
Ce problème se pose également lors de la conception d'agents artificiels. Par exemple, un agent d'apprentissage par renforcement peut trouver le chemin le plus court pour recevoir une grande quantité de récompenses sans terminer la tâche comme prévu par le concepteur humain. Ce comportement est courant et nous avons collecté environ 60 exemples à ce jour (combinant des listes existantes et des contributions actuelles de la communauté IA). Dans cet article, nous examinerons les causes possibles du jeu en fonction de la spécification, partagerons des exemples où cela se produit dans la pratique et discuterons également de la nécessité de travailler davantage sur des approches de principe pour surmonter les problèmes de spécification.
Regardons un exemple. Dans la tâche de construction avec des blocs Lego, le résultat souhaité était que le bloc rouge soit au-dessus du bloc bleu. L'agent a été récompensé pour la hauteur de la surface inférieure du bloc rouge au moment où il n'a pas touché ce bloc. Au lieu de passer par la manœuvre relativement difficile de ramasser le bloc rouge et de le placer au-dessus du bleu, l'agent a simplement retourné le bloc rouge pour récupérer la récompense. Ce comportement nous a permis d'atteindre notre objectif (le bas du bloc rouge était haut) au détriment de ce qui intéresse vraiment le concepteur (construire sur le haut du bloc bleu).

Apprentissage par renforcement profond pour une manipulation adroite des données.
Nous pouvons regarder le jeu des spécifications sous deux angles. Dans le cadre du développement d'algorithmes d'apprentissage par renforcement (RL), l'objectif est de créer des agents qui apprennent à atteindre un objectif donné. Par exemple, lorsque nous utilisons les jeux Atari comme référence pour l'enseignement des algorithmes RL, l'objectif est d'évaluer si nos algorithmes sont capables de résoudre des problèmes complexes. Qu'un agent résout un problème, en utilisant ou non une échappatoire, n'est pas important dans ce contexte. De ce point de vue, jouer selon les spécifications est un bon signe: l'agent a trouvé une nouvelle façon d'atteindre cet objectif. Ce comportement démontre l'ingéniosité et la puissance des algorithmes pour trouver des moyens de faire exactement ce que nous leur disons de faire.
