
«Laissez-moi tranquille, je vous en prie, je suis un créateur! Laisse-moi créer! »- le programmeur Gennady pour la troisième fois dans la soirée prononce ce mantra dans sa tête. Cependant, il n'a pas encore écrit une seule ligne de code, car une autre pull request est arrivée dans la bibliothèque qu'il tente de développer. Et, conformément à la politique de l'entreprise, la révision du code doit avoir lieu avec un minimum de retards. Maintenant, Gennady réfléchit à ce qu'il faut faire: sans chercher à accepter les changements, également sans chercher à les rejeter, ou encore passer un temps précieux à comprendre leur essence. Après tout, qui d'autre que lui? Il a écrit ce code, il le suivra. Et tous les changements ne sont possibles que grâce à son consentement personnel, car il s'agit de la bibliothèque Doomsday.
Pendant ce temps, littéralement derrière le mur, une équipe appelée "Cedar Beavers" redistribue les demandes entre elles afin que la charge de les visualiser tombe plus ou moins uniformément. Oui, ils ne traitent pas avec la bibliothèque Doomsday, mais ils effectuent d'autres tâches qui nécessitent des changements de code rapides et des processus plus rapides.
Il n'y a pas de solution universelle pour tous les cas: pour certains, la rationalisation et la rapidité des processus sont importantes, quelque part, une main ferme et un contrôle total peuvent être nécessaires. De plus, à différentes étapes du développement d'un même produit, différentes approches peuvent être nécessaires pour se remplacer. Chacun d'eux a ses avantages et ses inconvénients, et sur la base d'eux, nous sommes arrivés là où nous en sommes maintenant.
Alors, où sommes-nous allés à Wrike?
Quelles options avons-nous choisi notre propre façon de posséder le code?
Strictement personnel. Nous n'avons même pas envisagé cela. Maintenant, si Gennady interdit de créer des pull requests dans sa bibliothèque, et qu'il fait tous les changements personnellement, alors vous obtenez une approche strictement personnelle. Sûrement Gennady a commencé de cette façon.
Les inconvénients évidents de cette approche sont simplement le totalitarisme dans le monde du développement. Gennady est sans exagération la seule personne sur Terre qui connaît parfaitement le code, a (ou pas) des plans pour son développement et peut le changer. Le même bus, qui est le "facteur de basse", a déjà quitté le coin. Si Gennady attrape un rhume, alors, très probablement, le projet tombera avec lui. Un autre développeur devra bifurquer, il y en aura beaucoup et un chaos complet s'ensuivra.
Cette approche a un plus - une approche complètement consolidée du développement. Une personne prend toutes les décisions sur l'architecture, le style de code et résout personnellement tout problème. Pas de frais généraux de communication.
Conditionnellement personnel. C'est exactement ce que Gennady ne veut pas faire: regarder tous les MR, donner la possibilité de changer le code de sa bibliothèque à d'autres personnes, mais avoir un contrôle total sur les changements et avoir le droit de veto. Les avantages et les inconvénients sont les mêmes que dans le paragraphe précédent, mais maintenant ils sont un peu lissés par la possibilité d'envoyer une pull request à des développeurs tiers directement vers le référentiel, et de ne pas rédiger de spécification technique pour la mise en œuvre de certaines fonctionnalités.
Collectifcomme Cedar Beavers. Dans ce cas, toute l'équipe est responsable du code, et ses membres décident eux-mêmes qui surveillera quelle requête.
Parmi les avantages, on peut noter la rapidité de révision de la revue, la répartition de l'expertise entre les membres de l'équipe et une diminution du facteur bus. Bien sûr, il y a aussi des inconvénients. Dans les discussions sur Internet, nombreux sont ceux qui évoquent le manque de responsabilité si celle-ci est «répartie» entre plusieurs personnes. Mais cela dépend de la structure de l'équipe et de la culture des développeurs: le Senior Developer ou le team lead peut être responsable de l'équipe, alors il sera le point d'entrée pour les questions. Et la MR et l'écriture de nouvelles fonctionnalités peuvent être divisées en fonction du niveau de formation des développeurs. Après tout, il serait faux de donner à un débutant qui commence à peine à comprendre l'architecture de l'application de refactoriser le code.
