
Il existe de nombreuses approches pour créer un code d'application pour empêcher la complexité du projet de croître au fil du temps. Par exemple, l'approche orientée objet et de nombreux modèles attachés permettent, si ce n'est de maintenir la complexité du projet au même niveau, au moins de le garder sous contrôle pendant le développement et de mettre le code à la disposition du nouveau programmeur de l'équipe.
Comment gérer la complexité d'un projet de transformation ETL sur Spark?
Ce n'est pas aussi simple.
À quoi cela ressemble-t-il dans la vraie vie? Le client propose de créer une application qui collecte une vitrine. Il semble nécessaire d'exécuter le code via Spark SQL et d'enregistrer le résultat. Lors du développement, il s'avère que la construction de ce magasin nécessite 20 sources de données, dont 15 sont similaires, les autres ne le sont pas. Ces sources doivent être combinées. Ensuite, il s'avère que pour la moitié d'entre eux, vous devez rédiger vos propres procédures d'assemblage, de nettoyage et de normalisation.
Et une simple vitrine, après une description détaillée, commence à ressembler à quelque chose comme ceci:
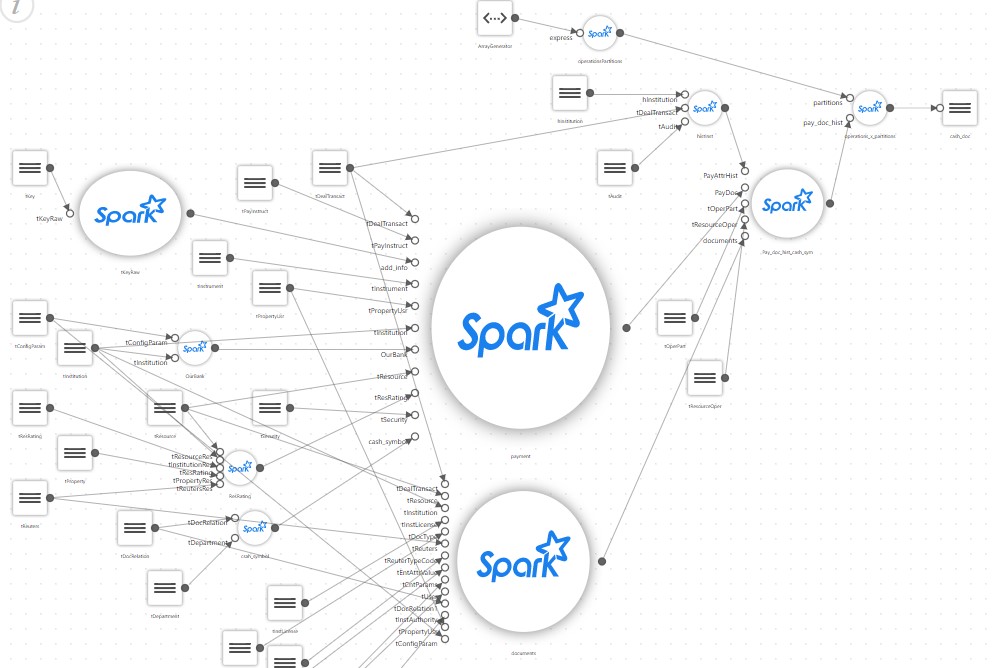
Du coup, un projet simple qui était censé simplement exécuter un script SQL qui collecte la vitrine sur Spark acquiert son propre configurateur, un bloc pour lire un grand nombre de fichiers de configuration, sa propre branche de mappage, des traducteurs de certaines règles spéciales etc.
Au milieu du projet, il s'avère que seul l'auteur peut prendre en charge le code résultant. Et il passe le plus clair de son temps à réfléchir. Pendant ce temps, le client demande à collecter quelques vitrines supplémentaires, à nouveau basées sur des centaines de sources. Dans le même temps, nous devons nous rappeler que Spark n'est généralement pas très adapté à la création de vos propres frameworks.
Par exemple, Spark est conçu pour que le code ressemble à quelque chose comme ceci (pseudocode):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)
Au lieu de cela, vous devez faire quelque chose comme ceci:
var Source1 = readSourceProps(“source1”) var sql = readSQL(“destTable”) writeSparkData(source1, sql)
Autrement dit, pour retirer des blocs de code dans des procédures séparées et essayer d'écrire quelque chose de votre propre, universel, qui peut être personnalisé par des paramètres.
Dans le même temps, la complexité du projet reste au même niveau, bien sûr, mais uniquement pour l'auteur du projet, et seulement pour une courte période. Tout programmeur invité prendra beaucoup de temps à maîtriser, et l'essentiel est que cela ne fonctionnera pas pour attirer des personnes qui ne connaissent que SQL dans le projet.
C'est dommage, car Spark en lui-même est un excellent moyen de développer des applications ETL pour ceux qui ne connaissent que SQL.
Et au cours du développement du projet, il s'est avéré qu'une chose simple était devenue complexe.
Imaginez maintenant un vrai projet, où il y a des dizaines, voire des centaines, de vitrines telles que dans l'image, et elles utilisent différentes technologies, par exemple, certaines d'entre elles peuvent être basées sur l'analyse de données XML, et d'autres sur des données en streaming.