Cependant, lorsque nous voulons qu'un agent connecte réellement des blocs Lego, cette même ingéniosité peut créer un problème. Dans le cadre plus large de la construction d'agents ciblés qui atteignent un résultat souhaité dans le monde, le jeu de spécifications est problématique car il implique que l'agent exploite une faille de spécification au détriment du résultat souhaité. Ce comportement est dû à un paramètre de problème incorrect et non à une faille dans l'algorithme RL. Outre la conception d'algorithmes, la conception des récompenses est un autre élément nécessaire à la création d'agents ciblés.
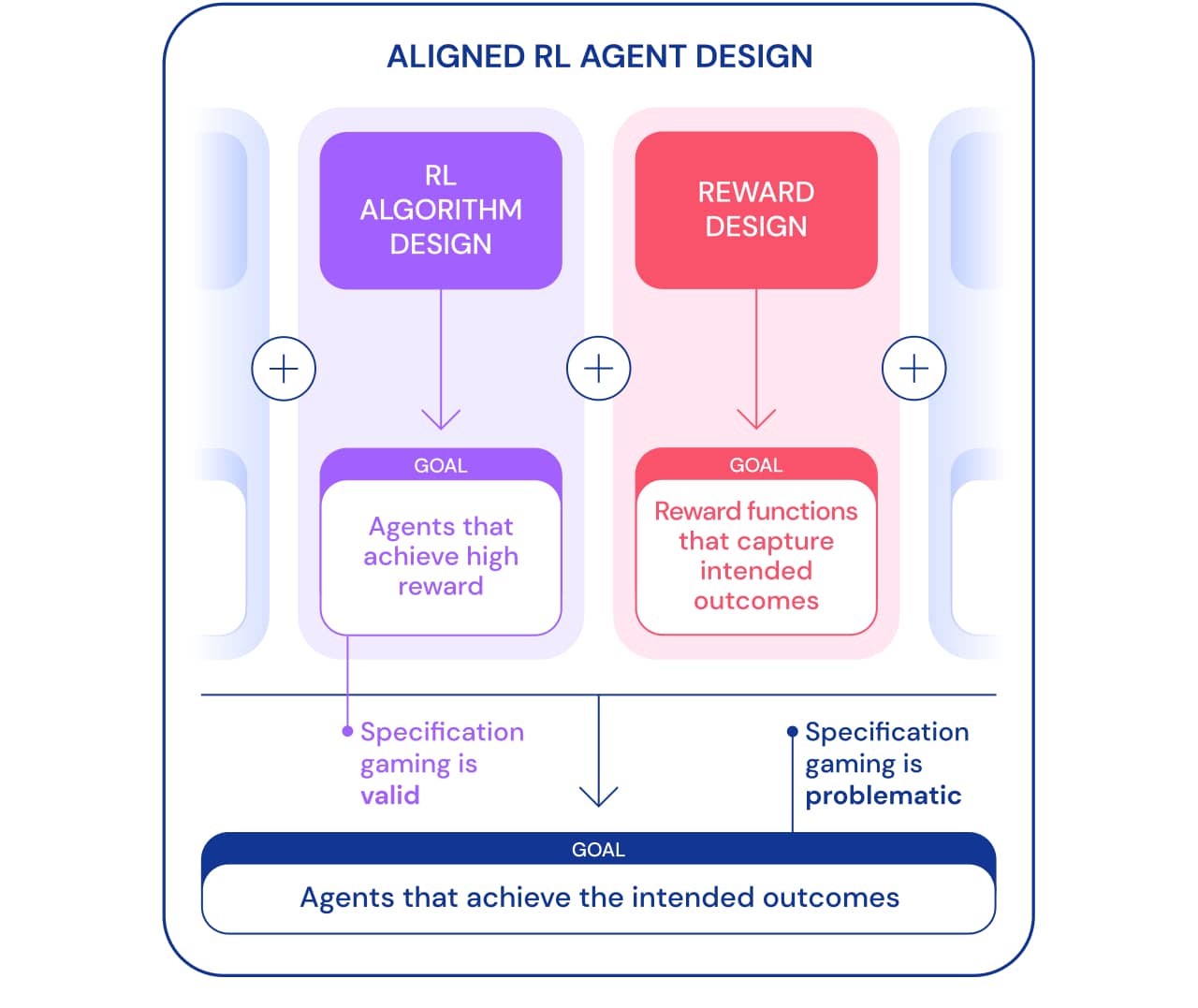
Concevoir des spécifications de tâches (fonctions de récompense, environnement, etc.) qui reflètent fidèlement l'intention du concepteur humain est généralement difficile. Même avec un léger malentendu, un très bon algorithme RL peut trouver une solution complexe qui est très différente de ce qui est prévu; même si un algorithme plus faible ne peut pas trouver cette solution et ainsi rapprocher une solution du résultat attendu. Cela signifie que la définition correcte du résultat souhaité peut devenir plus importante pour y parvenir à mesure que les algorithmes RL s'améliorent. Par conséquent, il est important que la capacité des chercheurs à définir correctement les problèmes ne soit pas en retard sur la capacité des agents à trouver de nouvelles solutions.
Nous utilisons le terme spécification de tâche dans un sens large pour englober de nombreux aspects du processus de développement d'agent. Lors de la configuration d'un RL, la spécification de la tâche comprend non seulement la conception de la récompense, mais également le choix de l'environnement d'apprentissage et des récompenses de soutien. L'exactitude de l'énoncé du problème peut déterminer si l'ingéniosité de l'agent correspond ou non au résultat attendu. Si la spécification est correcte, la créativité de l'agent produit la nouvelle solution souhaitée. C'est ce qui a permis à AlphaGo de faire le fameux 37e coup., qui a surpris les experts de Go par surprise, mais a joué un rôle clé dans le deuxième match contre Lee Sedol. Si la spécification est incorrecte, cela peut conduire à un comportement de jeu indésirable, comme retourner un bloc. De telles solutions sont possibles et nous n'avons aucun moyen objectif de les remarquer.

