- Bonjour à tous, je m'appelle Lesha, je suis développeur frontend. Commençons. Je vais vous parler un peu de moi et du projet dans lequel je travaille. Flow apprend l'anglais avec Yandex.Practicum. La sortie a eu lieu en avril de cette année. Le front était écrit directement en TypeScript, auparavant il n'y avait pas de code.
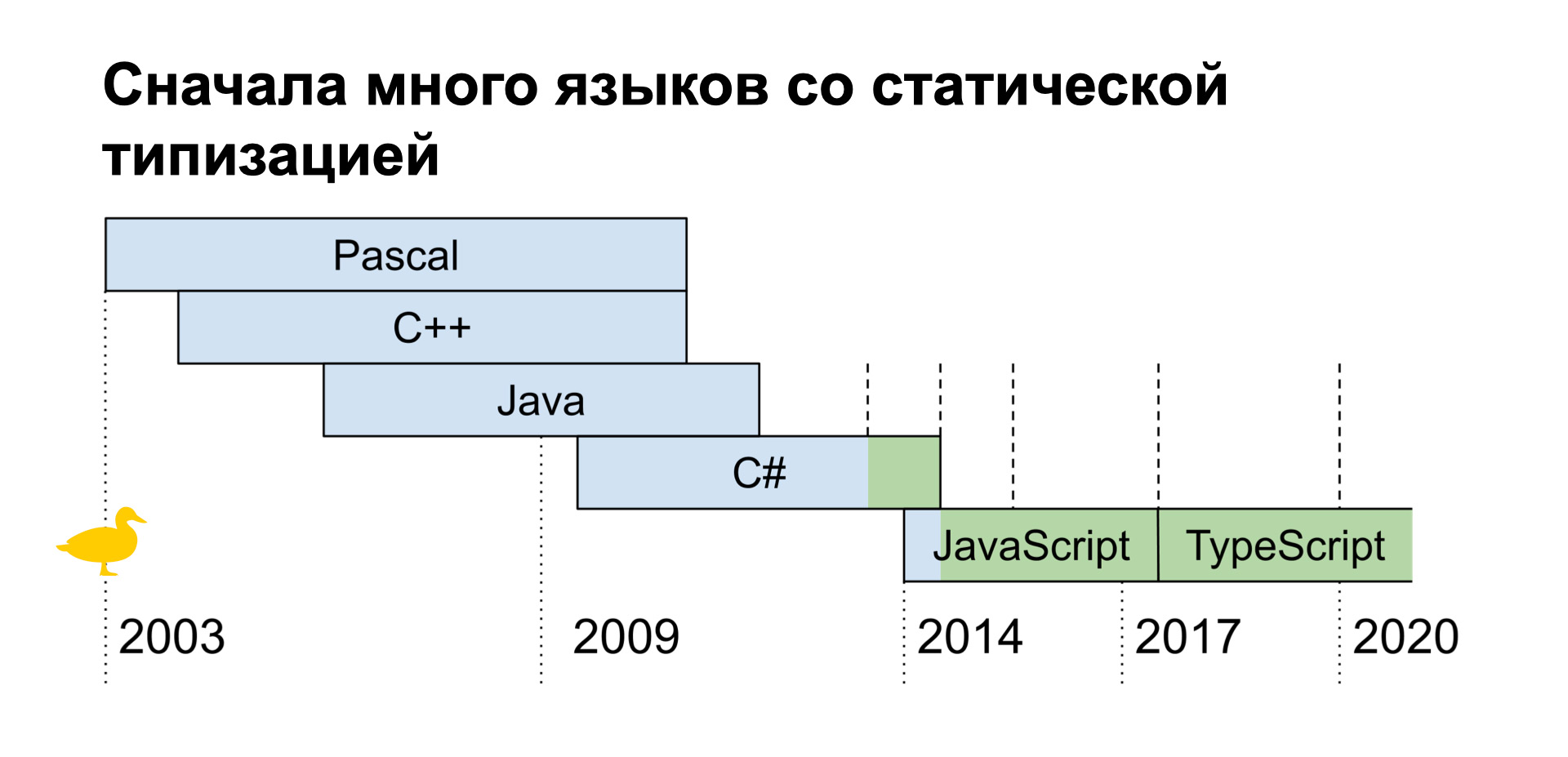
Un peu de mon expérience. Dans une année lointaine, j'ai commencé à programmer. Un an en 2013, il a commencé à travailler.
Presque aussitôt, j'ai réalisé que j'étais beaucoup plus intéressé par le front, mais j'avais de l'expérience avec les langues à typage statique. J'ai commencé à utiliser JavaScript et ce typage statique n'était pas là. Cela me paraissait pratique, j'aimais ça.
Lors d'un changement de projet, j'ai commencé à travailler avec TypeScript. Je vais vous parler des avantages que j'ai réalisés en passant à TypeScript. Plus facile à comprendre le projet. Nous avons une description des types de données qui sont utilisés dans le projet et les conversions entre eux.