Chez Wrike, nous adoptons une approche collaborative de la propriété du code, avec le chef d'équipe comme principale responsabilité. Cette personne possède le plus d'expertise dans le code, sait lequel des développeurs est compétent dans l'examen d'une complexité particulière et assume l'entière responsabilité de la qualité du code de l'équipe.
Mais le chemin vers la mise en œuvre technique de cette solution n'a pas été des plus faciles. Oui, en termes de mots, tout semble assez simple: voici une fonctionnalité, voici une commande. L'équipe sait de quoi elle est responsable, ce qui signifie qu'elle la surveillera.
De tels accords peuvent fonctionner comme un contrat verbal si le nombre de commandes est inférieur au nombre de doigts d'une main. Et dans notre cas, c'est plus de trente commandes et des millions de lignes de code. De plus, souvent les limites d'une fonctionnalité ne peuvent pas être désignées par un référentiel: il existe des intégrations assez proches de certaines fonctionnalités dans d'autres.
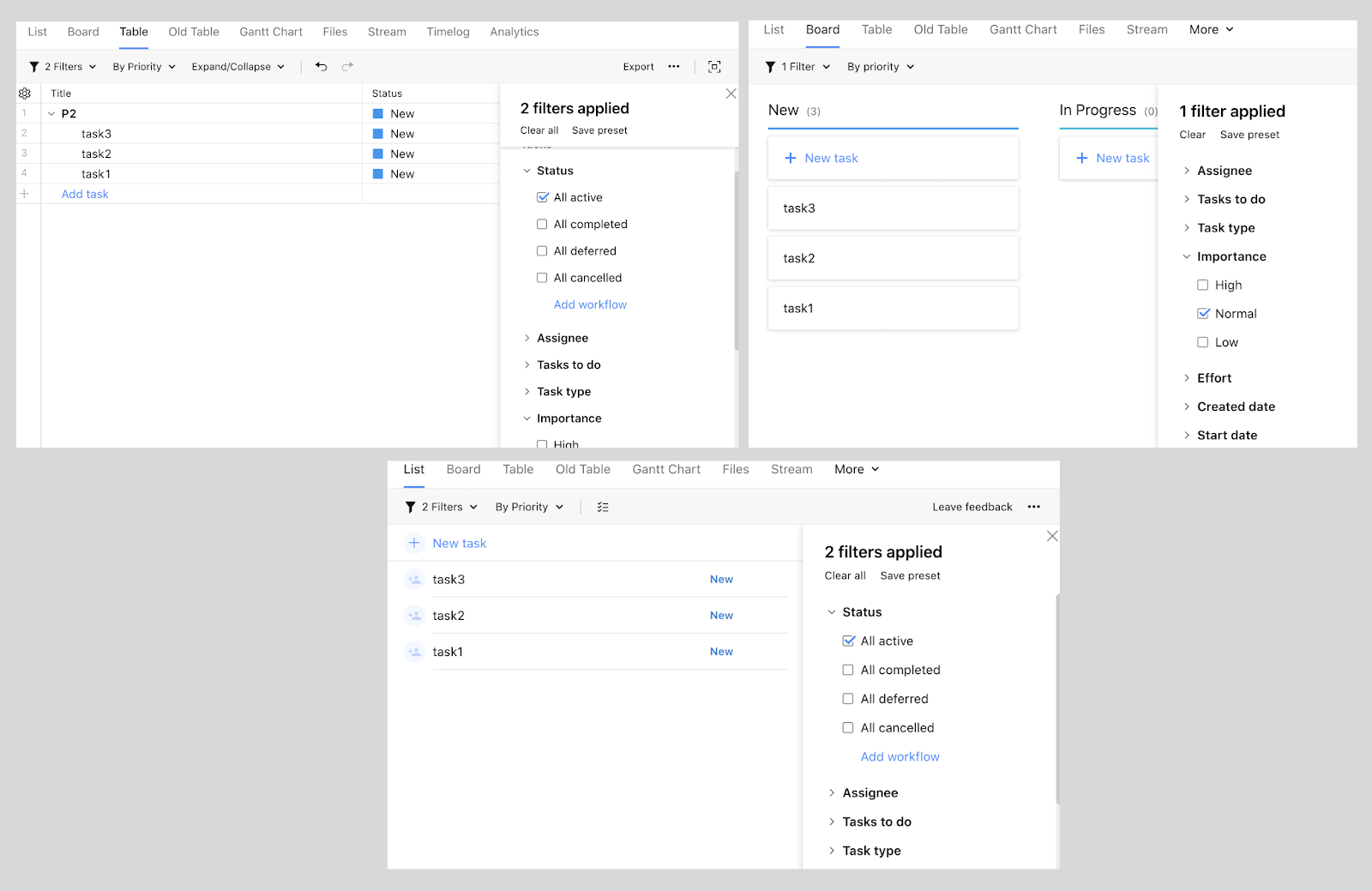 Le panneau de filtres sur la droite est le même pour toutes les vues. C'est une caractéristique de l'équipe "A". De plus, toutes les vues sont des caractéristiques des trois autres équipes, l'
Le panneau de filtres sur la droite est le même pour toutes les vues. C'est une caractéristique de l'équipe "A". De plus, toutes les vues sont des caractéristiques des trois autres équipes, l'
exemple le plus évident étant les filtres. Ils ont la même apparence et se comportent de la même manière dans toutes les vues possibles, tandis que les vues elles-mêmes peuvent différer par leurs fonctionnalités. Cela signifie que la vue appartient à une équipe et que le panneau de filtrage unique appartient à une autre. Et donc des dizaines de référentiels, des milliers de fichiers de code différent. À qui devriez-vous vous adresser pour l'examen si vous devez apporter des modifications à un fichier spécifique?
