- article de recherche
- Pytorch : YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7 ( référentiel principal - utilisé pour reproduire les résultats)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- Darknet : YOLOv4-tiny, YOLOv4-CSP, YOLOv4x-MISH
- Structure de YOLOv4-CSP
Le YOLO v4 mis à l'échelle est le réseau de neurones le plus précis ( 55,8% AP ) sur l'ensemble de données Microsoft COCO de tous les réseaux de neurones publiés à ce jour. Et c'est aussi le meilleur en termes de rapport vitesse / précision sur toute la plage de précision et de vitesse de 15 FPS à 1774 FPS . Pour le moment, il s'agit du réseau neuronal Top1 pour la détection d'objets.
Le YOLO v4 mis à l'échelle surpasse les réseaux de neurones en précision:
- Google EfficientDet D7x / DetectoRS ou SpineNet-190 (auto-formé sur des données supplémentaires)
- Amazon Cascade-RCNN ResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
Nous montrons que les approches YOLO et Cross-Stage-Partial (CSP) sont les meilleures en termes de précision absolue et de rapport précision / vitesse.
Tracé de précision (axe vertical) et de latence (axe horizontal) sur le GPU Tesla V100 (Volta) avec batch = 1 sans utiliser TensorRT:
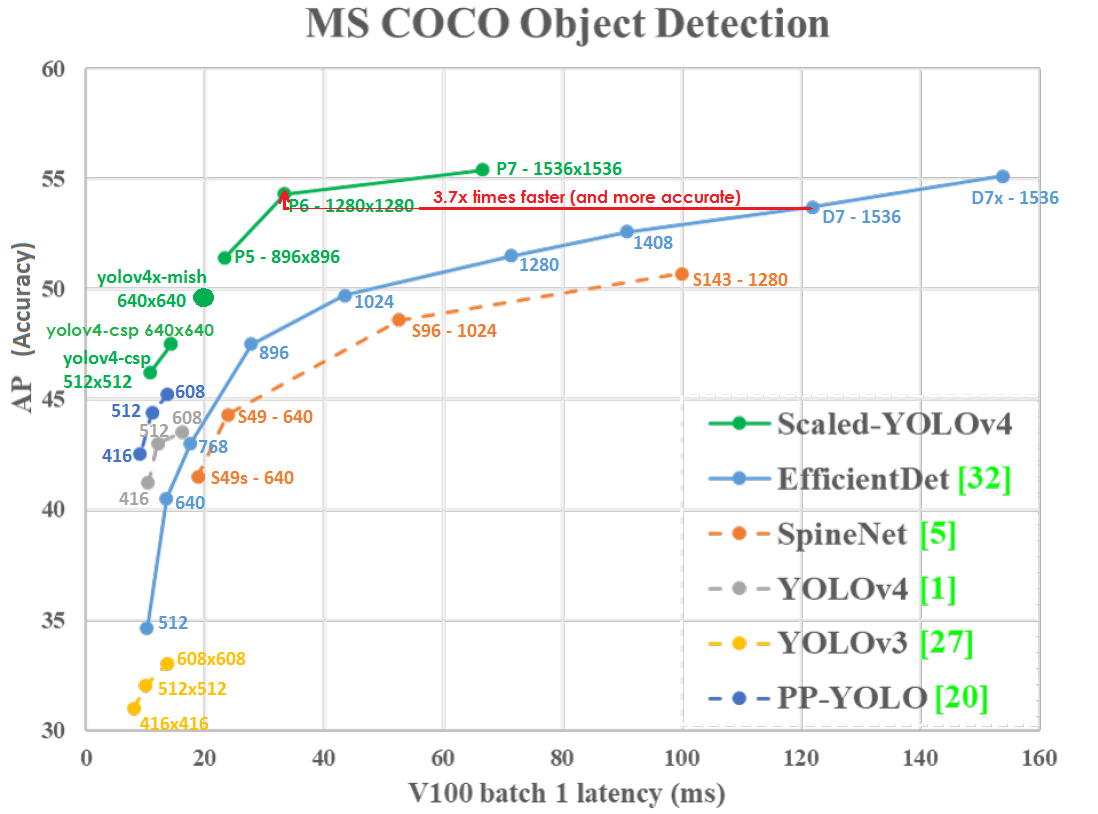
Même à une résolution réseau inférieure, Scaled-YOLOv4-P6 (1280x1280) 30 FPS est légèrement plus précis et 3,7 fois plus rapide que EfficientDetD7 (1536x1536) 8,2 FPS. Ceux. YOLOv4 utilise la résolution du réseau plus efficacement.
