Mélodie obsessionnelle (vers d'oreille anglais.) - un phénomène bien connu et parfois irritant. Une fois que l'un d'entre eux est coincé dans la tête, il peut être assez difficile de s'en débarrasser. La recherche a montré que la soi-disant interaction avec la composition originale , que ce soit en l'écoutant ou en la chantant, aide à chasser la mélodie intrusive. Mais que se passe-t-il si vous ne vous souvenez pas du nom de la chanson, mais que vous ne pouvez que fredonner l'air?
Lorsque l'on utilise les méthodes existantes de comparaison d'une mélodie chantée avec son enregistrement polyphonique original en studio, un certain nombre de difficultés surviennent. Le son d'un enregistrement en direct ou en studio avec des paroles, des chœurs et des instruments peut être très différent de ce qu'une personne fredonne. De plus, par erreur ou par conception, notre version peut ne pas avoir exactement la même hauteur, tonalité, tempo ou rythme. C'est pourquoi tant d' approches actuelles de la requête par système de bourdonnement mappent une mélodie chantée à une base de données de mélodies préexistantes ou d'autres versions chantées de cette chanson, plutôt que de l'identifier directement. Cependant, ce type d'approche est souvent basé sur une base de données limitée qui nécessite une mise à jour manuelle.
Lancé en octobre, Hum to Search est un nouveau système de recherche Google entièrement à apprentissage automatique qui permet à une personne de trouver une chanson en la chantant ou en la rinçant. Contrairement aux méthodes existantes, cette approche crée une incrustation à partir du spectrogramme de la chanson, en contournant la représentation intermédiaire. Cela permet au modèle de comparer directement notre mélodie à l'enregistrement original (polyphonique) sans avoir à avoir une mélodie ou une version MIDI différente de chaque piste. Il n'a pas non plus besoin d'utiliser une logique artisanale complexe pour extraire la mélodie. Cette approche simplifie considérablement la base de données pour Hum to Search, vous permettant d'y ajouter continuellement des incorporations de pistes originales du monde entier, même les versions les plus récentes.
Comment ça fonctionne
De nombreux systèmes de reconnaissance musicale existants le convertissent en spectrogramme avant de traiter un échantillon audio pour trouver une correspondance plus correcte. Cependant, il y a un problème avec la reconnaissance d'une mélodie chantée - elle contient souvent relativement peu d'informations, comme dans cet exemple de la chanson "Bella Ciao" . La différence entre la version chantée et le même segment de l'enregistrement studio correspondant peut être visualisée à l'aide des spectrogrammes ci-dessous:

Visualisation de l' extrait chanté et de son enregistrement en studio
Compte tenu de l'image de gauche, le modèle doit trouver l'audio qui correspond à l'image de droite dans une collection de plus de 50 millions d'images similaires (correspondant à des segments d'enregistrements en studio d'autres chansons). Pour ce faire, le modèle doit apprendre à se concentrer sur la mélodie dominante et à ignorer les chœurs, les instruments et le timbre de la voix, ainsi que les différences dues au bruit de fond ou à la réverbération. Pour déterminer à l'œil nu la mélodie dominante qui pourrait être utilisée pour comparer ces deux spectrogrammes, vous pouvez rechercher des similitudes dans les lignes au bas des images ci-dessus.
Les tentatives précédentes de mise en œuvre de la reconnaissance musicale, en particulier la musique dans les cafés ou les clubs, ont montré comment l'apprentissage automatique peut être appliqué à ce problème. Now Playing , sorti en 2017 pour les téléphones Pixel, utilise un réseau neuronal profond intégré pour reconnaître les chansons sans avoir besoin d'une connexion au serveur, tandis que Sound Search , qui a développé plus tard la technologie, utilise la reconnaissance basée sur le serveur pour rechercher rapidement et avec précision plus de 100 millions de chansons. Nous devions également appliquer ce que nous avions appris dans ces versions pour reconnaître la musique d'une bibliothèque tout aussi grande, mais déjà des passages chantés.
Configurer l'apprentissage automatique
La première étape de l'évolution de Hum to Search a été de changer les modèles de reconnaissance musicale utilisés dans Now Playing et Sound Search pour qu'ils fonctionnent avec des enregistrements de mélodies. En principe, de nombreux moteurs de recherche similaires (comme la reconnaissance d'image) fonctionnent de la même manière. Dans le processus de formation, le réseau neuronal reçoit une paire (une mélodie et un enregistrement original) en entrée et crée leurs incorporations, qui seront plus tard utilisées pour correspondre à la mélodie chantée.

