salut! Je m'appelle Dmitry Shelamov et je travaille chez Vivid.Money en tant que développeur backend dans le département Customer Care. Notre entreprise est une startup européenne qui crée et développe des services bancaires par Internet pour les pays européens. Il s'agit d'une tâche ambitieuse, ce qui signifie que sa mise en œuvre technique nécessite une infrastructure bien pensée qui peut supporter des charges élevées et évoluer en fonction des besoins de l'entreprise.
Le projet est basé sur une architecture de microservices qui comprend des dizaines de services dans différentes langues. Ceux-ci incluent Scala, Java, Kotlin, Python et Go. C'est là que j'écris le code, donc les exemples pratiques de cette série utiliseront principalement Go (et certains docker-compose).
Travailler avec des microservices a ses propres caractéristiques, dont l'une est l'organisation des communications entre les services. Le modèle d'interaction dans ces communications peut être synchrone ou asynchrone et peut avoir un impact significatif sur les performances et la tolérance aux pannes du système dans son ensemble.
Communication asynchrone
Alors, imaginons que nous avons deux microservices (A et B). Nous supposerons que la communication entre eux se fait via l'API et qu'ils ne savent rien de l'implémentation interne l'un de l'autre, comme le prescrit l'approche microservice. Le format des données transmises entre eux est préalablement convenu.
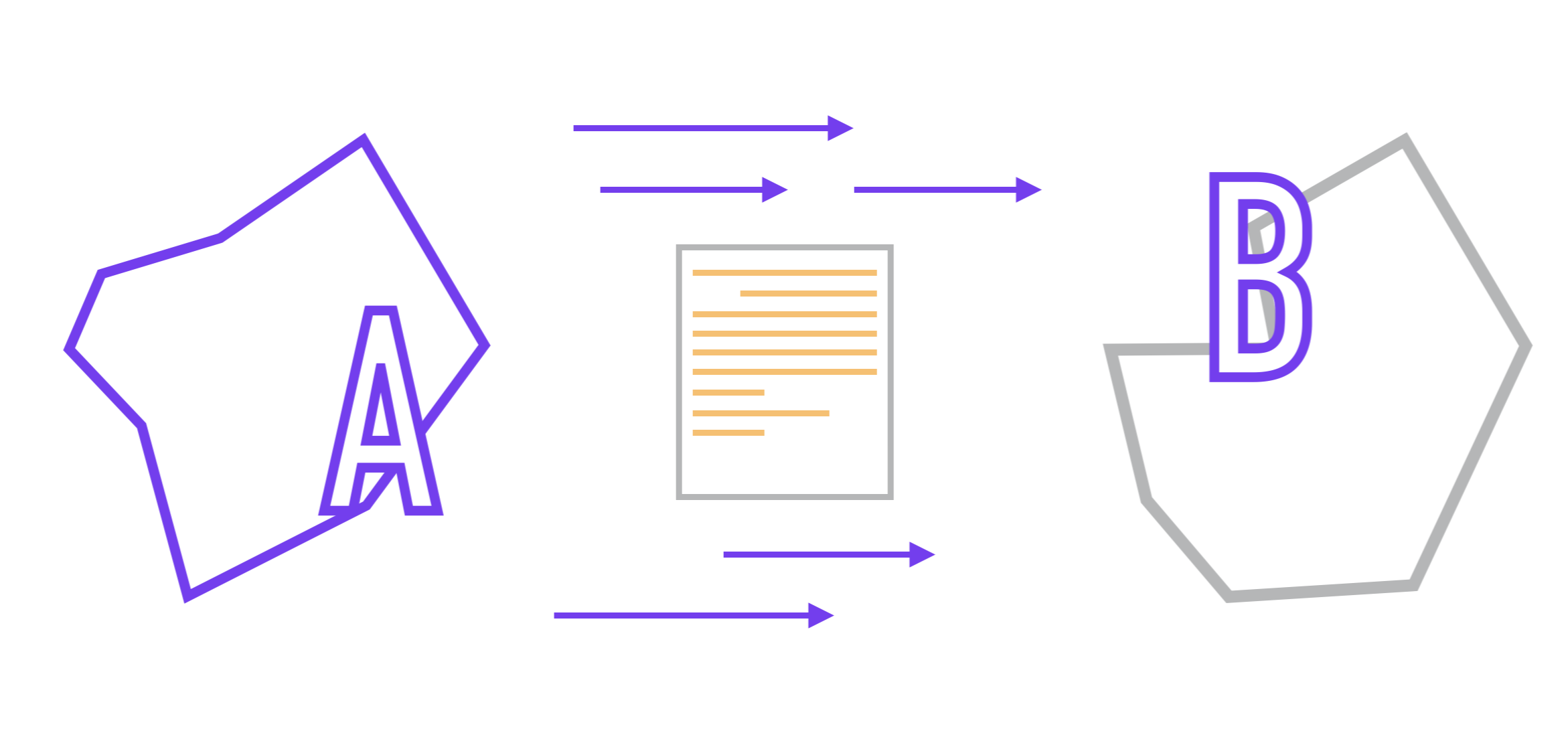
La tâche qui nous attend est la suivante: nous devons organiser le transfert des données d'une application à une autre et, de préférence, avec un minimum de délais.
Dans le cas le plus simple, la tâche est réalisée par interaction synchrone , lorsque A envoie une demande à l'application B, après quoi le service B la traite et, selon que la demande a été traitée avec succès ou non, envoie une réponseservice A qui attend cette réponse.
Si la réponse à la demande n'a pas été reçue (par exemple, B interrompt la connexion avant d'envoyer la réponse, ou A tombe par timeout), le service A peut répéter sa demande à B.
