MegaFon a choisi l'opportunité de travailler avec des communications instables comme l'un de ses points de croissance importants. Il y a des endroits en Russie où les communications sont temporairement déconnectées ou perdues pendant une longue période. Et même dans ce cas, l'application doit fonctionner sans échec.
Valentin a parlé de la façon dont cette tâche a été effectuée au cours des cinq derniers mois, de la manière dont l'architecture du projet a été choisie et mise en œuvre, des technologies utilisées, ainsi que de ce qu'elles ont réalisé et de ce qui était prévu pour l'avenir, Valentin a pris la parole lors de la conférence Apps Live 2020 des développeurs d'applications mobiles.

Une tâche
L'entreprise a dit - nous nous déconnectons afin que l'utilisateur puisse interagir avec succès avec l'application dans une connexion réseau instable. En tant qu'équipe de développement, nous devions d'abord garantir Offline - l'application fonctionnera même avec un Internet instable ou complètement absent. Aujourd'hui, je vais vous dire par où nous avons commencé et quelles premières mesures nous avons prises dans cette direction.
Pile technologique
Outre l'architecture MVC standard, nous utilisons:
Swift + Objective-C
La majeure partie du code (80% de notre projet) est écrite en Objective-C. Et déjà, nous écrivons un nouveau code dans Swift.
Architecture modulaire
Nous divisons logiquement les morceaux de code globaux en modules pour accélérer la compilation, le lancement et le développement de projets.
Sous-modules (bibliothèques)
Nous connectons toutes les bibliothèques supplémentaires via le sous-module git pour avoir plus de contrôle sur les bibliothèques utilisées. Par conséquent, si le soutien à l'un d'entre eux cesse soudainement, nous serons en mesure de corriger la situation par nous-mêmes.
Données de base pour le stockage local
Lors du choix, le critère principal pour nous était la nativité et l'intégration avec les frameworks iOS. Et ces avantages de Core Data ont été décisifs:
- Sauvegardez automatiquement la pile et les données que nous recevons;
- , ( , ..)
- ;
- ;
- ;
- ;
- UI (FRC);
- (NSPredicates).
UIManaged document
Le kit d'interface utilisateur a une classe intégrée appelée UIManagedDocument, qui est une sous-classe d'UIDocument. Sa principale différence est que lorsqu'un document géré est initialisé, une URL est spécifiée pour l'emplacement du document dans le stockage local ou distant. L'objet document crée ensuite complètement une pile de données de base dès la sortie de la boîte, qui est utilisée pour accéder au stockage persistant du document à l'aide du modèle d'objet (.xcdatamodeld) à partir du package d'application principal. C'est pratique et logique, même si nous vivons déjà au 21e siècle:
- UIDocument enregistre automatiquement l'état actuel lui-même, à une fréquence spécifique. Pour les sections particulièrement critiques, nous pouvons déclencher manuellement la sauvegarde.
- . - — , , - , — , , .
- UIDocument .
- Core data .
- iCloud . , .
- .
- Le paradigme de l'application basée sur un document est utilisé - représentant le modèle de données en tant que conteneur pour stocker ces données. Si nous regardons le modèle MVC classique dans la documentation Apple, nous pouvons voir que les données de base ont été créées précisément pour manipuler ce modèle et nous aider à travailler avec des données à un niveau d'abstraction plus élevé. Au niveau du modèle, nous travaillons en connectant le UIManagedDocument à l'ensemble de la pile créée. Et nous considérons le document lui-même comme un conteneur qui stocke les données de base et toutes les données du cache (des écrans, des utilisateurs). De plus, il peut s'agir d'images, de vidéos, de textes - n'importe quelle information.
Nous considérons notre application, son lancement, l'autorisation de l'utilisateur et toutes ses données comme une sorte de grand document (fichier), qui stocke l'historique de notre utilisateur:

Processus
Comment nous avons conçu l'architecture
Notre processus de conception se déroule en plusieurs étapes:
- Analyse des spécifications techniques.
- Rendu d'un diagramme UML. Nous utilisons principalement trois types de diagrammes UML: diagramme de classes, organigramme, diagramme de séquence. C'est la responsabilité directe des développeurs seniors, mais les développeurs moins expérimentés peuvent également le faire. C'est même le bienvenu, car cela vous permet de bien plonger dans la tâche et d'en apprendre toutes ses subtilités. Cela permet de détecter d'éventuelles failles dans la mission technique, ainsi que de structurer toutes les informations sur la tâche. Et nous essayons de prendre en compte la nature multiplateforme de notre application - nous travaillons en étroite collaboration avec l'équipe Android, en dessinant le même diagramme sur deux plates-formes et en essayant d'utiliser les principaux modèles de conception généralement acceptés du groupe de quatre.