Il est plus sûr d'apporter des modifications au code: lorsqu'il y a des modifications dans le backend ou juste une partie du code, TypeScript mettra en évidence les endroits où des erreurs sont apparues.
Les types sont moins préoccupés. Lorsque nous créons de nouvelles fonctionnalités, nous définissons immédiatement les types avec lesquels les fonctions fonctionnent, et nous pouvons être moins inquiets de recevoir des données différentes.
Il n'y a aucune crainte que nul ou indéfini ne vienne, nous n'avons pas besoin d'être paranoïaques, d'insérer si inutile et des constructions similaires.

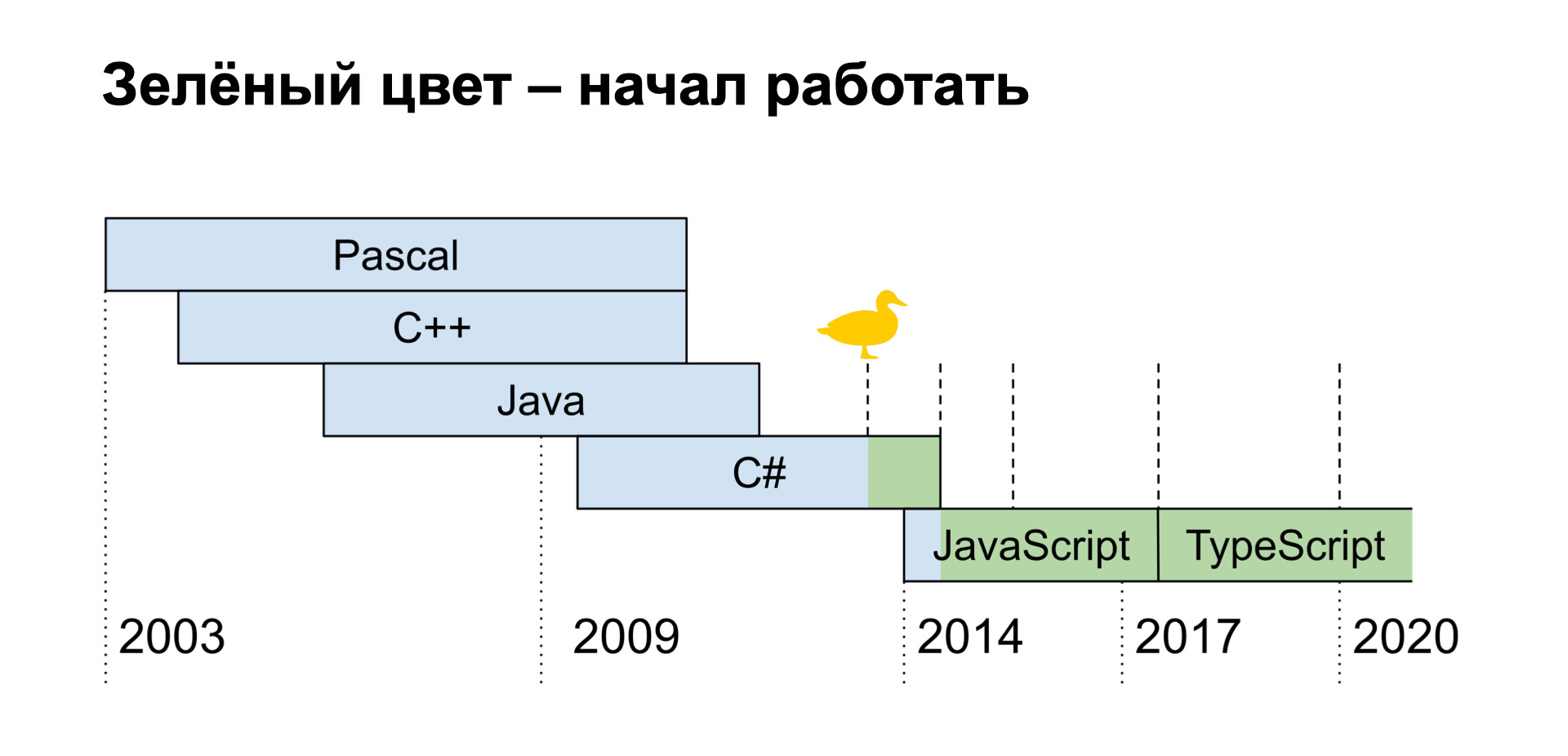
Au début de cette année, j'ai rejoint Flow. TypeScript est également utilisé ici, mais je ne l'ai pas reconnu un peu. Pourquoi? Il était trop gentil avec moi, un quart des erreurs des clients étaient liées à des valeurs nulles et indéfinies. J'ai commencé à comprendre ce qui se passait et j'ai trouvé une ligne dans la configuration qui a changé tout le comportement de TypeScript.