D'une part, un tel modèle d'interaction donne une certitude de l'état de livraison des données pour chaque demande lorsque l'expéditeur sait avec certitude si les données ont été reçues par le destinataire et quelles autres actions il doit faire en fonction de la réponse.
En revanche, le prix à payer attend. Après avoir envoyé une demande, le service A (ou le thread dans lequel la demande est exécutée) est bloqué jusqu'à ce qu'il reçoive une réponse ou considère que la demande a échoué selon sa logique interne, après quoi il entreprend d'autres actions.
Le problème n'est pas seulement que des temps d'attente et des temps d'arrêt ont lieu, mais que des retards dans la communication réseau sont inévitables. Le principal problème est l'imprévisibilité de ce retard. Les participants à la communication dans l'approche microservice ne connaissent pas les détails de la mise en œuvre de l'autre, par conséquent, il n'est pas toujours évident pour le demandeur si sa demande est traitée de manière routinière ou si les données doivent être renvoyées.
Tout ce qui reste avec ce modèle d'interaction est simplement d'attendre. Peut-être une nanoseconde, peut-être une heure. Et ce chiffre est bien réel si B, en cours de traitement de données, effectue des opérations lourdes, comme le traitement vidéo.
Peut-être que le problème ne vous a pas semblé important - un morceau de fer attend que l'autre réponde, la perte est-elle importante?
Pour rendre ce problème plus personnel, supposons que le service A est une application en cours d'exécution sur votre téléphone et pendant qu'il attend une réponse de B, vous voyez une animation de chargement à l'écran. Vous ne pouvez pas continuer à utiliser l'application tant que le service B n'a pas répondu et vous devez attendre. Durée inconnue. Étant donné que votre temps est beaucoup plus précieux que le temps d'exécution d'un morceau de code.
Cette rugosité est résolue comme suit - vous divisez les participants à l'interaction en deux «camps»: certains ne peuvent pas travailler plus vite, peu importe comment vous les optimisez (traitement vidéo), tandis que d'autres ne peuvent pas attendre plus d'un certain temps (interface de l'application sur votre téléphone).
Ensuite, vous remplacez la synchronisationl'interaction entre eux (lorsqu'une partie est obligée d'attendre l'autre pour s'assurer que les données ont été livrées et traitées par le service destinataire) à asynchrone , c'est-à-dire que le modèle de travail est envoyé et oublié - dans ce cas, le service A continuera son travail sans attendre une réponse de B.
Mais comment pouvez-vous vous assurer que le transfert est réussi dans ce cas? Vous ne pouvez pas, par exemple, après avoir téléchargé une vidéo sur un service d'hébergement vidéo, afficher un message à l'utilisateur: "votre vidéo peut être traitée, mais il se peut que ce ne soit pas le cas", car le service qui télécharge la vidéo n'a pas reçu de confirmation du processeur de service que la vidéo a atteint lui sans incident.
Comme l'une des solutions à ce problème, nous pouvons ajouter une couche entre les services A et B, qui agira comme un stockage temporaire et garant de la livraison des données à un rythme convenable pour l'expéditeur et le destinataire. Ainsi, nous pourrons découpler des services dont l'interaction synchrone pourrait potentiellement poser problème:
- Les données qui sont perdues lorsque le service de réception se termine anormalement peuvent à présent être récupérées à partir du stockage intermédiaire pendant que le service d'envoi continue de faire son travail. Ainsi, nous obtenons un mécanisme de garantie de livraison ;
- Cette couche protège également les destinataires des pics de charge, car le destinataire reçoit les données au fur et à mesure de leur traitement et non à leur arrivée;
- Les demandes d'opérations lourdes (telles que le rendu vidéo) peuvent désormais être transmises via cette couche, ce qui réduit la connectivité entre les parties rapides et lentes de l'application.
Un SGBD ordinaire est tout à fait adapté aux exigences ci-dessus. Les données qu'il contient peuvent être stockées pendant une longue période sans se soucier de la perte d'informations. La surcharge des destinataires est également exclue, car ils sont libres de choisir le rythme et les volumes de lecture des documents qui leur sont destinés. La confirmation du traitement peut être réalisée en marquant les enregistrements lus dans les tables correspondantes.
Cependant, le choix d'un SGBD comme outil d'échange de données peut entraîner des problèmes de performances à mesure que la charge de travail augmente. En effet, la plupart des bases de données ne sont pas conçues pour ce cas d'utilisation. De plus, de nombreux SGBD n'ont pas la capacité de séparer les clients connectés en destinataires et expéditeurs (Pub / Sub) - dans ce cas, la logique de livraison des données doit être implémentée côté client.
Nous avons probablement besoin de quelque chose de plus spécialisé qu'une base de données.
Courtiers en messages
Un courtier de messages (file d'attente de messages) est un service distinct qui est responsable du stockage et de la livraison des données des services d'expéditeur aux services destinataires à l'aide du modèle Pub / Sub.
Ce modèle suppose que la communication asynchrone suit la logique suivante de deux rôles:
- Les éditeurs publient de nouvelles informations sous forme de messages regroupés par un attribut;
- Les abonnés s'abonnent aux flux de messages avec des attributs spécifiques et les traitent.
L'attribut de regroupement de messages est la file d'attente , qui est nécessaire pour séparer les flux de données, afin que les destinataires ne puissent s'abonner qu'aux groupes de messages qui les intéressent.
Par analogie avec les abonnements sur diverses plates-formes de contenu - en vous abonnant à un auteur spécifique, vous pouvez filtrer le contenu, en choisissant de ne regarder que celui qui vous intéresse.

