À l'heure actuelle, l'une des tendances dans l'étude des réseaux de neurones graphiques est l'analyse du fonctionnement de telles architectures, la comparaison avec les méthodes nucléaires, l'évaluation de la complexité et la capacité de généralisation. Tout cela aide à comprendre les faiblesses des modèles existants et crée de l'espace pour de nouveaux.
Le travail vise à étudier deux problèmes liés aux réseaux de neurones graphiques. Premièrement, les auteurs donnent des exemples de graphes dont la structure est différente, mais impossible à distinguer pour les GNN simples et plus puissants . Deuxièmement, ils ont lié l'erreur de généralisation pour les réseaux de neurones graphiques plus précisément que les limites VC.
introduction
Les réseaux de neurones graphiques sont des modèles qui fonctionnent directement avec des graphiques. Ils vous permettent de prendre en compte des informations sur la structure. Un GNN typique comprend un petit nombre de couches qui sont appliquées séquentiellement, mettant à jour les représentations de sommets à chaque itération. Exemples d'architectures populaires: GCN , GraphSAGE , GAT , GIN .
Le processus de mise à jour des plongements de sommets pour toute architecture GNN peut être résumé par deux formules:

où AGG est généralement une fonction invariante aux permutations ( somme , moyenne , max etc.), COMBINE est une fonction qui combine la représentation d'un sommet et de ses voisins.

Les architectures plus avancées peuvent prendre en compte des informations supplémentaires telles que les caractéristiques des bords, les angles des bords, etc.
L'article considère la classe GNN pour le problème de classification des graphes. Ces modèles sont structurés comme ceci:
Premièrement, les sommets peuvent être intégrés en utilisant L étapes de convolutions de graphe
(, sum, mean, max)
GNN:
(LU-GNN). GCN, GraphSAGE, GAT, GIN
CPNGNN, , 1 d, d - ( port numbering)
DimeNet, 3D-,
LU-GNN
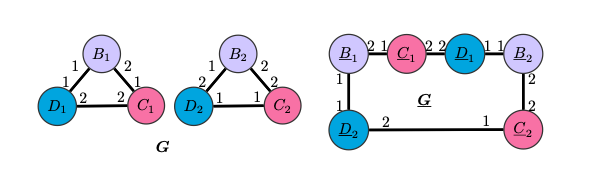
G G LU-GNN, , , readout-, . CPNGNN G G, .
CPNGNN

, “” , CPNGNN .
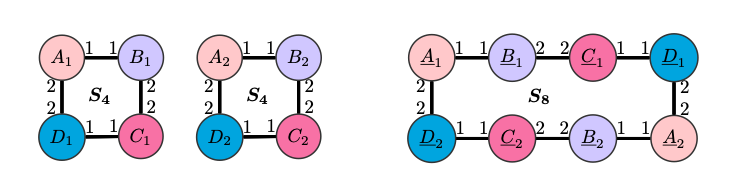
S8 S4 , , ( ), , , CPNGNN readout-, , . , .
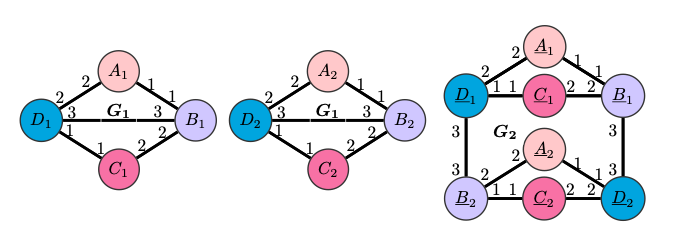
CPNGNN G2 G1. , DimeNet , , , , 
 .
.
DimeNet

DimeNet G4 , G3, . , . , G4 G3 S4 S8, , , DimeNet S4 S8 .
GNN
. , , .
GNN, :
DimeNet
message-



 , c - i- v, t - .
, c - i- v, t - .
:

readout-
.
: LU-GNN,

 - ,
- ,  - v, ,
- v, ,  . ,
. , 
 ,
,  .
.  GNN.
GNN.
. 
 .
.
 - GNN
- GNN  ,
,  - ,
- ,  .
.
,  ,
, - :
![loss _ {\ gamma} \ left (a \ right) = \ mathbb {I} \ left [a> 0 \ right] + (1 + \ frac {a} {\ gamma}) \ mathbb {I} \ left [a \ in \ left [\ gamma, 0 \ right] \ right].](https://habrastorage.org/getpro/habr/upload_files/10f/f87/63c/10ff8763ced82f8bcc4a3f1514442cd6.svg)
GNN 
 :
:

, , , , GNN . , (GNN, ), , , .
, :
,
( )

 - “ ”:
- “ ”:  , r - , d - , m - , L - ,
, r - , d - , m - , L - ,  - ,
- ,

( ), . , , , , , , .
Des preuves et des informations plus détaillées peuvent être trouvées en lisant l' article original ou en regardant un rapport de l'un des auteurs.