
TL; DR
Dans cet article, nous allons commencer à résoudre le problème de la création de liens imprimés dans des livres ou des magazines cliquables à l'aide d'un appareil photo de smartphone.
À l'aide de l' API de détection d'objets TensorFlow 2, nous apprendrons au modèle TensorFlow à trouver les positions et les dimensions des lignes https://
dans les images (par exemple, dans chaque image vidéo d'une caméra de smartphone).
, https://
, Tesseract. Tesseract , links-detector repository GitHub.
Links Detector , .
links-detector GitHub .
:
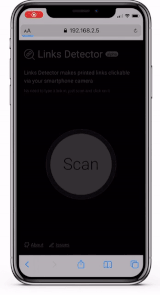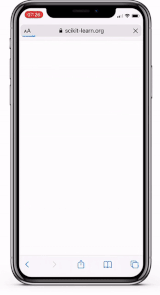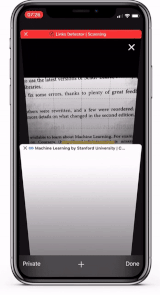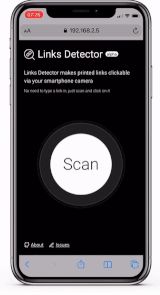
. , , , . , TensorFlow 2 Object Detection API, production-ready .
, GitHub
, Machine Learning . .
, , https://tensorflow.org/
https://some-url.com/which/may/be/even/longer?and_with_params=true
.

, (, !). , . .
, , QR , "" (1) (2) - ? . O(N)
O(1)
.
:
, . . TensorFlow 2 Object Detection API, production-ready .
, :
- (,
0.5-1
iPhone X). , +2
. - .
- (-) (-) .
-
https://
(,http://
,ftp://
,tcp://
).
№1:
:
- - ( ) .
- .
- .
- .

:
- ✓ . ( ) ( GPUs).
- ✓ (, , ), .
~10Mb
, -~100Mb
UX (user experience). - ✓ . "" API, .
:
- ✗ .
JavaScript
, ,Python
. . - ✗ .
- ✗ HTTP . ,
1
10+
.10+
.10
, ,100+
.HTTP/2
gRPC
, , . - ✗ . .
№2:
:
- - ( ) .
- ( ).
- .
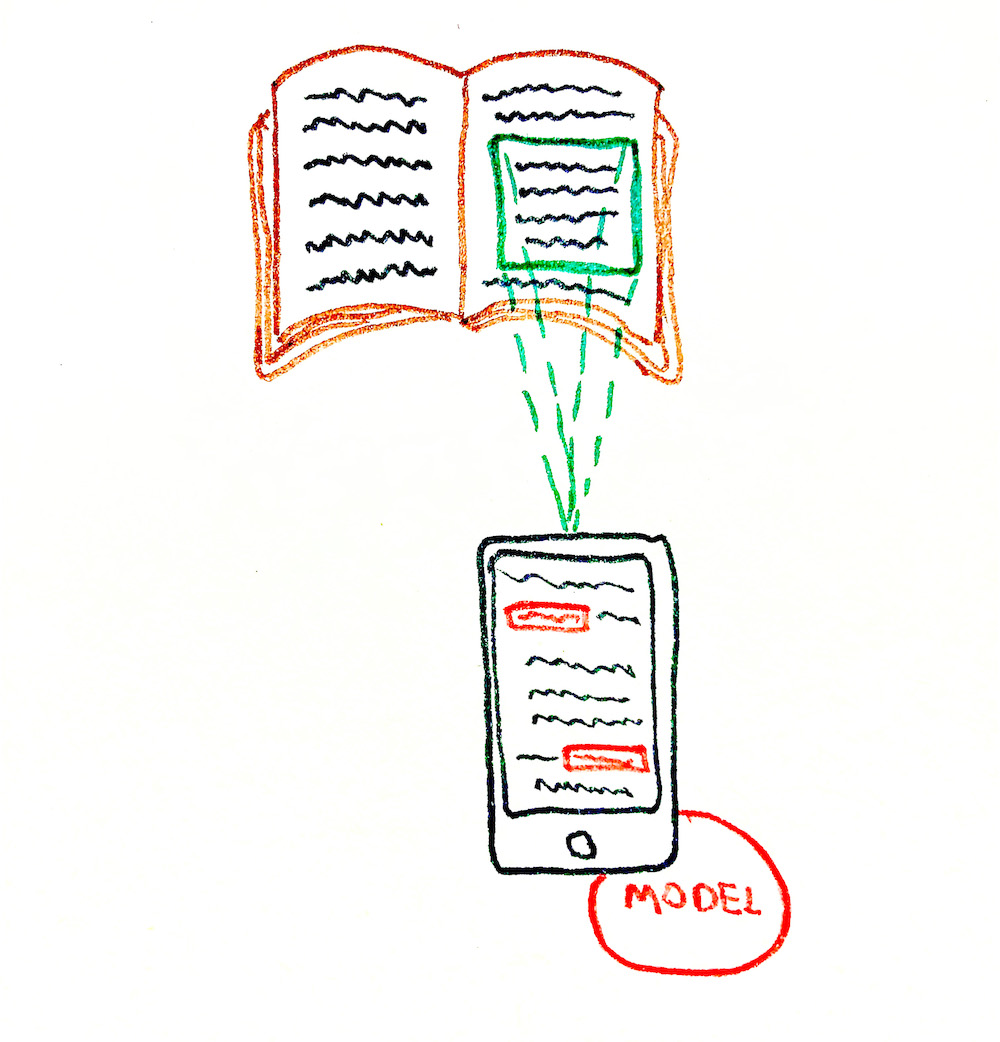
:
- ✓ . API.
- ✓ . (. Progressive Web Application)
- ✓ "" . "" . ( ).
- ✓ . (
HTML
,JS
,CSS
, .). GitHub, . - ✓ ( ) HTTP .
:
- ✗ , . . .
- ✗ . .
- ✗ . . , iPhone .
, . , .
, . , () - , :

:
- ( )
- ( )
№1: Tesseract
(OCR) , , Tesseract.js. , , .

const URL_REG_EXP = /https?:\/\/(www\.)?[-a-zA-Z0-9@:%._+~#=]{2,256}\.[a-z]{2,4}\b([-a-zA-Z0-9@:%_+.~#?&/=]*)/gi; const extractLinkFromText = (text: string): string | null => { const urls: string[] | null = text.match(URL_REG_EXP); if (!urls || !urls.length) { return null; } return urls[0]; };
✓ , :
- .
- .
✗ , + 2
20+
, " " . 0.5-1
.
✗ , , , - , , , ~10% . .
№2: Tesseract TensorFlow (+1 )
Tesseract "-" , . "-" ( ) ( ) . , :
- Tesseract.
- , "" Tesseract , . "" .
"-", Tesseract , . 1
(, iPhone X). ( "" ).
, ( ) ,https://
(https://
, ?). ,https://
, Tesseract ,https://
.
:

, Tesseract , , ( , ).
, , , "" https://
.
- TensorFlow
:
- ✗ / ( - GPU).
- ✗ , . -, ,
https://
. , .
, , (. transfer learning). " " https://
. :
- ✓ . ( ). . , COCO ( "" , , , "").
- ✓ ( GPU / /). ( ) .
"" TensorFlow 2, COCO 2017. ~40
.
, "" , , TensorFlow 2 Object Detection API. TensorFlow Object Detection API — TensorFlow, .
"" , .
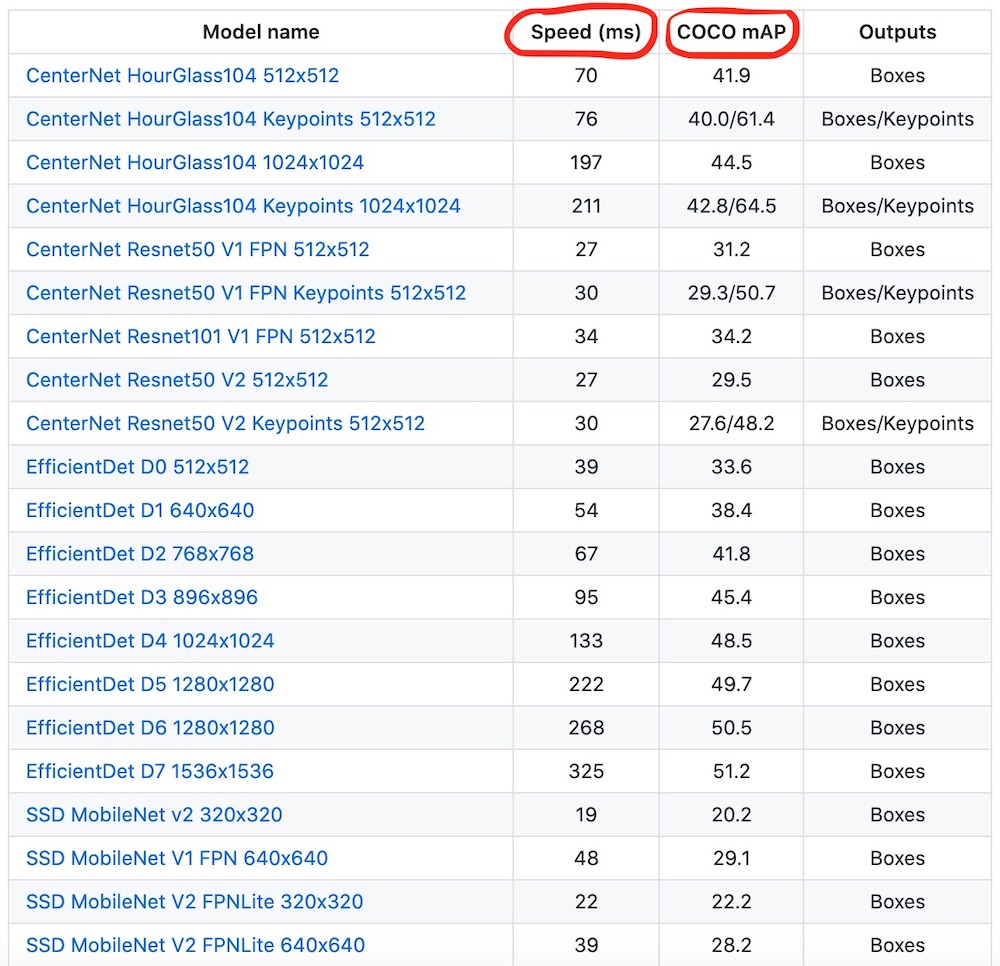
, , , . , , .
~20Mb
~1Gb
. :
1386 (Mb)
centernet_hg104_1024x1024_kpts_coco17_tpu-32
330 (Mb)
centernet_resnet101_v1_fpn_512x512_coco17_tpu-8
195 (Mb)
centernet_resnet50_v1_fpn_512x512_coco17_tpu-8
198 (Mb)
centernet_resnet50_v1_fpn_512x512_kpts_coco17_tpu-8
227 (Mb)
centernet_resnet50_v2_512x512_coco17_tpu-8
230 (Mb)
centernet_resnet50_v2_512x512_kpts_coco17_tpu-8
29 (Mb)
efficientdet_d0_coco17_tpu-32
49 (Mb)
efficientdet_d1_coco17_tpu-32
60 (Mb)
efficientdet_d2_coco17_tpu-32
89 (Mb)
efficientdet_d3_coco17_tpu-32
151 (Mb)
efficientdet_d4_coco17_tpu-32
244 (Mb)
efficientdet_d5_coco17_tpu-32
376 (Mb)
efficientdet_d6_coco17_tpu-32
376 (Mb)
efficientdet_d7_coco17_tpu-32
665 (Mb)
extremenet
427 (Mb)
faster_rcnn_inception_resnet_v2_1024x1024_coco17_tpu-8
424 (Mb)
faster_rcnn_inception_resnet_v2_640x640_coco17_tpu-8
337 (Mb)
faster_rcnn_resnet101_v1_1024x1024_coco17_tpu-8
337 (Mb)
faster_rcnn_resnet101_v1_640x640_coco17_tpu-8
343 (Mb)
faster_rcnn_resnet101_v1_800x1333_coco17_gpu-8
449 (Mb)
faster_rcnn_resnet152_v1_1024x1024_coco17_tpu-8
449 (Mb)
faster_rcnn_resnet152_v1_640x640_coco17_tpu-8
454 (Mb)
faster_rcnn_resnet152_v1_800x1333_coco17_gpu-8
202 (Mb)
faster_rcnn_resnet50_v1_1024x1024_coco17_tpu-8
202 (Mb)
faster_rcnn_resnet50_v1_640x640_coco17_tpu-8
207 (Mb)
faster_rcnn_resnet50_v1_800x1333_coco17_gpu-8
462 (Mb)
mask_rcnn_inception_resnet_v2_1024x1024_coco17_gpu-8
86 (Mb)
ssd_mobilenet_v1_fpn_640x640_coco17_tpu-8
44 (Mb)
ssd_mobilenet_v2_320x320_coco17_tpu-8
20 (Mb)
ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8
20 (Mb)
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
369 (Mb)
ssd_resnet101_v1_fpn_1024x1024_coco17_tpu-8
369 (Mb)
ssd_resnet101_v1_fpn_640x640_coco17_tpu-8
481 (Mb)
ssd_resnet152_v1_fpn_1024x1024_coco17_tpu-8
480 (Mb)
ssd_resnet152_v1_fpn_640x640_coco17_tpu-8
233 (Mb)
ssd_resnet50_v1_fpn_1024x1024_coco17_tpu-8
233 (Mb)
ssd_resnet50_v1_fpn_640x640_coco17_tpu-8
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
:
- ✓ —
20Mb
. - ✓ —
39ms
. - ✓ MobileNet v2 (feature extractor), .
- ✓ ( regions proposal, ).
- ✗ ( ️)
, :
- —
640x640px
. - Single Shot MultiBox Detector (SSD) Feature Pyramid Network (FPN).
- (CNN) MobileNet v2 (feature extractor).
- COCO
Object Detection API
Tensorflow 2 Object Detection API Python. , Google Colab () Jupyter. .
Object Detection API Docker, .
API ( ), TensorFlow 2 Object Detection API tutorial, .
API:
git clone --depth 1 https://github.com/tensorflow/models
output →
Cloning into 'models'... remote: Enumerating objects: 2301, done. remote: Counting objects: 100% (2301/2301), done. remote: Compressing objects: 100% (2000/2000), done. remote: Total 2301 (delta 561), reused 922 (delta 278), pack-reused 0 Receiving objects: 100% (2301/2301), 30.60 MiB | 13.90 MiB/s, done. Resolving deltas: 100% (561/561), done.
cd ./models/research
protoc object_detection/protos/*.proto --python_out=.
API TensorFlow 2 pip
setup.py`:
cp ./object_detection/packages/tf2/setup.py . pip install . --quiet
, ,pip install . --quiet
.
:
python object_detection/builders/model_builder_tf2_test.py
, - :
[ OK ] ModelBuilderTF2Test.test_unknown_ssd_feature_extractor ---------------------------------------------------------------------- Ran 20 tests in 45.072s OK (skipped=1)
TensorFlow Object Detection API ! , API, , .
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
TensorFlow , , "", "", "" . ( , COCO).
TensorFlow get_file() URL .
import tensorflow as tf
import pathlib
MODEL_NAME = 'ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8'
TF_MODELS_BASE_PATH = 'http://download.tensorflow.org/models/object_detection/tf2/20200711/'
CACHE_FOLDER = './cache'
def download_tf_model(model_name, cache_folder):
model_url = TF_MODELS_BASE_PATH + model_name + '.tar.gz'
model_dir = tf.keras.utils.get_file(
fname=model_name,
origin=model_url,
untar=True,
cache_dir=pathlib.Path(cache_folder).absolute()
)
return model_dir
# Start the model download.
model_dir = download_tf_model(MODEL_NAME, CACHE_FOLDER)
print(model_dir)
output →
/content/cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
:

checkpoint
"" .
pipeline.config
. , .
, COCO ( 90), , car
, bird
, hot dog
. (labels).

: COCO
, .
COCO
Object Detection API () COCO .
import os
# Import Object Detection API helpers.
from object_detection.utils import label_map_util
# Loads the COCO labels data (class names and indices relations).
def load_coco_labels():
# Object Detection API already has a complete set of COCO classes defined for us.
label_map_path = os.path.join(
'models/research/object_detection/data',
'mscoco_complete_label_map.pbtxt'
)
label_map = label_map_util.load_labelmap(label_map_path)
# Class ID to Class Name mapping.
categories = label_map_util.convert_label_map_to_categories(
label_map,
max_num_classes=label_map_util.get_max_label_map_index(label_map),
use_display_name=True
)
category_index = label_map_util.create_category_index(categories)
# Class Name to Class ID mapping.
label_map_dict = label_map_util.get_label_map_dict(label_map, use_display_name=True)
return category_index, label_map_dict
# Load COCO labels.
coco_category_index, coco_label_map_dict = load_coco_labels()
print('coco_category_index:', coco_category_index)
print('coco_label_map_dict:', coco_label_map_dict)
output →
coco_category_index: { 1: {'id': 1, 'name': 'person'}, 2: {'id': 2, 'name': 'bicycle'}, ... 90: {'id': 90, 'name': 'toothbrush'}, } coco_label_map_dict: { 'background': 0, 'person': 1, 'bicycle': 2, 'car': 3, ... 'toothbrush': 90, }
, , , .
import tensorflow as tf
# Import Object Detection API helpers.
from object_detection.utils import config_util
from object_detection.builders import model_builder
# Generates the detection function for specific model and specific model's checkpoint
def detection_fn_from_checkpoint(config_path, checkpoint_path):
# Build the model.
pipeline_config = config_util.get_configs_from_pipeline_file(config_path)
model_config = pipeline_config['model']
model = model_builder.build(
model_config=model_config,
is_training=False,
)
# Restore checkpoints.
ckpt = tf.compat.v2.train.Checkpoint(model=model)
ckpt.restore(checkpoint_path).expect_partial()
# This is a function that will do the detection.
@tf.function
def detect_fn(image):
image, shapes = model.preprocess(image)
prediction_dict = model.predict(image, shapes)
detections = model.postprocess(prediction_dict, shapes)
return detections, prediction_dict, tf.reshape(shapes, [-1])
return detect_fn
inference_detect_fn = detection_fn_from_checkpoint(
config_path=os.path.join('cache', 'datasets', MODEL_NAME, 'pipeline.config'),
checkpoint_path=os.path.join('cache', 'datasets', MODEL_NAME, 'checkpoint', 'ckpt-0'),
)
inference_detect_fn
.
:

inference/test/
. Google Colab, .
:

import matplotlib.pyplot as plt
%matplotlib inline
# Creating a TensorFlow dataset of just one image.
inference_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory='inference',
image_size=(640, 640),
batch_size=1,
shuffle=False,
label_mode=None
)
# Numpy version of the dataset.
inference_ds_numpy = list(inference_ds.as_numpy_iterator())
# You may preview the images in dataset like this.
plt.figure(figsize=(14, 14))
for i, image in enumerate(inference_ds_numpy):
plt.subplot(2, 2, i + 1)
plt.imshow(image[0].astype("uint8"))
plt.axis("off")
plt.show()
. inference_ds_numpy[0]
Numpy
.
detections, predictions_dict, shapes = inference_detect_fn(
inference_ds_numpy[0]
)
, :
boxes = detections['detection_boxes'].numpy()
scores = detections['detection_scores'].numpy()
classes = detections['detection_classes'].numpy()
num_detections = detections['num_detections'].numpy()[0]
print('boxes.shape: ', boxes.shape)
print('scores.shape: ', scores.shape)
print('classes.shape: ', classes.shape)
print('num_detections:', num_detections)
output →
boxes.shape: (1, 100, 4) scores.shape: (1, 100) classes.shape: (1, 100) num_detections: 100.0
100
"". , 100
. , 100
100
. "" (, score), , . boxes
. scores
. classes
"".
5 "":
print('First 5 boxes:')
print(boxes[0,:5])
print('First 5 scores:')
print(scores[0,:5])
print('First 5 classes:')
print(classes[0,:5])
class_names = [coco_category_index[idx + 1]['name'] for idx in classes[0]]
print('First 5 class names:')
print(class_names[:5])
output →
First 5 boxes: [[0.17576033 0.84654826 0.25642633 0.88327974] [0.5187813 0.12410264 0.6344235 0.34545377] [0.5220358 0.5181462 0.6329132 0.7669856 ] [0.50933677 0.7045719 0.5619138 0.7446198 ] [0.44761637 0.51942706 0.61237675 0.75963426]] First 5 scores: [0.6950246 0.6343004 0.591157 0.5827219 0.5415643] First 5 classes: [9. 8. 8. 0. 8.] First 5 class names: ['traffic light', 'boat', 'boat', 'person', 'boat']
(traffic light
), (boats
) (person
). , .
scores
, ( 70% ) traffic light
.
boxes
[y1, x1, y2, x2]
, (x1, y1)
(x2, y2)
.
:
# Importing Object Detection API helpers.
from object_detection.utils import visualization_utils
# Visualizes the bounding boxes on top of the image.
def visualize_detections(image_np, detections, category_index):
label_id_offset = 1
image_np_with_detections = image_np.copy()
visualization_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'][0].numpy(),
(detections['detection_classes'][0].numpy() + label_id_offset).astype(int),
detections['detection_scores'][0].numpy(),
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=200,
min_score_thresh=.4,
agnostic_mode=False,
)
plt.figure(figsize=(12, 16))
plt.imshow(image_np_with_detections)
plt.show()
# Visualizing the detections.
visualize_detections(
image_np=tf.cast(inference_ds_numpy[0][0], dtype=tf.uint32).numpy(),
detections=detections,
category_index=coco_category_index,
)
:

, :

. - , — https://
.
, ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
, COCO "" .
:
- (, )
- , .