Voyons maintenant les raisons possibles du jeu de spécifications. L'une des sources d'idées fausses sur la fonction de récompense est la génération de récompenses mal conçue. La formation de récompenses facilite l'assimilation de certains objectifs en donnant à l'agent une récompense sur le chemin de la résolution du problème, au lieu de ne récompenser que pour le résultat final. Cependant, la formation de récompenses peut changer les politiques optimales si elles ne sont pas basées sur la perspective . Pensez à un agent qui dirige un bateau dans Coast Runnersoù l'objectif visé est de terminer la course le plus rapidement possible. L'agent a reçu une récompense formative pour être entré en collision avec des blocs verts le long de la piste de course, ce qui a changé la politique optimale pour contourner et entrer en collision avec les mêmes blocs verts encore et encore.

Fonctions de récompense erronées en action.
Déterminer une récompense qui reflète fidèlement le résultat final souhaité peut être une tâche ardue en soi. Dans le problème de la connexion des blocs Lego, il ne suffit pas d'indiquer que le bord inférieur du bloc rouge doit être haut du sol, car l'agent peut simplement retourner le bloc rouge pour atteindre cet objectif. Une spécification plus complète du résultat souhaité inclurait également que la face supérieure de la boîte rouge soit plus haute que la face inférieure et que la face inférieure soit alignée avec la face supérieure de la boîte bleue. Il est facile d'oublier l'un de ces critères lors de la détermination du résultat, ce qui rend la spécification trop large et potentiellement plus facile à satisfaire avec une solution dégénérée.