Le YOLO v4 mis à l'échelle se trouve sur la courbe d' optimalité de Pareto - quel que soit l'autre réseau de neurones que vous utilisez, il existe toujours un tel réseau YOLOv4, qui est soit plus précis à la même vitesse, soit plus rapide avec la même précision, c'est-à-dire YOLOv4 est le meilleur en termes de vitesse et de précision.
Le YOLOv4 mis à l'échelle est plus précis et plus rapide que les réseaux de neurones:
- Google EfficientDet D0-D7x
- Google SpineNet S49s - S143
- Pagaie Baidu PP YOLO
- Et plein d'autres
Scaled YOLO v4 est une série de réseaux neuronaux construits à partir du réseau YOLOv4 amélioré et mis à l'échelle. Notre réseau neuronal a été formé à partir de zéro sans utiliser de poids pré-entraînés (Imagenet ou tout autre).
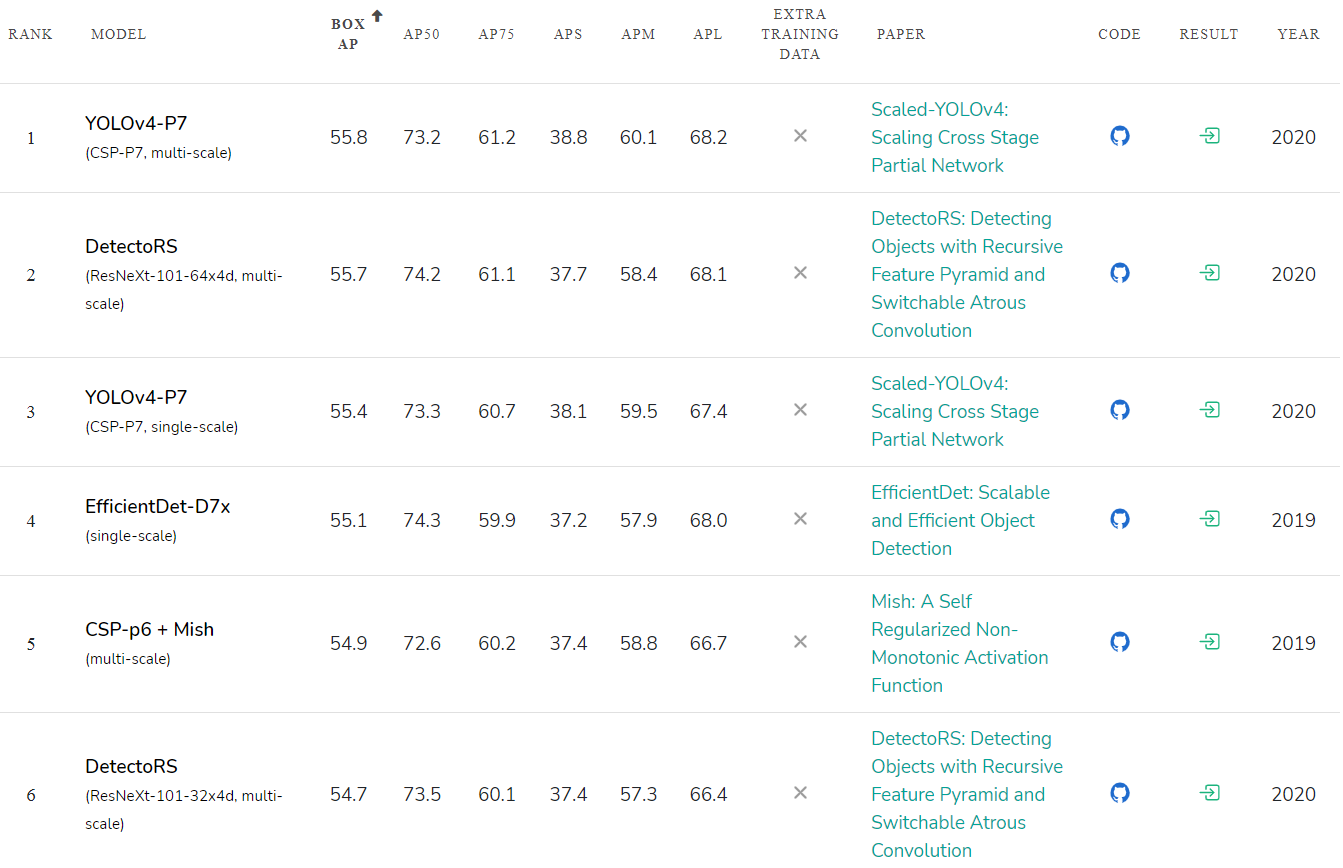
Évaluation de la précision des réseaux de neurones publiés: paperswithcode.com/sota/object-detection-on-coco :
la vitesse du réseau de neurones YOLOv4-tiny atteint 1774 FPS sur un GPU de jeu RTX 2080Ti utilisant TensorRT + tkDNN (batch = 4, FP16): github. com / ceccocats / tkDNN
YOLOv4-tiny peut fonctionner en temps réel à 39 FPS / 25ms de latence sur JetsonNano (416x416, fp16, batch = 1) tkDNN / TensorRT:

Scaled YOLOv4 utilise les ressources d'ordinateurs parallèles tels que les GPU et les NPU de manière beaucoup plus efficace. Par exemple, le GPU V100 (Volta) a des performances: 14 TFLops - 112 TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
Si nous testons les deux modèles sur GPU V100 avec batch = 1 , avec les paramètres --hparams = mixed_precision = true et sans --tensorrt = FP32 , alors:
- YOLOv4-CSP (640x640) - 47,5% AP - 70 FPS - 120 BFlops (60 FMA)
Sur la base des BFlops, il devrait être 933 FPS = (112000/120), mais en réalité, nous obtenons 70 FPS, c'est-à-dire utilisé 7,5% GPU = (70/933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
