Il se trouve qu'en 1998, je suis entré à l'école supérieure de l'Académie agricole d'État russe et j'ai choisi l'IA / ML comme sujet de mon travail scientifique. Ce sont les moments difficiles de la prochaine ère glaciaire des réseaux de neurones. C'est à cette époque que Yang Lecun a publié son célèbre ouvrage «Gradient-Based Learning Applied to Document Recognition» sur les principes d'organisation des réseaux convolutifs, ce qui, à mon avis, n'était que le début d'un nouveau dégel. C'est drôle qu'à ce moment-là je travaillais sur des éléments similaires, c'est vrai qu'ils disent que l'idée, le moment venu, est dans l'air. Cependant, tout le monde n'est pas donné pour lui donner vie. Malheureusement, je n'ai jamais terminé mon travail avant la défense, mais j'ai toujours voulu le terminer un jour.
La source:Hitecher
Et maintenant, après 20 ans, quand j'ai commencé à travailler comme enseignant à la Southern Federal University et en même temps à enseigner dans le programme de formation complémentaire "Samsung IT School", j'ai eu une seconde chance. Samsung a proposé à SFedU d'être le premier à lancer le parcours de formation «Samsung IT Academy» sur l'intelligence artificielle pour les bacheliers et masters. Je craignais qu'il ne soit possible de mettre en œuvre l'intégralité du programme, mais j'ai répondu avec enthousiasme à l'offre de lire le cours. J'ai réalisé que le cercle était fermé et que j'avais encore une seconde chance de faire ce que j'avais échoué une fois. Il convient de noter ici que le cours Samsung AI / ML est l'un des meilleurs cours de langue russe actuellement ouverts et disponibles gratuitement sur la plateforme Stepik ( https://stepik.org/org/srr). Cependant, dans le cas d'un programme universitaire, en plus du cours théorique / pratique, la partie projet a été ajoutée. Autrement dit, le programme annuel de "Samsung IT Academy" a été considéré comme maîtrisé dans le cas de l'étude de deux modules "Réseaux de neurones et vision par ordinateur", "Réseaux de neurones et traitement de texte" avec la réception des certificats Stepik correspondants, ainsi que la mise en œuvre d'un projet individuel. Le cours s'est terminé par la défense des projets d'étudiants, auxquels des experts ont été invités, incl. employés du Centre de Moscou pour l'intelligence artificielle Samsung.
Et depuis septembre 2019, nous avons commencé une formation à l'Institut des Hautes Technologies et Piezotechniques de la SFedU. Bien sûr, un assez grand nombre d'étudiants sont venus au HYIP et par la suite il y a eu un sérieux abandon. Le programme n'était pas si compliqué, mais volumineux - des connaissances étaient nécessaires:
- algèbre linéaire,
- théorie des probabilités,
- calculs différentiels,
- le langage de programmation Python.
Bien entendu, toutes les connaissances et compétences requises ne vont pas au-delà du cursus du programme de 3ème année de premier cycle de l'université. Je vais donner quelques exemples, parmi ceux qui sont plus compliqués:
- Trouvez la dérivée de la fonction d'activation de la tangente hyperbolique
 et exprimez le résultat en termes de...
et exprimez le résultat en termes de...
- Trouvez le dérivé de la fonction d'activation sigmoïde
 et exprimez le résultat en termes de sigmoïde...
et exprimez le résultat en termes de sigmoïde...
- Dans le graphique des calculs illustré à la Fig. 1 présente une fonction complexe avec paramètres ... Pour plus de commodité, ajout des résultats intermédiaires des opérations... Il est nécessaire de déterminer à quoi le dérivé sera égal par paramètre

Pour être honnête, j'ai étudié à la hâte quelque chose, en particulier à partir d'algorithmes modernes pour travailler avec des réseaux de neurones, avec des étudiants. Au départ, on supposait que les étudiants eux-mêmes étudieraient les conférences vidéo du cours en ligne Samsung sur Stepik, et en classe, nous ne ferions que des ateliers. Cependant, j'ai pris la décision de lire également la théorie. Cette décision est due au fait qu'avec l'enseignant, vous pouvez régler un sujet incompréhensible, discuter des idées qui ont surgi, etc. Les étudiants ont reçu des tâches pratiques sous forme de devoirs. L'approche s'est avérée correcte - dans la classe, une atmosphère animée a été obtenue, j'ai vu que les élèves en général réussissaient assez bien à maîtriser le matériel.
