
AWS Fault Injection Simulator (FIS)- un outil qui vous permet de mettre en œuvre des scénarios précédemment connus de défaillance du système interne dans les services AWS. Pourquoi? - afin que les équipes puissent élaborer des scénarios pour leur élimination et, de manière générale, évaluer le comportement de leur produit dans les conditions proposées. Le système proposera immédiatement plusieurs modèles avec des scénarios de panne, par exemple, un ralentissement des serveurs, leur panne, une erreur d'accès à la base de données ou son crash. Dans le même temps, le FIS s'assurera que l'expérience n'ira pas trop loin et lorsque certains paramètres seront atteints, les tests seront arrêtés et le système reviendra à la normale. Le slogan principal du nouveau produit du géant du cloud est "accroître la résilience et les performances grâce à la technologie du chaos contrôlé". La sortie du nouveau système de test est prévue pour 2021.
AWS propose également des tests et des systèmes virtualisés distribués qui dépendent moins d'un seul hôte. La spécificité d'une défaillance dans un système distribué est que le problème peut être cyclique et avoir une structure plus complexe. La nouvelle fonctionnalité AWS vous permettra de rechercher des vulnérabilités non seulement dans l'infrastructure des monolithes, mais également dans les systèmes et applications distribués.
Voyons pourquoi c'est important et cool.
L'ingénierie du chaos est un processus de test de simulation dans lequel le principal impact du système vient de l'intérieur et affecte l'infrastructure du projet. L'équipe simule des situations dans lesquelles la partie infrastructure du projet est confrontée à des problèmes techniques et autres, par exemple avec une baisse ponctuelle ou systémique des performances sur les instances. Cela peut également inclure des pannes de serveur, des échecs d'API et d'autres cauchemars du backend auxquels l'équipe peut faire face à tout moment ou, pire encore, le jour de la sortie de la prochaine version.
Il n'y a pas encore de définition sans ambiguïté de l'ingénierie du chaos, voici donc quelques-unes des options les plus populaires et, à notre avis, les plus précises. L'ingénierie du chaos est: «une approche qui consiste à expérimenter un système de production pour s'assurer qu'il peut résister à diverses perturbations qui se produisent pendant le fonctionnement» et «une expérience pour atténuer les effets d'une défaillance».
Pourquoi AWS Fault Injection Simulator est-il vraiment nécessaire?
Les développeurs de l'outil citent plusieurs raisons pour lesquelles le FIS sera utile aux équipes lors du test et de la préparation de leurs systèmes.
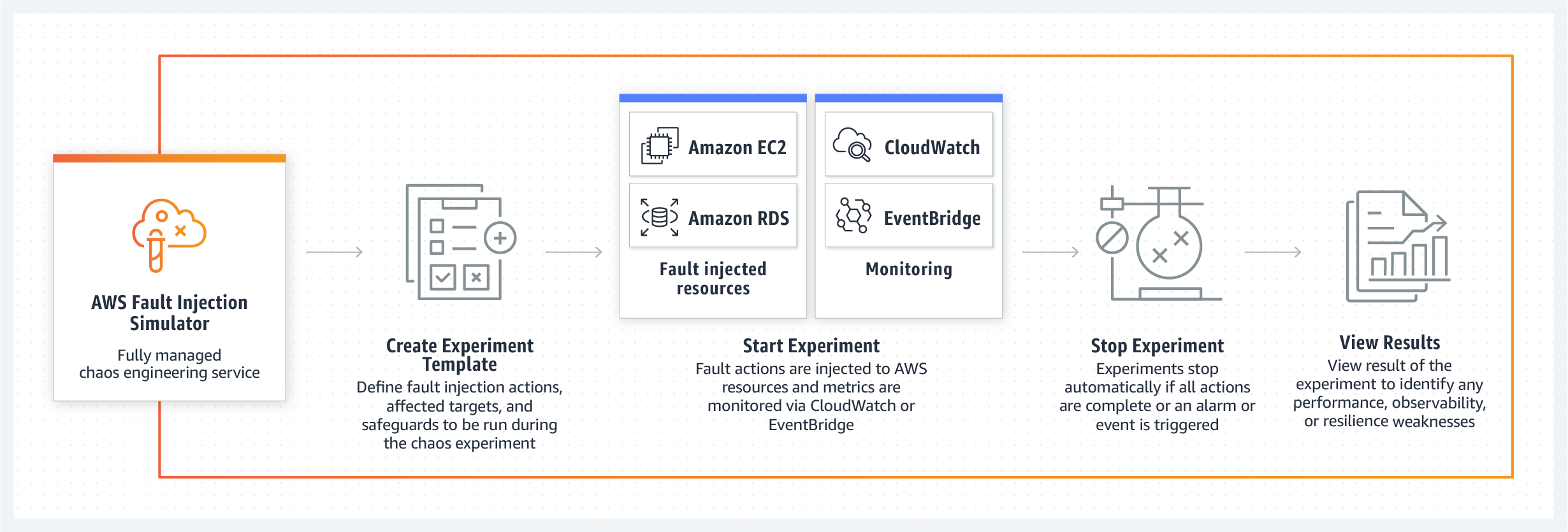
Les performances, la résilience et la transparence du système sont l'un des principaux messages de l'équipe AWS FIS.
