Nous continuons le thème de la sécurité de l'information et publions la traduction de l' article de Coussement Bruno.
Ajouter du bruit aux données existantes, ajouter du bruit uniquement aux résultats de manipulation des données ou générer des données synthétiques? Faisons confiance à notre intuition?

Les entreprises se développent et leurs réglementations en matière de cybersécurité deviennent plus strictes, les architectes seniors adoptent les tendances ... Tout cela conduit à la nécessité (ou à l'obligation) de réduire les risques de confidentialité et la fuite d'informations ne fait que s'intensifier pour les personnes concernées.
Dans ce cas, les méthodes d'anonymisation ou de tokenisation des données sont largement utilisées, bien qu'elles permettent également la possibilité de divulguer des informations privées (voir cet article pour comprendre pourquoi cela se produit).
Générer des données synthétiques
Les données synthétiques ont une différence fondamentale. Le but est de créer un générateur de données qui affiche les mêmes statistiques globales que les données d'origine. Distinguer l'original du résultat final devrait être difficile pour un modèle ou une personne.
Illustrons ce qui précède en générant des données synthétiques sur l' ensemble de données Covertype à l' aide du modèle TGAN .

Après avoir entraîné le modèle sur cette table, j'ai généré 5000 lignes et tracé un histogramme de la colonne Élévation de l'ensemble d' origine et généré. Il semble que les deux lignes coïncident visuellement.
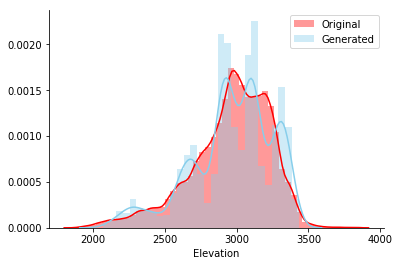
Pour vérifier la relation entre les paires de barres, un graphique apparié de toutes les barres continues s'affiche. La forme que forment les points bleu-vert (générés) doit correspondre visuellement à la forme des points rouges (original). Et c'est arrivé, cool!

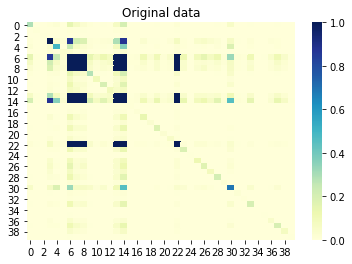
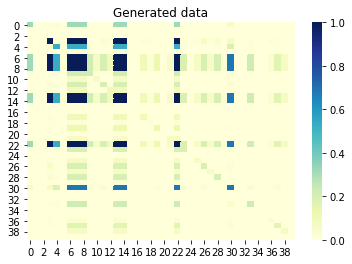
Si nous examinons maintenant les informations mutuelles (également appelées corrélation non signée) entre les colonnes, les colonnes qui sont corrélées les unes avec les autres doivent également être corrélées dans l'ensemble généré. À l'inverse, les colonnes non corrélées de l'ensemble d'origine ne doivent pas être corrélées dans l'ensemble généré. Une valeur proche de 0 signifie aucune corrélation et une valeur proche de 1 signifie une corrélation parfaite. C'est génial!
Informations mutuelles entre les colonnes du jeu d'origine:
Informations mutuelles entre les colonnes générées ensemble:
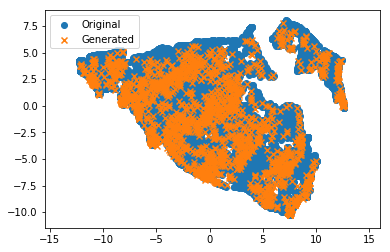
Comme test final, je voulais entraîner la méthode de réduction de dimensionnalité non linéaire ( UMAP ) sur l'ensemble d'origine et projeter les points d' origine dans l'espace 2D. J'entre l'ensemble généré dans le même projecteur. Les croix orange (générées) doivent se trouver dans les nuages de points bleus du jeu de données d'origine. Et voici! Excellent!
OK, expérimenter avec des données est amusant!
Pour les cas plus graves, il existe 2 approches principales:
- : , . , . .
Il convient de prêter attention à des initiatives telles que le coffre - fort de données synthétiques , Gretel.AI , Mostly.ai , MDClone , Hazy .
Aujourd'hui, vous pouvez déjà rédiger une preuve de concept à l'aide de données synthétiques pour résoudre l'un des problèmes courants suivants auxquels sont confrontées les organisations informatiques:
- Aucune charge utile dans l'environnement de développement
Disons que vous travaillez sur un produit de données (cela peut être n'importe quoi) où les données qui vous intéressent se trouvent dans un environnement de production avec une politique d'accès très stricte. Malheureusement, vous n'avez accès qu'à l'environnement de développement sans données intéressantes.