- Revue d'architecture. En règle générale, un collègue d'une équipe adjacente procède à l'examen et à l'évaluation.
- Implémentation et test sur l'exemple d'un module UI.
- Mise à l'échelle. Si le test réussit, nous adaptons l'architecture à l'ensemble de l'application.
- Refactoring. Pour vérifier si nous avons manqué quelque chose.
Maintenant, après cinq mois de développement de ce projet, je peux montrer l'ensemble de notre processus en trois étapes: ce qui s'est passé, comment cela a changé et ce qui s'est passé en conséquence.
Qu'est-il arrivé
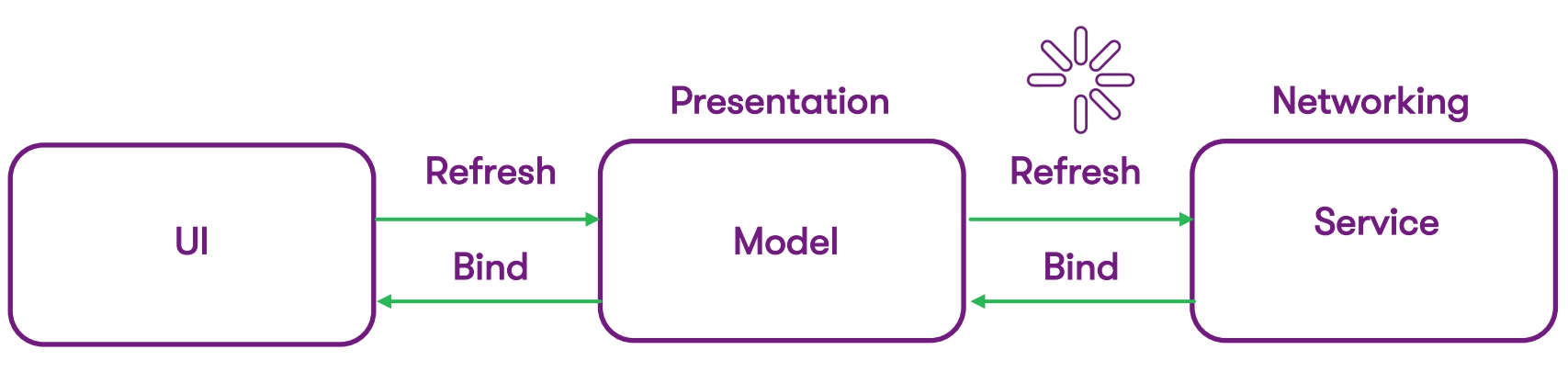
Notre point de départ était l'architecture MVC standard - ce sont des couches interconnectées:
- Couche UI, entièrement programmée à l'aide de l'Objectif C;
- Classe de présentation (modèle);
- La couche de service sur laquelle nous travaillons avec le réseau.
L'indicateur d'activité était situé à la place du diagramme où le processus de réception des données est sensible à la vitesse d'Internet - l'utilisateur veut un résultat rapide, mais est obligé de regarder certains chargeurs, indicateurs et autres signaux. Voici nos points de croissance dans l'expérience utilisateur:
Période de transition
Pendant la période de transition, nous avons dû implémenter la mise en cache pour les écrans. Mais comme l'application est volumineuse et contient beaucoup de code Objective C hérité, nous ne pouvons pas simplement prendre et supprimer tous les services et modèles en insérant du code Swift - nous devons prendre en compte qu'en parallèle avec la mise en cache, nous avons encore de nombreuses autres tâches produit en développement.
Nous avons trouvé un moyen simple de s'intégrer le plus efficacement possible dans le code actuel, sans rien casser, et de mener la première itération aussi facilement que possible. Sur le côté gauche du diagramme précédent, nous avons complètement supprimé tout ce qui concerne les requêtes réseau - via l'interface, le service communique désormais avec DataSourceFacade. Et maintenant, c'est la façade avec laquelle le service fonctionne. Il attend du DataSource les données qu'il a précédemment reçues du réseau. Et dans le DataSource lui-même, la logique d'extraction de ces données est masquée.
