Chez Dentsu, nous avons mis au point Podcaster, un outil d'analyse pour mesurer les audiences de podcast et planifier des publicités. Comment nous avons commencé à collecter des données et résolu le problème de la reconnaissance du public, quelles difficultés nous avons rencontrées et ce qui en est sorti, nous vous le dirons dans cet article.

Contexte
La programmation des podcasts est désormais basée sur les données des vendeurs (studios ou agences spécialisées) qui contactent les auteurs de podcast et demandent une description des auditeurs. Les podcasteurs eux-mêmes reçoivent des données soit de la plateforme sur laquelle le podcast est publié, soit d'un système de statistiques externe. Cette approche présente un certain nombre de limites:
- les podcasts peuvent être sélectionnés à partir d'une liste limitée avec laquelle le vendeur a des accords et dispose de données sur l'audience du podcast;
- il n'y a pas de possibilité de choisir des podcasts plus affinitifs (l'affinité est le rapport entre un public cible donné parmi les auditeurs et tous les auditeurs de podcast), car, en règle générale, une description du noyau d'auditeurs est disponible, et elle est généralement la même en termes d'âge pour la plupart des podcasts;
- les podcasteurs eux-mêmes ont des données sur chaque podcast, mais ni les podcasteurs ni les vendeurs ne savent comment les auditeurs se croisent entre les podcasts.
Afin de rendre la planification des podcasts plus intelligente, nous avons essayé de former un système d'analyse unifié qui serait basé sur les données de la liste des podcasts existants et de la base d'utilisateurs écoutant ces podcasts, ainsi que sur la possibilité de déterminer le sexe et l'âge de ces mêmes auditeurs.
Une approche
Nous avons rapidement réalisé que nous ne pourrions pas obtenir nous-mêmes des auditions spécifiques aux utilisateurs. Mais il y a des goûts / abonnés au podcast: un mécanisme similaire fonctionne, par exemple, sur Instagram avec des blogueurs, lorsqu'une personne s'abonne à un blogueur pour voir ses actualités. Nous avons supposé que la même histoire se produisait avec les podcasts - les auditeurs s'abonnent à leurs podcasts préférés afin qu'ils aient un accès rapide et puissent suivre de nouveaux épisodes.
Nous avons décidé de tester cette hypothèse en utilisant une plate-forme populaire à travers laquelle le public écoute des podcasts. Selon Tiburon, Yandex.Music est le leader de l'écoute de podcasts.
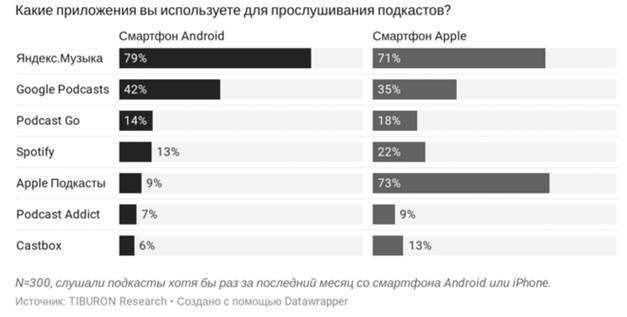
Heureusement, Ya Music dispose d'une page utilisateur qui fournit des informations sur les abonnements aux podcasts.
Un exemple de profil avec une photo et des abonnements à des podcasts
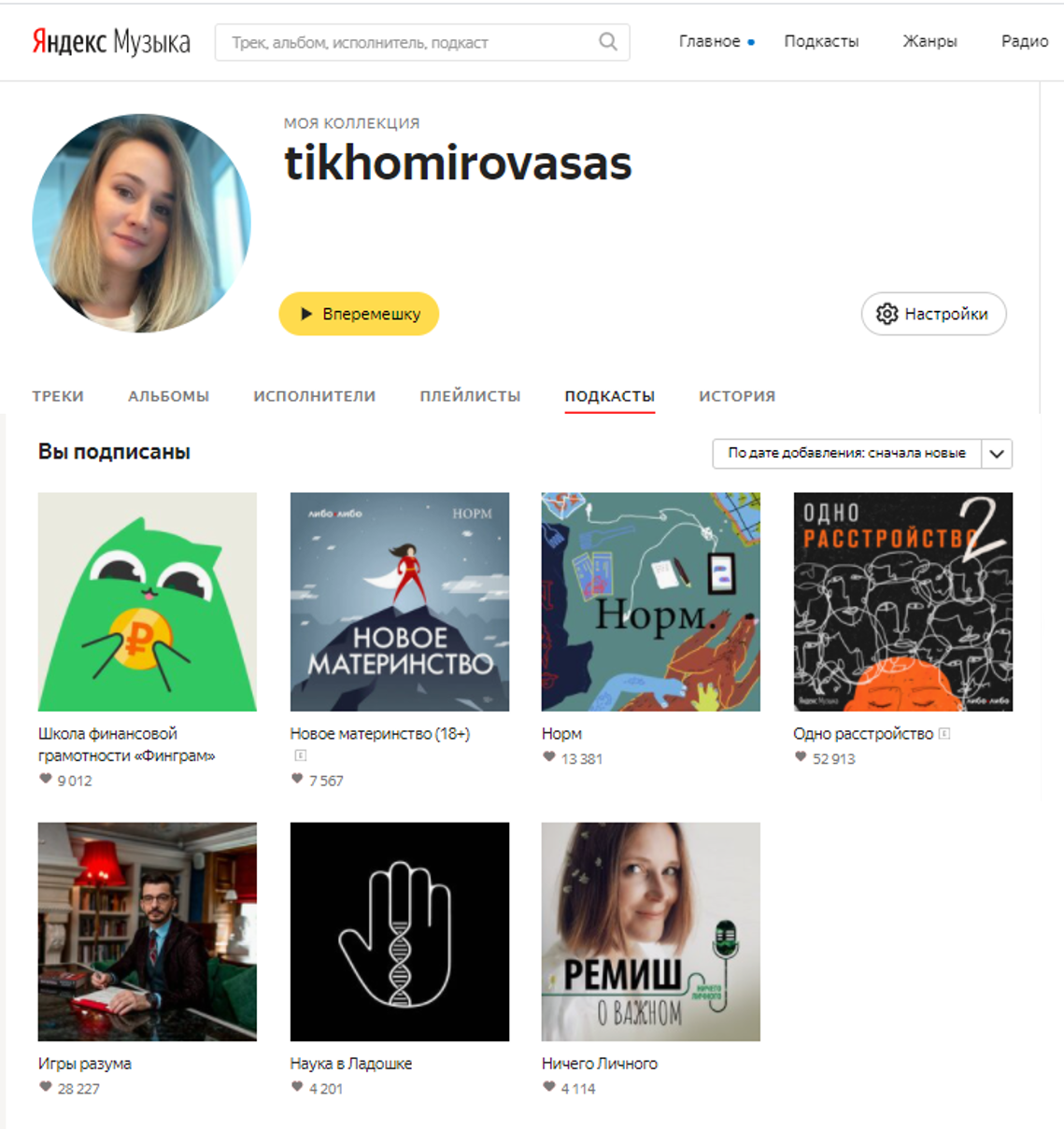