Mise en place de la formation des réseaux de neurones
Pour assurer la reconnaissance de ce que nous chantons, les plongements de paires audio avec la même mélodie doivent être situés les uns à côté des autres, même s'ils ont des accompagnements instrumentaux et des voix chantées différents. Les paires audio contenant différentes mélodies doivent être éloignées. Pendant la formation, le réseau reçoit ces paires audio jusqu'à ce qu'il apprenne à créer des imbrications avec cette propriété.
En fin de compte, le modèle formé sera capable de générer des plongements pour nos morceaux, similaires aux plongements d'enregistrements maîtres de chansons. Dans ce cas, trouver la chanson souhaitée est juste une question de recherche dans la base de données pour des incorporations similaires calculées sur la base d'enregistrements audio de musique populaire.
Données d'entraînement
Puisque la formation du modèle nécessitait des paires de chansons (enregistrées et chantées), le premier défi était d'obtenir suffisamment de données. Notre ensemble de données original se composait principalement d'extraits chantés (très peu d'entre eux ne contenaient qu'un bourdonnement d'un motif sans mots). Pour rendre le modèle plus fiable, pendant l'entraînement, nous avons appliqué une augmentation à ces fragments: nous avons changé la hauteur et le tempo dans un ordre aléatoire. Le modèle résultant fonctionnait assez bien pour des exemples où la chanson était chantée plutôt que fredonnée ou sifflée.
Pour améliorer les performances du modèle sur des mélodies sans mots, nous avons généré des données d'entraînement supplémentaires avec un «bourdonnement» artificiel à partir de l'ensemble existant de données audio. Pour cela, nous avons utilisé SPICE, un modèle d'extraction de pitch développé par notre équipe élargie dans le cadre du projet FreddieMeter . SPICE extrait les valeurs de hauteur d'un audio donné, que nous utilisons ensuite pour générer une mélodie composée de tonalités audio discrètes. La toute première version de ce système a transformé le passage original ici en cela .
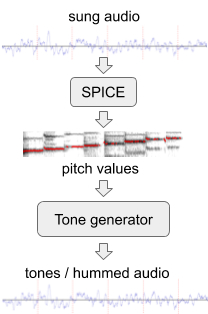
Génération de «bourdonnement» à partir d'un fragment audio chanté
Plus tard, nous avons amélioré l'approche en remplaçant un simple générateur de sons par un réseau neuronal qui génère un son qui ressemble à un véritable bourdonnement d'un motif sans mots. Par exemple, l'extrait ci-dessus peut être transformé en un tel bourdonnement ou sifflet .
Dans la dernière étape, nous avons comparé les données d'entraînement en mélangeant et en faisant correspondre des extraits audio. Lorsque, par exemple, nous sommes tombés sur des extraits similaires de deux artistes différents, nous les avons alignés sur nos modèles préliminaires et avons donc fourni au modèle une paire supplémentaire d'extraits audio de la même mélodie.
Améliorer le modèle
Lors de la formation du modèle Hum to Search, nous avons commencé avec la fonction de perte de triplets , qui s'est bien comportée dans diverses tâches de classification telles que la classification d'images et de musique enregistrée . Si une paire d'audio correspond à la même mélodie (les points R et P dans l'espace d'incorporation illustré ci-dessous), la fonction de perte de triolet ignore certaines parties des données d'apprentissage dérivées de l'autre mélodie. Cela permet d'améliorer le comportement d'apprentissage lorsque le modèle trouve une autre mélodie trop simple et déjà éloignée de R et P (voir point E). Et aussi quand il est trop complexe pour l'étape actuelle de la formation du modèle et se révèle trop proche de R (voir point H).

Exemples de segments audio rendus sous forme de points dans l'espace
Nous avons constaté que nous pouvons améliorer la précision du modèle en prenant en compte des données d'apprentissage supplémentaires (points H et E), notamment en formulant le concept général de confiance du modèle dans une série d'exemples: dans quelle mesure le modèle est-il sûr que toutes les données, avec laquelle elle a travaillé peut être classée correctement? Ou a-t-elle rencontré des exemples qui ne correspondent pas à sa compréhension actuelle? Sur cette base, nous avons ajouté une fonction de perte qui rapproche la confiance du modèle de 100% dans toutes les zones de l'espace d'intégration, ce qui améliore la qualité et la précision de la mémoire de notre modèle .
Les changements susmentionnés, en particulier l'augmentation et la combinaison de données d'entraînement, ont permis au modèle de réseau neuronal utilisé dans les recherches Google de reconnaître des airs chantés. Le système actuel atteint un haut niveau de précision basé sur une base de données de plus d'un demi-million de chansons que nous mettons constamment à jour. Cette collection de morceaux a de la place pour se développer, avec plus de musique du monde entier à inclure.
Pour tester cette fonctionnalité, ouvrez la dernière version de l'appli Google, cliquez sur l'icône du microphone et dites "Qu'est-ce que cette chanson" ou cliquez sur "Trouver une chanson". Vous pouvez maintenant fredonner ou siffler une mélodie! Nous espérons que Hum to Search vous aidera à vous débarrasser des mélodies intrusives ou simplement à trouver et à écouter une piste sans entrer son nom.