C'est l'inclusion de strict. Ce n'était pas là, mais il fallait l'activer pour améliorer la vérification.
TypeScript: strict
Qu'est-ce qui est strict? En quoi cela consiste?

Il s'agit d'un ensemble d'indicateurs qui peuvent être activés individuellement, mais à mon avis, ils sont tous très utiles. noImplicitAny - avant d'activer cet indicateur, nous pouvons déclarer, par exemple, des fonctions dont les paramètres seront implicites, comme any. Si nous activons cet indicateur, nous devons ajouter la saisie aux endroits où TypeScript ne peut pas calculer le type à partir du contexte.
Autrement dit, dans le second cas, il faut ajouter du typage, car il n'y a pas de contexte en tant que tel. Dans le troisième cas, où nous avons une carte, nous ne pouvons pas ajouter de typage pour a, car il est clair d'après le contexte qu'il y aura un type de nombre.

noImplicitThis. TypeScript nous oblige à taper ceci lorsqu'il n'y a pas de contexte. Lorsque le contexte est, c'est-à-dire qu'il s'agit d'un objet ou d'une classe, nous n'avons pas besoin de le faire.

alwaysStrict. Ajoute «use strict» à chaque fichier. Mais cela affecte la façon dont JavaScript exécute notre code. (...)

strictBindCallApply. Pour une raison quelconque, avant d'activer cette option, TypeScript ne vérifie pas la liaison, l'application et l'appel de types. Après l'avoir allumé, il les vérifie et ne nous permet pas de faire des choses aussi désagréables.

strictNullChecks est, à mon avis, la vérification la plus nécessaire. Cela nous oblige à indiquer dans le typage les endroits où nul ou indéfini peut venir. Avant l'inclusion, nous pouvons passer null ou undefined là où il n'est pas explicitement spécifié et, en conséquence, obtenir une erreur. Après cela, le contrôle sera bien meilleur.