Sur le côté droit du diagramme, nous avons décomposé l'acquisition de données en commandes - le modèle de commande vise à exécuter une commande de base et à obtenir le résultat. Dans le cas d'iOS, nous utilisons les héritiers de NSOperation:
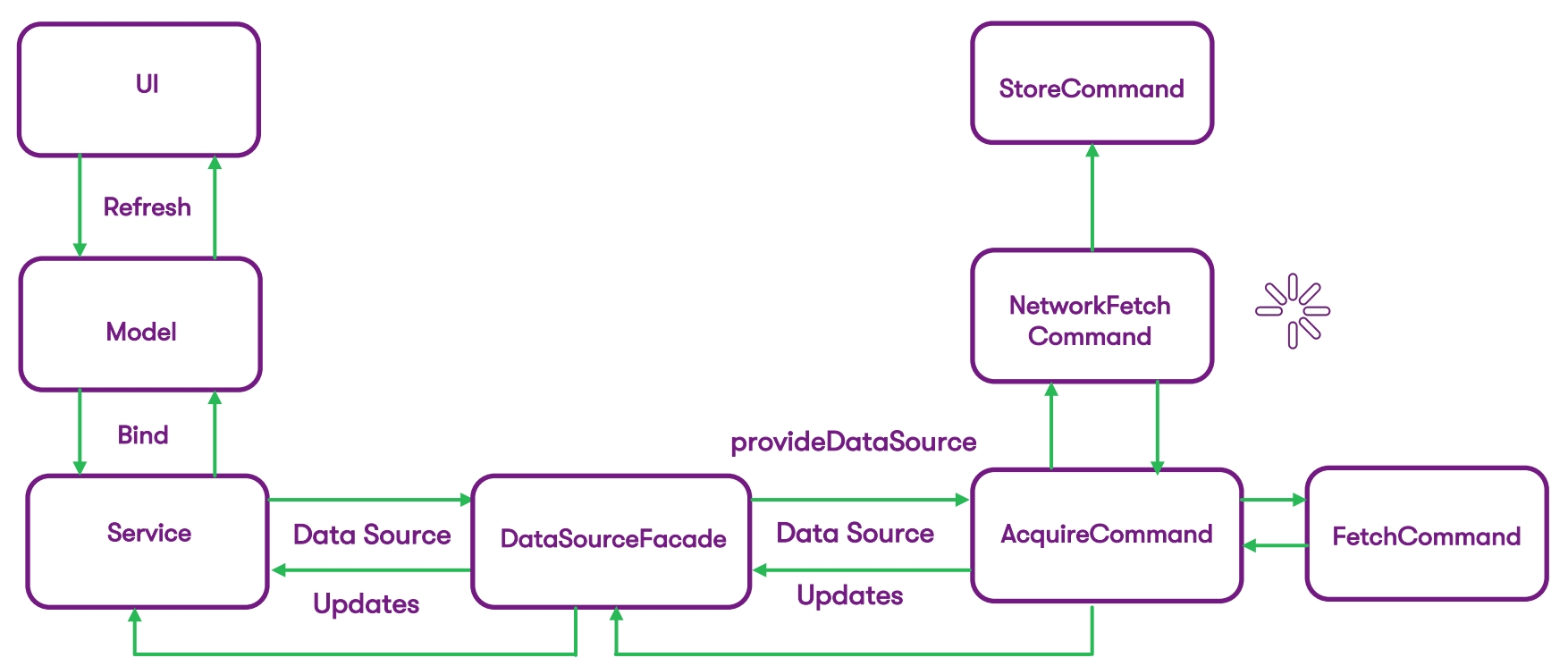
Chaque commande que vous voyez ici est une opération qui contient une unité logique de l'action attendue. Il s'agit d'obtenir des données d'une base de données (ou d'un réseau) et de stocker ces données dans les données de base. Par exemple, l'objectif principal d'AcquireCommand n'est pas seulement de renvoyer la source de données sur la façade, mais aussi de nous permettre de concevoir du code de manière à recevoir des données à travers la façade. Autrement dit, l'interaction avec les opérations passe par cette façade.