La file d'attente peut être considérée comme un canal de communication entre l'écrivain et le lecteur. Les rédacteurs placent les messages dans une file d'attente, après quoi ils sont «poussés» vers les lecteurs qui s'abonnent à cette file d'attente. Un lecteur reçoit un message à la fois, après quoi il devient inaccessible aux autres lecteurs.
Un message, en revanche, est une unité de données, généralement constituée d'un corps de message et de métadonnées de courtier.
En général, un corps est une collection d'octets dans un format spécifique.
Le destinataire doit connaître ce format afin de pouvoir désérialiser son corps pour un traitement ultérieur après avoir reçu un message.
Vous pouvez utiliser n'importe quel format pratique, cependant, il est important de se souvenir de la compatibilité descendante, qui est prise en charge, par exemple, par le binaire Protobuf et le framework Apache Avro.
La plupart des courtiers de messages basés sur AMQP (Advanced Message Queuing Protocol) fonctionnent selon ce principe, un protocole qui décrit une norme pour la messagerie tolérante aux pannes via les files d'attente.
Cette approche nous offre plusieurs avantages importants:
- Faible cohésion. Cela se fait grâce à la transmission de messages asynchrone: c'est-à-dire que l'expéditeur supprime les données et continue de travailler sans attendre une réponse du récepteur, et le récepteur lit et traite les messages quand cela lui convient, et non quand ils ont été envoyés. Dans ce cas, la file d'attente peut être comparée à une boîte aux lettres dans laquelle le facteur dépose vos lettres, et vous les récupérez quand cela vous convient.
- . , ( , ), - .
, . - . - . , , : , , , -, .
- . “at least once” “at most once”.
Élimine au plus une fois le retraitement des messages, mais permet de les perdre. Dans ce cas, le courtier remettra les messages aux destinataires sur une base «envoyer et oublier». Si le destinataire n'a pas pu, pour une raison quelconque, traiter le message lors de la première tentative, le courtier ne le renverra pas.
Au moins une fois , en revanche, garantit que le destinataire recevra le message, mais il y a la possibilité de retraiter les mêmes messages.
Souvent, cette garantie est obtenue en utilisant le mécanisme Ack / Nack (accusé de réception / accusé de réception négatif) , qui prescrit de renvoyer un message si le destinataire, pour une raison quelconque, ne pouvait pas le traiter.
Ainsi, pour chaque message envoyé par le courtier (mais pas encore traité), il y a trois états finaux - le récepteur a renvoyé Ack (traitement réussi), renvoyé Nack (traitement infructueux) ou a abandonné la connexion. Les deux derniers scénarios entraînent un ré-envoi et un nouveau traitement des messages.
Cependant, le courtier peut renvoyer le message même si le destinataire a correctement traité le message. Par exemple, si le destinataire a traité le message, mais est sorti sans envoyer de signal Ack au courtier.
Dans ce cas, le courtier remettra le message dans la file d'attente, après quoi il sera à nouveau traité, ce qui peut entraîner des erreurs et une corruption des données, si le développeur n'a pas fourni de mécanisme pour éliminer les doublons du côté du destinataire.