En plus de l'abonnement lui-même, il existe un pseudo et un avatar d'utilisateur dans le domaine public. C'est déjà quelque chose, car en fait, nous voyons le noyau des auditeurs de podcast, c'est-à-dire ceux qui les écoutent régulièrement. Nous avons également ici le lien très utilisateur-podcast que nous voulions trouver.
Mécanique
Nous avons commencé à collecter des données, à savoir les utilisateurs et les podcasts auxquels les auditeurs se sont abonnés. Dans un premier temps, nous avons trouvé des utilisateurs de Y.Muzyka avec des podcasts sur les données des employés de Dentsu qui ont fourni leurs boîtes aux lettres sur Yandex. Il n'a pas été difficile de faire évoluer le projet, car nous travaillons avec des données publiques depuis plusieurs années.
La bonne nouvelle était que la base d'abonnés au podcast se rassemblait très rapidement - en seulement un mois et demi, nous avons obtenu plus de 10 000 utilisateurs qui se sont abonnés à au moins un podcast.
Mais il y avait aussi de mauvaises nouvelles - il n'est pas toujours possible de déterminer le sexe et l'âge à l'œil nu par photo et surnom, ou plutôt, c'est impossible du tout. Pour nous, afin de pouvoir choisir des podcasts pertinents pour différents publics, nous ne pouvons pas nous passer du sexe et de l'âge. Notre réseau de neurones s'est
chargé de cette tâche de déterminer le sexe et l'âge à partir d'une photographie , dont la précision est de 96%. L'algorithme est simple: nous prenons une photo de l'utilisateur J. Music, cherchons un visage et l'utilisons pour déterminer le sexe et l'âge. Le visage est trouvé par la bibliothèque de reconnaissance faciale
en utilisant dlib. Et au cœur de notre réseau neuronal se trouve le modèle VGGFace pré-formé basé sur l'architecture ResNet-50, que nous avons formé sur les photos des utilisateurs VK, disponibles via l'API publique. L'ensemble de données se compose d'un million de photographies, qui ont également été enrichies par des albumentations. Il est à noter que nous ne considérons pas les photographies d'utilisateurs de moins de 12 ans et de plus de 65 ans à des fins de formation.
résultats
Après la formation, nous avons réalisé que dans environ 45% des profils d'utilisateurs avec des podcasts, nous pouvons déterminer le sexe et l'âge, car il existe de nombreux profils sans photo ou image, un symbole ou juste une photo de mauvaise qualité. Mais même ce résultat nous convient.
Compte tenu de la dynamique de recherche de profils qui s'abonnent à des podcasts, nous prévoyons que dans quelques mois, la base d'auditeurs sera de 50 000 profils, et 22 500 d'entre eux auront le sexe et l'âge.
Exemple de profil par lequel nous ne pouvons pas déterminer le sexe et l'âge
Les développements actuels nous permettent de réaliser des échantillons de podcasts affinitifs pour différents publics.
Une sélection de podcasts pour 20-50 sur des sujets pertinents pour la marque

