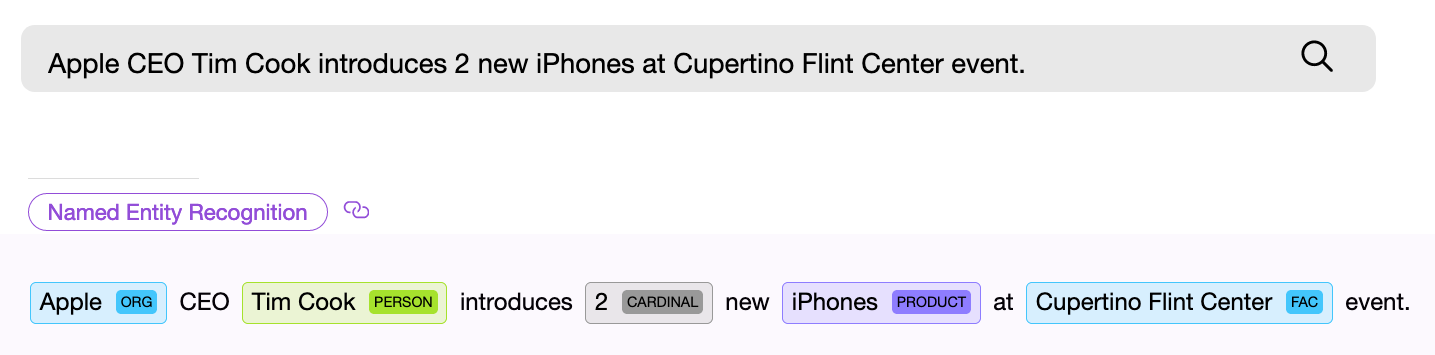
Le composant NER (named entity Recognition), c'est-à-dire un composant logiciel de recherche d'entités nommées, doit trouver un objet dans le texte et, si possible, en tirer des informations. Exemple - "Donnez-moi vingt-deux masques." Le composant numérique NER trouve l'expression «vingt-deux» dans le texte donné et extrait de ces mots la valeur numérique normalisée - « 22 », maintenant cette valeur peut être utilisée.
Les composants NER peuvent être basés sur des réseaux de neurones ou fonctionner sur la base de règles et de tout modèle interne. Les composants NER à usage général utilisent souvent la deuxième méthode.
Considérons plusieurs solutions toutes faites pour trouver des entités standard dans le texte. Dans cet article, nous nous concentrerons sur les bibliothèques gratuites ou gratuites avec restrictions, et parlerons également de ce qui a été fait dans le projet Apache NlpCraft dans le cadre de ce numéro. La liste ci-dessous n'est pas un aperçu détaillé et complet, dont il existe déjà un nombre suffisant sur le réseau, mais plutôt une brève description des principales caractéristiques, avantages et inconvénients de l'utilisation de ces bibliothèques.
Fournisseurs de composants NER
Apache OpenNlp
Apache OpenNlp fournit un ensemble assez standard de composants NER pour la langue anglaise, traitant des dates, des heures, de la géographie, des organisations, des pourcentages numériques et des personnes. Un petit ensemble est également disponible pour d'autres langues (espagnol, néerlandais).
Livraison:
bibliothèque Java. Apache OpenNlp ne fournit pas de modèles avec le projet principal. Ils sont disponibles en téléchargement séparément.
Avantages:
licence Apache. Les modèles ont été testés dans de nombreuses implémentations.
Moins:
Apparemment, les modèles ont été supprimés du projet principal pour une raison. On a l'impression que le travail sur eux est soit arrêté, soit se déroule à un rythme déprimant, car les nouveaux modèles ou les modifications des modèles existants n'ont pas été observés depuis un certain temps. Étant donné que les utilisateurs d'Apache OpenNlp peuvent créer et entraîner leurs propres modèles, il est possible que cette tâche leur soit complètement laissée.
Stanford Nlp
Stanford NLP est un produit vivant et en constante évolution, d'excellente qualité et offrant un large éventail de possibilités. Pour la langue anglaise, ajout de la prise en charge de la reconnaissance des entités suivantes: personne, emplacement, organisation, divers, argent, nombre, ordinal, pourcentage, date, heure, durée, ensemble. De plus, le composant Regex NER intégré vous permet de trouver avec un haut degré de précision des entités telles que: email, url, ville, état_ou_province, pays, nationalité, religion, titre (emploi), idéologie, charge_criminelle, cause_of_death, handle. Plus de détails sur le lien . Un support NER limité pour l'allemand, l'espagnol et le chinois est annoncé. La qualité de la reconnaissance peut être testée à l'aide de la démo en ligne .
