
Un peu sur moi-même: je suis également développeur débutant, je suis en train de suivre le cours "développeur Python". Ce matériel n'a pas été compilé à la suite de la télédétection, mais dans l'ordre du développement personnel. Mon code peut être assez naïf, et donc n'hésitez pas à laisser vos commentaires dans les commentaires. Si je ne t'ai pas encore fait peur, s'il te plaît, sous la coupure :)
Nous analyserons un exemple pratique de normalisation d'une table plate contenant des données dupliquées à l'état de 3NF ( troisième forme normale ).
À partir de ce tableau:
Tableau de données

faisons une telle base de données:
Schéma de connexion DB
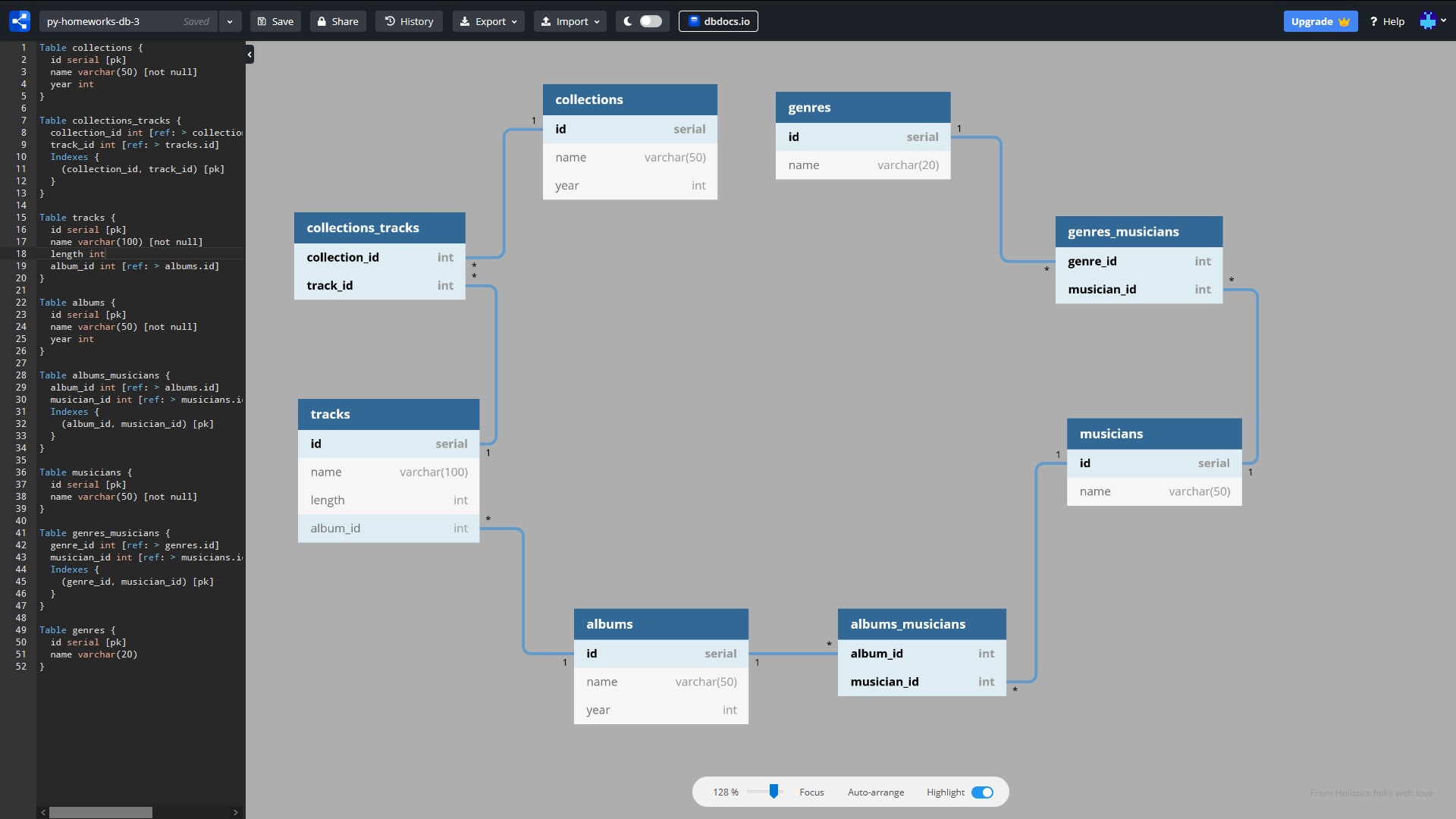
Pour les impatients: le code prêt à fonctionner se trouve dans ce référentiel . Le schéma de base de données interactif est ici . Une feuille de triche pour écrire des requêtes ORM se trouve à la fin de l'article.