BFlops, 2240 FPS = (112 000 / 50), 36 FPS, .. 1.6% GPU = (36 / 2240)
Ceux. efficacité des opérations de calcul sur les appareils avec un calcul parallèle massif tels que les GPU utilisés dans YOLOv4-CSP (7,5 / 1,6) = 4,7 fois meilleure que l'efficacité des opérations utilisées dans EfficientDetD3.
Habituellement, les réseaux de neurones sont exécutés sur le processeur uniquement dans les tâches de recherche pour un débogage plus facile, et la fonctionnalité BFlops n'a actuellement qu'un intérêt académique. Dans les tâches du monde réel, la vitesse et la précision réelles sont importantes, et non les performances sur papier. La vitesse réelle du YOLOv4-P6 est 3.7x plus rapide que celle de EfficientDetD7 sur le GPU V100. Par conséquent, les appareils à parallélisme massif GPU / NPU / TPU / DSP sont presque toujours utilisés avec beaucoup plus d'optimisation: vitesse, prix et dissipation thermique:
- GPU intégré (Jetson Nano / Nx)
- Mobile-GPU / NPU / DSP (Bionic-NPU / Snapdragon-DSP / Mediatek-APU / Kirin-NPU / Exynos-GPU / ...)
- TPU-Edge (Google Coral / Intel Myriad / Mobileye EyeQ5 / Tesla-moteurs TPU 144 TOPS-8bit)
- GPU cloud (nVidia A100 / V100 / TitanV)
- Cloud NPU (Google-TPU, Huawei Ascend, Intel Habana, Qualcomm AI 100, ...)
Aussi lors de l'utilisation de réseaux de neurones sur le Web - généralement le GPU est utilisé via les bibliothèques WebGL, WebAssembly, WebGPU, dans ce cas - la taille du modèle peut avoir de l'importance: github.com/tensorflow/tfjs#about-this-repo
Utilisation d'appareils et d'algorithmes avec des le parallélisme est une voie sans issue du développement, car il est impossible de réduire la taille de la lithographie plus petite que la taille d'un atome de silicium pour augmenter la fréquence du processeur:
- La meilleure taille actuelle pour la fabrication de dispositifs semi-conducteurs est de 5 nanomètres.
