Chez Miro, nous travaillons sur le processus de partitionnement des bases de données Postgres et utilisons différentes approches en fonction des besoins de l'entreprise. Récemment, nous avons été confrontés à la tâche de sharding de nouvelles bases de données, au cours de laquelle nous avons choisi une nouvelle approche du sharding pour nous, basée sur un hachage cohérent .
Lors de la mise en œuvre de cette approche, l'une des questions centrales était de savoir quelle implémentation de la fonction de hachage non cryptographique nous devrions choisir et utiliser. Dans cet article, je décrirai les critères et l'algorithme de comparaison que nous avons développé et utilisé en pratique pour trouver la meilleure implémentation.
À propos de l'approche architecturale
Il existe de nombreux produits ( mongo , redis , etc.) qui utilisent un hachage cohérent pour le sharding, et notre implémentation leur sera très similaire.
Soit, en entrée, un ensemble d'entités avec des clés de partitionnement sélectionnées, de type chaîne. Pour ces clés, en utilisant la fonction de hachage, nous obtenons un code de hachage d'une certaine longueur, pour lequel nous définissons le slot requis via l'opération modulo. Le nombre de slots et la correspondance des entités avec les slots est fixe. Il est également nécessaire de conserver la correspondance entre les plages d'emplacements et de fragments, ce qui n'est pas une tâche difficile, et un fichier de configuration est tout à fait adapté à l'emplacement de stockage.
Les avantages de cette approche sont:
répartition uniforme des entités entre les fragments;
déterminer la correspondance des entités et des fragments sans stockage supplémentaire avec un minimum de coûts de ressources;
la possibilité d'ajouter de nouvelles partitions au cluster.
Les inconvénients:
l'inefficacité de certaines opérations de recherche, dans lesquelles il est nécessaire de faire des requêtes pour tous les fragments;
processus de redistribution assez compliqué.
Exigences
java- -.
- , 256 , - - , 4 . - 2 4 .
-:
, , ;
. , , ;
( );
. , .
: - ; - , .
.
, .
java- - -:
, 216,553 ;
, UTF-8.
(- ) - "2", "4", "8", "16", "32", "64", "128", "256".
:
JMH. :
, 256 . - , .
- warmup- - 50;
- measurement- - 100;
-
throughput
-Xms1G, -Xmx8G
GCProfiler
, α=0,05, . .
:
 ,
,


 — , -
— , - 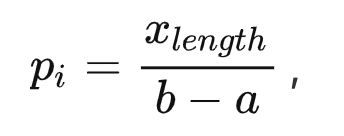
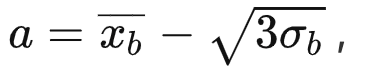
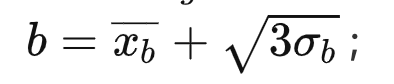 ,
,  ,
, , α k ;
, α k ; , , — .
, , — .:
, 256. 16384, 8192, 4096, 2048, 1024, , .
- , -. , .
( ) .
:
, , loseLose, crc16 sdbm.
16 256 :
murmur2 , murmur; crc16 sdbm .
, crc16, murmur2, murmur3 .
, .
, loseLose, Djb2, Sdbm, , , :
Fnv1 Fnv1a , :
.
:
, crc16, murmur2, murmur3 , .
, : .
. murmur2/murmur3 8 .
. , : crc16, murmur2/murmur3. crc16, murmur2/murmur3.
, , murmur2/murmur3.