
Aujourd'hui, nous allons parler d'un sujet apparemment simple comme les données relationnelles et connexes.
Malgré toute sa simplicité, je remarque que parfois les gens sont vraiment confus à leur sujet - j'ai décidé de résoudre ce problème en écrivant une explication courte et informelle de ce qu'ils sont et pourquoi ils sont nécessaires.
Nous discuterons de ce qu'est le modèle relationnel et du SQL et de l'algèbre relationnelle associés. Passons ensuite aux exemples de données associées de Wikidat, puis RDF, SPARQL et un peu de discussion sur Datalog et la représentation logique des données. En fin de compte, les conclusions - quand appliquer le modèle relationnel, et quand le modèle logique connecté.
Le but principal de l'article est de décrire quand ce qui a du sens à postuler et pourquoi. Comme il y a beaucoup de concepts difficiles qui se sont réunis en un seul endroit, il serait bien sûr possible d'écrire un livre pour chacun - mais notre tâche aujourd'hui est de donner une idée du sujet et nous l'analyserons de manière informelle à l'aide d'exemples simples.
Si vous avez des doutes sur la différence entre l'un et l'autre et pourquoi vous avez besoin de données liées (LinkedData), alors bienvenue sous cat.

Données relationnelles
Commençons par une définition standard: une
base de données relationnelle est un ensemble de données avec des relations prédéfinies entre elles. Ces données sont organisées sous la forme d'un ensemble de tableaux composés de colonnes et de lignes. Les tables stockent des informations sur les objets représentés dans la base de données.
Lorsqu'il est appliqué:
- Modélisation de domaine fixe
- Le schéma de données change peu ou les modifications affectent immédiatement un groupe significatif d'enregistrements
- Requêtes de base - filtrage des catégories par champs clés d'enregistrements, agrégation, génération de rapports et d'analyses basés sur des indicateurs statistiques, etc.
Dans cette situation, l'unité de modélisation est la table et les relations entre les tables (telles que les clés étrangères). En fait, une table est un prédicat avec des attributs fixes, c'est-à-dire nous connaissons toujours l' arité d'un prédicat tabulaire.
Prenons une clé étrangère comme exemple de relations de contraintes: la clé «p (_, X, _) → q (_, Y, _)», qui définit des contraintes sous la forme X \ sous-ensemble Y, où X est un attribut de la relation p, et Y attribut de relation q.

Plus important encore, dans le monde des données relationnelles, nous avons tout une table! Et les opérations prennent une table comme entrée et renvoient une table, par exemple:

Langage de données relationnelles: SQL et algèbre relationnelle
L'algèbre relationnelle (algèbre de Codd) est essentiellement un ensemble d'opérations sur des tables qui renvoient des tables. Autrement dit, pour vous, l'élément central de la modélisation est précisément les tables fixes et leurs transformations.
Le langage SQL est une superstructure déclarative et une implémentation concrète des idées de l'algèbre relationnelle.
Un exemple de requête simple et les opérateurs relationnels correspondants issus de l'algèbre.