Convenons que dans le texte de l'article, nous utiliserons le mot «Table» au lieu de «Relation», et le mot «Champ» au lieu de «Attribut». Lors de l'affectation, nous devons placer une table avec les fichiers musicaux dans la base de données, tout en éliminant la redondance des données. Le tableau d'origine (format CSV) contient les champs suivants (piste, genre, musicien, album, durée, album_year, collection, collection_year). Les liens entre eux sont les suivants:
- chaque musicien peut chanter dans plusieurs genres, ainsi que plusieurs musiciens peuvent se produire dans un genre (relation plusieurs à plusieurs)
- un ou plusieurs musiciens peuvent participer à la création d'un album (relation plusieurs-à-plusieurs)
- une piste appartient à un seul album (relation un à plusieurs)
- les pistes peuvent être incluses dans plusieurs collections (relation plusieurs-à-plusieurs)
- la piste ne peut être incluse dans aucune collection.
Pour plus de simplicité, disons que les noms de genre, les noms d'artistes, les noms d'album et de collection ne sont pas répétés. Les noms de piste peuvent être répétés. Nous avons conçu 8 tables dans la base de données:
- genres (genres)
- genres_musicians (table de préparation)
- musiciens (musiciens)
- albums_musicians (table intermédiaire)
- albums (albums)
- des pistes
- collections_tracks (table de préparation)
- collections (collections)
* ce schéma est un test, tiré de l'un des DZ, il présente quelques inconvénients - par exemple, il n'y a pas de lien entre les pistes et le musicien, ainsi que la piste avec le genre. Mais ce n'est pas essentiel pour l'apprentissage, et nous omettons cet inconvénient.
Pour le test, j'ai créé deux bases de données sur le Postgres local: "TestSQL" et "TestORM", accès à celles-ci: login et test de mot de passe. Écrivons enfin du code!
Créer des connexions et des tables
Créer des connexions à la base de données
* read_data clear_db .
DSN_SQL = 'postgresql://test:test@localhost:5432/TestSQL'
DSN_ORM = 'postgresql://test:test@localhost:5432/TestORM'
# CSV .
DATA = read_data('data/demo-data.csv')
print('Connecting to DB\'s...')
# , .
engine_orm = sa.create_engine(DSN_ORM)
Session_ORM = sessionmaker(bind=engine_orm)
session_orm = Session_ORM()
engine_sql = sa.create_engine(DSN_SQL)
Session_SQL = sessionmaker(bind=engine_sql)
session_sql = Session_SQL()
print('Clearing the bases...')
# . .
clear_db(sa, engine_sql)
clear_db(sa, engine_orm)
Nous créons des tables de manière classique en utilisant SQL
* read_query . .
print('\nPreparing data for SQL job...')
print('Creating empty tables...')
session_sql.execute(read_query('queries/create-tables.sql'))
session_sql.commit()
print('\nAdding musicians...')
query = read_query('queries/insert-musicians.sql')
res = session_sql.execute(query.format(','.join({f"('{x['musician']}')" for x in DATA})))
print(f'Inserted {res.rowcount} musicians.')
print('\nAdding genres...')
query = read_query('queries/insert-genres.sql')
res = session_sql.execute(query.format(','.join({f"('{x['genre']}')" for x in DATA})))
print(f'Inserted {res.rowcount} genres.')
print('\nLinking musicians with genres...')