- Mode Dieu - Droits d'accès pour les ingénieurs et les scientifiques des données
Disons que vous êtes un data scientist et qu'un responsable de la sécurité de l'information a soudainement limité vos privilèges indispensables pour accéder aux données de production. Comment pouvez-vous continuer à faire du bon travail dans un environnement aussi difficile et limité?
- Transfert de données sensibles vers un partenaire externe non approuvé
Vous faites partie de la société X. L'organisation Y aimerait présenter son dernier produit de données cool (cela pourrait être n'importe quoi).
Ils vous demandent d'extraire des données pour vous montrer le produit.
Quel est le lien entre les données synthétiques et la confidentialité différentielle?
La principale propriété de la génération de données synthétiques est que, indépendamment du post-traitement ou de l'ajout d'informations tierces, personne ne pourra jamais savoir si un objet est contenu dans l'ensemble d'origine et ne pourra pas non plus obtenir les propriétés de cet objet. Cette propriété fait partie d'un concept plus large appelé confidentialité différentielle (DP).
Confidentialité différentielle mondiale et locale
DP est divisé en 2 types.
Souvent, seul le résultat d'une tâche spécifique présente un intérêt (par exemple, former un modèle basé sur des données non divulguées de patients de différents hôpitaux, calculer le nombre moyen de personnes ayant déjà commis un crime, etc.), il convient alors de prêter attention à la confidentialité différentielle globale.
Dans ce cas, un utilisateur non fiable ne verra jamais de données confidentielles. Au lieu de cela, il ou elle indique à un conservateur de confiance (avec des mécanismes de confidentialité différentiels mondiaux) qui a accès aux données sensibles les opérations à effectuer.
Seul le résultat est signalé à l'utilisateur non approuvé. Je recommande Pysyftet OpenDP si vous avez besoin de plus d'informations sur des outils similaires.
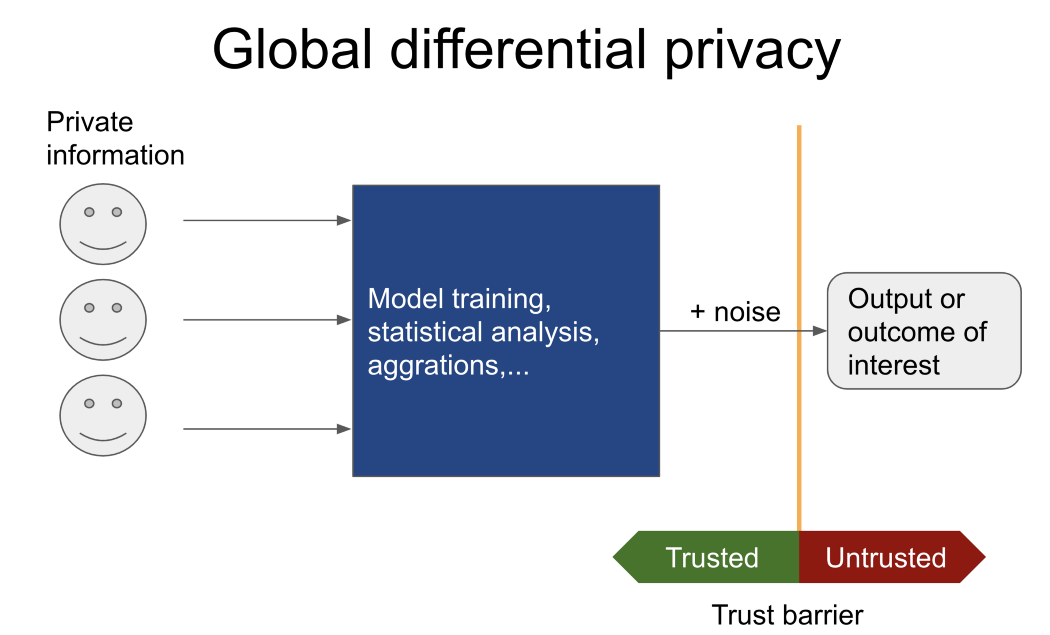
En revanche, si des données doivent être transférées à une partie non approuvée, les principes de confidentialité différentielle locale entrent en jeu. Traditionnellement, cela se fait en ajoutant du bruit à chaque ligne d'une table ou d'une base de données. La quantité de bruit ajouté dépend de:
- le niveau de confidentialité requis (le fameux epsilon dans la littérature DP),
- la taille du jeu de données (un jeu de données plus grand nécessite moins de bruit pour atteindre le même niveau de confidentialité),
- type de données de colonne (quantitatif, catégorique, ordinal).

