8. L'architecture du réseau proposé.
Les réseaux neuronaux génératifs à convolution multicolonne (GMCNN, 2018) [10] étendent l'importance de champs réceptifs suffisants pour la restauration d'image et offrent de nouvelles fonctions de perte pour améliorer davantage les détails de texture locale du contenu généré. Comme le montre la figure 9, il y a trois branches / colonnes et chaque branche utilise trois tailles de filtre différentes. L'utilisation de plusieurs champs récepteurs (tailles de filtre) est due au fait que la taille du champ récepteur est importante pour la tâche de restauration d'image. Puisqu'il n'y a pas de pixels voisins locaux, il est nécessaire d'emprunter des informations à des emplacements spatialement distants pour remplir les pixels manquants locaux.
Pour les fonctions de perte proposées, l'idée principale derrière la perte de champ aléatoire de Markov diversifié implicite (ID-MRF) est de diriger les correctifs d'éléments générés pour trouver leurs voisins les plus proches en dehors des zones ignorées comme références, et ces voisins les plus proches devraient être suffisamment diversifié pour modéliser des détails de texture plus locaux. En fait, cette perte est une version améliorée de la perte de texture utilisée dans MSNPS [3]. Je vous recommande fortement de lire mon message [ ici ] pour une explication détaillée de cette perte.
PartialConv (élargit les contraintes de restauration grâce à l'apprentissage en profondeur pour les vides irréguliers, 2018)

. 9. , .
(PartialConv ou PConv) [11] repousse les limites de l'apprentissage en profondeur dans la restauration d'image en offrant un moyen de gérer les images latentes avec de multiples trous irréguliers. De toute évidence, l'idée principale de cet article est le pliage partiel. Lors de l'utilisation de PConv, les résultats de la convolution dépendront uniquement des pixels autorisés, nous contrôlons donc les informations transmises au sein du réseau. Il s'agit du premier travail de restauration d'image à traiter les vides irréguliers. Veuillez noter que les modèles de restauration précédents ont été formés sur des images endommagées correctes, de sorte que ces modèles ne sont pas adaptés aux images de restauration avec des vides incorrects.
J'ai fourni un exemple simple pour expliquer clairement comment le pliage partiel est effectué dans mon article précédent [ ici]. Visitez le lien pour plus de détails. J'espère que vous apprécierez.
EdgeConnect - Les contours d'abord, les couleurs ensuite, 2019

Figure: 10. Architecture réseau EdgeConnect. Comme vous pouvez le voir, il y a deux générateurs et deux discriminateurs.
EdgeConnect[12]: Restauration d'image générative à l'aide de l'apprentissage Adversarial Edge (EdgeConnect) [12] présente une manière intéressante de résoudre le problème de la restauration d'image. L'idée principale de cet article est de diviser la tâche de restauration en deux étapes simplifiées, à savoir prédire les bords et compléter l'image en fonction de la carte des bords prédite. Les bords dans les zones manquantes sont prédits en premier, puis l'image se termine en fonction de la prédiction de bord. La plupart des méthodes utilisées dans cet article ont été couvertes dans mes articles précédents. Un bon aperçu de la façon dont diverses techniques peuvent être utilisées ensemble pour façonner une nouvelle approche de la restauration d'images par apprentissage en profondeur. Peut-être développerez-vous votre propre modèle de restauration. S'il vous plaît voir mon post précédent [ici ] pour en savoir plus sur cet article.
DeepFill v2 (Une approche pratique de la restauration d'image générative, 2019)

Figure: 11. Vue d'ensemble de l'architecture réseau du modèle pour une restauration gratuite.
Restauration de forme libre avec convolution fermée(DeepFill v2 ou GConv, 2019) [13]. C'est peut-être l'algorithme de restauration d'image le plus pratique qui puisse être utilisé directement dans vos applications. Il peut être considéré comme une version améliorée de DeepFill v1 [9], de la convolution partielle [11] et d'EdgeConnect [12]. L'idée principale du travail est Gated Convolution, une version entraînable de la convolution partielle. En ajoutant une couche convolutionnelle standard supplémentaire suivie d'une fonction sigmoïde, il est possible de connaître la validité de chaque emplacement de pixel / objet, et par conséquent une entrée d'esquisse personnalisée supplémentaire est également autorisée. En plus de la Convolution Gated, SN-PatchGAN est utilisé pour stabiliser davantage l'apprentissage du modèle GAN. Pour en savoir plus sur la différence entre la convolution partielle et la convolution fermée, et commentcomment une entrée supplémentaire de croquis utilisateur peut affecter les résultats de la restauration, veuillez consulter mon dernier message [ici ].
Conclusion
J'espère que vous avez maintenant une compréhension de base de la restauration d'image. Je pense que la plupart des techniques courantes utilisées dans la restauration d'images par apprentissage en profondeur ont été couvertes dans mes articles précédents. Si vous êtes un vieil ami à moi, je pense que vous êtes maintenant en mesure de comprendre d'autres travaux de restauration en utilisant le deep learning. Si vous êtes débutant, je vous souhaite la bienvenue. J'espère que vous trouverez cet article utile. En fait, cet article vous donne l'opportunité de nous rejoindre et d'apprendre ensemble.
À mon avis, il est encore difficile de restaurer des images avec des structures de scène complexes et un grand nombre de pixels manquants (par exemple, lorsque 50% des pixels manquent). Bien entendu, un autre défi est la restauration d'images haute résolution. Toutes ces tâches peuvent être qualifiées d'extrêmes. Je pense qu'une approche basée sur les dernières avancées en matière de restauration peut résoudre certains de ces problèmes.
Liens vers les articles
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “Context Encoders: Feature Learning by Inpainting,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.

- Cours avancé "Machine Learning Pro + Deep Learning"
- Cours d'apprentissage automatique
- Formation aux métiers de la Data Science
- Formation d'analyste de données
- Cours Python pour le développement Web
Plus de cours
Articles recommandés
- Combien gagne un data scientist: un aperçu des salaires et des emplois en 2020
- Combien gagne un analyste de données: un aperçu des salaires et des emplois en 2020
- Comment devenir Data Scientist sans cours en ligne
- 450 cours gratuits de l'Ivy League
- Machine Learning 5 9
- Machine Learning Computer Vision
- Machine Learning Computer Vision