# assume that musician + genre has to be unique
genres_musicians = {x['musician'] + x['genre']: [x['musician'], x['genre']] for x in DATA}
query = read_query('queries/insert-genre-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, value in genres_musicians.items():
res += session_sql.execute(query.format(value[1], value[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding albums...')
# assume that albums has to be unique
albums = {x['album']: x['album_year'] for x in DATA}
query = read_query('queries/insert-albums.sql')
res = session_sql.execute(query.format(','.join({f"('{x}', '{y}')" for x, y in albums.items()})))
print(f'Inserted {res.rowcount} albums.')
print('\nLinking musicians with albums...')
# assume that musicians + album has to be unique
albums_musicians = {x['musician'] + x['album']: [x['musician'], x['album']] for x in DATA}
query = read_query('queries/insert-album-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, values in albums_musicians.items():
res += session_sql.execute(query.format(values[1], values[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding tracks...')
query = read_query('queries/insert-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['track'], item['length'], item['album'])).rowcount
print(f'Inserted {res} tracks.')
print('\nAdding collections...')
query = read_query('queries/insert-collections.sql')
res = session_sql.execute(query.format(','.join({f"('{x['collection']}', {x['collection_year']})" for x in DATA if x['collection'] and x['collection_year']})))
print(f'Inserted {res.rowcount} collections.')
print('\nLinking collections with tracks...')
query = read_query('queries/insert-collection-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['collection'], item['track'])).rowcount
print(f'Inserted {res} connections.')
session_sql.commit()
En fait, nous créons des répertoires dans des packages (genres, musiciens, albums, collections), puis en boucle nous lions le reste des données et construisons manuellement des tables intermédiaires. Exécutez le code et vérifiez que la base de données a été créée. L'essentiel est de ne pas oublier d'appeler commit () sur la session.
Nous essayons maintenant de faire de même, mais en utilisant l'approche ORM. Afin de travailler avec ORM, nous devons décrire les classes de données. Pour cela, nous allons créer 8 classes (une pour chaque table).
Liste des classes DB
.
Base = declarative_base()
class Genre(Base):
__tablename__ = 'genres'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(20), unique=True)
# Musician genres_musicians
musicians = relationship("Musician", secondary='genres_musicians')
class Musician(Base):
__tablename__ = 'musicians'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
# Genre genres_musicians
genres = relationship("Genre", secondary='genres_musicians')
# Album albums_musicians
albums = relationship("Album", secondary='albums_musicians')
class GenreMusician(Base):
__tablename__ = 'genres_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('genre_id', 'musician_id'),)
#
genre_id = sa.Column(sa.Integer, sa.ForeignKey('genres.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Album(Base):
__tablename__ = 'albums'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
year = sa.Column(sa.Integer)
# Musician albums_musicians
musicians = relationship("Musician", secondary='albums_musicians')
class AlbumMusician(Base):
__tablename__ = 'albums_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('album_id', 'musician_id'),)
#
album_id = sa.Column(sa.Integer, sa.ForeignKey('albums.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Track(Base):
__tablename__ = 'tracks'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(100))
length = sa.Column(sa.Integer)
# album_id ,
album_id = sa.Column(sa.Integer, ForeignKey('albums.id'))
# Collection collections_tracks
collections = relationship("Collection", secondary='collections_tracks')
class Collection(Base):
__tablename__ = 'collections'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50))
year = sa.Column(sa.Integer)
# Track collections_tracks
tracks = relationship("Track", secondary='collections_tracks')
class CollectionTrack(Base):
__tablename__ = 'collections_tracks'
# ,
__table_args__ = (PrimaryKeyConstraint('collection_id', 'track_id'),)
#
collection_id = sa.Column(sa.Integer, sa.ForeignKey('collections.id'))
track_id = sa.Column(sa.Integer, sa.ForeignKey('tracks.id'))
Nous avons juste besoin de créer une classe de base Base pour le style déclaratif de description des tables et d'en hériter. Toute la magie des relations de table réside dans l'utilisation correcte de la relation et de ForeignKey. Le code indique dans quel cas nous créons quelle relation. L'essentiel est de ne pas oublier d'enregistrer la relation des deux côtés de la relation plusieurs-à-plusieurs.