Jusqu'à présent, tout ce que nous avons couvert sont les choses classiques que nous savons de tout cours de base de données.
Données liées et graphiques de connaissances
Imaginons simplement ce qui se passera si nous avons de nouvelles propriétés et que cela se produit, peut-être en temps réel? Autrement dit, le domaine n'est pas fixe - mais flexible et extensible ?
Dans une telle situation, bien sûr, nous pouvons ajouter des tables et des colonnes aux tables en injectant des valeurs NULL ou par défaut. Mais en plus d'être techniquement peu pratique, ce n'est pas non plus un outil approprié du point de vue de la modélisation.
Imaginez que vous modélisez la vie des gens sous tous ses aspects possibles. Même deux personnes différentes auront un ensemble assez différent de propriétés clés et c'est tout à fait normal!
Vous n'avez pas de liste fixe de la manière dont un personnage particulier sera décrit.L'écrivain et le joueur de football sont deux personnes qui ont de nombreuses propriétés importantes, mais néanmoins différentes.
Commençons par l'écrivain Douglas Adams - les principales propriétés sont assez typiques pour tout le monde - ici et plus loin, nous utilisons Wikidata comme exemple de LinkedData.
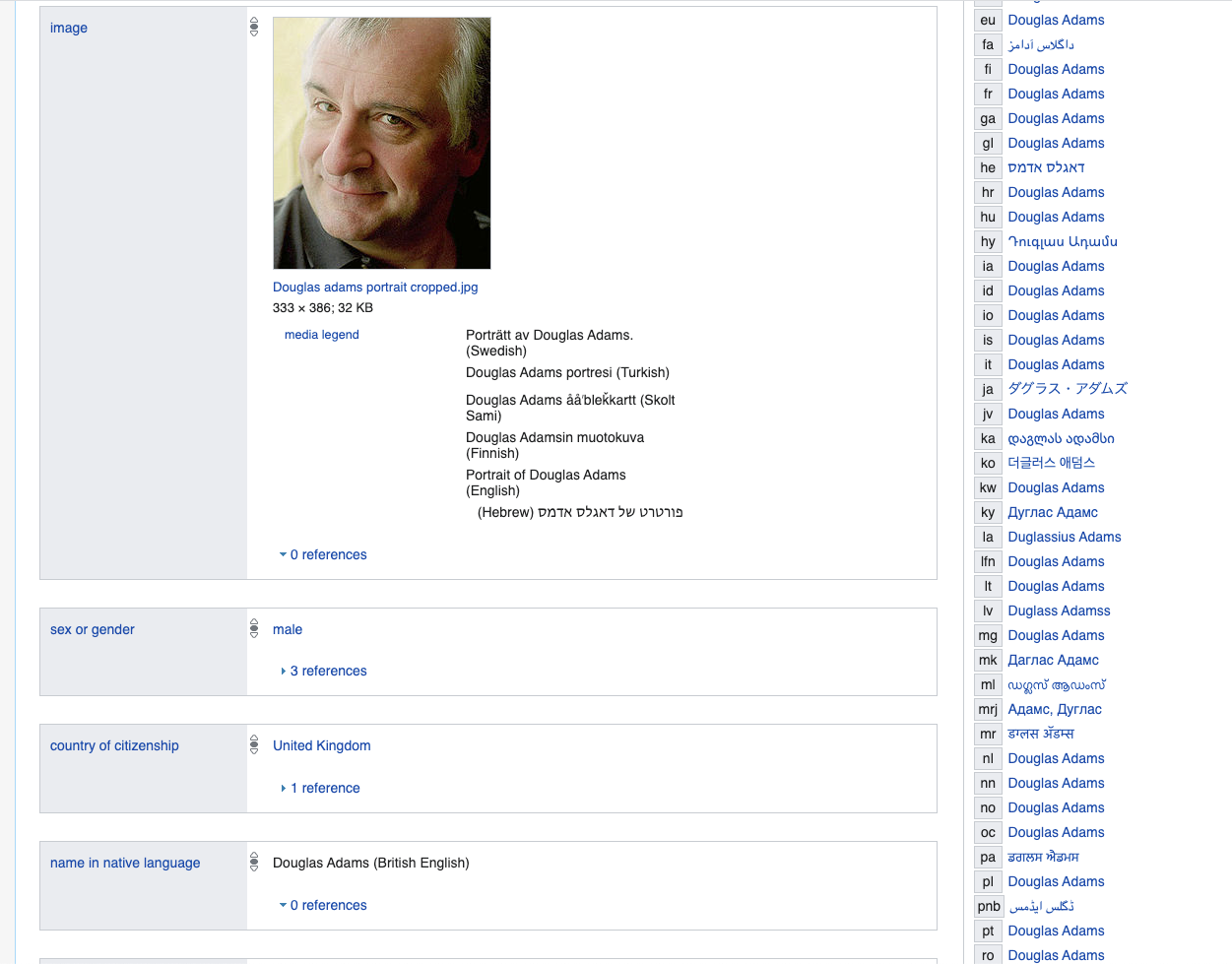
www.wikidata.org/wiki/Q42
Mais creusons un peu plus profondément et
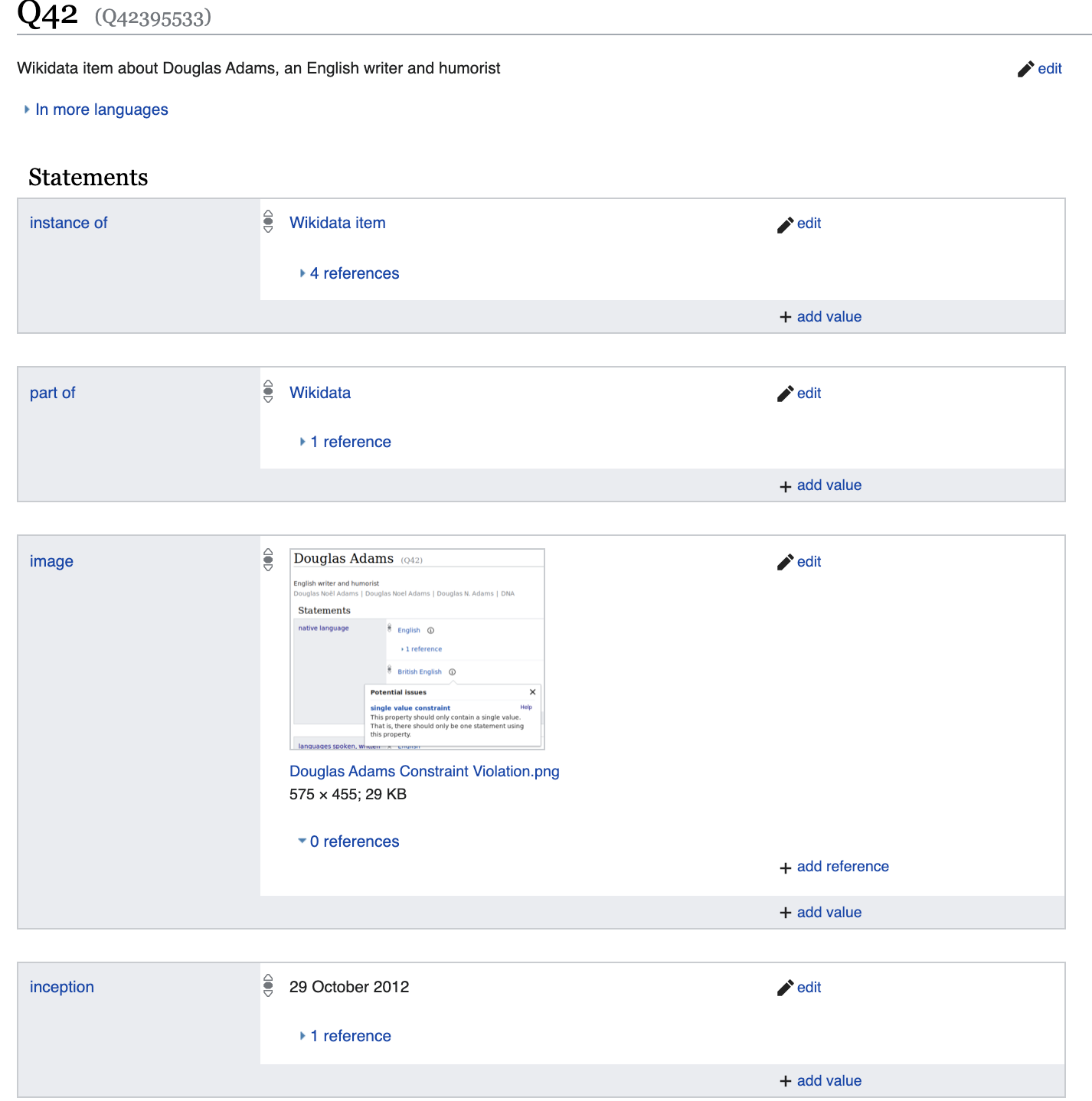
voyons un ensemble de propriétés qui différeront considérablement de, par exemple, Diego Maradonna.
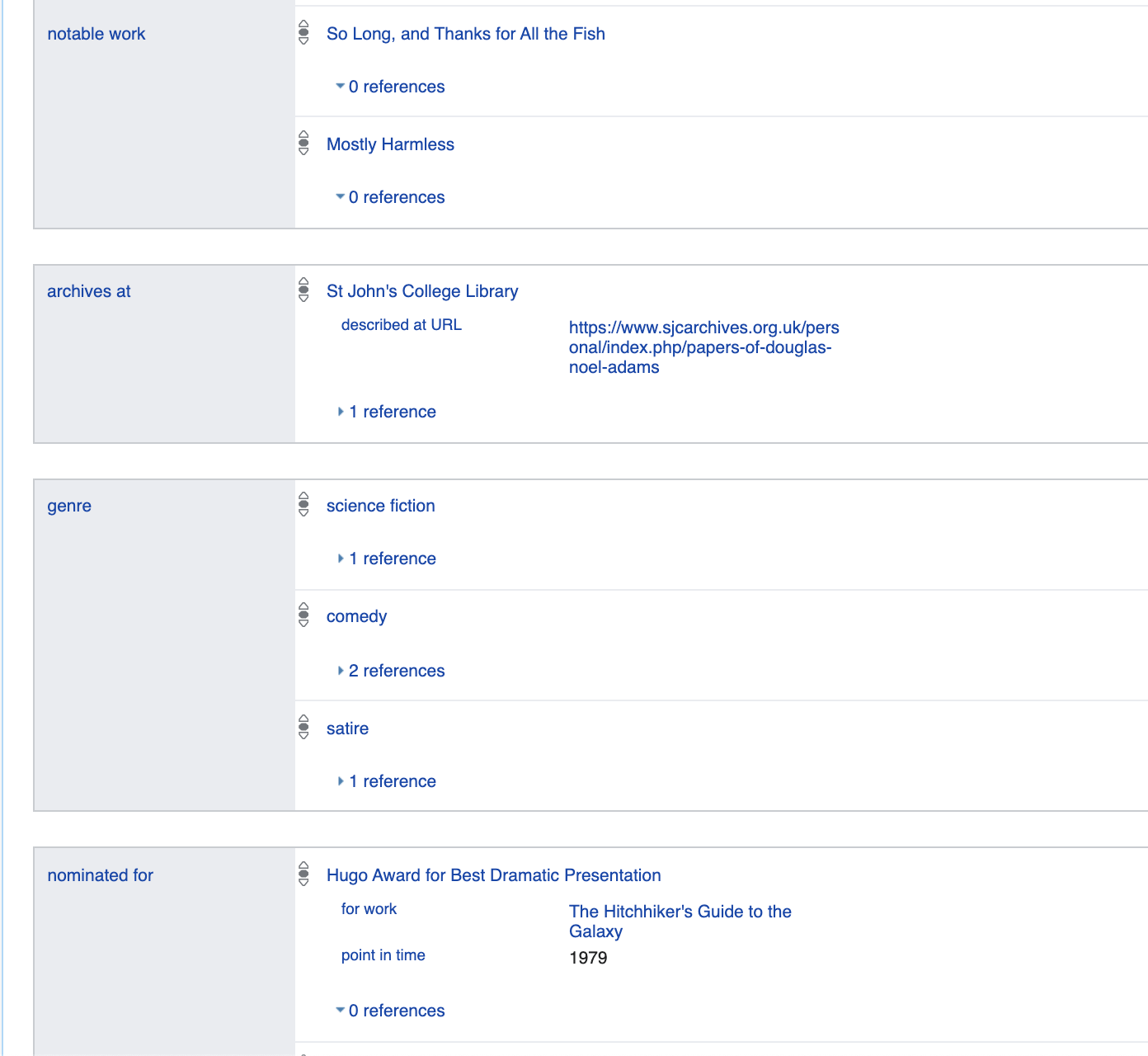
Parlons un peu plus des propriétés spécifiées ici. Par exemple, gender: male est