La fourniture:
Bibliothèque Java. Les modèles peuvent être téléchargés à partir de mavens avec le projet.
Je n'ai trouvé nulle part une liste et une description détaillée des composants NER pour les langues autres que l'anglais. Liens 1 , 2 - des exemples du processus de formation de vos propres composants NER pour différentes langues sont donnés. En termes simples, la possibilité d'utiliser d'autres langues est annoncée, mais il faut bricoler.
Avantages:
Le sentiment de travailler avec le projet dans son ensemble et avec des modèles prêts à l'emploi est le plus positif, le projet vit et se développe, la qualité de la reconnaissance est bonne («bon» est un concept conditionnel, il existe des métriques qui caractérisent la qualité de la reconnaissance des composants NER, mais cette question dépasse le cadre de l'article).
Moins:
Mis à part un certain chaos avec les docs, ils sont petits. Pour qui c'est important, faites attention à la licence. La licence publique générale GNU est différente d' Apache , donc, par exemple, vous ne pouvez pas ajouter un produit avec cette licence aux produits sous licence Apache, etc.
API Google Language
L'API de langue Google pour l'anglais prend en charge la liste d'entités suivante: personne, emplacement, organisation, événement, work_of_art, consumer_good, other, phone_number, adresse, date, numéro, prix.
Plateforme:
API REST, SaaS. Des bibliothèques client prêtes à l'emploi sur REST sont disponibles (Java, C #, Python, Go, etc.).
Avantages:
Un grand nombre de composants NER, le développement et la qualité sont fournis par le géant de l'Internet bien connu.
Inconvénients: à
partir de certains volumes, l'utilisation est payante .
Spacy
Cette bibliothèque fournit l'un des ensembles les plus larges d'entités prises en charge pour la reconnaissance, voir le lien pour une liste des entités prises en charge.
Plateforme:
Python.
Malheureusement, le manque d'expérience personnelle d'utilisation industrielle ne me permet pas d'ajouter une véritable description des avantages et des inconvénients de cette bibliothèque. De plus, un aperçu détaillé des solutions Python NLP a déjà été publié sur habr.
Toutes les bibliothèques ci-dessus vous permettent de former vos propres modèles. De plus, tous (sauf Apache OpenNlp) permettent d'extraire des valeurs normalisées d'entités trouvées, c'est-à-dire, par exemple, d'obtenir le nombre «173» de l'entité numérique «cent soixante-treize» trouvée dans la requête.
Comme nous pouvons le voir, il existe de nombreuses options pour résoudre le problème de la recherche d'entités nommées, la direction de leur développement est évidente - élargir la liste des langues prises en charge et un ensemble d'entités reconnues, améliorant la qualité de la reconnaissance.
Voici un résumé de ce que le projet Apache NlpCraft a apporté à ce domaine déjà très développé.
Fonctionnalités supplémentaires fournies par NlpCraft
- Posséder des composants NER pour de nouvelles entités, des solutions améliorées pour certaines existantes.
- Intégration des composants NER de toutes les bibliothèques ci-dessus dans le cadre de l'utilisation du produit.
- Prise en charge des «entités composites», ce qui permet aux utilisateurs de créer facilement de nouveaux composants personnalisés à partir de composants existants.
Maintenant sur tout cela dans un peu plus de détails.
Composants NER propriétaires
Les composants NER natifs d'Apache NlpCraft sont des composants permettant de reconnaître les dates, les nombres, la géographie, les coordonnées, le tri et la mise en correspondance de différentes entités. Certains d'entre eux sont uniques, certains ne sont qu'une mise en œuvre améliorée des solutions existantes (la précision de la reconnaissance a été augmentée, des champs de valeur supplémentaires ont été ajoutés, etc.).
Intégration de solutions existantes
Toutes les solutions ci-dessus sont intégrées pour une utilisation avec Apache NlpCraft.
Lorsqu'il travaille avec un projet, l'utilisateur doit simplement connecter le module requis et spécifier dans la configuration quels composants NER doivent être utilisés lors de la recherche d'entités d'un modèle particulier.
Voici un exemple de configuration qui utilise quatre composants NER différents de deux fournisseurs lors de la recherche dans le texte:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
En savoir plus sur l'utilisation d'Apache NlpCraft ici . Un compte de développeur Google valide est requis pour utiliser l'API Google Language.
Prise en charge des entités composites
La prise en charge des entités composites est la plus intéressante des fonctionnalités ci-dessus, revenons-y un peu plus en détail.