La création directe de tables à l'aide de l'approche ORM se fait en appelant:
Base.metadata.create_all(engine_orm)
Et c'est là que la magie entre en jeu, littéralement toutes les classes déclarées dans le code par héritage de Base deviennent des tables. Immédiatement, je n'ai pas vu comment spécifier les instances de quelles classes devraient être créées maintenant et lesquelles devraient être reportées pour la création plus tard (par exemple, dans une autre base de données). Il existe sûrement un tel moyen, mais dans notre code, toutes les classes héritant de Base sont instanciées en même temps, gardez cela à l'esprit.
Le remplissage des tables à l'aide de l'approche ORM ressemble à ceci:
Remplir les tables avec des données via ORM
print('\nPreparing data for ORM job...')
for item in DATA:
#
genre = session_orm.query(Genre).filter_by(name=item['genre']).scalar()
if not genre:
genre = Genre(name=item['genre'])
session_orm.add(genre)
#
musician = session_orm.query(Musician).filter_by(name=item['musician']).scalar()
if not musician:
musician = Musician(name=item['musician'])
musician.genres.append(genre)
session_orm.add(musician)
#
album = session_orm.query(Album).filter_by(name=item['album']).scalar()
if not album:
album = Album(name=item['album'], year=item['album_year'])
album.musicians.append(musician)
session_orm.add(album)
#
# ,
#
track = session_orm.query(Track).join(Album).filter(and_(Track.name == item['track'],
Album.name == item['album'])).scalar()
if not track:
track = Track(name=item['track'], length=item['length'])
track.album_id = album.id
session_orm.add(track)
# ,
if item['collection']:
collection = session_orm.query(Collection).filter_by(name=item['collection']).scalar()
if not collection:
collection = Collection(name=item['collection'], year=item['collection_year'])
collection.tracks.append(track)
session_orm.add(collection)
session_orm.commit()
Vous devez remplir chaque livre de référence (genres, musiciens, albums, collections) par pièce. Dans le cas des requêtes SQL, il était possible de générer des ajouts de données par lots. Mais les tables intermédiaires n'ont pas besoin d'être créées explicitement; les mécanismes internes de SQLAlchemy en sont responsables.
Requêtes de base de données
Lors de l'affectation, nous devons écrire 15 requêtes en utilisant à la fois les techniques SQL et ORM. Voici une liste des questions posées par ordre de difficulté croissante:
- titre et année de sortie des albums sortis en 2018;
- titre et durée de la plus longue piste;
- le nom des pistes, dont la durée n'est pas inférieure à 3,5 minutes;
- les titres des collections publiées dans la période de 2018 à 2020 inclus;
- les artistes dont le nom se compose d'un mot;
- le nom des pistes qui contiennent le mot «moi».
- le nombre d'interprètes dans chaque genre;
- le nombre de titres inclus dans les albums 2019-2020;
- longueur moyenne des pistes pour chaque album;
- tous les artistes qui n'ont pas sorti d'albums en 2020;
- les titres des collections dans lesquelles un artiste spécifique est présent;
- le nom des albums dans lesquels se trouvent des interprètes de plus d'un genre;
- le nom des pistes qui ne sont pas incluses dans les collections;
- le ou les artistes qui ont écrit la piste la plus courte (en théorie, il peut y en avoir plusieurs);
- le nom des albums contenant le plus petit nombre de pistes.
Comme vous pouvez le voir, les questions ci-dessus impliquent à la fois une sélection et une jonction simples de tables, ainsi que l'utilisation de fonctions d'agrégation.
Vous trouverez ci-dessous des solutions pour chacune des 15 requêtes dans deux options (en utilisant SQL et ORM). Dans le code, les requêtes viennent par paires pour montrer que les résultats sont identiques sur la sortie de la console.