( ). . ,
,
. ( ). , : .
, . :
- .
- .
-
https://
( ) .
№1:
. :
✓ , , , , .
✗ , , .
.
№2:
( keras_ocr), , .
✓ , : http://
, http://
, ftp://
, tcp://
. .
✓ , . , . .
✗ , ,
, . , ( ) . "" .
. ( ). , , , .
№3:
— ( ), , https://
.
, , , ( ). , . "" (. transfer learning few-shot learning).
✓ . , , , .
✗ , , , .
✗ , , . ( ).
, , , , .
125
, https://
.

dataset/printed_links/raw
.
— . :
- ,
1024px
(3024px
) - , ( , , ,
https:
). - , exif.
- -, , .
, , , ( - , , -).
Python:
import os
import math
import shutil
from pathlib import Path
from PIL import Image, ImageOps, ImageEnhance
# Resize an image.
def preprocess_resize(target_width):
def preprocess(image: Image.Image, log) -> Image.Image:
(width, height) = image.size
ratio = width / height
if width > target_width:
target_height = math.floor(target_width / ratio)
log(f'Resizing: To size {target_width}x{target_height}')
image = image.resize((target_width, target_height))
else:
log('Resizing: Image already resized, skipping...')
return image
return preprocess
# Crop an image.
def preprocess_crop_square():
def preprocess(image: Image.Image, log) -> Image.Image:
(width, height) = image.size
left = 0
top = 0
right = width
bottom = height
crop_size = min(width, height)
if width >= height:
# Horizontal image.
log(f'Squre cropping: Horizontal {crop_size}x{crop_size}')
left = width // 2 - crop_size // 2
right = left + crop_size
else:
# Vetyical image.
log(f'Squre cropping: Vertical {crop_size}x{crop_size}')
top = height // 2 - crop_size // 2
bottom = top + crop_size
image = image.crop((left, top, right, bottom))
return image
return preprocess
# Apply exif transpose to an image.
def preprocess_exif_transpose():
# @see: https://pillow.readthedocs.io/en/stable/reference/ImageOps.html
def preprocess(image: Image.Image, log) -> Image.Image:
log('EXif transpose')
image = ImageOps.exif_transpose(image)
return image
return preprocess
# Apply color transformations to the image.
def preprocess_color(brightness, contrast, color, sharpness):
# @see: https://pillow.readthedocs.io/en/3.0.x/reference/ImageEnhance.html
def preprocess(image: Image.Image, log) -> Image.Image:
log('Coloring')
enhancer = ImageEnhance.Color(image)
image = enhancer.enhance(color)
enhancer = ImageEnhance.Brightness(image)
image = enhancer.enhance(brightness)
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(contrast)
enhancer = ImageEnhance.Sharpness(image)
image = enhancer.enhance(sharpness)
return image
return preprocess
# Image pre-processing pipeline.
def preprocess_pipeline(src_dir, dest_dir, preprocessors=[], files_num_limit=0, override=False):
# Create destination folder if not exists.
Path(dest_dir).mkdir(parents=False, exist_ok=True)
# Get the list of files to be copied.
src_file_names = os.listdir(src_dir)
files_total = files_num_limit if files_num_limit > 0 else len(src_file_names)
files_processed = 0
# Logger function.
def preprocessor_log(message):
print(' ' + message)
# Iterate through files.
for src_file_index, src_file_name in enumerate(src_file_names):
if files_num_limit > 0 and src_file_index >= files_num_limit:
break
# Copy file.
src_file_path = os.path.join(src_dir, src_file_name)
dest_file_path = os.path.join(dest_dir, src_file_name)
progress = math.floor(100 * (src_file_index + 1) / files_total)
print(f'Image {src_file_index + 1}/{files_total} | {progress}% | {src_file_path}')
if not os.path.isfile(src_file_path):
preprocessor_log('Source is not a file, skipping...\n')
continue
if not override and os.path.exists(dest_file_path):
preprocessor_log('File already exists, skipping...\n')
continue
shutil.copy(src_file_path, dest_file_path)
files_processed += 1
# Preprocess file.
image = Image.open(dest_file_path)
for preprocessor in preprocessors:
image = preprocessor(image, preprocessor_log)
image.save(dest_file_path, quality=95)
print('')
print(f'{files_processed} out of {files_total} files have been processed')
# Launching the image preprocessing pipeline.
preprocess_pipeline(
src_dir='dataset/printed_links/raw',
dest_dir='dataset/printed_links/processed',
override=True,
# files_num_limit=1,
preprocessors=[
preprocess_exif_transpose(),
preprocess_resize(target_width=1024),
preprocess_crop_square(),
preprocess_color(brightness=2, contrast=1.3, color=0, sharpness=1),
]
)
dataset/printed_links/processed
.

:
import matplotlib.pyplot as plt
import numpy as np
def preview_images(images_dir, images_num=1, figsize=(15, 15)):
image_names = os.listdir(images_dir)
image_names = image_names[:images_num]
num_cells = math.ceil(math.sqrt(images_num))
figure = plt.figure(figsize=figsize)
for image_index, image_name in enumerate(image_names):
image_path = os.path.join(images_dir, image_name)
image = Image.open(image_path)
figure.add_subplot(num_cells, num_cells, image_index + 1)
plt.imshow(np.asarray(image))
plt.show()
preview_images('dataset/printed_links/processed', images_num=4, figsize=(16, 16))
, ( https://
) LabelImg.
LabelImg . LabelImg
LabelImg, , ( dataset/printed_links/processed
), :
labelImg dataset/printed_links/processed
dataset/printed_links/processed
XML dataset/printed_links/labels/xml/
.


XML :