Ensuite, strictFunctionTypes. La situation ici est un peu plus compliquée. Imaginons que nous ayons trois fonctions. L'un travaille avec des animaux, un autre avec des chiens et un avec des chats. Un chien et un chat sont des animaux. Autrement dit, il sera erroné de travailler avec un chien de la même manière qu'avec un chat, car ils sont différents. Cela fonctionnera correctement avec un chien comme avec un animal.
La troisième option est lorsque nous essayons de travailler avec n'importe quel animal comme un chien. Pour une raison quelconque, elle est initialement autorisée dans TypeScript, mais si vous activez cette option, elle sera invalide et certaines vérifications seront effectuées.

Ensuite, strictPropertyInitialization. Ceci est pour les cours. Cela nous oblige à définir des valeurs initiales soit lors de la déclaration d'une propriété, soit dans un constructeur. Parfois, vous devez contourner cette règle. Vous pouvez utiliser un point d'exclamation, mais, encore une fois, cela nous oblige à être un peu plus prudents.
Donc, j'ai compris que nous devions activer strict. J'essaie de l'allumer et de nombreuses erreurs apparaissent. Par conséquent, il a été décidé d'utiliser une configuration de transition vers strict. Nous avons défini strict en trois étapes.

Première étape: nous ajoutons «strict»: true à tsconfig, et, en conséquence, notre environnement de développement nous demande des endroits avec une erreur, qui est causée précisément par l'activation de strict.
Mais pour webpack, nous créons un tsconfig spécial, qui strict sera faux, et l'utilisons lors de la construction. Autrement dit, rien ne casse lors de l'assemblage, mais dans notre éditeur, nous voyons ces erreurs. Et nous pouvons les réparer immédiatement. Ensuite, nous passons de temps en temps à la deuxième étape, c'est un correctif. Nous construisons notre projet avec le tsconfig habituel. Nous corrigeons certaines des erreurs qui ont été commises et répétons tout cela pendant notre temps libre.
Par de telles actions, nous avons jusqu'à présent réduit le nombre de nos erreurs de 400 à 200. Nous sommes impatients de passer à la troisième étape - supprimer webpackTsConfig et utiliser tsconfig lors de la construction, mais avec strict activé.
TypeScript:
Vous pouvez parler un peu des petites subtilités de TypeScript qui ne sont pas couvertes par strict, mais elles sont difficiles à formaliser correctement.

Commençons par l'opérateur point d'exclamation. Que vous permet-il de faire? Dans ce cas, faites référence à un champ qui peut être indéfini, comme s'il ne pouvait pas être indéfini. Cela a du sens en mode strict, lorsque nous essayons d'accéder à un champ, en disant explicitement: je suis sûr qu'il n'est certainement pas nul ou indéfini. Mais c'est mauvais, car s'il s'avère soudainement nul ou non défini, nous obtenons naturellement une erreur d'exécution.
ESLint nous aidera à éviter de telles choses, il nous interdira simplement. Nous l'avons fait. Comment corriger l'exemple précédent maintenant?
Supposons que nous ayons cette situation.

Il y a un élément, il peut être de type link ou span. Avec notre tête, nous comprenons que la durée n'est que du texte et que le lien est du texte et un lien.
(image)
Mais nous avons oublié de dire le langage TypeScript, donc dans la fonction getItemHtml une situation se présente que dans le cas du lien, nous devons dire: href n'est pas optionnel, il le sera certainement. C'est aussi un endroit potentiel pour l'erreur. Comment le réparer?

La première option est de corriger le typage, c'est-à-dire d'indiquer explicitement à TypeScript qu'un href est requis pour un lien, et facultatif pour span.

Et le point d'exclamation ne sera pas nécessaire ici.

Deuxième option de correction. Supposons que le type d'élément n'est pas décrit par nous et que nous ne pouvons pas simplement le prendre et le restreindre. Ensuite, nous pouvons le réécrire de la même manière.