Au début, nous avons essayé de résoudre ce problème avec un simple fichier JSON, qui se trouvait à la racine du référentiel. Il y avait une description de la fonctionnalité et les noms des personnes responsables. Ils pourraient être contactés pour obtenir un avis sur leur pull request.
C'est un peu comme un modèle de propriété de code personnel conditionnel. La seule exception est que non pas une personne est désignée comme responsable, mais deux ou trois. Mais cette approche ne nous convenait jamais: les gens ont déménagé dans d'autres équipes, sont tombés malades, sont partis en vacances, ont démissionné, et à chaque fois, nous devions d'abord rechercher quelqu'un qui remplace le propriétaire spécifié, puis dire aux propriétaires de changer manuellement le nom et de pousser les changements.
Plus tard, ils sont passés de personnes spécifiques à la spécification de commandes.Cependant, tout est dans le même fichier JSON. Cela ne s'est pas beaucoup amélioré, car il était maintenant nécessaire de trouver des membres de l'équipe à qui le code pourrait être soumis pour examen. Et nous avons des centaines (un peu rusés, près de 70) développeurs front-end, et il n'était pas facile de trouver tous les participants à ce moment-là. Le système de propriété est déjà devenu collectif, mais trouver les bonnes personnes n'était parfois pas plus facile que de rechercher un propriétaire adjoint de la version précédente. De plus, le problème avec le code, dans lequel plusieurs fonctionnalités pourraient se croiser, ne pouvait toujours pas être résolu.
Par conséquent, il était essentiel de résoudre deux questions: comment attribuer des fonctionnalités individuelles à une certaine équipe dans le référentiel d'une autre équipe et comment rendre les informations simples et accessibles pour toutes les équipes susceptibles de posséder le code.
Pourquoi les outils prêts à l'emploi ne nous convenaient pas. Il existe des outils sur le marché pour affecter des personnes à des avis et associer des individus spécifiques à un code. Lors de leur utilisation, vous n'avez pas besoin de recourir à la création de fichiers avec les noms des personnes à qui vous devez exécuter en cas de critiques, de bogues, de refactorisations complexes.
