Parmi les frameworks que nous envisageons pour le traitement de données complexes en Java, il y a Apache Flink. Nous aimerions vous proposer une traduction d'un bon article du blog Analytics Vidhya sur le portail Medium afin d'évaluer l'intérêt du lecteur. N'hésitez pas à voter!

Dans cet article, nous allons examiner de bas en haut comment rationaliser avec Flink; dans les services cloud et sur d'autres plates-formes, des solutions de streaming sont fournies (dont certaines ont Flink intégré sous le capot). Si vous vouliez comprendre ce sujet à partir de zéro, vous avez trouvé exactement ce que vous recherchiez.
Notre solution monolithique ne pouvait pas faire face aux volumes croissants de données entrantes; il fallait donc le développer. Il est temps de passer à une nouvelle génération dans l'évolution de notre produit. Il a été décidé d'utiliser le traitement en continu. Il s'agit d'un nouveau paradigme d'absorption des données supérieur au traitement par lots traditionnel.
Apache Flink en un coup d'œil
Apache Flink est un framework de threading distribué évolutif conçu pour les opérations sur des flux de données continus. Dans ce cadre, des concepts tels que les sources, les transformations de flux, le traitement parallèle, la planification, l'affectation des ressources sont utilisés. Une variété de destinations de données sont prises en charge. Plus précisément, Apache Flink peut se connecter à HDFS, Kafka, Amazon Kinesis, RabbitMQ et Cassandra.
Flink est connu pour son débit élevé et sa faible latence, son traitement cohérent et strictement unique (toutes les données sont traitées une fois, aucune duplication) et sa haute disponibilité. Comme tout autre produit open source à succès, Flink dispose d'une large communauté qui cultive et étend les capacités de ce framework.
Flink peut gérer des flux de données (la taille du flux n'est pas définie) ou des ensembles de données (la taille de l'ensemble de données est spécifique). Cet article traite spécifiquement du traitement des threads (gestion des objets
DataStream
).
Le streaming et ses défis inhérents
De nos jours, avec l'omniprésence des appareils IoT et d'autres capteurs, les données proviennent constamment de nombreuses sources. Ce flux de données sans fin nécessite l'adaptation du traitement par lots traditionnel aux nouvelles conditions.
- Streaming de données illimité; ils n'ont ni début ni fin.
- De nouvelles données arrivent de manière imprévisible, à des intervalles irréguliers.
- Les données peuvent arriver de manière désordonnée, avec des horodatages différents.
Avec ces caractéristiques uniques, les tâches de traitement des données et d'interrogation ne sont pas simples à réaliser. Les résultats peuvent changer rapidement et il est presque impossible de tirer des conclusions définitives; les calculs peuvent parfois bloquer lorsque vous essayez d'obtenir des résultats valides. De plus, les résultats ne sont pas reproductibles, car les données continuent d'évoluer au cours des calculs. Enfin, les retards sont un autre facteur affectant l'exactitude des résultats.
Apache Flink vous permet de faire face à de tels problèmes de traitement, car il se concentre sur les horodatages avec lesquels les données entrantes sont renvoyées dans la source. Flink a un mécanisme pour accumuler des événements basés sur des horodatages, mis sur eux - et seulement après avoir accumulé le système procède au traitement. Dans ce cas, il est possible de se passer de l'utilisation de micro-emballages, et dans ce cas, la précision des résultats est augmentée.
Flink met en œuvre un traitement cohérent, strictement unique, qui garantit la précision des calculs, et le développeur n'a pas besoin de programmer quoi que ce soit de spécial pour cela.
De quoi sont faits les paquets Flink
En règle générale, Flink absorbe des flux de données provenant de différentes sources. L'objet de base est
DataStream<T>
un flux d'éléments du même type. Le type d'élément dans un tel flux est déterminé au moment de la compilation en définissant un type générique
T
(vous pouvez en savoir plus à ce sujet ici ).
L'objet
DataStream
contient de nombreuses méthodes utiles pour transformer, fractionner et filtrer les données. Pour commencer, il sera utile d'avoir une idée de ce qu'ils font
map
,
reduce
et
filter
; voici les principales méthodes de transformation:
Map
: obtient un objetT
et renvoie par conséquent un objet de typeR
;MapFunction
strictement une fois appliqué à chaque élément de l'objetDataStream
.
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce
: obtient deux valeurs consécutives et renvoie un objet, en les combinant en un objet du même type; cette méthode s'exécute sur toutes les valeurs du groupe jusqu'à ce qu'il n'en reste qu'une seule.
T reduce(T value1, T value2)
Filter
: récupère un objetT
et renvoie un flux d'objetsT
; cette méthode itère sur tous les élémentsDataStream
, mais ne retourne que ceux pour lesquels la fonction retournetrue
.
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
Drain de données
L'un des principaux objectifs de Flink, avec la transformation des données, est de contrôler les flux et de les diriger vers certaines destinations. Ces endroits sont appelés «drains». Flink a des chaînes intégrées (texte, CSV, socket), ainsi que des mécanismes prêts à l'emploi pour se connecter à d'autres systèmes, par exemple Apache Kafka .
Balises d'événement Flink
Lors du traitement des flux de données, le facteur temps est extrêmement important. Il existe trois façons de déterminer l'horodatage:
- ( ): , ; , . - . , .
, , . , , , ; , .
// Processing Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- : , , , Flink. , , Flink .
Flink , , , ; « » (watermark). ; Flink.
// Event Time streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream<String> dataStream = streamEnv.readFile(auditFormat, dataDir, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000). assignTimestampsAndWatermarks( new TimestampExtractor());// ... ... // public class TimestampExtractor implements AssignerWithPeriodicWatermarks<String>{ @Override public Watermark getCurrentWatermark() { return new Watermark(System.currentTimeMillis()-maxTimeFrame); } @Override public long extractTimestamp(String str, long l) { return InputData.getDataObject(str).timestamp; } }
- Temps d'absorption: c'est le moment auquel l'événement entre dans Flink; attribué lorsque l'événement est dans la source et est donc considéré comme plus stable que le temps de traitement attribué lorsque le processus démarre.
Le temps d'absorption ne convient pas pour traiter des événements dans le désordre ou des données tardives car l'horodatage correspond au début de l'absorption; en cela, il diffère de l'heure de l'événement, qui offre la possibilité de détecter les événements en attente et de les traiter, en s'appuyant sur le mécanisme de tatouage.
// Ingestion Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
Vous pouvez en savoir plus sur les horodatages et leur incidence sur la diffusion en continu sur le lien suivant .
Panne de fenêtre
Le flux est par définition sans fin; par conséquent, le mécanisme de traitement est associé à la définition de fragments (par exemple, périodes-fenêtres). Ainsi, le flux est divisé en lots qui sont pratiques pour l'agrégation et l'analyse. Une définition de fenêtre est une opération sur un objet DataStream ou autre chose qui en hérite.
Il existe plusieurs types de fenêtres dépendant du temps:
Fenêtre de basculement (configuration par défaut):
Le flux est divisé en fenêtres de taille équivalente qui ne se chevauchent pas. Pendant que le flux coule, Flink calcule en permanence les données en fonction de ce storyboard fixé dans le temps. Implémentation de la