Attention: le chèque vient d'apparaître. Vient ensuite la journalisation que le programmeur ne s'attendait pas à cette valeur lors de l'écriture de ce code, donc à l'avenir nous verrons cette erreur et prendrons les mesures appropriées.
Ensuite, nous essayons de rendre notre élément d'une manière ou d'une autre. Ici, vous pouvez simplement donner une erreur à l'utilisateur. Mais s'il s'agit de données insignifiantes, vous pouvez créer un stub, comme ici.
comme
Plus loin. Il existe également un opérateur as. Que vous permet-il de faire?

Cela permet de dire - je sais mieux, il y a tel ou tel type - et aussi de se conduire à une erreur.
Tableaux
Les méthodes de lutte sont les mêmes. Vous devez être un peu plus prudent avec les tableaux. TypeScript n'est pas une panacée, il ne vérifie pas certains points. Par exemple, nous pouvons faire référence à un élément de tableau inexistant. Dans ce cas, nous prendrons le premier élément du tableau et obtiendrons une erreur dans ce code. Comment pouvons-nous régler ceci?

Encore une fois, il y a deux façons. La première méthode consiste à taper. Nous disons que nous avons le premier élément et nous nous référons sans crainte à cet élément. Ou nous vérifierons, nous enregistrerons, si quelque chose ne va pas, si nous attendons explicitement un tableau non vide.
Objets
C'est la même chose avec les objets. Nous pouvons déclarer un objet qui peut avoir n'importe quel nombre de propriétés et également obtenir une erreur non définie.

Encore une fois, vous pouvez donner des instructions explicites sur les propriétés requises, ou simplement vérifier.
tout
Maintenant, la chose évidente est n'importe laquelle.

Il vous permet d'accéder à n'importe quelle propriété d'un objet comme s'il n'y avait pas du tout de frappe. Dans ce cas, nous pouvons faire ce que nous voulons avec x. Et encore une fois, tirez-vous dans le pied, faites des erreurs.
Encore une fois, il est préférable de l'interdire explicitement avec ESLint. Mais il y a des situations où il apparaît tout seul.

Par exemple, dans ce cas, JSON.parse renvoie uniquement ce type any. Ce qui peut être fait?

Vous pouvez simplement dire: je ne vous crois pas, il vaut mieux dire que je ne sais pas ce que c’est, et je vivrai avec. Comment vivre avec? Voici un exemple hypothétique.

Il y a un utilisateur, l'utilisateur a un nom obligatoire et un e-mail facultatif.

Nous écrivons la fonction parseUser. Il prend une chaîne JSON et nous renvoie notre objet. Maintenant, nous commençons à vérifier tout cela. Tout d'abord, nous voyons la ligne avec parse et inconnu qui nous est familière de la diapositive précédente. Ensuite, nous commençons à vérifier.

S'il ne s'agit pas d'un objet ou s'il est nul, lancez une erreur.

De plus, s'il n'y a pas de propriété de nom requise ou s'il ne s'agit pas d'une chaîne, nous lançons une erreur. Voici la suite du code.

Nous commençons à former l'utilisateur, puisque tous les champs obligatoires ont déjà été collectés.

Ensuite, nous vérifions s'il existe un champ email. Si c'est le cas, nous vérifions son type et, si le type ne correspond pas, nous renvoyons une erreur. S'il n'y a pas d'e-mail, nous n'envoyons rien et renvoyons le résultat. Tout va bien. Mais vous devez écrire beaucoup pour le type le plus simple.

Et il faut beaucoup de contrôles
Nous avons besoin de beaucoup de validation car une requête JSON typique ressemble à ceci.

Sans plus tarder, c'est juste fetch et json (). La conversion de any en SomeRequestResponse apparaît en retour. Cela doit également être combattu. Cela peut être fait de la manière précédente, ou cela peut être un peu différent.
io-ts
C'est pareil sous le capot: nous utilisons une bibliothèque spéciale pour la vérification de type. Dans ce cas, il s'agit de io-ts. Voici un exemple simple de la façon de l'utiliser.