Il est à noter qu'il existe une autre garantie de livraison appelée «exactement une fois» . C'est difficile à réaliser dans les systèmes distribués, mais c'est aussi le plus souhaitable.
À cet égard, Apache Kafka, dont nous parlerons plus loin, se démarque favorablement dans le contexte de nombreuses solutions disponibles sur le marché. Depuis la version 0.11, Kafka offre une garantie de livraison exactement une foisau sein d'un cluster et des transactions, alors que les courtiers AMQP ne peuvent pas fournir de telles garanties. Les transactions dans Kafka font l'objet d'une publication distincte, nous commencerons aujourd'hui par découvrir Apache Kafka.
Apache Kafka
Il me semble qu'il sera utile pour comprendre de commencer l'histoire de Kafka avec une représentation schématique du dispositif de cluster.
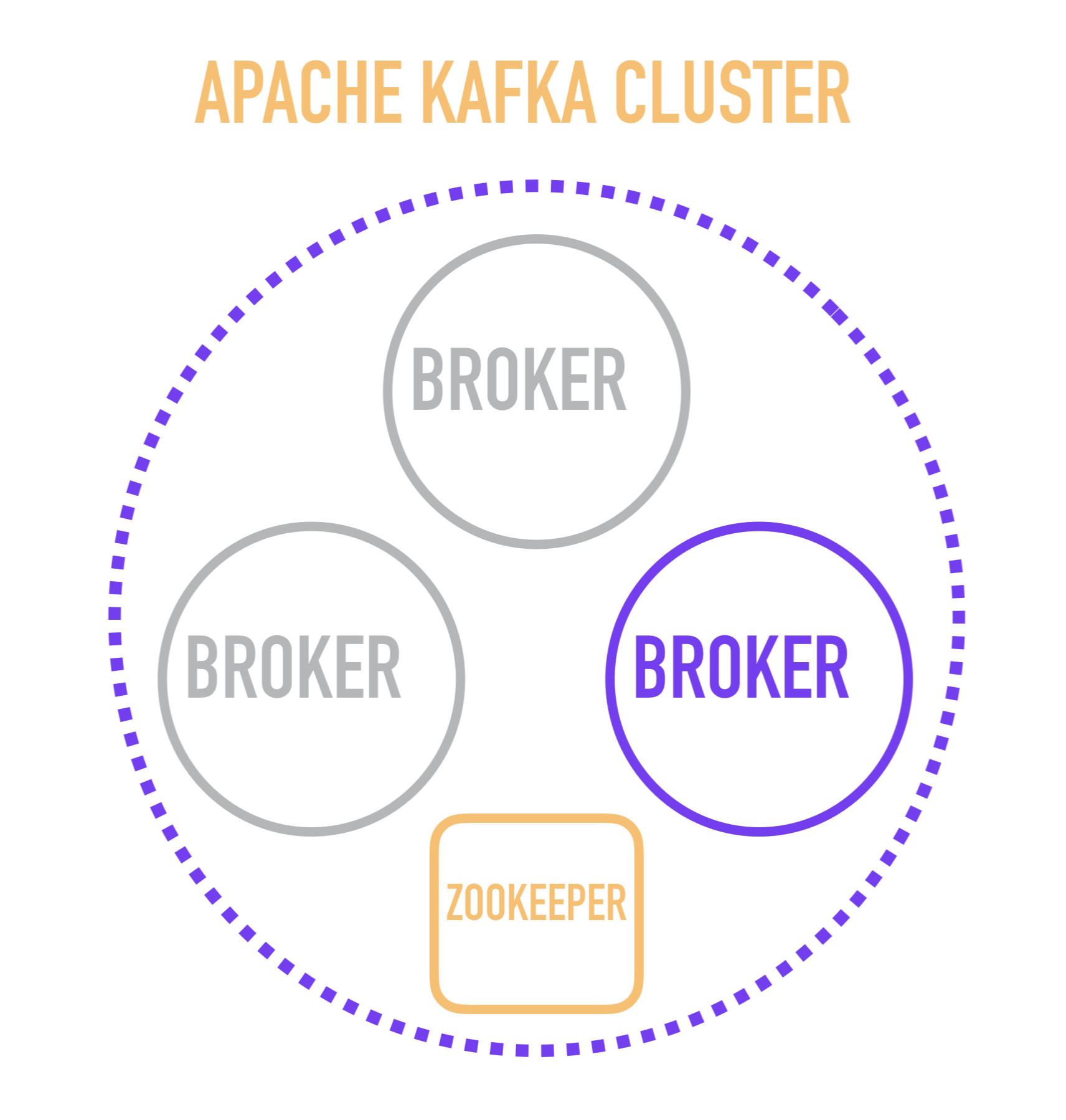
Un serveur Kafka distinct est appelé un courtier . Les courtiers forment un cluster dans lequel l'un de ces courtiers agit en tant que contrôleur qui prend en charge certaines des opérations administratives (marquées en violet).
Le choix d'un courtier-contrôleur, quant à lui, relève de la responsabilité d'un service distinct - ZooKeeper, qui effectue également la découverte de services des courtiers, stocke les configurations et participe à la distribution de nouveaux lecteurs parmi les courtiers et, dans la plupart des cas, stocke des informations sur le dernier message lu pour chacun des lecteurs. C'est un point important, dont l'étude vous oblige à descendre d'un niveau et à réfléchir au fonctionnement d'un courtier distinct à l'intérieur.
Journal de validation
La structure de données sous-jacente à Kafka est appelée journal de validation ou journal de validation.

Les nouveaux éléments ajoutés au journal de validation sont placés strictement à la fin, et leur ordre par la suite n'est pas modifié, de sorte que dans chaque journal individuel, les éléments sont toujours répertoriés dans l'ordre dans lequel ils ont été ajoutés.
La propriété de commande du journal de validation permet de l'utiliser, par exemple, pour la réplication selon le principe de cohérence éventuelle entre les répliques de base de données: ils stockent un journal des modifications apportées aux données dans le nœud maître, dont l'application séquentielle sur les nœuds esclaves permet aux données qu'ils contiennent d'être portées à la valeur convenue avec le maître esprit.
Dans Kafka, ces journaux sont appelés partitions et les données qui y sont stockées sont appelées messages .
Qu'est-ce qu'un message? C'est l'unité de base de données dans Kafka et c'est simplement une collection d'octets dans laquelle vous pouvez transmettre des informations arbitraires - son contenu et sa structure ne sont pas pertinents pour Kafka. Le message peut contenir une clé, qui est également un ensemble d'octets. La clé vous permet de mieux contrôler le mécanisme de distribution des messages aux partitions.
Partitions et sujets
Pourquoi cela pourrait-il être important? Le fait est qu'une partition n'est pas analogue à une file d'attente dans Kafka, comme cela peut sembler à première vue. Permettez-moi de vous rappeler que, techniquement, une file d'attente de messages est un moyen de regrouper et de gérer des flux de messages, permettant à des lecteurs spécifiques de s'abonner uniquement à des flux de données spécifiques.