J'aimerais en quelque sorte maintenir la complexité du projet à un niveau acceptable. Comment cela peut-il être fait?
La solution peut être d'utiliser un outil et une approche low-code, lorsque l'environnement de développement décide pour vous, ce qui prend toute la complexité, offrant une approche pratique, comme, par exemple, décrit dans cet article .
Cet article décrit les approches et les avantages de l'utilisation de l'outil pour résoudre ces types de problèmes. En particulier, Neoflex propose sa propre solution Neoflex Datagram, qui est utilisé avec succès par différents clients.
Mais il n'est pas toujours possible d'utiliser une telle application.
Que faire?
Dans ce cas, nous utilisons une approche qui est classiquement appelée Orc - Object Spark, ou Orka, comme vous le souhaitez.
Les données initiales sont les suivantes:
Il y a un client qui fournit un lieu de travail où il existe un ensemble standard d'outils, à savoir: Hue pour le développement de code Python ou Scala, les éditeurs Hue pour le débogage SQL via Hive ou Impala, et Oozie Workflow Editor. Ce n'est pas beaucoup, mais assez pour résoudre des problèmes. Il est impossible d'ajouter quelque chose à l'environnement, il est impossible d'installer de nouveaux outils, pour diverses raisons.
Alors, comment développer des applications ETL qui, comme d'habitude, deviendront un grand projet, dans lequel des centaines de tables de sources de données et des dizaines de marchés cibles seront impliqués, sans se noyer dans la complexité et sans trop écrire?
Un certain nombre de dispositions sont utilisées pour résoudre le problème. Ils ne sont pas leur propre invention, mais sont entièrement basés sur l'architecture de Spark elle-même.
- Toutes les jointures, calculs et transformations complexes sont effectués via Spark SQL. L'optimiseur Spark SQL s'améliore avec chaque version et fonctionne très bien. Par conséquent, nous confions tout le travail de calcul de Spark SQL à l'optimiseur. Autrement dit, notre code repose sur la chaîne SQL, où l' étape 1 prépare les données, l' étape 2 joint, l' étape 3 calcule, et ainsi de suite.
- Spark, Spark SQL. (DataFrame) Spark SQL.
- Spark Directed Acicled Graph, , , , , 2, 2.
- Spark lazy, , , .
En conséquence, toute l'application peut être rendue très simple.
Il suffit de créer un fichier de configuration dans lequel définir une liste à un seul niveau de sources de données. Cette liste séquentielle de sources de données est l'objet qui décrit la logique de l'ensemble de l'application.
Chaque source de données contient un lien vers SQL. En SQL, pour la source actuelle, vous pouvez utiliser une source qui n'est pas dans Hive, mais décrite dans le fichier de configuration au-dessus de l'actuel.
Par exemple, la source 2, lorsqu'elle est traduite en code Spark, ressemble à ceci (pseudocode):
var df = spark.sql(“select * from t1”); df.saveAsTempTable(“source2”);
Et la source 3 peut déjà ressembler à ceci:
var df = spark.sql(“select count(*) from source2”) df.saveAsTempTable(“source3”);
Autrement dit, la source 3 voit tout ce qui a été calculé avant elle.
Et pour les sources qui sont des vitrines cibles, vous devez spécifier les paramètres pour enregistrer cette vitrine cible.
En conséquence, le fichier de configuration de l'application ressemble à ceci:
[{name: “source1”, sql: “select * from t1”}, {name: “source2”, sql: “select count(*) from source1”}, ... {name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]
Et le code de l'application ressemble à ceci:
List = readCfg(...) For each source in List: df = spark.sql(source.sql).saveAsTempTable(source.name) If(source.target == true) { df.write(“format”, source.format).save(source.path) }
C'est, en fait, toute l'application. Rien d'autre n'est requis sauf un moment.
Comment déboguer tout ça?
Après tout, le code lui-même dans ce cas est très simple, ce qu'il y a à déboguer, mais la logique de ce qui est fait serait agréable à vérifier. Le débogage est très simple - vous devez passer par toutes les applications jusqu'à la source en cours de vérification. Pour ce faire, ajoutez un paramètre au flux de travail Oozie qui vous permet d'arrêter l'application à la source de données requise en imprimant son schéma et son contenu dans le journal.
Nous avons appelé cette approche Object Spark dans le sens où toute la logique d'application est découplée du code Spark et stockée dans un fichier de configuration unique et assez simple, qui est l'objet de description de l'application.
Le code reste simple, et une fois créé, même des vitrines complexes peuvent être développées à l'aide de programmeurs qui ne connaissent que SQL.
Le processus de développement est très simple. Au début, un programmeur Spark expérimenté est impliqué, qui crée du code universel, puis le fichier de configuration de l'application est édité en y ajoutant de nouvelles sources.
Ce que cette approche donne:
- Vous pouvez impliquer des programmeurs SQL dans le développement;
- Compte tenu du paramètre dans Oozie, le débogage d'une telle application devient facile et simple. Il s'agit de déboguer toute étape intermédiaire. L'application fonctionnera tout à la source désirée, la calculera et s'arrêtera;
- ( … ), , , , , . , Object Spark;
- , . . , , , XML JSON, -. , ;
- . , , , , .