Affinité = public cible parmi les auditeurs de podcast / tous les auditeurs de podcast) / (tous les auditeurs de podcast / toutes les personnes avec des podcasts)
Nous pouvons également analyser un podcast spécifique si l'annonceur s'y intéresse.
En voyant combien de personnes sont abonnées à des podcasts, nous pouvons faire des recommandations sur le package de podcast qui permettra de créer la plus grande portée.
Courbe de couverture pour 50 podcasts sélectionnés
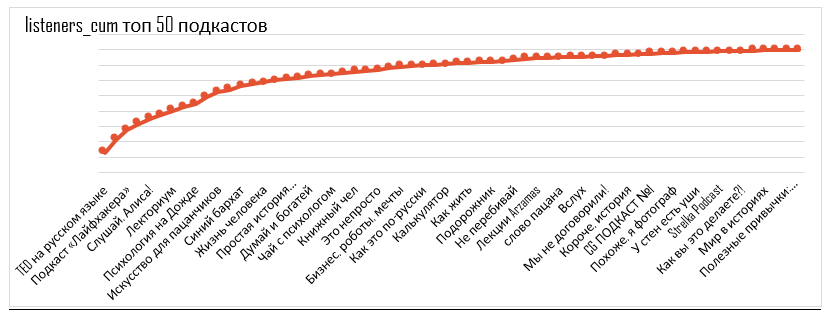
Chaque point +1 podcast par mix. Le premier point est le podcast avec le plus grand public unique, le dernier point est le podcast avec le plus petit public unique.
Mécanique des courbes et modèle mathématique
Tout d'abord, nous prenons le podcast qui a un public plus large, dans notre cas c'est le podcast 3. Ci-dessous, un tableau dans lequel la logique de la force brute est révélée, c'est-à-dire le principe de la répartition des conciliateurs entre les podcasts.

Ensuite, nous barrons les auditeurs que nous touchons avec le podcast 3, et sélectionnons à nouveau le podcast avec l'audience la plus unique (podcast 4). Ceci est un podcast qui nous donne 2 nouveaux auditeurs uniques, nous vous recommandons donc de le placer ensuite.

Nous répétons l'exercice, et il s'avère que nous ne couvrirons pas plus d'auditeurs uniques, c'est-à-dire que le placement dans 2 podcasts sur 6 est suffisant pour couvrir tout le public unique possible.

conclusions
Nous n'avons pas répondu à toutes les questions, nous continuons donc à rechercher des données. Par exemple, Ya.Muzyka a récemment commencé à publier des informations sur le nombre de spectateurs abonnés pour chacun des podcasts. Nous comprenons maintenant le volume des auditeurs collectés à partir du total.
Nous travaillons sur les mécanismes de combinaison des données d'abonnement avec les données des sites et des podcasteurs pour affiner le modèle d'estimation du nombre et de la composition des auditeurs. Mais déjà maintenant, notre approche contribue à changer le schéma de planification des intégrations publicitaires dans les podcasts et ne procède pas de données agrégées des vendeurs ou de l'intuition des annonceurs sur l'audience du podcast, mais de l'audience de la marque. Et aussi pour composer des packages de podcast qui sont spécifiquement pertinents pour ce public de marque et pour en accroître la portée.
Auteur Sasha_Kopylova