(test
train
). , , , . tf.data.Dataset.
import re
import random
def partition_dataset(
images_dir,
xml_labels_dir,
train_dir,
test_dir,
val_dir,
train_ratio,
test_ratio,
val_ratio,
copy_xml
):
if not os.path.exists(train_dir):
os.makedirs(train_dir)
if not os.path.exists(test_dir):
os.makedirs(test_dir)
if not os.path.exists(val_dir):
os.makedirs(val_dir)
images = [f for f in os.listdir(images_dir)
if re.search(r'([a-zA-Z0-9\s_\\.\-\(\):])+(.jpg|.jpeg|.png)$', f, re.IGNORECASE)]
num_images = len(images)
num_train_images = math.ceil(train_ratio * num_images)
num_test_images = math.ceil(test_ratio * num_images)
num_val_images = math.ceil(val_ratio * num_images)
print('Intended split')
print(f' train: {num_train_images}/{num_images} images')
print(f' test: {num_test_images}/{num_images} images')
print(f' val: {num_val_images}/{num_images} images')
actual_num_train_images = 0
actual_num_test_images = 0
actual_num_val_images = 0
def copy_random_images(num_images, dest_dir):
copied_num = 0
if not num_images:
return copied_num
for i in range(num_images):
if not len(images):
break
idx = random.randint(0, len(images)-1)
filename = images[idx]
shutil.copyfile(os.path.join(images_dir, filename), os.path.join(dest_dir, filename))
if copy_xml:
xml_filename = os.path.splitext(filename)[0]+'.xml'
shutil.copyfile(os.path.join(xml_labels_dir, xml_filename), os.path.join(dest_dir, xml_filename))
images.remove(images[idx])
copied_num += 1
return copied_num
actual_num_train_images = copy_random_images(num_train_images, train_dir)
actual_num_test_images = copy_random_images(num_test_images, test_dir)
actual_num_val_images = copy_random_images(num_val_images, val_dir)
print('\n', 'Actual split')
print(f' train: {actual_num_train_images}/{num_images} images')
print(f' test: {actual_num_test_images}/{num_images} images')
print(f' val: {actual_num_val_images}/{num_images} images')
partition_dataset(
images_dir='dataset/printed_links/processed',
train_dir='dataset/printed_links/partitioned/train',
test_dir='dataset/printed_links/partitioned/test',
val_dir='dataset/printed_links/partitioned/val',
xml_labels_dir='dataset/printed_links/labels/xml',
train_ratio=0.8,
test_ratio=0.2,
val_ratio=0,
copy_xml=True
)
:
dataset/ └── printed_links ├── labels │ └── xml ├── partitioned │ ├── test │ └── train │ ├── IMG_9140.JPG │ ├── IMG_9140.xml │ ├── IMG_9141.JPG │ ├── IMG_9141.xml │ ... ├── processed └── raw
, , TFRecord. TFRecord
TensorFlow ( ).
: CSV
, TFRecord
.
mkdir -p dataset/printed_links/labels/csv mkdir -p dataset/printed_links/tfrecords
- dataset/printed_links/labels/label_map.pbtxt
, . , http
. :
item { id: 1 name: 'http' }
TFRecord jpg
xml
:
import os
import io
import math
import glob
import tensorflow as tf
import pandas as pd
import xml.etree.ElementTree as ET
from PIL import Image
from collections import namedtuple
from object_detection.utils import dataset_util, label_map_util
tf1 = tf.compat.v1
# Convers labels from XML format to CSV.
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def class_text_to_int(row_label, label_map_dict):
return label_map_dict[row_label]
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
# Creates a TFRecord.
def create_tf_example(group, path, label_map_dict):
with tf1.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class'], label_map_dict))
tf_example = tf1.train.Example(features=tf1.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def dataset_to_tfrecord(
images_dir,
xmls_dir,
label_map_path,
output_path,
csv_path=None
):
label_map = label_map_util.load_labelmap(label_map_path)
label_map_dict = label_map_util.get_label_map_dict(label_map)
tfrecord_writer = tf1.python_io.TFRecordWriter(output_path)
images_path = os.path.join(images_dir)
csv_examples = xml_to_csv(xmls_dir)
grouped_examples = split(csv_examples, 'filename')
for group in grouped_examples:
tf_example = create_tf_example(group, images_path, label_map_dict)
tfrecord_writer.write(tf_example.SerializeToString())
tfrecord_writer.close()
print('Successfully created the TFRecord file: {}'.format(output_path))
if csv_path is not None:
csv_examples.to_csv(csv_path, index=None)
print('Successfully created the CSV file: {}'.format(csv_path))
# Generate a TFRecord for train dataset.
dataset_to_tfrecord(
images_dir='dataset/printed_links/partitioned/train',
xmls_dir='dataset/printed_links/partitioned/train',
label_map_path='dataset/printed_links/labels/label_map.pbtxt',
output_path='dataset/printed_links/tfrecords/train.record',
csv_path='dataset/printed_links/labels/csv/train.csv'
)
# Generate a TFRecord for test dataset.
dataset_to_tfrecord(
images_dir='dataset/printed_links/partitioned/test',
xmls_dir='dataset/printed_links/partitioned/test',
label_map_path='dataset/printed_links/labels/label_map.pbtxt',
output_path='dataset/printed_links/tfrecords/test.record',
csv_path='dataset/printed_links/labels/csv/test.csv'
)
test.record
train.record
dataset/printed_links/tfrecords/
:
dataset/ └── printed_links ├── labels │ ├── csv │ ├── label_map.pbtxt │ └── xml ├── partitioned │ ├── test │ ├── train │ └── val ├── processed ├── raw └── tfrecords ├── test.record └── train.record
test.record
train.record
, ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
.
TFRecord
, TFRecord
TensorFlow 2 Object Detection API.
:
import tensorflow as tf
# Count the number of examples in the dataset.
def count_tfrecords(tfrecords_filename):
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
# Keep in mind that the list() operation might be
# a performance bottleneck for large datasets.
return len(list(raw_dataset))
TRAIN_RECORDS_NUM = count_tfrecords('dataset/printed_links/tfrecords/train.record')
TEST_RECORDS_NUM = count_tfrecords('dataset/printed_links/tfrecords/test.record')
print('TRAIN_RECORDS_NUM: ', TRAIN_RECORDS_NUM)
print('TEST_RECORDS_NUM: ', TEST_RECORDS_NUM)
output →
TRAIN_RECORDS_NUM: 100 TEST_RECORDS_NUM: 25
, 100
25
.
:
import tensorflow as tf
import numpy as np
from google.protobuf import text_format
import matplotlib.pyplot as plt
# Import Object Detection API.
from object_detection.utils import visualization_utils
from object_detection.protos import string_int_label_map_pb2
from object_detection.data_decoders.tf_example_decoder import TfExampleDecoder
%matplotlib inline
# Visualize the TFRecord dataset.
def visualize_tfrecords(tfrecords_filename, label_map=None, print_num=1):
decoder = TfExampleDecoder(
label_map_proto_file=label_map,
use_display_name=False
)
if label_map is not None:
label_map_proto = string_int_label_map_pb2.StringIntLabelMap()
with tf.io.gfile.GFile(label_map,'r') as f:
text_format.Merge(f.read(), label_map_proto)
class_dict = {}
for entry in label_map_proto.item:
class_dict[entry.id] = {'name': entry.name}
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
for raw_record in raw_dataset.take(print_num):
example = decoder.decode(raw_record)
image = example['image'].numpy()
boxes = example['groundtruth_boxes'].numpy()
confidences = example['groundtruth_image_confidences']
filename = example['filename']
area = example['groundtruth_area']
classes = example['groundtruth_classes'].numpy()
image_classes = example['groundtruth_image_classes']
weights = example['groundtruth_weights']
scores = np.ones(boxes.shape[0])
visualization_utils.visualize_boxes_and_labels_on_image_array(
image,
boxes,
classes,
scores,
class_dict,
max_boxes_to_draw=None,
use_normalized_coordinates=True
)
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.show()
# Visualizing the training TFRecord dataset.
visualize_tfrecords(
tfrecords_filename='dataset/printed_links/tfrecords/train.record',
label_map='dataset/printed_links/labels/label_map.pbtxt',
print_num=3
)
,