En théorie, à niveau égal de confidentialité, le mécanisme DP global (ajout de bruit au résultat) fournira des résultats plus précis que le mécanisme local (bruit au niveau de la ligne).
Ainsi, les méthodes de génération de données synthétiques peuvent être considérées comme une forme de DP local.
Pour plus d'informations sur ces sujets, je vous conseille de consulter les sources suivantes:
- www.udacity.com/course/secure-and-private-ai--ud185
- medium.com/@arbidha1412/local-and-global-differential-privacy-249aaa3571
- www.openmined.org
Recommandation
Regardons maintenant un exemple plus spécifique. Vous souhaitez partager une feuille de calcul contenant des informations personnelles avec une partie non approuvée.
À l'heure actuelle, vous pouvez soit ajouter du bruit aux lignes de données existantes (DP local), configurer et utiliser un système robuste (DP global), ou générer des données synthétiques basées sur l'original.
Le bruit doit être ajouté aux lignes de données existantes si
- vous ne savez pas quelle opération sera effectuée sur les données après publication,
- vous devez partager périodiquement une mise à jour des données d'origine (= avoir ce flux de travail dans le cadre d'un processus par lots stable),
- vous et les propriétaires des données faites confiance à la personne / l'équipe / l'organisation pour ajouter du bruit aux données d'origine.
Ici, je recommande de commencer par les outils OpenDP .
Le cas le plus célèbre de confidentialité différentielle se trouve dans le recensement des États-Unis (voir databricks.com/session_na20/using-apache-spark-and-differential-privacy-for-protecting-the-privacy-of-the-2020-census-respondents ).
Ces données sont recalculées et mises à jour tous les trois ans. Ce sont principalement des données numériques qui sont agrégées et publiées à plusieurs niveaux (comté, état, national).
Installez et utilisez un système fiable si
- le système que vous avez spécifié prend en charge les tâches et opérations qui y seront effectuées,
- les données de base sont stockées à différents endroits et ne peuvent pas les laisser (par exemple, dans différents hôpitaux),
- vous et les propriétaires de données faites réellement confiance au système actuel et à la personne / équipe / organisation qui le met en place.
En tant qu'utilisateur de données sensibles, vous obtiendrez des résultats plus précis que la première approche.
De nombreux frameworks ne disposent pas actuellement de toutes les fonctionnalités nécessaires pour déployer cette bête de manière sécurisée, évolutive et auditable. Il y a encore beaucoup de travail d'ingénierie à faire ici.
Mais à mesure que leur adoption se développe, DP peut être une bonne alternative pour les grandes organisations et les entreprises.
Je recommande de commencer ici avec OpenMined .
Il est possible de générer des données synthétiques si
- (<1 , <100 ),
- ad-hoc ( ),
- / / , .
Comme pour la petite expérience décrite ci-dessus, les résultats sont prometteurs. Il ne nécessite pas non plus une excellente connaissance des systèmes DP. Vous pouvez commencer dès aujourd'hui, si vous en avez besoin, laissez-le s'entraîner pendant la nuit et, pour ainsi dire, préparer l'ensemble synthétique partagé pour demain matin.
Le plus gros inconvénient est que ces modèles complexes peuvent devenir coûteux à entraîner et à entretenir si la quantité de données augmente. Chaque table nécessite également sa propre formation de modèle complète (la formation portable ne fonctionnera pas ici). Vous ne pourrez pas passer à des centaines de tables, même avec un budget de calcul important.
Sinon, vous n'avez pas de chance.
Conclusion
La confidentialité des données étant plus importante que jamais, nous disposons d'excellentes méthodes pour générer des données synthétiques ou pour ajouter du bruit aux données existantes. Cependant, ils ont tous encore leurs limites. Hormis quelques cas de niche, un outil évolutif et flexible de niveau entreprise n'a pas encore été créé pour permettre le transfert de données contenant des informations personnelles à des parties non fiables.
Les propriétaires de données doivent toujours faire confiance aux méthodes ou aux systèmes établis, ce qui nécessite une grande confiance de leur part. C'est le plus gros problème!
En attendant, si vous voulez l'essayer (preuve de concept, testez-le), ouvrez l'un des liens ci-dessus.