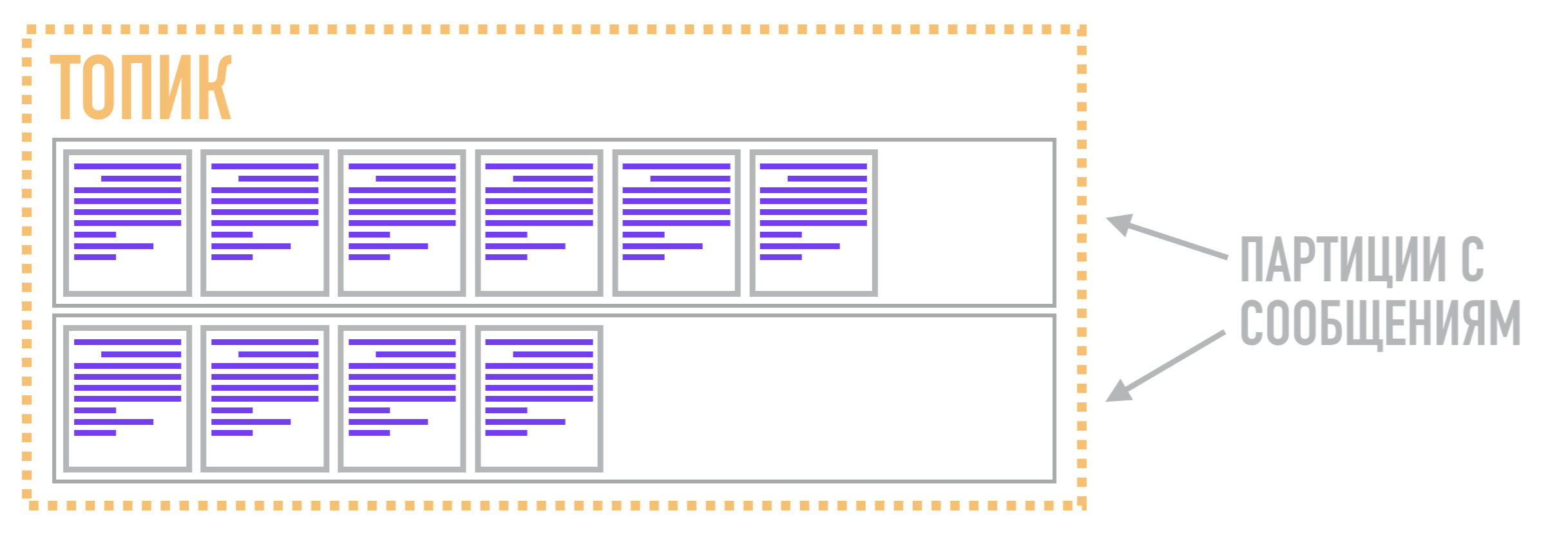
Ainsi, dans Kafka, la fonction de la file d'attente n'est pas assurée par la partition, mais par le sujet . Il est nécessaire de combiner plusieurs partitions dans un flux commun. Les partitions elles-mêmes, comme nous l'avons dit précédemment, stockent les messages sous une forme ordonnée selon la structure des données du journal de validation. Ainsi, un message lié à un sujet peut être stocké dans deux partitions différentes, à partir desquelles les lecteurs peuvent les extraire sur demande.
Par conséquent, l'unité de parallélisme dans Kafka n'est pas un sujet (ou une file d'attente dans les courtiers AMQP), mais une partition. Pour cette raison, Kafka peut traiter différents messages liés au même sujet sur plusieurs courtiers en même temps et répliquer non pas le sujet entier dans son ensemble, mais uniquement des partitions individuelles, offrant une flexibilité et une évolutivité supplémentaires par rapport aux courtiers AMQP.
Tire et pousse
Notez que je n'ai pas accidentellement utilisé le mot «retire» à propos du lecteur.
Dans les courtiers décrits précédemment, les messages sont délivrés en les poussant ( push ) aux destinataires via un canal conditionnel sous la forme d'une file d'attente.
Dans le processus de livraison Kafka lui-même ne l'est pas: chaque lecteur lui-même est responsable d'extraire ( extraire ) les messages des partitions, qu'il lit.
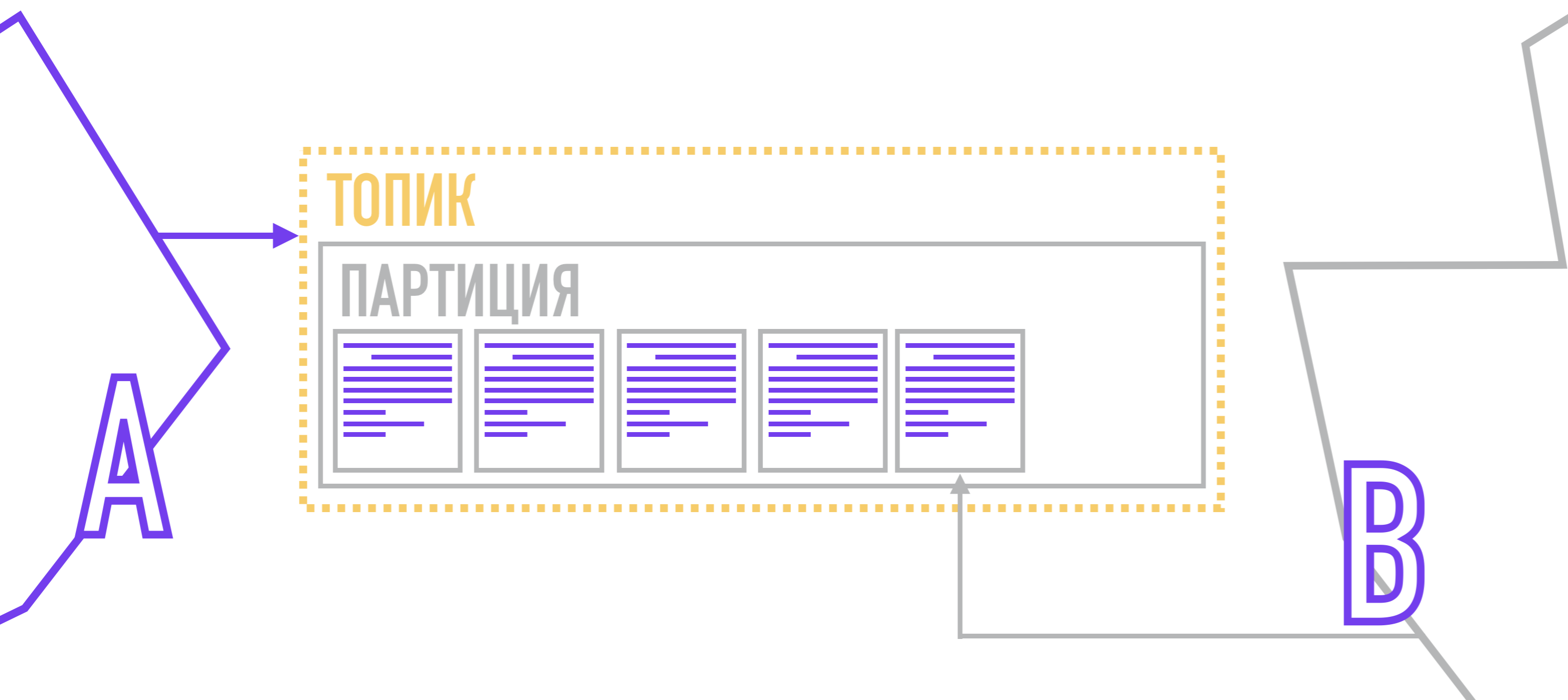
Les producteurs, formant des messages, y attachent une clé et un numéro de partition. Le numéro de partition peut être choisi au hasard (round robin) si le message n'a pas de clé.
