Bref, je dirai qu'elle imitait une ville à part entière et plutôt grande, dans laquelle il y avait pratiquement de tout - de l'aéroport aux institutions financières en passant par un parc d'attractions! Cela a donné aux attaquants l'occasion de montrer leurs compétences en matière de piratage et aux défenseurs de leurs capacités à détecter et à repousser les menaces.
Alors, la question s'est posée, comment pouvons-nous «observer» cette bataille du point de vue de la sécurité de l'information? En fait, cet article porte sur les détails de la construction d'un tel processus d'observation et les résultats que nous avons obtenus.
Nous avons compris que nous ne devrions pas interférer avec le fonctionnement du site de test, et que le format de l'événement ne nous permet pas de nous engager dans un ajustement détaillé des profils de détection d'attaques, c'est pourquoi des solutions de classe NTA (NTA - Network Traffic Analytics) ont été choisies - ce sont des solutions qui identifient les menaces en analysant la télémétrie du réseau ou, en termes simples, le profil de trafic réseau. La mise en œuvre de tels systèmes est beaucoup plus simple et plus transparente que, par exemple, la mise en œuvre de systèmes classiques de détection et de prévention des intrusions. Cela est dû au fait qu'il n'est pas nécessaire d'apporter des modifications à la topologie du réseau, ainsi qu'au fait que le cœur de ces systèmes est l'apprentissage automatique combiné avec des données de renseignement sur les menaces. Cette approche permet au système non seulement d'identifier rapidement les menaces typiques, mais aussi «d'apprendre» sur une certaine période de temps,puis utilisez les connaissances acquises pour détecter les comportements anormaux des utilisateurs, des systèmes et des applications. De plus, ces systèmes, simplement dans leur approche, sont nettement moins «bruyants» en termes d'avertissement sur toutes sortes de menaces et beaucoup plus précis en termes d'identification d'incidents réels. Sur cette brève excursion dans ce sujet, je terminerai, qui veut en savoir plus à ce sujet, je vous conseille de faire attention
sur ce matériel .
Au départ, j'ai décidé d'utiliser le produit bien connu Cisco Stealthwatch Enterprise, qui est utilisé avec succès par nombre de mes collègues dans différentes organisations. Et j'étais sur le point d'appeler mes collègues de Positive pour leur dire de combien de processeurs, d'espace disque, de machines virtuelles, etc. j'ai besoin. À ce moment-là, une pensée étrange m'est venue - je me suis souvenu du nombre de ressources, à la fois humaines et techniques, qui avaient été mises à la création de ce cyber polygone, et je pensais que personne ne s'attendait à ce que je demande certaines de ces ressources. En revanche, je ne voulais pas abandonner l'idée, et dans le cadre des tendances modernes en matière de sécurité de l'information, j'ai décidé de passer à une solution cloud appelée Stealthwatch Cloud. Je dois dire que cette solution s'appelle cloud pour une raison, puisqu'elle permet de collecter et d'analyser la télémétrie des clouds privés,créé dans des clouds publics via des interfaces de programmation d'application (API). Autrement dit, avec l'aide de cette solution, je peux analyser, du point de vue de la sécurité de l'information, ce qui se passe dans Amazon AWS, Microsoft Azure, Google GCP, ainsi que dans les conteneurs Kubernetes. Mais maintenant, j'avais besoin d'une autre application pour ce produit - à savoir la surveillance des réseaux privés. Dans ce cas, un capteur (capteur) est simplement installé dans une telle grille, qui envoie la télémétrie à la console de surveillance et de contrôle basée sur le cloud. Dans la phrase précédente, j'ai utilisé le mot «simple» et je vais maintenant essayer de l'élargir plus en détail.ainsi que les conteneurs Kubernetes. Mais maintenant, j'avais besoin d'une autre application pour ce produit - à savoir la surveillance des réseaux privés. Dans ce cas, un capteur (capteur) est simplement installé dans une telle grille, qui envoie la télémétrie à la console de surveillance et de contrôle basée sur le cloud. Dans la phrase précédente, j'ai utilisé le mot «simple» et je vais maintenant essayer de l'élargir plus en détail.ainsi que les conteneurs Kubernetes. Mais maintenant, j'avais besoin d'une autre application pour ce produit - à savoir la surveillance des réseaux privés. Dans ce cas, un capteur (capteur) est simplement installé dans une telle grille, qui envoie la télémétrie à la console de surveillance et de contrôle basée sur le cloud. Dans la phrase précédente, j'ai utilisé le mot «simple» et je vais maintenant essayer de l'élargir plus en détail.