Prenons le type d'utilisateur précédent et écrivons-le dans la bibliothèque que nous utilisons. Oui, la saisie est un peu plus compliquée ici, mais deux conditions doivent être remplies simultanément. Il doit s'agir d'un objet avec un champ de nom obligatoire et un objet avec un champ d'e-mail facultatif. Comment pouvons-nous vérifier tout cela?

Écrivons le même parseUser. Dans ce cas, nous utilisons la méthode User.decode. On y passe l'objet déjà apparié, il nous renvoie le résultat. Peut-être dans un format inhabituel. Un objet de type Soit, il peut être dans deux états. Le premier a raison. Cela signifie généralement que tout s'est bien passé. gauche dit que ça ne s'est pas très bien passé. Ces deux états ont des propriétés qui nous permettent d'en savoir plus. En cas de succès, c'est le résultat de l'exécution, si une erreur se produit, une erreur.
Nous vérifions si nos résultats sont à l'état gauche. Si c'est le cas, nous disons qu'une erreur s'est produite. Ensuite, si tout va bien, nous renvoyons simplement le résultat.
Affichage des erreurs

À propos de l'affichage des erreurs. Vous pouvez l'améliorer un peu. Nous utiliserons io-ts-reporters pour cela. C'est une bibliothèque écrite par le même auteur que io-ts. Cela permet à l'erreur d'être magnifiquement présentée. Ce qu'elle fait? Nous avons changé le code ici où se trouve le canard. Il prend le résultat et renvoie un tableau de chaînes. Nous le joignons simplement en une seule ligne et l'affiche. Qu'est-ce qu'on obtient à la fin?

Supposons que nous transmettions null à une chaîne JSON.

Cela donnera deux erreurs. Cela est dû à la subtilité de l'implémentation, car nous avons fait l'intersection. Les erreurs sont assez claires. Les deux disent que nous nous attendions à un objet mais que nous avons obtenu la valeur null. C'est juste que pour chacune de ces conditions, cela donnera une erreur séparément.

Ensuite, essayons d'y passer un tableau vide. Ce sera pareil.

Il nous dira simplement: je m'attendais aussi à un objet, mais j'ai reçu un tableau vide.

Ainsi, nous continuons à voir ce qui se passera si nous commençons à transmettre des données incorrectes. Par exemple, passons un objet vide.

Maintenant, cela donnera une erreur sur le fait que nous n'avons pas le champ de nom requis. Il s'attendait à ce que le champ de nom soit de type chaîne, mais se termine par undefined. Il est également facile de comprendre à partir de cette erreur ce qui s'est passé.

Ensuite, nous essaierons d'y passer un type incorrect. Nous obtenons également une erreur, à peu près la même que dans l'exemple précédent.

Mais ici, il nous écrit clairement le sens que nous avons véhiculé.

Que peut faire d'autre io-ts? Il vous permet d'obtenir un type TypeScript. Autrement dit, nous ajoutons cette ligne. En ajoutant simplement typeof, également typeof, nous obtenons un type TypeScript que nous pouvons utiliser ultérieurement dans l'application. Idéalement.

Que peut faire d'autre cette bibliothèque? Convertissez les types. Disons que nous faisons une demande au serveur. Le serveur envoie les dates au format d'heure unix. Et il existe une bibliothèque spéciale, toujours du créateur de la bibliothèque io-ts: io-ts-types. Il existe des transformations qui ont été écrites à l'origine et des outils pour rendre ces transformations plus faciles à écrire. On ajoute un champ de date: il provient du serveur sous forme de nombre, et on finit par le recevoir sous forme d'objet Date.
Décrivons le type
Voyons ce qu'il y a dans cette bibliothèque et essayons de décrire le type le plus simple.

Voyons d'abord comment cela est généralement décrit. Il est décrit de la même manière, assez compliqué, étant donné qu'il est également nécessaire pour les transformations. Mis à part le serveur vers le client, si l'on considère l'interaction avec le serveur, et la transformation inverse, du client vers le serveur.
Simplifions un peu notre tâche. Nous allons simplement écrire le type qui vérifie. Dans ce cas, voyons ce que signifient ces champs. nom - tapez le nom.