Si vous avez besoin de plus de contrôle, vous pouvez attacher une clé au message, puis utiliser la fonction de hachage ou écrire votre propre algorithme par lequel la partition du message sera sélectionnée. Après la formation, le producteur envoie un message à Kafka, qui l'enregistre sur le disque, en notant à quelle partition il appartient.
Chaque destinataire est affecté à une partition spécifique (ou plusieurs partitions) dans le sujet d'intérêt, et lorsqu'un nouveau message apparaît, il reçoit un signal pour lire l'élément suivant dans le journal de validation, tout en notant le dernier message qu'il a lu. Ainsi, lors de la reconnexion, il saura quel message lire ensuite.
Quels sont les avantages de cette approche?
- . , , . , ( Retention Policy, ), .
- Message Replay. , . , , .
- . , ( ) – , .
- . (batch) , , . : (1 ), .
Les inconvénients de cette approche comprennent l'utilisation des messages de problème. Contrairement aux courtiers classiques, les messages interrompus (qui ne peuvent pas être traités en tenant compte de la logique existante du destinataire ou en raison de problèmes de désérialisation) ne peuvent pas être remis en file d'attente indéfiniment jusqu'à ce que le destinataire apprenne à les traiter correctement.
Dans Kafka, par défaut, la lecture des messages de la partition s'arrête lorsque le destinataire atteint le message cassé, et jusqu'à ce qu'il soit ignoré et jeté dans la file d'attente "quarantaine" (également appelée " file d'attente de lettres mortes ") pour un traitement ultérieur, continuez à lire la partition ne fonctionnera pas.
Toujours dans Kafka, il est plus difficile (en comparaison avec les courtiers AMQP) d'implémenter la priorité des messages. Cela découle directement du fait que les messages dans les partitions sont stockés et lus strictement dans l'ordre où ils ont été ajoutés. L'un des moyens de contourner cette limitation dans Kafka est de créer plusieurs rubriques pour les messages avec des priorités différentes (les rubriques ne différeront que par leurs noms), par exemple, events_low, events_medium, events_high , puis implémenter la logique de lecture prioritaire des rubriques listées du côté de l'application grand public.
Un autre inconvénient de cette approche est lié au fait qu'il est nécessaire de conserver des enregistrements du dernier message lu dans la partition par chacun des lecteurs. En raison de la simplicité de la structure des partitions, ces informations sont présentées sous la forme d'une valeur entière appelée offset (offset). Offset vous permet de déterminer le message que chacun des lecteurs lit actuellement. L'analogie la plus proche du décalage est l'index d'un élément dans un tableau, et le processus de lecture est similaire à parcourir un tableau dans une boucle en utilisant un itérateur comme index de l'élément.
Cependant, cet inconvénient est compensé par le fait que Kafka, à partir de la version 0.9, stocke les offsets pour chaque utilisateur dans une rubrique spéciale __consumer_offsets (jusqu'à la version 0.9, les offsets étaient stockés dans ZooKeeper).
De plus, vous pouvez suivre les décalages directement du côté du destinataire.

La mise à l'échelle devient également plus compliquée: laissez-moi vous rappeler que dans les courtiers AMQP, afin d'accélérer le traitement du flux de messages, il vous suffit d'ajouter plusieurs instances du service de lecture et de les abonner à une file d'attente, et vous n'avez pas besoin de modifier la configuration du courtier lui-même.
Cependant, la mise à l'échelle est un peu plus compliquée dans Kafka que chez les courtiers AMQP. Par exemple, si vous ajoutez une autre copie du lecteur et la définissez sur la même partition, vous n'obtenez aucune efficacité, car dans ce cas, les deux instances liront le même ensemble de données.
Par conséquent, la règle de base pour la mise à l'échelle de Kafka est que le nombre de lecteurs concurrents (c'est-à-dire un groupe de services qui implémentent la même logique de traitement (répliques)) d'un sujet ne doit pas dépasser le nombre de partitions de ce sujet, sinon une paire de lecteurs traitera le même ensemble de données.
Groupe de consommateurs
Pour éviter la situation de lecture d'une partition par des lecteurs concurrents, il est habituel dans Kafka de combiner plusieurs répliques d'un service dans un groupe de consommateurs , au sein duquel Zookeeper n'assignera pas plus d'un lecteur à une partition.
Étant donné que les lecteurs sont directement liés à la partition (alors que le lecteur ne sait généralement rien du nombre de partitions dans le sujet), ZooKeeper, lorsqu'un nouveau lecteur est connecté, redistribue les membres au groupe de consommateurs afin que chaque partition ait un et un seul lecteur.
Le lecteur désigne son groupe de consommateurs lors de la connexion à Kafka.