Chez Azure DevOps, les services ont des fonctionnalités - Inclure automatiquement le réviseur de code. Le nom parle de lui-même et un ancien de mes collègues dit qu'ils utilisent cet outil dans leur entreprise et avec beaucoup de succès. Nous ne travaillons pas avec Azure, ce serait donc formidable d'entendre les lecteurs comment les choses se passent avec la visionneuse automatique.
Nous utilisons GitLab, il serait donc logique de se tourner vers les propriétaires de code GitLab. Mais le principe de fonctionnement de cet outil ne nous convenait pas: la fonctionnalité de GitLab est un tas de chemins dans le référentiel (fichiers et dossiers) et de personnes via leurs comptes dans GitLab. Ce bundle est écrit dans un fichier spécial - codeowners.md. Nous avions besoin d'un tas de chemins et de fonctionnalités. De plus, nos fonctionnalités sont contenues dans un dictionnaire spécial, où elles sont affectées à la commande. Cela vous permet de marquer des fonctionnalités complexes qui peuvent exister dans plus d'un référentiel, être développées par plusieurs équipes et, encore une fois, ne pas être liées à des noms spécifiques. De plus, nous avions prévu d'utiliser ces informations pour créer un répertoire pratique des équipes, des fonctionnalités associées et de tous les membres de l'équipe.
En conséquence, nous avons décidé de créer notre propre système de contrôle de propriété du code. L'implémentation de la première version de notre système était basée sur les capacités du SDK Dart , car au départ, il était lancé pour les référentiels du département front-end et uniquement pour les fichiers Dart. Nous avons utilisé nos propres balises meta (heureusement, cela est pris en charge au niveau de la langue), puis parcouru tous les fichiers source avec un analyseur statique et créé quelque chose comme un tableau: Fichier / Fonctionnalité - Commande propriétaire. Vous pouvez marquer à la fois des fichiers individuels et des chemins entiers avec plusieurs dossiers.
Après un certain temps, le balisage avec des fonctionnalités est devenu disponible pour le code dans Dart, JS et Java, et il s'agit de toute la base de code: à la fois le frontend et le backend. Afin d'obtenir des informations sur les propriétaires, un analyseur statique est utilisé. Mais, bien sûr, ce n'est pas la même chose que dans la première version et ne fonctionnait qu'avec du code Dart. Par exemple, pour les fichiers Java, la bibliothèque javaparser est utilisée . Ces analyseurs fonctionnent selon un calendrier et collectent toutes les informations pertinentes dans un registre.
En plus de lier certains codes aux équipes propriétaires, nous avons construit une intégration avec le service de collecte des erreurs de production et affiché toutes les informations utiles sur les équipes et les fonctionnalités sur une ressource interne. Désormais, n'importe quel employé peut voir à qui s'adresser s'il a soudainement des questions sur une vue particulière. Et nous avons également rendu automatique la création de tâches pour les responsables en cas de changements globaux, comme le passage à une nouvelle version de Dart ou Angular.
 En cliquant sur la commande, vous pouvez voir toutes les fonctionnalités, tous les membres de l'équipe, quelles fonctionnalités sont purement techniques et lesquelles sont des produits
En cliquant sur la commande, vous pouvez voir toutes les fonctionnalités, tous les membres de l'équipe, quelles fonctionnalités sont purement techniques et lesquelles sont des produits
En conséquence, nous avons non seulement un système assez flexible pour relier les fonctionnalités aux équipes, mais également une infrastructure à part entière qui aide, à partir du code, à trouver une fonctionnalité associée, une équipe avec tous les participants, un propriétaire de produit de fonctionnalité et des rapports de bogues.
Parmi les inconvénients figurent la nécessité de surveiller de près le balisage des fonctionnalités lors de la refactorisation et du transfert de code d'un endroit à un autre, et le besoin de puissance supplémentaire pour collecter toutes les informations sur le balisage.
Comment résolvez-vous le problème de la possession de votre code? Et y a-t-il des problèmes connexes et, surtout, leur solution?