Alors, à quoi ressemble le processus?
Vous devez demander un essai, cela prend quelques minutes.
Lien ici .
Puis, dans quelques jours, diverses lettres utiles commencent à arriver et à la fin une lettre arrive que le portail est activé!
Après cela, vous obtenez un portail personnel, dont le lien ressemble à ceci:
cisco-YOUR_CISCO_USERNAME.obsrvbl.com , par exemple: cisco-mkader.obsrvbl.com .
En y entrant, nous voyons l'écran principal, à partir duquel vous pouvez télécharger une machine virtuelle de capteur pour surveiller les réseaux privés. Les exigences pour cette machine virtuelle ne sont pas grandes - 2 processeurs virtuels, 2 gigaoctets de mémoire et 32 gigaoctets d'espace disque. En général, le processus d'installation est extrêmement simple et est décrit dans un manuel exceptionnellement simple et pratique, réalisé sous la forme d'un livre électronique déroulant .
Je dois dire tout de suite que le capteur a deux interfaces - l'une sert à la communication avec la console de contrôle et collecte également la télémétrie sur elle-même, par exemple NetFlow, et surveille en même temps tout le trafic qui y arrive. Le second peut fonctionner en mode de capture de paquets (mode promiscuité) et générer de la télémétrie sur le trafic capté. Dans notre cas particulier, nous n'avons utilisé que la première interface.
Après l'installation, le capteur s'exécute vers le cloud où se trouve la console - il s'agit en fait d'AWS et produit un beau message:
{"error":"unknown identity","identity":"185.190.117.34"}
C'est la même adresse IP sous laquelle le capteur pense qu'il se voit dans le monde extérieur, franchissant un pare-feu d'entreprise, traduction d'adresse, etc. Juste au cas où, je dirai tout de suite que le capteur a besoin de HTTP et HTTP, ainsi que de la configuration de DNS une. Après avoir reçu le message ci-dessus, il vous suffit de prendre cette adresse et de l'ajouter à la liste de vos capteurs sur la console:
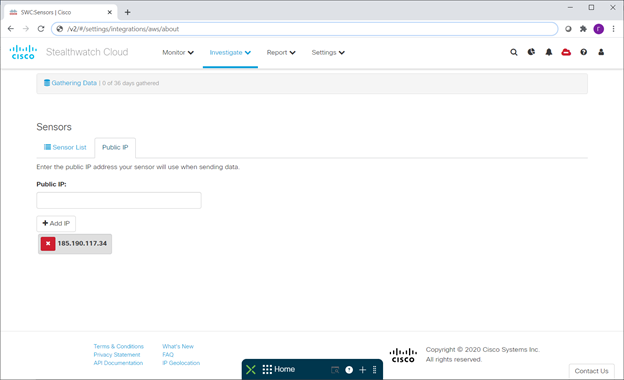
Et après un certain temps, le capteur devient vert - cela signifie que le capteur a établi une connexion à la console.
Et, en général, le lancement du système est terminé sur ce point. L'étape suivante consiste à ajouter des sources de télémétrie, en plus de l'écoute du capteur lui-même. Si nous voulons recevoir des données de télémétrie à l'aide du protocole NetFlow, le site est extrêmement utile .
Sur celui-ci, nous pouvons sélectionner le périphérique réseau dont nous avons besoin, entrer quelques paramètres et obtenir une configuration prête à l'emploi:
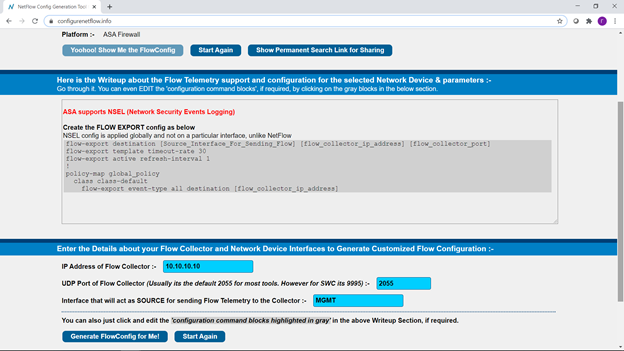
Et copier les informations reçues sur nos périphériques réseau. Voilà, le système est prêt à fonctionner! Au contraire, cela a même commencé à fonctionner.