Plutôt que d'essayer de créer une spécification couvrant tous les cas possibles, nous pourrions apprendre la fonction de récompense à partir des commentaires humains . Il est souvent plus facile d'évaluer si un résultat a été atteint que de le déclarer explicitement. Cependant, cette approche peut également rencontrer des problèmes de spécification de jeu si le modèle de récompense n'étudie pas la véritable fonction de récompense qui reflète les préférences du concepteur. Une source possible d'inexactitudes pourrait être la rétroaction humaine utilisée pour entraîner le modèle de récompense. Par exemple, l'agent exécutant la tâche de capture a appris à tromper l'évaluateur en survolant la caméra et l'objet.

Renforcez l'apprentissage en profondeur basé sur les préférences humaines.
Le modèle de récompense formé peut également être mal défini pour d'autres raisons, comme une mauvaise généralisation. Des commentaires supplémentaires peuvent être utilisés pour corriger les tentatives de l'agent d'exploiter les inexactitudes dans le modèle de récompense.
Une autre classe de jeu par spécification provient d'un agent exploitant les bogues du simulateur. Par exemple, un robot simulé qui devait apprendre à marcher a eu l'idée de verrouiller ses jambes ensemble et de glisser sur le sol.
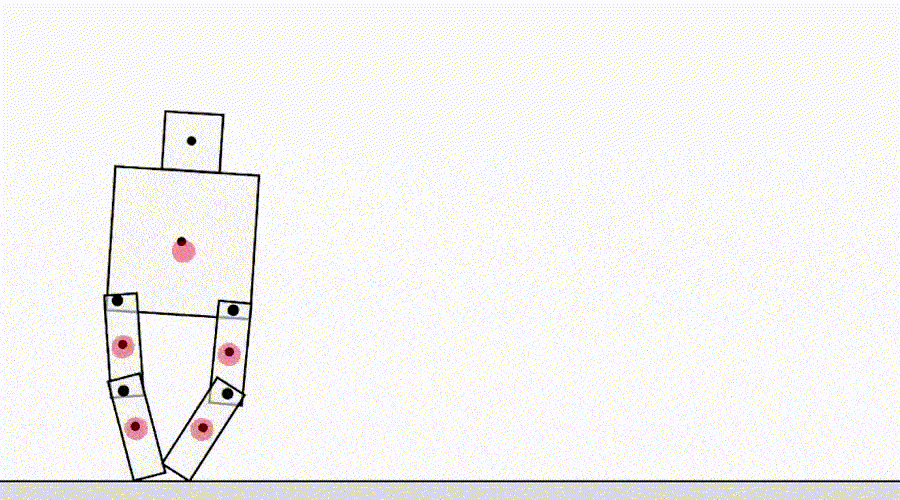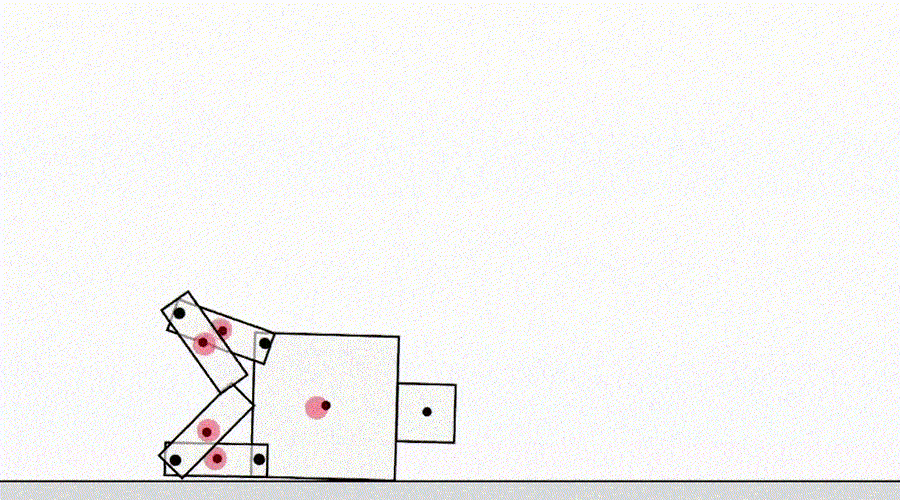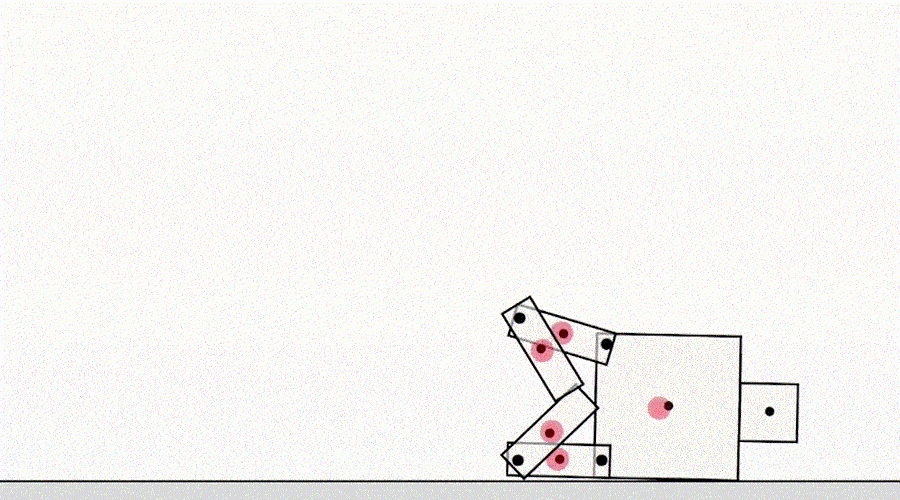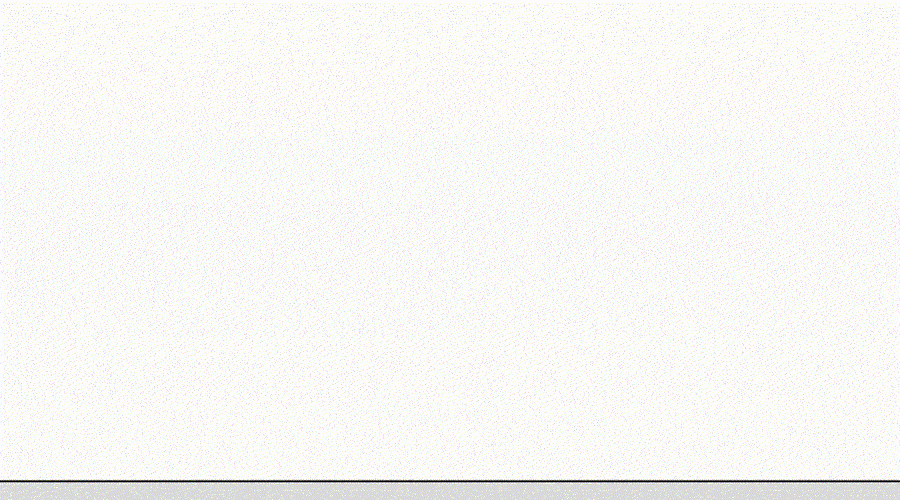
L'IA apprend à marcher.