essentiellement le reflet du fait logique: p21 (Q42, Q6581097).
Où p21 → c'est gender_identity / 2 - un prédicat binaire
Q42 → Douglas Adams
Q6581097 → male
Ainsi, toutes les données sont présentées soit comme prédicats unaires, par exemple is_dead (Q42), soit comme binaire p21 (Q42, Q6581097).
En fait, c'est un autre paradigme de la modélisation - la logique du premier ordre, mais sur des prédicats unaires et binaires.
Et ici, il est très facile d'ajouter de nouvelles données: tout ce qui n'est pas indiqué sous la forme d'un prédicat sur les objets est faux, dans la littérature, il est connu comme l' hypothèse du monde fermé .
De plus, ce format permet une méta-modélisation absolument naturelle
https://www.wikidata.org/wiki/Q42395533
Il existe plusieurs bases de stockage et d'écriture de requêtes sur ces données - regardons les options les plus courantes.
RDF et le langage de requête SPARQL
RDF est un langage formel pour décrire les données associées pour le traitement ultérieur des requêtes, c'est-à-dire qu'il s'agit d'un format lisible par machine.
En fait, pour lui, la clé est le concept de triplet:

Et voici un exemple d'enregistrement de données dans ce modèle (les préfixes déterminent où se trouvent les «descriptions» de ces prédicats)