Demandes et leur brève description
print('\n1. All albums from 2018:')
query = read_query('queries/select-album-by-year.sql').format(2018)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).filter_by(year=2018):
print(item.name)
print('\n2. Longest track:')
query = read_query('queries/select-longest-track.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1):
print(f'{item.name}, {item.length}')
print('\n3. Tracks with length not less 3.5min:')
query = read_query('queries/select-tracks-over-length.sql').format(310)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc()):
print(f'{item.name}, {item.length}')
print('\n4. Collections between 2018 and 2020 years (inclusive):')
query = read_query('queries/select-collections-by-year.sql').format(2018, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).filter(2018 <= Collection.year,
Collection.year <= 2020):
print(item.name)
print('\n5. Musicians with name that contains not more 1 word:')
query = read_query('queries/select-musicians-by-name.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Musician).filter(Musician.name.notlike('%% %%')):
print(item.name)
print('\n6. Tracks that contains word "me" in name:')
query = read_query('queries/select-tracks-by-name.sql').format('me')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(Track.name.like('%%me%%')):
print(item.name)
print('Ok, let\'s start serious work')
print('\n7. How many musicians plays in each genres:')
query = read_query('queries/count-musicians-by-genres.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(
Genre.id):
print(f'{item.name}, {len(item.musicians)}')
print('\n8. How many tracks in all albums 2019-2020:')
query = read_query('queries/count-tracks-in-albums-by-year.sql').format(2019, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020):
print(f'{item[0].name}, {item[1].year}')
print('\n9. Average track length in each album:')
query = read_query('queries/count-average-tracks-by-album.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(
Album.id):
print(f'{item[0].name}, {item[1]}')
print('\n10. All musicians that have no albums in 2020:')
query = read_query('queries/select-musicians-by-album-year.sql').format(2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
for item in session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(
Musician.name.asc()):
print(f'{item}')
print('\n11. All collections with musician Steve:')
query = read_query('queries/select-collection-by-musician.sql').format('Steve')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(
Musician.name == 'Steve').order_by(Collection.name):
print(f'{item.name}')
print('\n12. Albums with musicians that play in more than 1 genre:')
query = read_query('queries/select-albums-by-genres.sql').format(1)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(
Genre.name)) > 1).group_by(Album.id).order_by(Album.name):
print(f'{item.name}')
print('\n13. Tracks that not included in any collections:')
query = read_query('queries/select-absence-tracks-in-collections.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
# Important! Despite the warning, following expression does not work: "Collection.id is None"
for item in session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None):
print(f'{item.name}')
print('\n14. Musicians with shortest track length:')
query = read_query('queries/select-musicians-min-track-length.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(func.min(Track.length))
for item in session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(
Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name):
print(f'{item[0].name}, {item[1]}')
print('\n15. Albums with minimum number of tracks:')
query = read_query('queries/select-albums-with-minimum-tracks.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
for item in session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name):
print(f'{item.name}')
Pour ceux qui ne veulent pas se plonger dans la lecture du code, je vais essayer de montrer à quoi ressemble SQL "brut" et son alternative dans une expression ORM, c'est parti!
Aide-mémoire pour faire correspondre les requêtes SQL et les expressions ORM
1. titre et année de sortie des albums 2018:
SQL
select name
from albums
where year=2018
ORM
session_orm.query(Album).filter_by(year=2018)
2. le titre et la durée de la piste la plus longue:
SQL
select name, length
from tracks
order by length DESC
limit 1
ORM
session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1)
3.le nom des pistes dont la durée n'est pas inférieure à 3,5 minutes:
SQL
select name, length
from tracks
where length >= 310
order by length DESC
ORM
session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc())
4. les noms des collections publiées dans la période de 2018 à 2020 inclus:
SQL
select name
from collections
where (year >= 2018) and (year <= 2020)
ORM
session_orm.query(Collection).filter(2018 <= Collection.year, Collection.year <= 2020)
* notez que ci-après, le filtrage est spécifié en utilisant filter, et non en utilisant filter_by.