fenêtre
tumultueuse dans le code:
// ,
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// ,
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
Fenêtre coulissante
De telles fenêtres peuvent se chevaucher et les propriétés de la fenêtre coulissante sont déterminées par la taille de cette fenêtre et la marge (quand démarrer la fenêtre suivante). Dans ce cas, les événements liés à plus d'une fenêtre peuvent être traités à un moment donné.

Fenêtre coulissante
Et voici à quoi cela ressemble dans le code:
// 1 30
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
Fenêtre de session
Inclut tous les événements limités par la portée d'une session. La session se termine s'il n'y a aucune activité ou si aucun événement n'est détecté après une certaine période. Cette période peut être fixe ou dynamique, selon les événements en cours de traitement. En théorie, si l'intervalle entre les sessions est inférieur à la taille de la fenêtre, la session peut ne jamais se terminer.
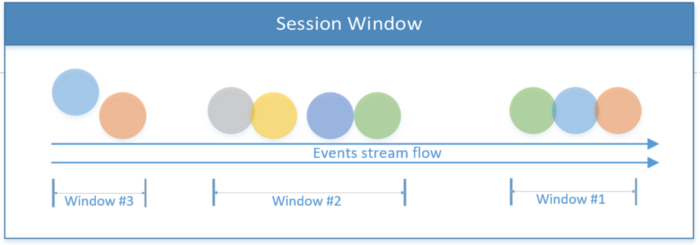
Fenêtre de session
Le premier extrait de code ci-dessous montre une session avec une valeur de temps fixe (2 secondes). Le deuxième exemple implémente une fenêtre de session dynamique basée sur les événements de thread.
// 2
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// ,
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// ,
}))
Fenêtre globale
L'ensemble du système est traité comme une seule fenêtre.

La fenêtre globale
Flink vous permet également d'implémenter vos propres fenêtres, dont la logique est définie par l'utilisateur.
En plus des fenêtres dépendant du temps, il existe d'autres, par exemple, la fenêtre Compte, où la limite du nombre d'événements entrants est définie; lorsque le seuil X est atteint, Flink traite X événements.

Fenêtre de comptage pour trois événements
Après une introduction théorique, discutons plus en détail de ce qu'est un flux de données d'un point de vue pratique. Pour plus d'informations sur Apache Flink et le threading, consultez le site officiel .
Description du flux
En guise de résumé théorique, le diagramme suivant montre les principaux flux de données implémentés dans les extraits de code de cet article. Le flux ci-dessous commence à la source (les fichiers sont écrits dans le répertoire) et continue pendant le traitement des événements qui sont transformés en objets.
L'implémentation décrite ci-dessous a deux chemins de traitement. Celui montré en haut divise un flux en deux flux latéraux, puis les combine pour obtenir un flux du troisième type. Le script affiché en bas du diagramme décrit le traitement du flux, après quoi les résultats du travail sont transférés vers le puits.