Une entité composite est une entité définie sur la base d'une autre. Regardons un exemple. Supposons que vous développiez un système de contrôle PNL basé sur l'intention (voir Alexa , Google Dialogflow , Alice , Apache Nlpraft , etc.) et que votre modèle fonctionne avec la géographie, mais uniquement pour les États-Unis. Vous pouvez utiliser n'importe quel composant de recherche géographique comme " nlpcraft: city " et l'utiliser directement.
De plus, lorsque l'intention est déclenchée, dans la fonction correspondante (callback), vous devez vérifier la valeur du " pays», Et s'il ne remplit pas les conditions requises, arrêtez la fonction, évitant ainsi les faux positifs. Ensuite, vous devriez revenir à la correspondance et essayer de choisir une autre fonction plus appropriée.
Quel est le problème avec cette approche:
- Vous rendez beaucoup plus difficile le travail avec les fonctions appelées en transférant leur contrôle vers le thread de travail principal et inversement. En outre, il convient de noter que tous les systèmes de dialogue ne disposent pas d'une telle fonctionnalité de transfert de contrôle.
- Vous étalez la logique de correspondance entre l'intention et le code de méthode exécutable.
Ok ... Vous pouvez créer votre propre composant NER à partir de zéro pour trouver des villes américaines, mais cette tâche n'est pas résolue en cinq minutes.
Essayons les choses différemment. Vous pouvez compliquer l'intention (dans ces systèmes si possible) et rechercher des villes en plus filtrées par pays. Mais, je le répète, tous les systèmes n'offrent pas la possibilité d'un filtrage complexe par champs d'éléments, en plus, vous compliquez les intentions, qui doivent être aussi claires et simples que possible, surtout s'il y en a beaucoup dans le projet.
Apache NlpCraft fournit un mécanisme pour définir des composants NER natifs basés sur ceux existants. Voici un exemple de configuration (la syntaxe DSL complète est disponible ici , un exemple de création d'éléments est ici ):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
Dans cet exemple, nous décrivons une nouvelle entité nommée "American city" - " custom: city: usa ", basée sur le " nlpcraft: city " déjà existant filtré par un certain critère.
Vous pouvez maintenant créer des intentions en fonction du nouvel élément créé, et les villes en dehors des États-Unis rencontrées dans le texte ne provoqueront pas de déclenchement indésirable de vos intentions.
Un autre exemple:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
Dans cet exemple, nous avons défini l'entité nommée «city airport in the USA» - « custom: airport: usa ». Lors de la définition de cet élément, nous avons non seulement filtré les villes en fonction de leur appartenance à l'État, mais également défini une règle supplémentaire selon laquelle le nom de la ville doit être précédé de tout synonyme définissant le concept d '«aéroport». (En savoir plus sur la création de synonymes d'éléments via des macros - ici ).
Les éléments composites peuvent être définis avec n'importe quel degré d'imbrication, c'est-à-dire que, si nécessaire, vous pouvez concevoir de nouveaux éléments basés sur le nouveau " custom: airport: usa ". Notez également que toutes les valeurs normalisées des entités parentes, dans ce cas l'élément de base « nlpcraft: city”Sont également disponibles dans l'élément“ custom: airport: usa ”et peuvent être utilisés dans le corps de fonction de l'intention déclenchée.
Bien entendu, les «blocs de construction» peuvent être définis non seulement pour tous les composants standard pris en charge d'OpenNlp, Stanford, Google, Spacy et NlpCraft, mais également pour les composants NER personnalisés, étendant leurs capacités et vous permettant de réutiliser les développements logiciels existants.
Veuillez noter qu'en fait, vous ne produisez pas de nouveaux composants pour chaque nouvelle tâche, mais simplement les configurer ou "mélanger" leurs fonctionnalités dans vos propres éléments.
Ainsi, en utilisant des «entités composites», un développeur peut:
- Simplifiez considérablement la logique de construction des intentions en les transférant partiellement vers des blocs de construction réutilisables.
- Obtenez des composants NER avec un nouveau comportement en utilisant des changements de configuration sans formation de modèle ni codage.
- Réutilisez des solutions prêtes à l'emploi avec la qualité attendue, en vous appuyant sur des tests ou des métriques existants.
Conclusion
J'espère qu'un bref aperçu des avantages et des inconvénients des composants NER existants sera utile aux lecteurs, et comprendre comment Apache NlpCraft peut considérablement étendre ses capacités et adapter les solutions existantes pour de nouvelles tâches accélérera le processus de développement de vos projets.