5. exécuteurs dont le nom se compose de 1 mot:
SQL
select name
from musicians
where not name like '%% %%'
ORM
session_orm.query(Musician).filter(Musician.name.notlike('%% %%'))
6. nom des pistes contenant le mot «moi»:
SQL
select name
from tracks
where name like '%%me%%'
ORM
session_orm.query(Track).filter(Track.name.like('%%me%%'))
7.nombre d'interprètes dans chaque genre:
SQL
select g.name, count(m.name)
from genres as g
left join genres_musicians as gm on g.id = gm.genre_id
left join musicians as m on gm.musician_id = m.id
group by g.name
order by count(m.id) DESC
ORM
session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(Genre.id)
8.nombre de pistes incluses dans les albums 2019-2020:
SQL
select t.name, a.year
from albums as a
left join tracks as t on t.album_id = a.id
where (a.year >= 2019) and (a.year <= 2020)
ORM
session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020)
9. longueur moyenne de la piste pour chaque album:
SQL
select a.name, AVG(t.length)
from albums as a
left join tracks as t on t.album_id = a.id
group by a.name
order by AVG(t.length)
ORM
session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(Album.id)
10.Tous les artistes qui n'ont pas sorti d'albums en 2020:
SQL
select distinct m.name
from musicians as m
where m.name not in (
select distinct m.name
from musicians as m
left join albums_musicians as am on m.id = am.musician_id
left join albums as a on a.id = am.album_id
where a.year = 2020
)
order by m.name
ORM
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(Musician.name.asc())
11.les noms des compilations dans lesquelles un artiste spécifique (Steve) est présent:
SQL
select distinct c.name
from collections as c
left join collections_tracks as ct on c.id = ct.collection_id
left join tracks as t on t.id = ct.track_id
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
where m.name like '%%Steve%%'
order by c.name
ORM
session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(Musician.name == 'Steve').order_by(Collection.name)
12.le nom des albums dans lesquels sont présents des artistes de plus d'un genre:
SQL
select a.name
from albums as a
left join albums_musicians as am on a.id = am.album_id
left join musicians as m on m.id = am.musician_id
left join genres_musicians as gm on m.id = gm.musician_id
left join genres as g on g.id = gm.genre_id
group by a.name
having count(distinct g.name) > 1
order by a.name
ORM
session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(Genre.name)) > 1).group_by(Album.id).order_by(Album.name)
13.Nom des pistes qui ne sont pas incluses dans les collections:
SQL
select t.name
from tracks as t
left join collections_tracks as ct on t.id = ct.track_id
where ct.track_id is null
ORM
session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None)
* Veuillez noter que malgré l'avertissement dans PyCharm, la condition de filtrage doit être composée de cette manière, si vous l'écrivez comme suggéré par l'EDI ("Collection.id is None") alors cela ne fonctionnera pas.
14. artiste (s) qui a écrit la piste la plus courte en longueur (en théorie, il pourrait y en avoir plusieurs):
SQL
select m.name, t.length
from tracks as t
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
group by m.name, t.length
having t.length = (select min(length) from tracks)
order by m.name
ORM
subquery = session_orm.query(func.min(Track.length)) session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name)
15.le nom des albums contenant le moins de pistes:
SQL
select distinct a.name
from albums as a
left join tracks as t on t.album_id = a.id
where t.album_id in (
select album_id
from tracks
group by album_id
having count(id) = (
select count(id)
from tracks
group by album_id
order by count
limit 1
)
)
order by a.name
ORM
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name)
Comme vous pouvez le voir, les questions ci-dessus impliquent à la fois une sélection simple et des tables de jointure, ainsi que l'utilisation de fonctions d'agrégation et de sous-requêtes. Tout cela peut être fait avec SQLAlchemy dans les modes SQL et ORM. La variété d'opérateurs et de méthodes vous permet d'exécuter une requête de n'importe quelle complexité.
J'espère que ce matériel aidera les débutants à rédiger rapidement et efficacement des requêtes.