Un mois plus tard, nous sommes passés en douceur du modèle neuronal aux premières architectures simples entièrement connectées, de la simple régression à la classification multi-classes, du simple calcul de gradient aux algorithmes d'optimisation de descente de gradient SGD, ADAM, etc. Nous avons terminé la première moitié du cours avec des réseaux convolutifs et des architectures modernes de réseau profond. La tâche finale du premier module de Computer Vision était de participer au concours " Dirty vs Cleaned " chez Kaggle, en dépassant le seuil de précision de 80%.
Autre facteur, à mon avis, important: nous n'étions pas enfermés à l'intérieur de l'université. Les organisateurs de la piste ont organisé des webinaires et des master classes pour nous avec des experts invités des laboratoires Samsung. De tels événements ont accru la motivation des étudiants, et la mienne, pour être honnête :). Par exemple, il y a eu un événement d'orientation de carrière intéressant - un pont en ligne entre les salles de classe de la SFedU, de l'Université d'État de Moscou et de Samsung, où les employés du centre d'IA de Moscou Samsung ont parlé des tendances modernes en matière de développement de l'IA / ML et ont répondu aux questions des étudiants.
La deuxième partie du cours, consacrée au traitement de texte, a débuté par une théorie générale de l'analyse linguistique. Ensuite, les étudiants ont été initiés aux modèles de texte vectoriel et TF-IDF, puis à la sémantique de distribution et à word2vec. Sur la base des résultats, plusieurs ateliers intéressants ont été organisés: générer des embeddings word2wec, générer des noms et des slogans. Ensuite, nous sommes passés à la théorie et à la pratique de l'utilisation de réseaux convolutifs et récurrents pour l'analyse de texte.
Bien que le point soit oui, j'ai publié un article dans le journal VAK et j'ai commencé à préparer le suivant, rassemblant progressivement du matériel pour une nouvelle thèse. Mes élèves ne sont pas restés immobiles non plus, mais ont commencé à travailler sur leurs premiers projets. Les étudiants ont choisi eux-mêmes les sujets et, par conséquent, ils ont obtenu 7 projets de fin d'études dans différents domaines d'application des réseaux de neurones:
- « » , .
- « » .
- « » .
- « » .
- « » .
- « » .
- « » , .

Tous les projets ont été défendus, mais le degré de complexité et de sophistication était différent, ce qui, à juste titre, se reflétait dans les estimations des projets. Sur la base des résultats de la défense, quatre projets ont été sélectionnés pour le concours annuel de la Samsung IT Academy . Et je peux dire avec fierté que le jury a attribué à deux de nos projets les premières places. Ci-dessous, je vais donner une brève description de ces projets, basée sur les matériaux fournis par mes étudiants Grateful Alexander, Krikunov Stanislav et Pandov Vyacheslav, pour lesquels un grand merci à eux. Je pense que les solutions qu'ils ont démontrées peuvent très bien être évaluées comme un travail de recherche sérieux.
1ère place à la nomination "Intelligence Artificielle" du concours "Samsung IT Academy".
"Surveillance de l'activité physique humaine", Alexander Grateful, Stanislav Krikunov
Le projet consistait à créer une application mobile qui identifie et quantifie l'activité physique à l'entraînement à l'aide de capteurs de téléphone mobile. Il existe désormais de nombreuses applications mobiles capables de reconnaître l'activité physique d'une personne: Google Fit, Nike Training Club, MapMyFitness et autres. Cependant, ces applications ne peuvent pas reconnaître certains types d'exercices et compter le nombre de répétitions.
L'un des auteurs du projet, Grateful Alexander, mon diplômé 2015 du programme Samsung IT School, et moi, non sans fierté, étions heureux que les connaissances acquises dans le développement mobile à l'école aient été appliquées de cette manière.