Et la tâche principale des opérations est de transmettre les données DataSource à DataSourceFacade. Bien sûr, nous construisons la logique de manière à montrer les données à l'utilisateur le plus rapidement possible. En règle générale, à l'intérieur de DataSourceFacade, nous avons une file d'attente opérationnelle où nous démarrons nos NSOperations. En fonction des conditions configurées, nous pouvons décider quand afficher les données du cache et quand recevoir du réseau. Lorsque nous demandons pour la première fois une source de données dans la façade, nous allons dans la base de données Core, en récupérons les données via FetchCommand (si elle est là) et les renvoyons instantanément à l'utilisateur.
En même temps, nous lançons une demande parallèle de données sur le réseau, et lorsque cette demande est exécutée, le résultat arrive dans la base de données, y est stocké, puis nous recevons une mise à jour de notre DataSource. Cette mise à jour est déjà incluse dans l'interface utilisateur. De cette façon, nous minimisons le temps d'attente pour les données, et l'utilisateur, les recevant instantanément, ne remarque pas la différence. Il recevra les données mises à jour dès que la base de données recevra une réponse du réseau.
Comment est-ce devenu
Nous allons à un schéma plus laconique (et nous arriverons à la fin):
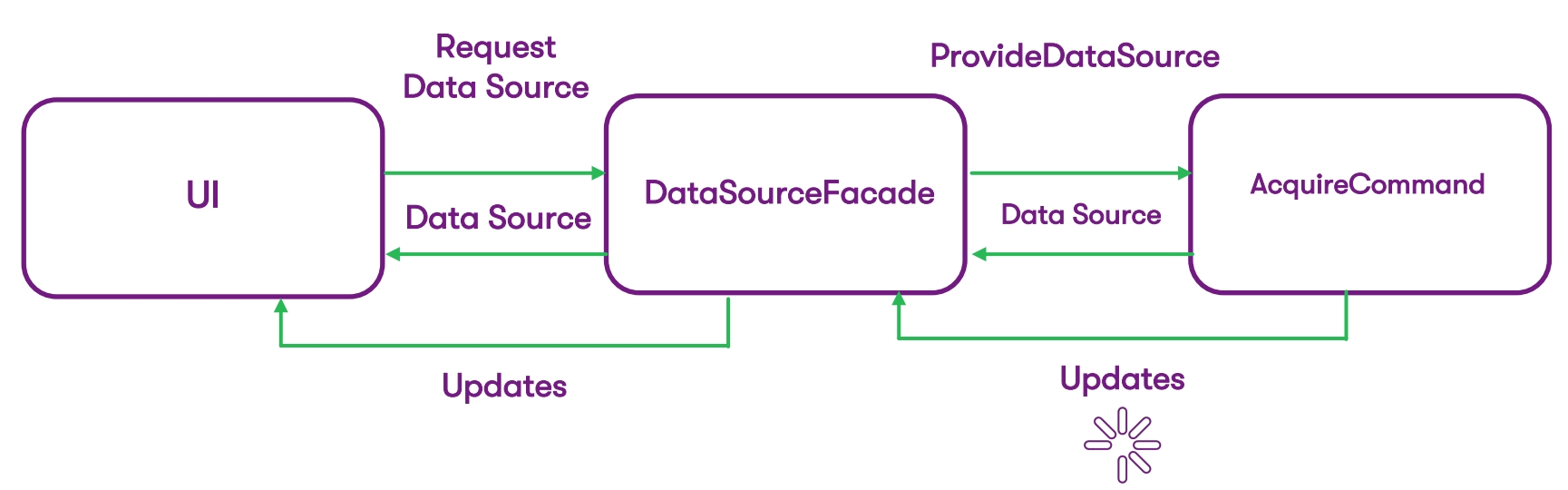
Maintenant, à partir de cela, nous avons:
- Couche UI,
- la façade à travers laquelle nous fournissons notre DataSource,
- la commande qui renvoie ce DataSource avec les mises à jour.
Qu'est-ce qu'une DataSource et pourquoi nous en parlons tant
DataSource est un objet qui fournit des données pour la couche de présentation et suit un protocole prédéfini. Et le protocole doit être ajusté à notre interface utilisateur et fournir des données pour notre interface utilisateur (cela n'a pas d'importance pour un écran spécifique ou pour un groupe d'écrans).
Un DataSource a généralement deux responsabilités principales:
- Fournir des données à afficher dans la couche d'interface utilisateur;
- Informer l'interface utilisateur de la couche des modifications de données et envoyer le lot de modifications nécessaire à l'écran lorsque nous recevons une mise à jour.