TensorBoard
, TensorBoard.
TensorBoard . , . TensorBoard .
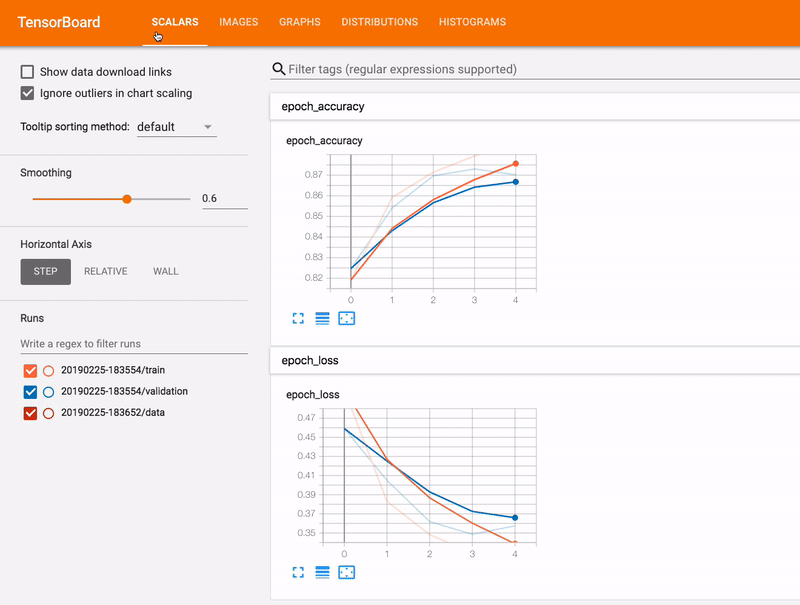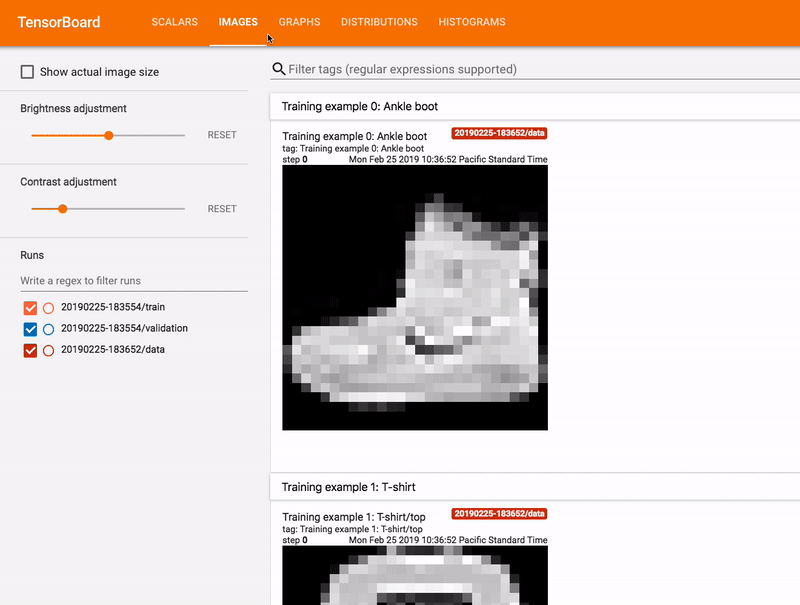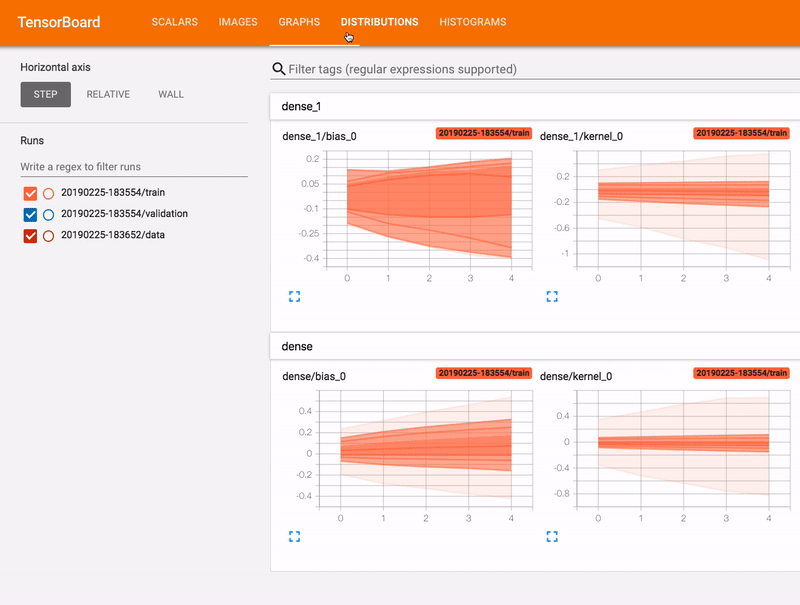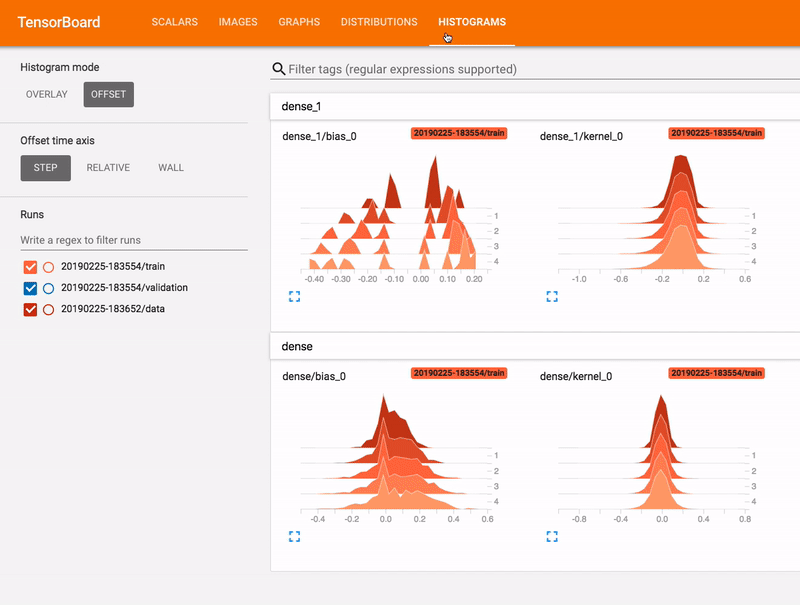
TensorBoard , Google Colab. Jupyter , TensorBoard Python .
./logs
, .
mkdir -p logs
, TensorBoard Google Colab:
%load_ext tensorboard
TensorBoard ./logs
,
%tensorboard --logdir ./logs
TensorBoard:

, , .
️
cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/pipeline.config
. ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
.
pipeline.config
:
-
90
( COCO)1
(http
) - (batch size)
8
, . - , , .
-
fine_tune_checkpoint_type
detection
. - , .
- , .
pipeline.config
, :
import tensorflow as tf
from shutil import copyfile
from google.protobuf import text_format
from object_detection.protos import pipeline_pb2
# Adjust pipeline config modification here if needed.
def modify_config(pipeline):
# Model config.
pipeline.model.ssd.num_classes = 1
# Train config.
pipeline.train_config.batch_size = 8
pipeline.train_config.fine_tune_checkpoint = 'cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0'
pipeline.train_config.fine_tune_checkpoint_type = 'detection'
# Train input reader config.
pipeline.train_input_reader.label_map_path = 'dataset/printed_links/labels/label_map.pbtxt'
pipeline.train_input_reader.tf_record_input_reader.input_path[0] = 'dataset/printed_links/tfrecords/train.record'
# Eval input reader config.
pipeline.eval_input_reader[0].label_map_path = 'dataset/printed_links/labels/label_map.pbtxt'
pipeline.eval_input_reader[0].tf_record_input_reader.input_path[0] = 'dataset/printed_links/tfrecords/test.record'
return pipeline
def clone_pipeline_config():
copyfile(
'cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/pipeline.config',
'pipeline.config'
)
def setup_pipeline(pipeline_config_path):
clone_pipeline_config()
pipeline = read_pipeline_config(pipeline_config_path)
pipeline = modify_config(pipeline)
write_pipeline_config(pipeline_config_path, pipeline)
return pipeline
def read_pipeline_config(pipeline_config_path):
pipeline = pipeline_pb2.TrainEvalPipelineConfig()
with tf.io.gfile.GFile(pipeline_config_path, "r") as f:
proto_str = f.read()
text_format.Merge(proto_str, pipeline)
return pipeline
def write_pipeline_config(pipeline_config_path, pipeline):
config_text = text_format.MessageToString(pipeline)
with tf.io.gfile.GFile(pipeline_config_path, "wb") as f:
f.write(config_text)
# Adjusting the pipeline configuration.
pipeline = setup_pipeline('pipeline.config')
print(pipeline)
pipeline.config
:
model { ssd { num_classes: 1 image_resizer { fixed_shape_resizer { height: 640 width: 640 } } feature_extractor { type: "ssd_mobilenet_v2_fpn_keras" depth_multiplier: 1.0 min_depth: 16 conv_hyperparams { regularizer { l2_regularizer { weight: 3.9999998989515007e-05 } } initializer { random_normal_initializer { mean: 0.0 stddev: 0.009999999776482582 } } activation: RELU_6 batch_norm { decay: 0.996999979019165 scale: true epsilon: 0.0010000000474974513 } } use_depthwise: true override_base_feature_extractor_hyperparams: true fpn { min_level: 3 max_level: 7 additional_layer_depth: 128 } } box_coder { faster_rcnn_box_coder { y_scale: 10.0 x_scale: 10.0 height_scale: 5.0 width_scale: 5.0 } } matcher { argmax_matcher { matched_threshold: 0.5 unmatched_threshold: 0.5 ignore_thresholds: false negatives_lower_than_unmatched: true force_match_for_each_row: true use_matmul_gather: true } } similarity_calculator { iou_similarity { } } box_predictor { weight_shared_convolutional_box_predictor { conv_hyperparams { regularizer { l2_regularizer { weight: 3.9999998989515007e-05 } } initializer { random_normal_initializer { mean: 0.0 stddev: 0.009999999776482582 } } activation: RELU_6 batch_norm { decay: 0.996999979019165 scale: true epsilon: 0.0010000000474974513 } } depth: 128 num_layers_before_predictor: 4 kernel_size: 3 class_prediction_bias_init: -4.599999904632568 share_prediction_tower: true use_depthwise: true } } anchor_generator { multiscale_anchor_generator { min_level: 3 max_level: 7 anchor_scale: 4.0 aspect_ratios: 1.0 aspect_ratios: 2.0 aspect_ratios: 0.5 scales_per_octave: 2 } } post_processing { batch_non_max_suppression { score_threshold: 9.99999993922529e-09 iou_threshold: 0.6000000238418579 max_detections_per_class: 100 max_total_detections: 100 use_static_shapes: false } score_converter: SIGMOID } normalize_loss_by_num_matches: true loss { localization_loss { weighted_smooth_l1 { } } classification_loss { weighted_sigmoid_focal { gamma: 2.0 alpha: 0.25 } } classification_weight: 1.0 localization_weight: 1.0 } encode_background_as_zeros: true normalize_loc_loss_by_codesize: true inplace_batchnorm_update: true freeze_batchnorm: false } } train_config { batch_size: 8 data_augmentation_options { random_horizontal_flip { } } data_augmentation_options { random_crop_image { min_object_covered: 0.0 min_aspect_ratio: 0.75 max_aspect_ratio: 3.0 min_area: 0.75 max_area: 1.0 overlap_thresh: 0.0 } } sync_replicas: true optimizer { momentum_optimizer { learning_rate { cosine_decay_learning_rate { learning_rate_base: 0.07999999821186066 total_steps: 50000 warmup_learning_rate: 0.026666000485420227 warmup_steps: 1000 } } momentum_optimizer_value: 0.8999999761581421 } use_moving_average: false } fine_tune_checkpoint: "cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/checkpoint/ckpt-0" num_steps: 50000 startup_delay_steps: 0.0 replicas_to_aggregate: 8 max_number_of_boxes: 100 unpad_groundtruth_tensors: false fine_tune_checkpoint_type: "detection" fine_tune_checkpoint_version: V2 } train_input_reader { label_map_path: "dataset/printed_links/labels/label_map.pbtxt" tf_record_input_reader { input_path: "dataset/printed_links/tfrecords/train.record" } } eval_config { metrics_set: "coco_detection_metrics" use_moving_averages: false } eval_input_reader { label_map_path: "dataset/printed_links/labels/label_map.pbtxt" shuffle: false num_epochs: 1 tf_record_input_reader { input_path: "dataset/printed_links/tfrecords/test.record" } }
TensorFlow 2 Object Detection API. API model_main_tf2.py, . Python , (, num_train_steps
, model_dir
.).
1000
().
%%bash
NUM_TRAIN_STEPS=1000
CHECKPOINT_EVERY_N=1000
PIPELINE_CONFIG_PATH=pipeline.config
MODEL_DIR=./logs
SAMPLE_1_OF_N_EVAL_EXAMPLES=1
python ./models/research/object_detection/model_main_tf2.py \
--model_dir=$MODEL_DIR \
--num_train_steps=$NUM_TRAIN_STEPS \
--sample_1_of_n_eval_examples=$SAMPLE_1_OF_N_EVAL_EXAMPLES \
--pipeline_config_path=$PIPELINE_CONFIG_PATH \
--checkpoint_every_n=$CHECKPOINT_EVERY_N \
--alsologtostderr
( ~10
1000
GPU runtime GoogleColab) TensorBoard. localization
classification
, , .
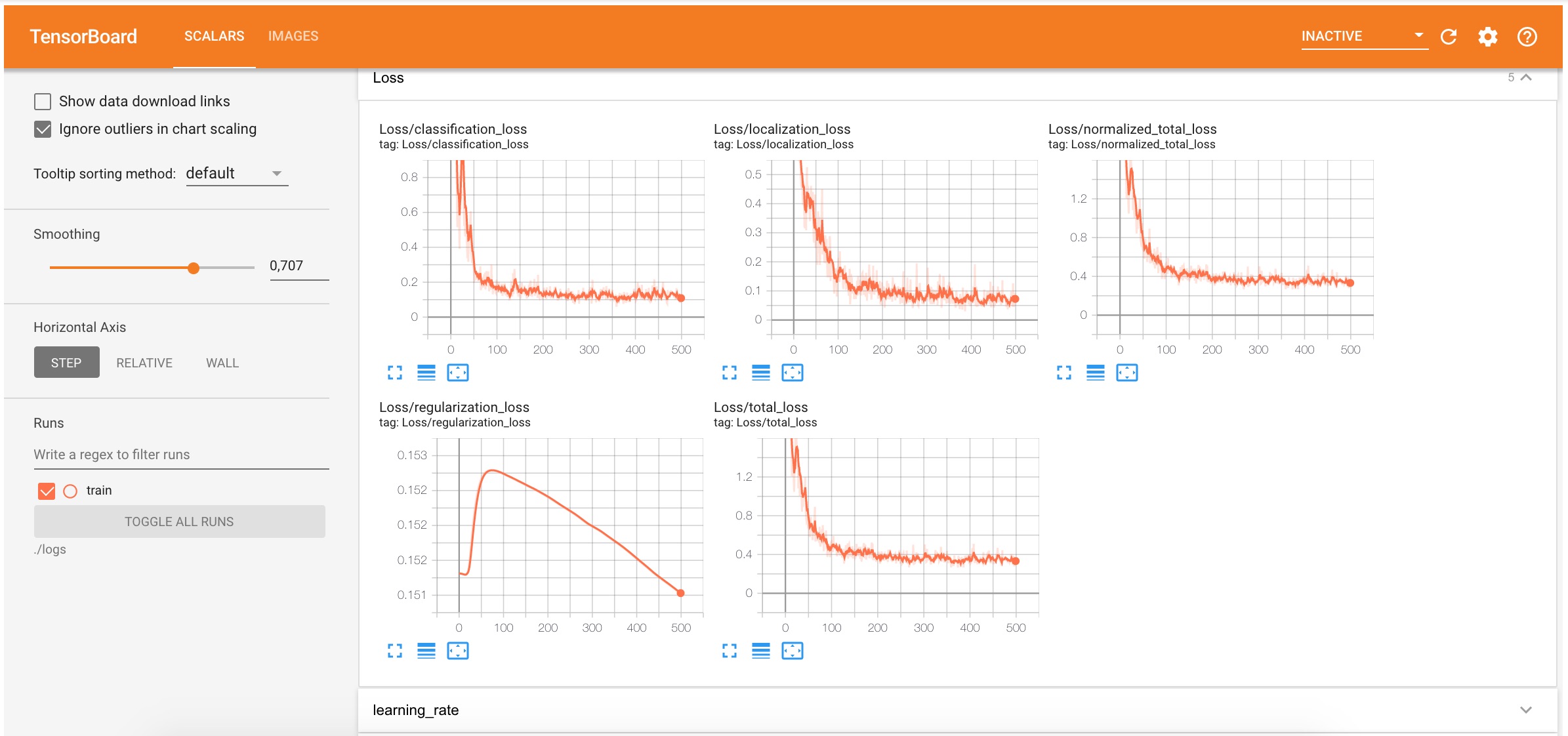
logs
() .
logs
:
logs ├── checkpoint ├── ckpt-1.data-00000-of-00001 ├── ckpt-1.index └── train └── events.out.tfevents.1606560330.b314c371fa10.1747.1628.v2
()
, - TensorBoard, , :
%%bash
PIPELINE_CONFIG_PATH=pipeline.config
MODEL_DIR=logs
python ./models/research/object_detection/model_main_tf2.py \
--model_dir=$MODEL_DIR \
--pipeline_config_path=$PIPELINE_CONFIG_PATH \
--checkpoint_dir=$MODEL_DIR \
:

. exporter_main_v2.py Object Detection API. TensorFlow . , SavedModel .
%%bash python ./models/research/object_detection/exporter_main_v2.py \ --input_type=image_tensor \ --pipeline_config_path=pipeline.config \ --trained_checkpoint_dir=logs \ --output_directory=exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
exported
:
exported └── ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8 ├── checkpoint │ ├── checkpoint │ ├── ckpt-0.data-00000-of-00001 │ └── ckpt-0.index ├── pipeline.config └── saved_model ├── assets ├── saved_model.pb └── variables ├── variables.data-00000-of-00001 └── variables.index
saved_model
, .
, , .
-, . :
import time
import math
PATH_TO_SAVED_MODEL = 'exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model'
def detection_function_from_saved_model(saved_model_path):
print('Loading saved model...', end='')
start_time = time.time()
# Load saved model and build the detection function
detect_fn = tf.saved_model.load(saved_model_path)
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(math.ceil(elapsed_time)))
return detect_fn
exported_detect_fn = detection_function_from_saved_model(
PATH_TO_SAVED_MODEL
)
output →
Loading saved model...Done! Took 9 seconds
:
from object_detection.utils import label_map_util
category_index = label_map_util.create_category_index_from_labelmap(
'dataset/printed_links/labels/label_map.pbtxt',
use_display_name=True
)
print(category_index)
output →
{1: {'id': 1, 'name': 'http'}}
.
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from object_detection.utils import visualization_utils
from object_detection.data_decoders.tf_example_decoder import TfExampleDecoder
%matplotlib inline
def tensors_from_tfrecord(
tfrecords_filename,
tfrecords_num,
dtype=tf.float32
):
decoder = TfExampleDecoder()
raw_dataset = tf.data.TFRecordDataset(tfrecords_filename)
images = []
for raw_record in raw_dataset.take(tfrecords_num):
example = decoder.decode(raw_record)
image = example['image']
image = tf.cast(image, dtype=dtype)
images.append(image)
return images
def test_detection(tfrecords_filename, tfrecords_num, detect_fn):
image_tensors = tensors_from_tfrecord(
tfrecords_filename,
tfrecords_num,
dtype=tf.uint8
)
for image_tensor in image_tensors:
image_np = image_tensor.numpy()
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = tf.expand_dims(image_tensor, 0)
detections = detect_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy() for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
image_np_with_detections = image_np.astype(int).copy()
visualization_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=100,
min_score_thresh=.3,
agnostic_mode=False
)
plt.figure(figsize=(8, 8))
plt.imshow(image_np_with_detections)
plt.show()
test_detection(
tfrecords_filename='dataset/printed_links/tfrecords/test.record',
tfrecords_num=10,
detect_fn=exported_detect_fn
)
10
https:
:

, ( https://
) , "" , , , .
-
, . , JavaScript TensorFlow — TensorFlow.js. JavaScript . tfjs_graph_model.
, , Python tensorflowjs:
pip install tensorflowjs --quiet
:
%%bash tensorflowjs_converter \ --input_format=tf_saved_model \ --output_format=tfjs_graph_model \ exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8/saved_model \ exported_web/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8
exported_web
.json
, .bin
.
exported_web └── ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8 ├── group1-shard1of4.bin ├── group1-shard2of4.bin ├── group1-shard3of4.bin ├── group1-shard4of4.bin └── model.json
- , https://
, JavaScript .
, :
import pathlib
def get_folder_size(folder_path):
mB = 1000000
root_dir = pathlib.Path(folder_path)
sizeBytes = sum(f.stat().st_size for f in root_dir.glob('**/*') if f.is_file())
return f'{sizeBytes//mB} MB'
print(f'Original model size: {get_folder_size("cache/datasets/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')
print(f'Exported model size: {get_folder_size("exported/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')
print(f'Exported WEB model size: {get_folder_size("exported_web/ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8")}')
output →
Original model size: 31 MB Exported model size: 28 MB Exported WEB model size: 13 MB
, , 13MB
, , .
:
import * as tf from '@tensorflow/tfjs';
const model = await tf.loadGraphModel(modelURL);
, . , , TypeScript links-detector GitHub.
. , https://
(, - ). tfjs_graph_model
JavaScript/TypeScript .
Links Detector , .
:
links-detector GitHub, .
Pour le moment, l'application est au stade expérimental et présente de nombreuses lacunes et limitations . Par conséquent, jusqu'à ce que les défauts ci-dessus soient corrigés, n'attendez pas trop de l'application.