À propos, des exemples de paramètres Netflow de ce site peuvent être utilisés non seulement pour Steathwatch, mais pour tout autre produit pouvant utiliser une telle télémétrie - par exemple, Cisco Tetration, IBM QRadar, etc.
Vous pouvez maintenant effectuer un réglage fin du système. Je tiens à dire tout de suite que j'aime vraiment regarder comment divers produits de sécurité des informations Cisco m'informent de tout ce qui se passe sur une seule console de surveillance et de réponse Cisco SecureX. En fait, SecureX est une chose extrêmement intéressante et mérite une description séparée. En un mot, il s'agit d'un système de surveillance de la sécurité de l'information (SIEM) basé sur le cloud, d'investigation (Threat Hunting), d'investigation et de réponse aux incidents, et en même temps d'automatisation des processus (SOAR). Je vous recommande vivement de vous familiariser avec ce système plus en détail, et il est "attaché" par défaut à tout produit de sécurité des informations Cisco. Eh bien, un peu de marketing sur ce sujet ici .
Alors, tout d'abord, j'ai mis en place une telle intégration: en

même temps, j'ai mis en place une intégration avec notre plateforme cloud pour fournir des services de sécurité Cisco Umbrella: https://habr.com/ru/company/jetinfosystems/blog/529174/ .
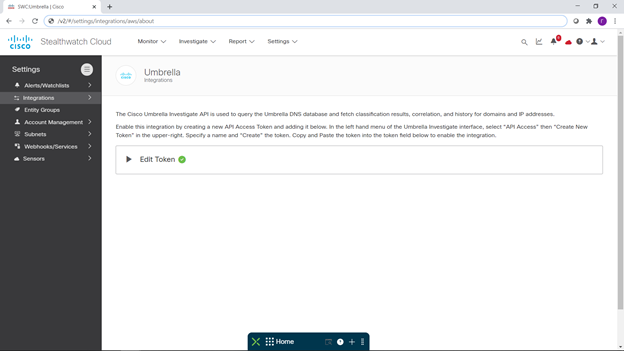
Je n'ai pas placé d'espoir particulier là-dessus, pensant que toutes les choses les plus intéressantes se passeraient à l'intérieur de la décharge, et ce n'était pas ma tâche de protéger cette décharge.
Après cela, je me suis créé une nouvelle console de surveillance dans SecureX. Tout cela a pris un total de 5 minutes, et peut-être même moins. Quelques photos de mon SecureX ci-dessous:


Après cela, j'ai décidé de désactiver les notifications qui ne m'intéressaient pas et d'activer celles qui m'intéressaient. Pour ce faire, je suis retourné sur la console SWC et suis allé mettre en place ces mêmes notifications:
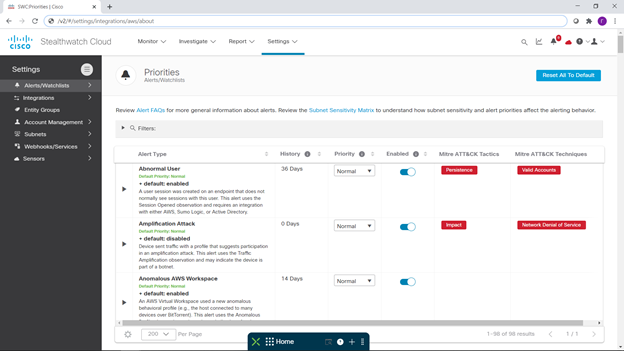
je dirai tout de suite que pour chacune des notifications, vous pouvez voir de quoi il s'agit, combien de jours de collecte d'informations télémétriques sont nécessaires pour détecter la menace correspondante, et comment elle se passe si elle tombe en panne, pour MITRE ATT & CK.
Le nombre de menaces détectées et de notifications associées augmente constamment à mesure que la solution elle-même évolue. Mais je n'ai pas vraiment besoin d'y penser - le cloud, car ils ont ajouté quelque chose de nouveau, est immédiatement à ma disposition.
J'ai désactivé la plupart des notifications liées aux attaques sur les clouds AWS, Azure, GCP, car elles n'étaient pas utilisées dans ce polygone, et j'ai activé toutes les notifications liées aux attaques sur les réseaux privés.
En outre, je peux gérer les politiques de surveillance pour différents sous-réseaux que je souhaite contrôler. Vous pouvez également activer séparément la surveillance pour les pays qui nous intéressent particulièrement:
À ce stade, j'ai lu mon texte ci-dessus et je me suis rendu compte qu'il fallait beaucoup plus de temps pour l'écrire que pour configurer le système, y compris toutes les intégrations.