Nous utilisons ici plusieurs variantes de DataSource, car nous avons beaucoup de code hérité Objective C - c'est-à-dire que nous ne pouvons pas facilement coller notre Swift DataSource partout. Nous n'utilisons pas encore de collections partout, mais à l'avenir, nous réécrirons le code spécifiquement pour utiliser les écrans CollectionView.
Un exemple de l'un de nos DataSource:

Il s'agit d'un DataSource pour une collection (il s'appelle CollectionDataSource) et c'est une classe assez simple du point de vue de l'interface. Il prend une collection configurée par un fetchedResultsController et un CellDequeueBlock. Où CellDequeueBlock est un alias de type, dans lequel nous décrivons la stratégie de création de cellules.
Autrement dit, nous avons créé le DataSource et l'avons attribué à la collection en appelant performFetch sur le fetchedResultsController, puis toute la magie est affectée à l'interaction de notre classe DataSource, fetchedResultsController et la capacité du délégué à recevoir des mises à jour de la base de données:

FetchedResultsController est le cœur de notre DataSource. Vous trouverez de nombreuses informations sur son utilisation dans la documentation Apple. En règle générale, nous recevons toutes les données avec son aide - à la fois les nouvelles données et les données qui ont été mises à jour ou supprimées. Dans le même temps, nous demandons simultanément des données au réseau. Dès que les données ont été reçues et stockées dans la base de données, nous avons reçu une mise à jour de DataSource, et la mise à jour nous est parvenue dans l'interface utilisateur. Autrement dit, avec une seule demande, nous recevons les données et les montrons à différents endroits - cool, pratique, natif!
Et partout où il est possible d'utiliser DataSource prêt à l'emploi avec des tables ou avec des collections, nous le faisons:

dans les endroits où nous avons beaucoup d'écrans et n'utilisons pas de tables et de collections (et utilisons la mise en page du logiciel Objective C), nous évaluons les données dont nous avons besoin pour l'écran, et à travers le protocole, nous décrivons notre DataSource. Après cela, nous écrivons la façade - en règle générale, il s'agit également d'un protocole public Objective C à travers lequel nous demandons notre DataSource. Et puis l'entrée au code Swift est déjà en cours.
Dès que nous serons prêts à traduire complètement l'écran en une implémentation Swift, il suffira de supprimer le wrapper Objective C - et, grâce au DataSource personnalisé, nous pouvons travailler directement avec le protocole Swift.
Nous utilisons actuellement trois principales variantes de DataSources:
- TableViewDatasource + stratégie de cellule (stratégie de création de cellules);
- CollectionViewDatasource + stratégie de cellule (option avec collections);
- CustomDataSource est une option personnalisée. Nous l'utilisons le plus maintenant.
résultats
Après toutes les étapes de conception, de mise en œuvre et d'interaction avec le code hérité, l'entreprise a bénéficié des améliorations suivantes:
- La vitesse de livraison des données à l'utilisateur a considérablement augmenté en raison de la mise en cache. C'est probablement un résultat évident et logique.
- Nous sommes maintenant un peu plus près du premier paradigme hors ligne.
- Les processus de revue architecturale multiplateforme ont été mis en place au sein des équipes iOS et Android - tous les développeurs impliqués dans ce projet ont des informations et échangent facilement leurs expériences entre les équipes.
- . , , legacy , .
- , — . , , , , , .
Le bonus pour nous était que nous avons compris à quel point travailler avec l'architecture et les diagrammes peut être intéressant et amusant (et cela simplifie le développement). Oui, nous avons passé beaucoup de temps à dessiner et à aligner nos approches architecturales, mais en ce qui concerne la mise en œuvre, nous avons évolué très rapidement sur tous les écrans.
Notre chemin vers Offline continue - nous avons besoin non seulement de la mise en cache pour être hors ligne, mais aussi l'utilisateur peut fonctionner sans connexion réseau, avec une synchronisation supplémentaire avec le serveur après l'apparition d'Internet.
Liens
- Guide de programmation basé sur des documents . C'est un document assez ancien, Apple ne recommande plus de l'utiliser. Mais je recommanderais au moins de chercher un développement supplémentaire. Il y a beaucoup d'informations utiles là-bas.
- Document-based WWDC:
- DataSources
Apps Live 2020 .
— Android iOS, . , , .