AWS Fault Injection Simulator , , «» , .
En fait, les méthodes de test habituelles sont, tout d'abord, la simulation de la charge externe sur le système. Par exemple, simuler un effet habra ou une attaque DDoS externe sur un système ou un service. Le plus souvent, tous les principaux systèmes de surveillance sont précisément liés à ces nœuds, tandis que le suivi du comportement de l'infrastructure interne se limite souvent à la réception de données dans le style "down / down" ou à la charge sur le processeur. Dans le même temps, les plus gros dégâts et les pannes les plus puissantes de ces dernières années sont précisément associés à des pannes internes ou des erreurs d'infrastructure. Il suffit de rappeler le crash de CloudFlare de l'année dernière, lorsque, en raison d'un certain nombre d'échecs et d'erreurs, les développeurs ont littéralement forcé la moitié d'Internet à «se coucher» de leurs propres mains.
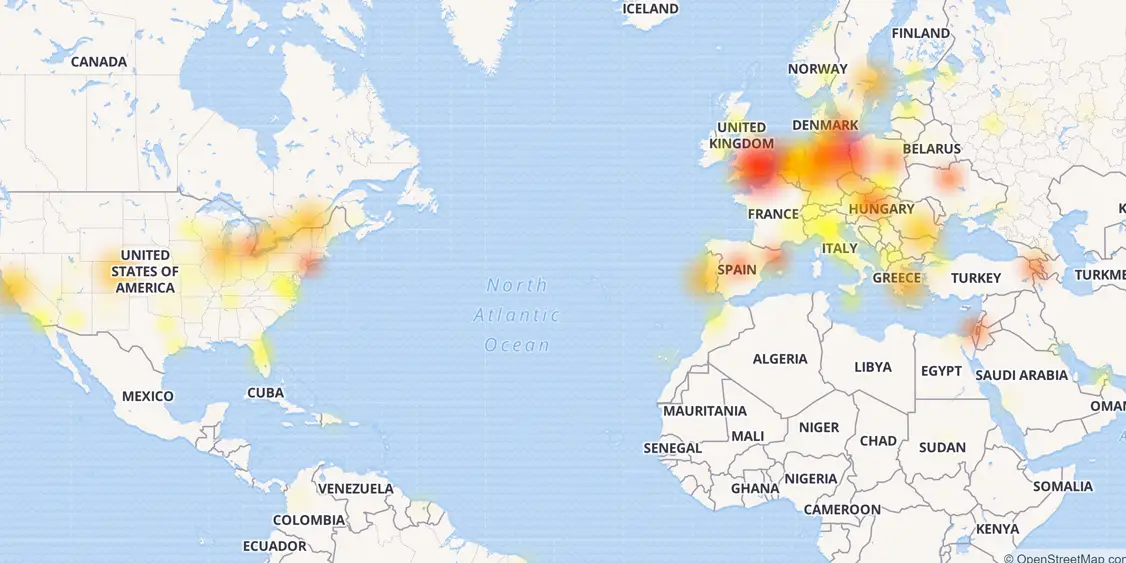
Carte de cet échec CloudFlare
Le nouvel outil est capable d'élaborer à la fois des modèles prêts à l'emploi pour des scénarios de panne de base de données, d'API ou de dégradation des performances, ainsi que de créer des conditions de test aveugle aléatoires dans lesquelles des problèmes se produiront dans une séquence arbitraire sur différents nœuds.
Un autre point fort de la nouvelle boîte à outils AWS est la contrôlabilité du chaos créé par l'équipe dans le système. Les ingénieurs s'assurent qu'avec l'aide de leur panneau de contrôle, les développeurs peuvent arrêter un scénario de panne contrôlée à tout moment et remettre le système dans son état de fonctionnement d'origine. Fault Injection Simulator prend en charge Amazon CloudWatch et les outils de surveillance tiers connectés via Amazon EventBridge, afin que les développeurs puissent utiliser leurs métriques pour surveiller les expériences de chaos contrôlées. Et, bien sûr, après l'arrêt du test, l'administrateur recevra un rapport complet sur les nœuds du système et dans quel ordre ont été affectés par la panne, ce qui aidera à l'avenir à développer un ensemble de mesures et de procédures pour localiser et éliminer les problèmes.