Maintenant qu'avons-nous vu?
Dans les premiers jours de Standoff, la télémétrie m'a été fournie par quelques-uns de nos pare-feu virtuels ASAv, mais le nombre de sources a légèrement augmenté - plus de pare-feu ont été ajoutés, ainsi que Netflow du courtier de trafic central.
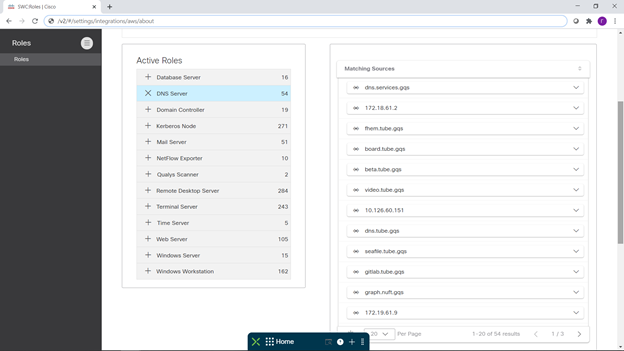
Les premières notifications sont arrivées très rapidement et, comme on pouvait s'y attendre, elles ont été associées à de nombreuses analyses. Eh bien, alors il est devenu plus intéressant de regarder le processus toutes les heures. Je ne décrirai pas ici l'ensemble du processus d'observation, mais je vous parlerai simplement de quelques faits. Premièrement, nous avons réussi à collecter de bonnes informations sur ce qui est quoi sur le site de test:

deuxièmement, pour évaluer l'ampleur de l'événement - avec quels pays était l'échange de trafic le plus actif:
En fait, il existe un format plus pratique pour présenter ces données, mais ici j'ai décidé de montrer plus de détails.
Ainsi, les principaux "externes", outre la Russie, les utilisateurs de la décharge étaient les États-Unis, l'Allemagne, la Hollande, l'Irlande, l'Angleterre, la France, la Finlande, le Canada, bien qu'il y ait eu une interaction avec presque tous les pays, y compris les pays d'Amérique du Sud, d'Afrique et d'Australie:
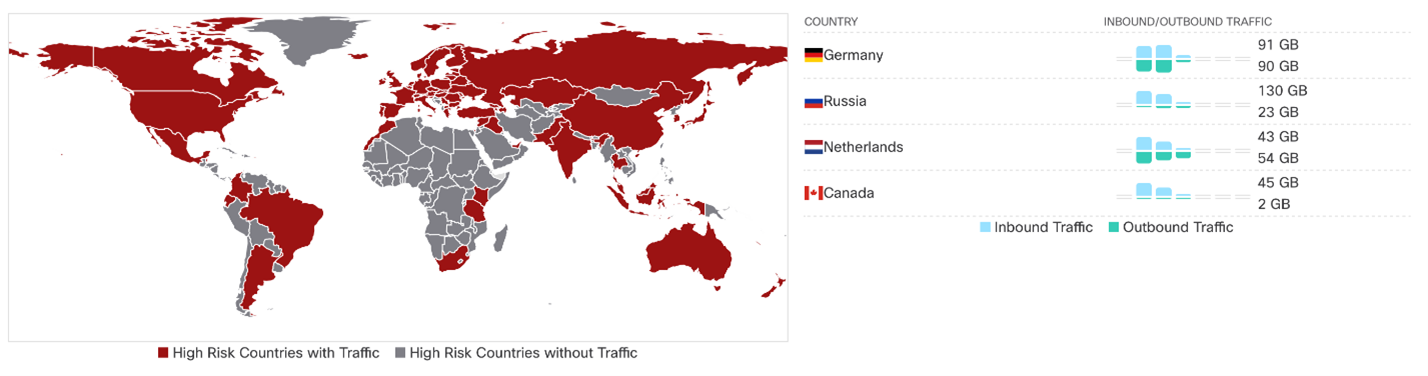
bien sûr, nous pourraient voir à qui appartiennent les adresses qu'ils ont vues:

et, si vous le souhaitez, poser des questions à leur sujet auprès d'autres sources analytiques utiles:

ce qui nous a permis de voir, par exemple, une interaction active avec les ressources Microsoft dans de nombreux pays.