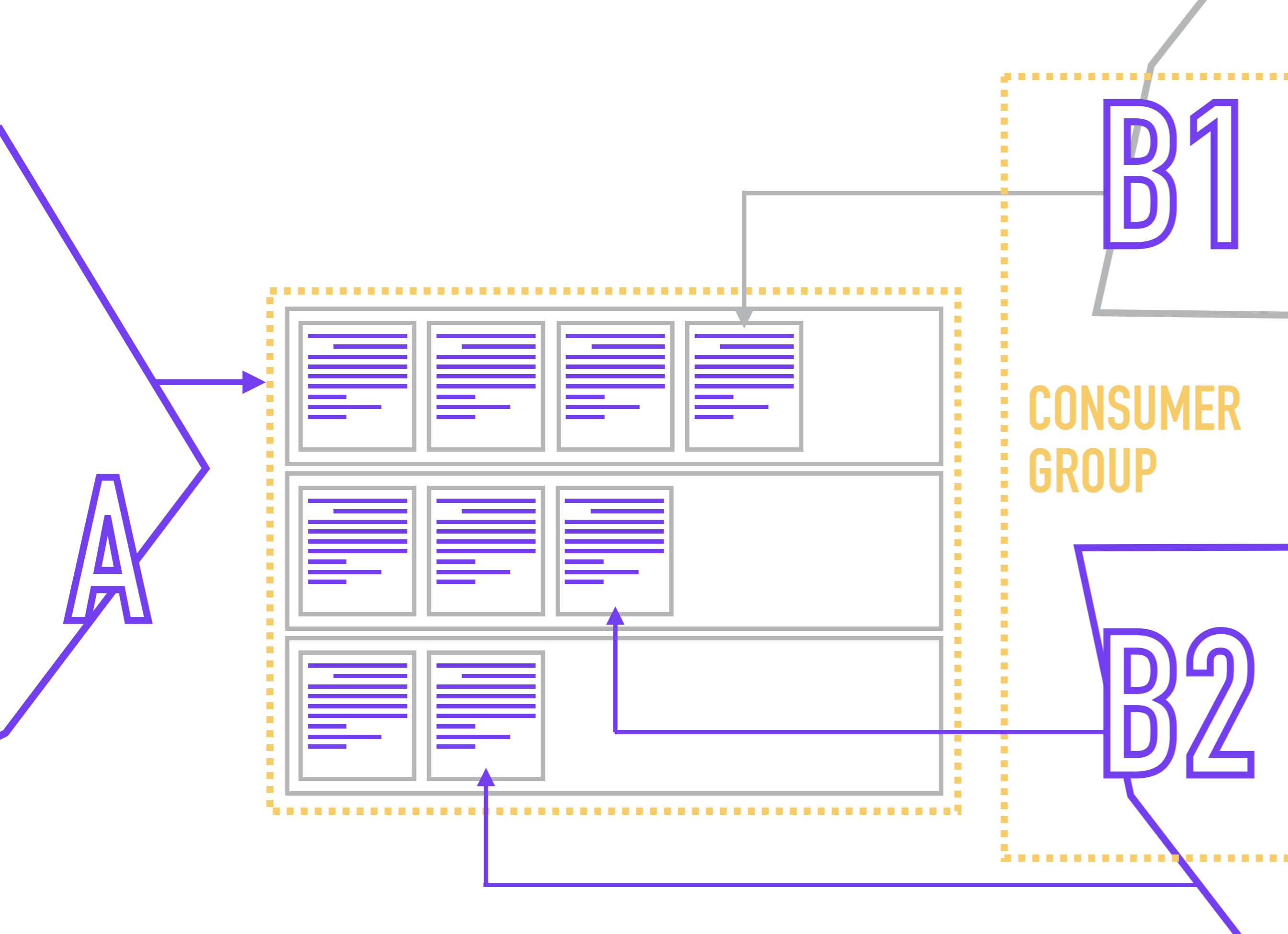
En même temps, rien ne vous empêche d'accrocher plusieurs lecteurs avec des logiques de traitement différentes sur une même partition. Par exemple, vous stockez dans une rubrique une liste d'événements par actions utilisateur et souhaitez utiliser ces événements pour générer plusieurs vues des mêmes données (par exemple, pour les analystes métier, les analystes de produit, les analystes système et le package Yarovaya), puis les envoyer aux stockages appropriés.
Mais ici, nous pouvons faire face à un autre problème, causé par le fait que Kafka utilise une structure de sujets et de partitions. Permettez-moi de vous rappeler que Kafka ne garantit pas l'ordre des messages dans une rubrique, uniquement dans une partition, ce qui peut être critique, par exemple, lors de la génération de rapports sur les actions des utilisateurs et de leur envoi vers le stockage tel quel.