Comment les Seigneurs du Chaos sont nés
De toute évidence, de tels tests de résistance du système sont plus logiques à effectuer dans la période de pré-publication afin de s'assurer que l'infrastructure existante sur AWS résistera au nouveau correctif. Cependant, en réalité, la technique d'ingénierie du chaos remonte à des pratiques plus anciennes, dont le fondateur est l'un des gestionnaires d'Amazon dans les années 2000, Jesse Robbins. Sa position était officiellement appelée «Master of Disaster», qui dans une traduction pathétique peut être confondue avec «Lord of Disasters», et dans une version gratuite, sa position ressemblait à «Master Lomaster».
 C'est Robbins, un ancien pompier-sauveteur, qui a
implémenté GameDay chez Amazon.... Le but de l'initiative Robbins était extrêmement simple: développer une compréhension intuitive parmi les équipes d'ingénierie de la façon de faire face à une catastrophe, de la même manière que ce sentiment est formé dans les pompiers. C'est pour cela que la méthode de simulation globale du chaos total a été choisie: tout se décompose de tous côtés, simultanément ou séquentiellement, et chaque tentative de faire face à l'échec conduit à des problèmes nouveaux et nouveaux.
C'est Robbins, un ancien pompier-sauveteur, qui a
implémenté GameDay chez Amazon.... Le but de l'initiative Robbins était extrêmement simple: développer une compréhension intuitive parmi les équipes d'ingénierie de la façon de faire face à une catastrophe, de la même manière que ce sentiment est formé dans les pompiers. C'est pour cela que la méthode de simulation globale du chaos total a été choisie: tout se décompose de tous côtés, simultanément ou séquentiellement, et chaque tentative de faire face à l'échec conduit à des problèmes nouveaux et nouveaux.
Lorsqu'une personne non préparée est confrontée à l'émeute des éléments, elle tombe le plus souvent dans un état de stupeur ou de panique. La plupart des développeurs et des ingénieurs ne sont pas prêts psychologiquement pour une situation où la résolution d'un problème devrait prendre trois jours et où le niveau de stress est tout simplement hors de l'échelle.
Robbins appelle le résultat le plus important de GameDay l'effet psychologique de tels exercices: ils développent la capacité d'accepter le fait que des perturbations à grande échelle se produisent . C'est l'acceptation du fait que tout autour est en feu et s'effondre, il l'appelle très important pour l'ingénieur, afin qu'il puisse rassembler ses pensées et enfin commencer à «éteindre le feu». Une personne non formée va, au mieux, tourner en rond et crier "tout est perdu".
Après l'introduction de la pratique GameDay, il s'est avéré que de tels exercices révélaient parfaitement des problèmes d'architecture et des goulots d'étranglement auxquels on ne prêtait pas attention lors des tests et des vérifications classiques.
Une autre différence significative entre GameDay et nos exercices habituels «d'entraînement et d'ordre» est que peu de gens connaissent le scénario spécifique et ce qui va se passer en général. Les informations sur les «jeux» à venir sont données de manière très générale et vague, de sorte que les participants n'ont pas pu se préparer complètement à cet événement. Idéalement, pour n'annoncer que la date du prochain «jour de jeu» sans aucune clarification du tout, afin que les participants ne la prennent pas pour un véritable accident. Bien sûr, cette méthodologie ne s'adapte pas à une grande entreprise, par exemple, GameDay ne peut pas être exécuté partout sur Yandex ou Microsoft à la fois.
En conséquence, la pratique a été modernisée en GameDay local et a été introduite dans toutes les grandes entreprises informatiques existantes, par exemple dans Google, Flickr et bien d'autres. Il dispose de ses propres Masters of Disasters (enfin, ou Master-Lommasters, comme vous le souhaitez), qui organisent les échecs de formation puis analysent les résultats obtenus sur des projets spécifiques.
La principale difficulté à mettre en œuvre cette pratique partout réside dans deux aspects: comment l'organiser et comment collecter des données pour que GameDay ne soit pas vain. C'est pourquoi, dans les petites entreprises, jusqu'à récemment, cette technique n'était pas très largement utilisée (voire pas du tout). Au lieu de GameDay et de simulation de catastrophe, l'entreprise s'est davantage concentrée sur différents types de tests, CI / CD et autres méthodologies pour un développement ordonné et cohérent. Autrement dit, sur ce qui empêche la catastrophe en tant que telle.
La nouvelle boîte à outils AWS vous permettra de vous attaquer à l'autre côté de la perturbation: au lieu de la prévention, ce qui est sans aucun doute important, FIS permettra aux équipes d'ingénierie de toutes tailles de se former efficacement à la résolution des défaillances d'infrastructures mondiales. Après tout, la principale chose que note Robbins est que les catastrophes se produisent de toute façon: elles ne peuvent être évitées.