Ensuite, nous essaierons de ressentir de nos mains la mise en œuvre pratique de la théorie ci-dessus; tout le code source discuté ci-dessous est publié sur GitHub .
Traitement de flux de base (exemple n ° 1)
Il sera plus facile de comprendre les concepts de Flink si vous commencez par l'application la plus simple. Dans cette application, le producteur écrit des fichiers dans un répertoire, simulant ainsi le flux d'informations. Flink lit les fichiers de ce répertoire et écrit des informations récapitulatives les concernant dans le répertoire de destination; c'est le stock.
Ensuite, examinons de près ce qui se passe pendant le traitement:
Conversion de données brutes en un objet:
// InputData;
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
L'extrait de code ci-dessous
InputData
convertit un objet de flux ( ) en une chaîne et un tuple entier. Il extrait uniquement certains champs du flux d'objets, les regroupant par un champ en quanta de deux secondes.
//
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // KeyedStream<T, Tuple> ( 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // timeWindowAll
.timeWindow(Time.seconds(2)) // WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
Création d'une destination pour un flux (implémentation d'un récepteur de données):
//
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) //
.reduce((x,y) -> // ,
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
//
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// DataStream; inputCountSummary countSink
inputCountSummary.addSink(countSink);
Exemple de code pour créer un récepteur de données.
Division des flux (exemple n ° 2)
Cet exemple montre comment diviser le flux principal à l'aide de flux de sortie secondaires. Flink fournit plusieurs flux secondaires à partir du flux principal
DataStream
. Le type de données situé de chaque côté du flux peut être différent du type de données du flux principal, ainsi que du type de données de chacun des flux secondaires.
Ainsi, en utilisant un flux de sortie secondaire, vous pouvez tuer deux oiseaux avec une pierre: divisez le flux et convertissez le type de données du flux en plusieurs types de données (ils peuvent être uniques pour chaque flux de sortie latéral).
L'extrait de code ci-dessous est appelé
ProcessFunction
diviser le flux en deux côtés, en fonction de la propriété d'entrée. Pour obtenir le même résultat, il faudrait utiliser la fonction à plusieurs reprises
filter
.
Fonction
ProcessFunction
collecte certains objets (en fonction du critère) et les envoie au collecteur de sortie principal (se trouve dans
SingleOutputStreamOperator
), et le reste des événements est transmis aux sorties latérales. Le flux
DataStream
se divise verticalement et publie différents formats pour chaque flux secondaire.
Notez que la définition d'une sortie sidestream est basée sur une balise de sortie unique (objet
OutputTag
).
//
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
//
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// InputData .
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// ;
// playerTag, (" ")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// InputData
collInputData.collect(inputData);
break;
}
}
});
Exemple de code montrant comment diviser un flux
Combinaison de flux (exemple n ° 3)
La dernière opération qui sera couverte dans cet article est la concaténation de threads. L'idée est de combiner deux flux différents, dont les formats de données peuvent différer, à partir desquels collecter un flux avec une structure de données unifiée. Contrairement à l'opération de jointure de SQL, où les données sont fusionnées horizontalement, les flux sont fusionnés verticalement, car le flux d'événements se poursuit et n'est pas limité dans le temps.
La concaténation des flux est effectuée en appelant la méthode de connexion, puis en définissant une opération d'affichage pour chaque élément de chaque flux individuel. Le résultat est un flux fusionné.
//
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // 1
Tuple2<String, String>, // 2
Tuple4<String, String, String, Integer> //
>() {
@Override
public Tuple4<String, String, String, Integer> // 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
Liste montrant comment obtenir un flux fusionné
Créer un projet de travail
Donc, pour récapituler: le projet de démonstration est téléchargé sur GitHub. Il décrit comment le construire et le compiler. C'est un bon point de départ pour s'entraîner avec Flink.
conclusions
Cet article décrit les opérations de base pour créer une application de threading basée sur Flink. Le but de l'application est de fournir une vue d'ensemble des appels critiques inhérents au streaming et de jeter les bases de la création ultérieure d'une application Flink entièrement fonctionnelle.
Étant donné que la diffusion en continu comporte de nombreuses facettes et de nombreuses complexités, la plupart des problèmes de cet article restent non résolus; en particulier, l'exécution Flink et la gestion des tâches, le tatouage lors du réglage de l'heure des événements de streaming, l'injection d'état dans les événements de flux, l'exécution d'itérations de flux, l'exécution de requêtes de type SQL sur les flux, et bien plus encore.
Nous espérons que cet article a suffi à vous donner envie d'essayer Flink.