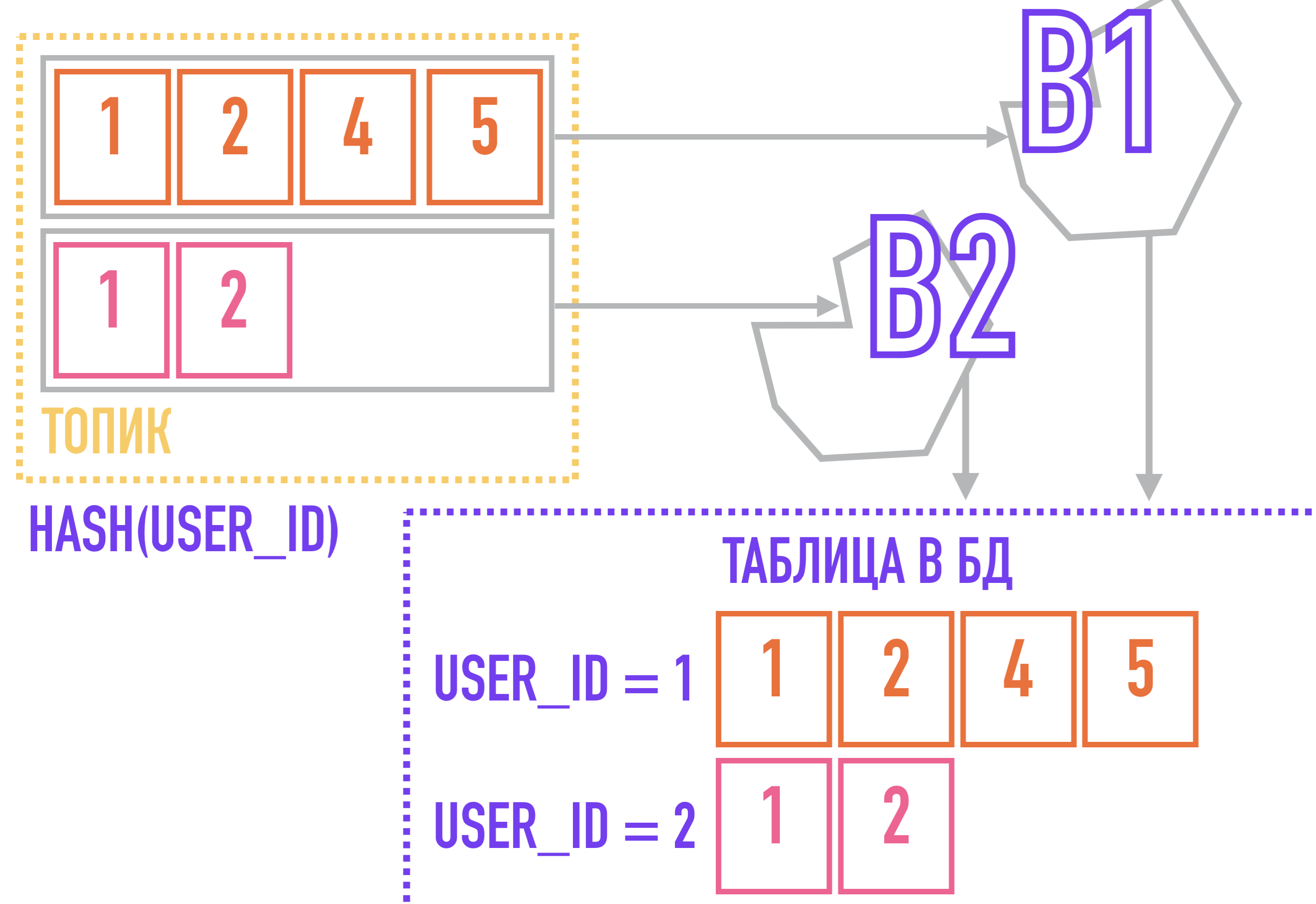
Pour résoudre ce problème, on peut partir du contraire: si tous les événements liés à une entité (par exemple, toutes les actions liées au même user_id) seront toujours ajoutés à la même partition, ils seront classés dans le sujet simplement parce que sont dans la même partition, l'ordre dans lequel est garanti par Kafka.
Pour ce faire, nous avons besoin d'une clé pour les messages: par exemple, si nous utilisons un algorithme qui calcule le hachage à partir de la clé pour sélectionner la partition à laquelle le message sera ajouté, les messages avec la même clé seront garantis de tomber dans une partition, et donc d'extraire le destinataire du message avec la même clé dans l'ordre dans lequel ils ont été ajoutés au sujet.
Dans un cas avec un flux d'événements sur les actions de l'utilisateur, la clé de partitionnement peut être user_id.
Politique de rétention
Il est maintenant temps de parler de la politique de rétention.
Il s'agit d'un paramètre responsable de la suppression des messages du disque lorsque les seuils pour la date d'ajout ( stratégie de rétention basée sur le temps ) ou l'espace occupé sur le disque ( stratégie de rétention basée sur la taille ) sont dépassés .
- Si vous configurez TBRP pendant 7 jours, tous les messages datant de plus de 7 jours seront signalés pour une suppression ultérieure. En d'autres termes, ce paramètre garantit que les messages inférieurs au seuil d'âge sont disponibles pour la lecture à tout moment. Peut être défini en heures, minutes et millisecondes.
- SBRP fonctionne de la même manière: lorsque le seuil d'espace disque est dépassé, les messages seront marqués pour suppression à partir de la fin (plus anciens). Il faut garder à l'esprit: puisque la suppression des messages n'est pas instantanée, l'espace disque occupé sera toujours légèrement supérieur à celui spécifié dans le paramètre. Défini en octets.
La stratégie de rétention peut être configurée à la fois pour l'ensemble du cluster et pour des sujets individuels: par exemple, les messages d'un sujet pour suivre les actions des utilisateurs peuvent être stockés pendant plusieurs jours, tandis que les notifications push peuvent être stockées pendant plusieurs heures. En supprimant les données en fonction de leur pertinence, nous économisons de l'espace disque, ce qui peut être important lors du choix d'un SSD comme stockage disque principal.
Politique de compactage
Une autre façon d'optimiser l'espace disque consiste à utiliser la stratégie de compactage - ce paramètre vous permet de stocker uniquement le dernier message pour chaque clé, en supprimant tous les messages précédents. Cela peut être utile lorsque nous ne sommes intéressés que par la dernière modification.
Cas d'utilisation de Kafka
- . : . , , , (Clickhouse !) .
Customer Care Vivid.Money CRM. - . , . , - ( ) , , .
, ( ) . , , , , . - . , .
- (commit log). , - / .
, , «» .
Customer Care CRM- .
Kafka
- – , ;
- – (pull) , . (, ) Consumer Group, ZooKeeper, , , , ;
- . , , , . , () ;
- , , AMQP , – . , ;
- . , , --, – .