Comment l'activité physique est-elle reconnue? Commençons par la façon dont le moment de l'exercice est déterminé. Pour détecter le début et la fin des exercices, les élèves ont décidé d'utiliser le module d'accélération, calculé comme la racine de la somme des carrés des accélérations le long des axes. Un certain seuil a été choisi, avec lequel la valeur d'accélération actuelle a été comparée. Si le seuil est dépassé (la dérivée de l'accélération est positive), alors on considère que l'exercice a commencé. Si l'accélération actuelle est inférieure au seuil (la dérivée de l'accélération est négative), alors on considère que l'exercice est terminé. Malheureusement, cette approche ne permet pas de traitement en temps réel. Une amélioration possible est l'application d'une fenêtre glissante sur les données avec le calcul du résultat à chaque pas de décalage.
L'ensemble de données a été collecté par les auteurs eux-mêmes. Lors de la réalisation de 7 exercices différents, 3 types de smartphones ont été utilisés (versions Android 4.4, 9.0, 10.0). Le smartphone était attaché à la main à l'aide d'une poche spéciale. Un total de 1800 répétitions a été effectué par trois volontaires. Pendant l'exécution, des erreurs dans la technique peuvent survenir pour n'importe quelle raison, par conséquent, la procédure de nettoyage de l'échantillon a été effectuée. Pour cela, les distributions de corrélations croisées ont été construites pour tous les types d'exercices. Ensuite, pour chaque exercice, un seuil de corrélation a été sélectionné, en dessous duquel l'exercice est considéré comme inapproprié et est exclu de l'échantillon.
Le même exercice, selon la répétition, a un temps d'exécution différent. Pour lutter contre cela, il a été décidé d'interpoler les données avec un nombre fixe d'échantillons, quel que soit le nombre provenant des capteurs. Reçu 50 - double le taux d'échantillonnage, calcul des positions intermédiaires comme moyenne arithmétique des voisines. Reçu 200 - défaussez tous les 2 points. Dans ce cas, le nombre d'échantillons sera constant. De même, pour tout rapport du nombre d'échantillons d'entrée au nombre de sortie souhaité.
Pour le réseau neuronal, il a été décidé d'appliquer des données dans le domaine fréquentiel. Étant donné que le poids corporel d'une personne est assez élevé, on peut s'attendre à ce que les fréquences de signal caractéristiques se situent dans la région des basses fréquences du spectre dans la plupart des exercices standard. Dans ce cas, les hautes fréquences peuvent être considérées soit comme une gigue lors de l'exécution, soit comme un bruit provenant des capteurs. Qu'est-ce que ça veut dire? Cela signifie que nous pouvons trouver le spectre du signal à l'aide de la FFT et n'utiliser que 10 à 20% des données pour l'analyse. Pourquoi si peu? Puisque 1) le spectre est symétrique, vous pouvez immédiatement couper la moitié des composants 2) les informations de base - seulement 20 à 40% de la partie informative du spectre. Ces hypothèses décrivent particulièrement bien les exercices de musculation lents.
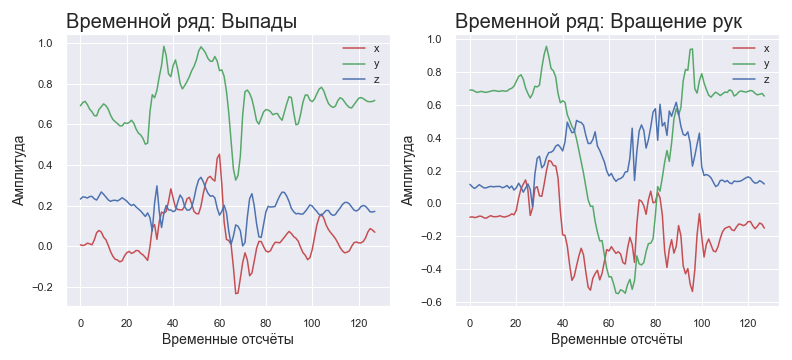
Série chronologique normalisée pour différents exercices
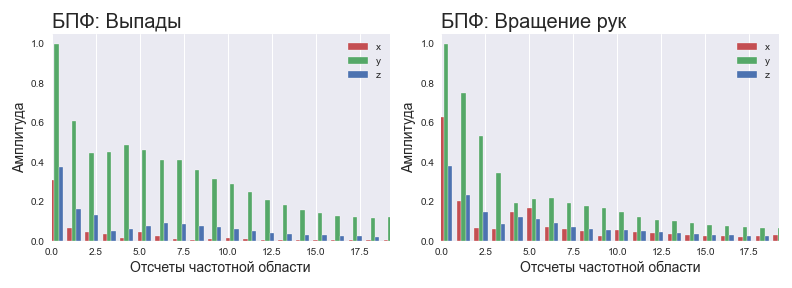
Spectre normalisé pour différents exercices
Avant le traitement par le réseau neuronal, le spectre de données est normalisé à la valeur maximale parmi les trois axes afin d'ajuster tous les échantillons d'exercice dans la plage d'amplitudes 0-1. Dans ce cas, les proportions entre les axes sont conservées.