De plus, le tableau des interactions les plus actives pourrait être vu sous la forme d'une image dynamique des connexions avec la possibilité de son analyse plus détaillée:
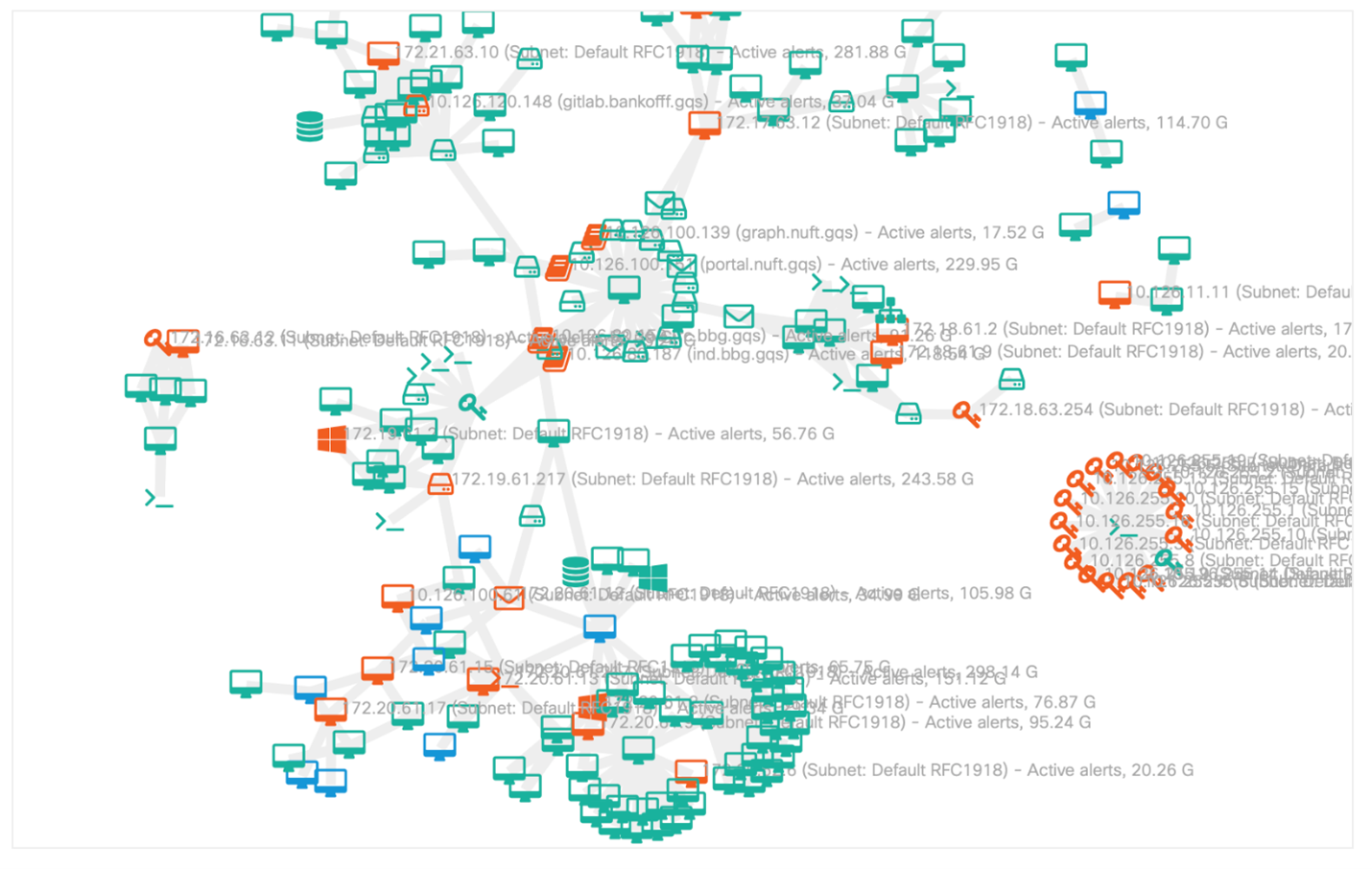
mais qu'avons-nous collecté exactement du point de vue des attaques?