À première vue, de tels exemples peuvent sembler amusants, mais moins intéressants et n'ont rien à voir avec le déploiement d'agents dans le monde réel, où il n'y a pas d'erreurs de simulateur. Cependant, le problème principal n'est pas l'erreur elle-même, mais l'échec de l'abstraction qui peut être utilisée par l'agent. Dans l'exemple ci-dessus, la tâche du robot a été mal définie en raison d'hypothèses erronées sur la physique du simulateur. De même, l'optimisation du trafic dans le monde réel peut être mal identifiée si l'on suppose que l'infrastructure de routage du trafic ne contient pas de bogues logiciels ou de vulnérabilités de sécurité qu'un agent suffisamment intelligent pourrait détecter. De telles hypothèses n'ont pas besoin d'être formulées explicitement - ce sont plutôt des détails qui n'ont tout simplement jamais traversé l'esprit du concepteur. Et comme les tâches deviennent trop compliquéespour prendre en compte chaque détail, les chercheurs sont plus susceptibles d'introduire des hypothèses incorrectes lors de l'élaboration d'une spécification. Cela soulève la question: est-il possible de concevoir des architectures d'agent qui corrigent ces fausses hypothèses au lieu de les utiliser?
L'une des hypothèses couramment utilisées dans la spécification de tâches est que la spécification ne peut pas être influencée par les actions de l'agent. Ceci est vrai pour un agent opérant dans un simulateur isolé, mais pas pour un agent opérant dans le monde réel. Toute spécification de tâche a une manifestation physique: une fonction de récompense stockée dans un ordinateur ou la préférence d'une personne. Un agent déployé dans le monde réel peut potentiellement manipuler ces notions de finalité, créant le problème de la contrefaçon de récompense . Pour notre système d'optimisation du trafic hypothétique, il n'y a pas de distinction claire entre la satisfaction des préférences des utilisateurs (par exemple en fournissant des conseils utiles) et l' impact sur les utilisateurs.afin qu'ils aient des préférences plus faciles à satisfaire (par exemple, en les poussant à choisir des destinations plus faciles à atteindre). Le premier satisfait la tâche, tandis que le second manipule la vision du monde de l'objectif (préférence de l'utilisateur), et les deux conduisent à des récompenses élevées pour le système d'IA. Autre exemple, plus extrême, un système d'IA très avancé peut prendre le contrôle de l'ordinateur sur lequel il s'exécute, définissant sa propre récompense à une valeur élevée.

Pour résumer, il y a au moins trois défis à surmonter lors de la résolution d'un problème de spécification de jeu:
- Comment capturer avec précision le concept humain d'une tâche donnée en tant que fonction de récompense?
- , , ?
- ?
De nombreuses approches ont été proposées, allant de la modélisation des récompenses au développement d'incitations pour les agents, le problème du jeu par spécification est loin d'être résolu. La liste des comportements de spécification possibles montre l'ampleur du problème et le grand nombre de façons dont un agent peut jouer autour de la spécification. Ces problèmes sont susceptibles de devenir plus complexes à l'avenir à mesure que les systèmes d'IA deviennent plus capables de satisfaire la spécification des tâches au détriment de leur résultat escompté. Au fur et à mesure que nous créons des agents plus avancés, nous aurons besoin de principes de conception qui abordent spécifiquement les problèmes de spécification et garantissent que ces agents atteignent de manière fiable les résultats escomptés par les développeurs.
Si vous voulez en savoir plus sur la machine et l'apprentissage profond, passez nous voir pour le cours approprié, ce ne sera pas facile, mais passionnant. Et le code promo HABR vous aidera dans vos efforts pour apprendre de nouvelles choses en ajoutant 10% à la réduction sur la bannière.

- Cours d'apprentissage automatique
- Cours avancé "Machine Learning Pro + Deep Learning"
- Formation aux métiers de la Data Science
- Formation d'analyste de données
Autres professions et cours