Le réseau neuronal effectue la tâche de classification des exercices. Cela signifie qu'il produit un vecteur de probabilités pour tous les exercices à partir de la liste par laquelle il a été entraîné. L'indice de l'élément maximum dans ce vecteur est le numéro de l'exercice effectué. De plus, si la confiance dans l'exercice effectué est inférieure à 85%, on considère qu'aucun des exercices n'a été réalisé. Le réseau se compose de 3 couches: 4 convolutives, 3 entièrement connectées, le nombre de neurones de sortie est égal au nombre d'exercices que nous voulons reconnaître. Dans l'architecture, pour économiser les ressources de calcul, seules les convolutions avec une taille de cœur de 3x3 sont utilisées. L'architecture relativement simple du réseau se justifie par les ressources informatiques limitées des smartphones; dans notre tâche, une reconnaissance avec un délai minimum est nécessaire.

Description de l'architecture du réseau neuronal
La stratégie d'apprentissage du réseau neuronal est un entraînement par époques à l'aide de la normalisation par lots des données d'apprentissage jusqu'à ce que la fonction de perte sur l'échantillon d'apprentissage atteigne sa valeur minimale.
Résultats: avec des performances d'exercice plus ou moins de haute qualité, la confiance du réseau est de 95 à 99%. Sur l'ensemble de validation, la précision était de 99,8%.
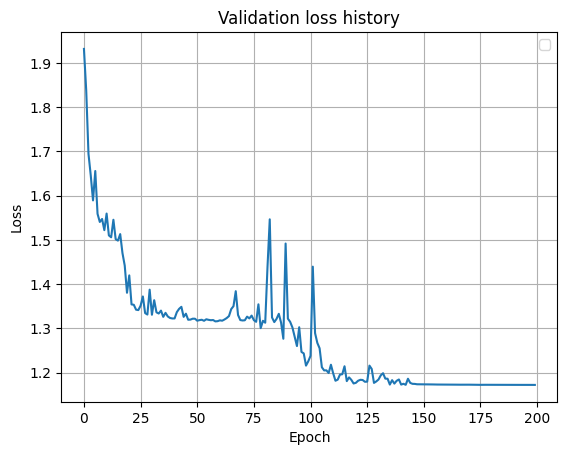
Erreur lors de la formation sur un ensemble de validation

Matrice d'erreur pour un
réseau de neurones Le réseau de neurones a été intégré dans une application mobile et a montré des résultats similaires à ceux de la formation.
L'étude a également testé d'autres modèles d'apprentissage automatique utilisés aujourd'hui pour résoudre des problèmes de classification: régression logistique, forêts aléatoires, XG Boost. Pour ces architectures, la régularisation de Tikhonov (L2), la validation croisée et la recherche de grille ont été utilisées pour trouver les paramètres optimaux. En conséquence, les indicateurs d'exactitude étaient les suivants:
- Régression logistique: 99,4%
- Forêts aléatoires: 99,1%
- Boost XG: 97,5%
Les connaissances acquises lors de la formation à la Samsung IT Academy ont aidé les auteurs du projet à élargir les horizons de leurs intérêts et ont apporté une contribution inestimable lors de leur inscription au programme de maîtrise à l'Institut des sciences et technologies de Skolkovo. En ce moment, mes étudiants y font des recherches dans le domaine de l'apprentissage automatique des systèmes de communication.