La liste des notifications nous en informe, dont certaines que vous voyez ci-dessous:
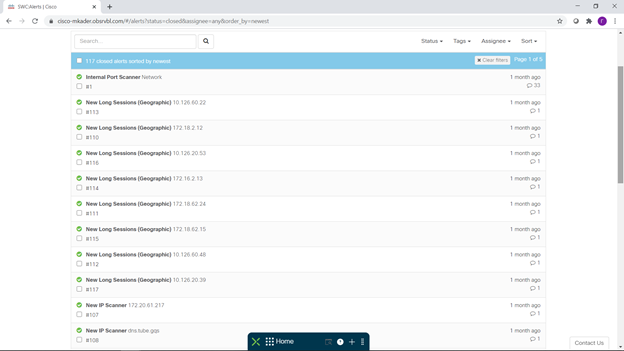
Au total, 117 attaques ont été identifiées, confirmées par de nombreuses observations (Observables) Nous voyons ici des scans de réseau, de longues sessions suspectes, des problèmes avec SMB, une mauvaise utilisation des ports et des services réseau, un comportement étrange nœuds de réseau, changements inattendus de leur comportement et autres bizarreries qui devraient alerter un spécialiste de la sécurité de l'information.
Pour chaque événement qui nous intéresse, nous pouvons obtenir des informations détaillées, notamment de quoi il s'agit, de quoi il s'agit et des recommandations de prévention. Quelques événements intéressants peuvent être vus ci-dessous - un lancement inattendu d'un serveur SSH sur un poste de travail Windows et l'utilisation d'une plage de ports non standard. Vous pouvez également faire attention au fait qu'avec l'intégration configurée, vous pouvez passer directement de la description de l'événement à la console d'enquête SecureX Treat Response pour une analyse détaillée de cet incident:
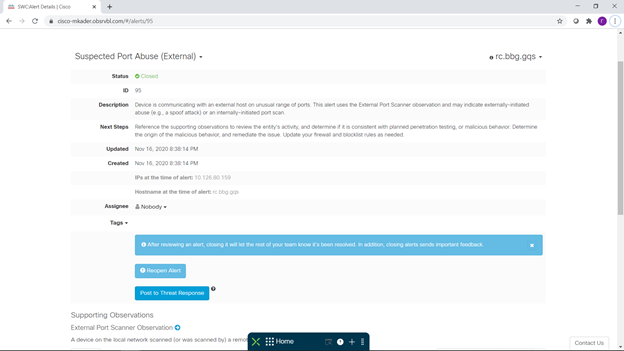
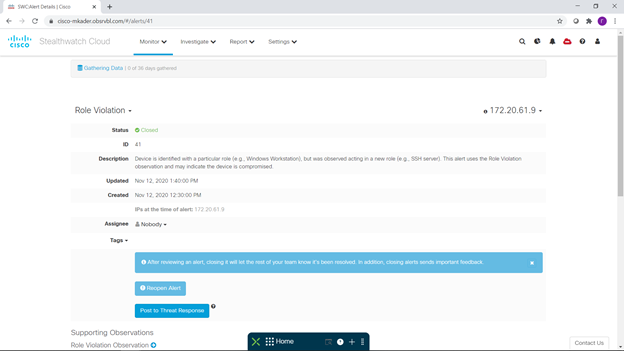
donc, quelques brèves conclusions basées sur les résultats de ce petit pilote divertissant.
Premièrement, Positive Technologies a réalisé d'excellents cyber exercices et c'était très intéressant de les observer un peu «de l'intérieur», et c'était pratique, facile et simple.
Le second, que je dois dire, les solutions de sécurité cloud sont rapides, simples et pratiques. Et s'il y en a encore beaucoup, et que vous pouvez mettre en place une intégration entre eux, c'est aussi très efficace.
Troisièmement, les participants au site de test ont également utilisé activement des services cloud, par exemple des services de Microsoft.
Quatrièmement, l'analyse automatique de la machine de diverses données de télémétrie réseau permet d'identifier facilement les incidents de sécurité de l'information, y compris les activités prévues des intrus. Et je vous conseille de faire attention au fait qu'il existe déjà de nombreux scénarios bien développés pour une utilisation efficace de la solution Cisco Stealthwatch pour les besoins de sécurité de l'information. Chacun des lecteurs peut trouver un script à son goût ici .
Eh bien, et un petit commentaire final - dans cet article, je n'ai délibérément pas énuméré en détail les listes reçues d'adresses IP, de domaines, de détails d'interaction, etc., réalisant combien d'efforts il a fallu à Positive Technologies pour assembler ce polygone et espérant qu'il leur sera utile à plusieurs reprises et nous dans le futur. Et nous ne faciliterons pas la vie des futurs attaquants.