Il est nécessaire d'afficher les erreurs. Comme nous l'avons vu dans les exemples précédents, les erreurs épellent en quelque sorte le nom du type. Vous pouvez le spécifier ici.
Ensuite, il y a la fonction de validation. Il prend - disons, du serveur - la valeur inconnue; prend un contexte pour afficher correctement l'erreur; et renvoie un objet Either dans deux états - une erreur ou une valeur validée.
Il y a deux autres fonctions: is et encoder. Ils sont utilisés pour inverser leur transformation, mais ne les touchons pas pour l'instant.

Comment le type de chaîne le plus simple peut-il être représenté? Nous définissons le nom sur string et vérifions qu'il s'agit d'une chaîne. Avec une conversion directe, ce ne sera pas nécessaire, mais formellement nous l'écrivons. Et puis nous faisons juste du typeof pour vérifier. En cas de succès, nous renvoyons le résultat avec succès, et à la suite d'une erreur, échec. Le contexte est également ajouté afin que l'erreur s'affiche correctement. Et nous retournons simplement la même chose, car il n'y a pas de transformation inverse.
Sur la pratique
Qu'est-ce qui est en pratique? Pourquoi avons-nous décidé de vérifier les données provenant du serveur?

Au minimum, il y a du JSON dans la base de données. Nous pensons bien sûr qu'il sera bien géré et qu'il sera contrôlé à certains moments. Mais le format peut changer un peu, il ne faut pas casser le frontend ou découvrir immédiatement des erreurs pour agir.
Nous avons Python sur le serveur sans typage explicite. Avec cela aussi, il peut parfois y avoir de petits problèmes. Et pour ne pas tomber en panne, nous pouvons simplement vérifier et nous sécuriser en plus, au cas où.
Il n'y a pas de documentation claire sur les réponses du serveur. Probablement, le serveur s'inquiète plus de ce qui lui arrivera que de ce qu'il va donner. Oui, c'est plus notre problème - de ne pas casser.

Qu'avons-nous trouvé? Nous avons déjà commencé à l'utiliser un peu. Trouvé que le serveur nous donne un objet vide au lieu d'un tableau vide. Je viens de regarder le code - il est écrit pour renvoyer un objet vide.
En outre - l'absence de certains champs. Nous pensions qu'elles étaient obligatoires, mais elles s'avèrent facultatives.
Un champ Nullable manquait simplement dans certains cas. Autrement dit, un champ optionnel peut être présenté de deux manières: soit lorsque nous ne le passons tout simplement pas, soit lorsque nous passons null. Cela ne nous est pas toujours venu correctement. Afin de ne pas attraper des erreurs au milieu de notre code, nous pouvons attraper cela uniquement à la demande.

Qu'avons-nous maintenant? Nous avons déjà vérifié beaucoup de réponses du serveur et enregistré si nous n'aimons pas quelque chose. Ensuite, nous analysons cela et définissons les tâches: soit pour modifier la saisie sur notre frontend, soit pour des modifications sur le backend. Maintenant, nous ne changeons pas les données qui proviennent du serveur: si null est venu au lieu d'une chaîne, nous ne le changeons pas, par exemple, en une chaîne vide.
Nos plans sont de vérifier et de consigner, mais de corriger s'il y a une erreur. Si nous recevons des données incorrectes, nous corrigerons cette valeur afin que les utilisateurs puissent afficher au moins quelque chose au lieu de tomber dans notre code.

Petits résultats. Nous activons strict pour que TypeScript nous aide davantage, exclure as, any et le point d'exclamation. Nous serons plus prudents avec les tableaux et les objets dans TypeScript, et nous vérifierons également toutes les données externes. Au fait, ce ne sont pas que des serveurs. Vous pouvez également vérifier localStorage, les messages qui viennent dans les événements. Par exemple postMessage.
Merci pour l'attention.