Code sur GitHub
II « » «IT Samsung».
« »,
Le travail du modèle est bien décrit sur cette diapositive:

tout commence par une photographie. Dans l'implémentation présentée, il provient d'un bot Telegram. En l'utilisant, Dlib frontal_face_detector trouve tous les visages de l'image. Ensuite, 68 points 2D clés de chaque face sont détectés à l'aide de Dlib shape_predictor_68_face_landmarks. Chaque ensemble est normalisé comme suit: centré (en soustrayant la moyenne de X et Y) et mis à l'échelle (en divisant par le maximum absolu de X et Y). Chaque coordonnée du point normalisé appartient à l'intervalle [-1, +1].
Ensuite, le réseau neuronal entre en jeu, qui prédit la profondeur de chaque point clé du visage - la coordonnée Z, en utilisant les coordonnées normalisées (X, Y). Ce modèle a été formé sur l'ensemble de données AFLW2000.
En outre, ces points sont connectés les uns aux autres, formant un masque maillé. On peut aussi l'appeler biométrie faciale. Les longueurs des segments d'un tel masque sont utilisées comme l'un des moyens de définir les émotions. L'idée est que chaque segment de ligne a sa propre place dans le vecteur de segment de ligne et certains d'entre eux en fonction de l'émotion. Et chaque émotion, en théorie, a un nombre limité de tels vecteurs. Cette hypothèse a été confirmée au cours des expériences. Pour former un tel modèle, les ensembles de données suivants ont été utilisés: Cohn-Kanade +, JAFFE, RAF-DB.
En parallèle, un autre réseau apprend à classer les émotions par l'image elle-même. Les images de visage sont découpées dans les rectangles trouvés avec Dlib. Converti en noir et blanc monocanal et compressé en 48x48. Pour entraîner ce modèle, les mêmes ensembles de données ont été utilisés que pour le modèle biométrique. Cependant, l'ensemble de données FER2013 a également été utilisé.
En conclusion, le troisième réseau de neurones entre en fonctionnement, dont l'architecture combine les deux précédents réseaux figés et pré-entraînés avec une couche entraînée. Ces réseaux remplacent également les dernières couches entièrement connectées. Au lieu du "vecteur de probabilités" attendu par lequel la classe cible peut être déterminée, plus de "caractéristiques de bas niveau" sont maintenant renvoyées. Et la couche unificatrice est formée pour interpréter ces informations dans la classe cible.
Parmi les «solutions similaires» figurent les suivantes: EmoPy, DLP-CNN (RAF-DB), FER2013, EmotioNet. Cependant, il est difficile de faire des comparaisons car ils ont été formés sur différentes données.
Code sur GitHub
Conclusion
En conclusion, je voudrais dire que le cours pilote a fait ses preuves et qu'en cette année universitaire 2020/21, le programme est déjà enseigné dans 23 universités, partenaires de la Samsung IT Academy en Russie et au Kazakhstan. La liste complète peut être consultée ici . Cette année, un groupe de maîtres et de bacheliers étudie déjà avec nous (il y a même un doctorat entier dans le groupe!) Et jusqu'à présent, dans la masse, le granit de la science ronge avec succès. Des idées pour un projet individuel n'ont pas encore été trouvées, mais les étudiants sont pleins d'optimisme. Bien sûr, lors du prochain concours de projets individuels, le concours décuplera, mais nous espérons continuer à recevoir des notes élevées pour les réalisations de nos étudiants. Et surtout, je suis sûr que les connaissances et l'expérience acquises seront d'une grande aide pour nos diplômés dans leur développement futur dans le domaine de l'informatique.
2020 Rostov-sur-le-Don. SFedU, Samsung IT Academy.

Dmitry Yatsenko
Maître de conférences au Département des technologies de l'information et de la mesure, Faculté des hautes technologies, Université fédérale du Sud,
Maître de conférences à la Samsung IT School,
Professeur de la piste AI IT à la Samsung Academy.