Ce format d'enregistrement vous permet de représenter graphiquement des données sur des objets - par exemple, vous pouvez écrire des informations sur la ville de Berlin.

Pour le format RDF, ils ont créé le langage de requête SPARQL: qui décrit essentiellement les contraintes sur les prédicats logiques et indique quelle variable doit être extraite de l'expression logique:

Ce que nous voulons en fait trouver est la valeur de la variable? Country telle que member_of est vrai member_of (? Country, q458) et q458 est l'ID UE.
En code réel, cela pourrait ressembler à ceci:
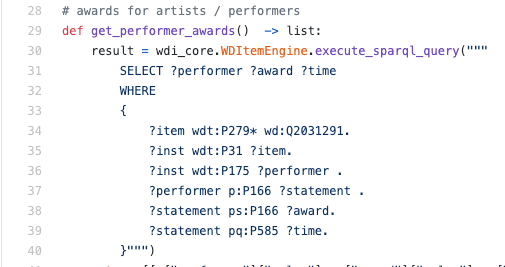
Total: RDF est un format pour représenter des données sous forme de triplets (prédicats binaires) et SPARQL est un langage de requête logique pour les triplets.
Langage de requête de datalog et dérivés
De plus, pour écrire des requêtes sur RDF (et pas seulement vers lui, plus à ce sujet plus tard), vous pouvez utiliser Datalog - un langage déclaratif (souvent) qui représente syntaxiquement un sous-ensemble de Prolog (le plus souvent).
Dans celui-ci, les requêtes ressemblent à ceci:
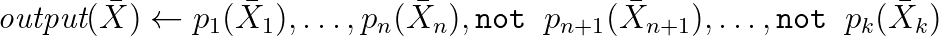
Souvent, la syntaxe est étendue à l'aide d'agrégations et d'autres choses pratiquement importantes. En fait, ce sont des règles d'inférence tirées de la logique, et avec leur aide, vous pouvez modéliser l'inférence de nouvelles propriétés et écrire des requêtes dans RDF. Ce qui suit est un exemple concret de travail avec WikiData basé sur l'un des dialectes

Un autre avantage important des langages de requêtes logiques basés sur Datalog est que pour eux, RDF est simplement un format d'enregistrement de faits (déclarations) de logique binaire. Ils peuvent aussi bien gérer toute autre assertion logique - pas nécessairement binaire.
conclusions
Premièrement, les données relationnelles sont bien adaptées à la modélisation de domaines fixes, où le schéma change rarement ou les changements affectent non seulement des enregistrements uniques, mais des segments entiers.
Deuxièmement, les langages relationnels sont bien adaptés aux tâches de modélisation où vous avez besoin d'extraire des sous-tables, de transformer et de combiner celles existantes - ce n'est pas un outil idéal lorsqu'une partie importante du travail se situe au niveau de la modification et / ou de l'inférence sur un enregistrement particulier.
Troisièmement, si le domaine de la modélisation est un domaine complet, et même évolutif, où même les enregistrements de la même classe sont remarquablement différents, des données cohérentes sont bien adaptées.
Quatrièmement, la représentation standard est RDF et il est logique de l'essayer d'abord. En y vissant les bases de données nécessaires et en utilisant des langages de type SPARQ, vous pouvez extraire les données nécessaires.
Cinquièmement, si la modélisation avec des triplets devient fastidieuse et peu pratique, vous pouvez considérer la représentation logique des données et Datalog comme un langage de requête.