- La taille du réseau cristallin du silicium est de 0,5 nanomètre.
- Le rayon atomique du silicium est de 0,1 nanomètre.
La solution est des ordinateurs à parallélisme massif: sur un monocristal ou sur plusieurs cristaux reliés par un interposeur. Par conséquent, il est impératif de créer des réseaux de neurones qui utilisent efficacement des machines informatiques massivement parallèles telles que les GPU et les NPU.
Améliorations de YOLOv4 mis à l'échelle par rapport à YOLOv4:
- YOLOv4 mis à l'échelle a utilisé des techniques de mise à l'échelle du réseau optimales pour obtenir les réseaux YOLOv4-CSP -> P5 -> P6 -> P7
- Architecture réseau améliorée: Backbone est optimisé et Neck (PAN) utilise les connexions Cross-stage-partial (CSP) et l'activation Mish
- La moyenne mobile exponentielle (EMA) est utilisée pendant l'entraînement - c'est un cas particulier de SWA: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- Pour chaque résolution du réseau, un réseau neuronal distinct est formé (dans YOLOv4, un seul réseau neuronal a été formé pour toutes les résolutions)
- Normaliseurs améliorés dans les couches [yolo]
- Activations modifiées pour la largeur et la hauteur, ce qui permet un entraînement réseau plus rapide
- Utilisez le paramètre [net] letter_box = 1 (préserve le rapport hauteur / largeur de l'image d'entrée) pour les réseaux haute résolution (pour tous sauf yolov4-tiny.cfg)
Architecture de réseau neuronal Scaled-YOLOv4 (exemples de trois réseaux: P5, P6, P7): La

connexion CSP est très efficace, simple et peut être appliquée à tous les réseaux neuronaux. L'essentiel est que
- la moitié du signal de sortie suit le chemin principal (générant plus d'informations sémantiques avec un grand champ récepteur)
- et l'autre moitié du signal suit un détour (en gardant plus d'informations spatiales avec un petit champ réceptif)
L'exemple le plus simple d'une connexion CSP (à gauche est un réseau régulier, à droite un réseau CSP):

Un exemple de connexion CSP dans YOLOv4-CSP / P5 / P6 / P7
(à gauche est un réseau régulier, à droite un réseau CSP):

Dans YOLOv4-tiny il y a 2 connexions CSP :

YOLOv4 est utilisé dans divers domaines et tâches:
- Gouvernement taïwanais: Contrôle du trafic www.taiwannews.com.tw/en/news/3957400 et youtu.be/IiU6wFmfVnk
- Amazon: Instances Anti-Covid19 Distance-assistant github.com/amzn/distance-assistant et Amazon Neurochip / Amazon EC2 Inf1: aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning- détection-d'objets-basée-avec-un-neurone-aws-compilé-yolov4-model-on-aws-inferentia
- Laboratoire d'innovation BMW: github.com/BMW-InnovationLab
Et dans de nombreuses autres tâches….
Il existe des implémentations dans différents frameworks:
- Pytorch : github.com/WongKinYiu/ScaledYOLOv4
- Darknet : github.com/AlexeyAB/darknet
- TensorFlow : github.com/hunglc007/tensorflow-yolov4-tflite
- o pip installer yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- La structure du réseau peut être visualisée à l'aide de l'utilitaire Netron - Visualizer for neural networks: github.com/lutzroeder/netron
Comment compiler et exécuter Cloud Object Detection gratuitement :
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- vidéo: www.youtube.com/watch?v=mKAEGSxwOAY
Comment compiler et exécuter gratuitement Training in the Cloud :
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- vidéo: youtu.be/mmj3nxGT2YQ
De plus, l'approche YOLOv4 peut être utilisée dans d'autres tâches, par exemple lors de la détection d'objets 3D:
- Code - Complex-YOLOv4 (5-DOF): github.com/maudzung/Complex-YOLOv4-Pytorch
- Code - YOLO3D-YOLOv4 (7-DOF): github.com/maudzung/YOLO3D-YOLOv4-PyTorch
