Compilateurs AOT et JIT
Les processeurs ne peuvent exécuter qu'un ensemble limité d'instructions - code machine. Pour qu'un programme soit exécuté par un processeur, il doit être représenté sous forme de code machine.
Il existe des langages de programmation compilés tels que C et C ++. Les programmes écrits dans ces langues sont distribués sous forme de code machine. Une fois le programme écrit, un processus spécial - le compilateur Ahead-of-Time (AOT), généralement appelé simplement compilateur, traduit le code source en code machine. Le code machine est conçu pour s'exécuter sur un modèle de processeur spécifique. Les processeurs dotés d'une architecture commune peuvent exécuter le même code. Les modèles de processeur plus récents prennent généralement en charge les instructions des modèles précédents, mais pas l'inverse. Par exemple, le code machine utilisant les instructions AVX pour les processeurs Intel Sandy Bridge ne peut pas s'exécuter sur des processeurs Intel plus anciens. Il existe différentes manières de résoudre ce problème, par exemple, en transférant des parties critiques du programme vers une bibliothèque contenant des versions pour les modèles de processeur principaux.Mais souvent, les programmes sont simplement compilés pour des modèles de processeurs relativement anciens et ne tirent pas parti des nouveaux jeux d'instructions.
Contrairement aux langages de programmation compilés, il existe des langages interprétés tels que Perl et PHP. Avec cette approche, le même code source peut être exécuté sur n'importe quelle plateforme pour laquelle un interpréteur existe. L'inconvénient de cette approche est que le code interprété est plus lent que le code machine qui fait de même.
Le langage Java propose une approche différente, un croisement entre les langages compilés et interprétés. Les applications Java sont compilées dans un code intermédiaire de bas niveau - bytecode.
Le nom bytecode a été choisi car exactement un octet est utilisé pour encoder chaque opération. Il existe environ 200 opérations dans Java 10.
Le bytecode est ensuite exécuté par la JVM ainsi qu'un programme de langage interprété. Mais comme le bytecode a un format bien défini, la JVM peut le compiler en code machine au moment de l'exécution. Naturellement, les anciennes versions de la JVM ne pourront pas générer de code machine en utilisant les nouveaux jeux d'instructions du processeur après elles. D'un autre côté, pour accélérer un programme Java, il n'a même pas besoin d'être recompilé. Il suffit de l'exécuter sur une JVM plus récente.
Compilateur HotSpot JIT
Différentes implémentations JVM JIT peuvent implémenter le compilateur de différentes manières. Dans cet article, nous examinons Oracle HotSpot JVM et son implémentation de compilateur JIT. Le nom HotSpot vient de l'approche utilisée par la JVM pour compiler le bytecode. Habituellement, dans une application, seules de petites parties du code sont exécutées assez souvent, et les performances de l'application dépendent principalement de la vitesse d'exécution de ces parties particulières. Ces parties du code sont appelées points chauds et sont ce que compile le compilateur JIT. Plusieurs arrêts sous-tendent cette approche. Si le code n'est exécuté qu'une seule fois, compiler ce code est une perte de temps. Les optimisations sont une autre raison. Plus la JVM exécute un code, plus elle accumule de statistiques, à l'aide desquelles vous pouvez générer un code plus optimisé.De plus, le compilateur partage les ressources de la machine virtuelle avec l'application elle-même, de sorte que les ressources consacrées au profilage et à l'optimisation peuvent être utilisées pour exécuter l'application elle-même, ce qui oblige à respecter un certain équilibre. L'unité de travail du compilateur HotSpot est une méthode et une boucle.
L'unité de code compilé est appelée nmethod (abréviation de méthode native).
Compilation à plusieurs niveaux
En fait, la JVM HotSpot n'a pas un, mais deux compilateurs: C1 et C2. Leurs autres noms sont client et serveur. Historiquement, C1 était utilisé dans les applications GUI et C2 dans les applications serveur. Les compilateurs diffèrent par la rapidité avec laquelle ils commencent à compiler le code. C1 commence à compiler le code plus rapidement, tandis que C2 peut générer du code plus optimisé.
Dans les versions antérieures de la JVM, vous deviez choisir un compilateur en utilisant les indicateurs -client pour le client et -server ou -d64pour la salle des serveurs. JDK 6 a introduit le mode de compilation à plusieurs niveaux. En gros, son essence réside dans une transition séquentielle du code interprété au code généré par le compilateur C1, puis C2. Dans JDK 8, les indicateurs -client, -server et -d64 sont ignorés, et dans JDK 11, l'indicateur -d64 a été supprimé et génère une erreur. Vous pouvez désactiver le mode de compilation à plusieurs niveaux avec l' indicateur -XX: -TieredCompilation .
Il existe 5 niveaux de compilation:
- 0 - code interprété
- 1 - C1 entièrement optimisé (pas de profilage)
- 2 - C1 considérant le nombre d'appels de méthode et d'itérations de boucle
- 3 - C1 avec profilage
- 4 - C2
Les séquences typiques de transitions entre les niveaux sont indiquées dans le tableau.
| Séquence
|
La description
|
|---|---|
| 0-3-4 | Interprète, niveau 3, niveau 4. Le plus courant. |
| 0-2-3-4 | , 4 (C2) . 2. , 3 , , 4. |
| 0-2-4 | , 3 . 4 3. 2 4. |
| 0-3-1 | . 3, , 4 . 1. |
| 0-4 | . |
Code cache
Le code machine compilé par le compilateur JIT est stocké dans une zone de mémoire appelée cache de code. Il stocke également le code machine de la machine virtuelle elle-même, tel que le code d'interprétation. La taille de cette zone de mémoire est limitée et lorsqu'elle est pleine, la compilation s'arrête. Dans ce cas, certaines des méthodes "chaudes" continueront à être exécutées par l'interpréteur. En cas de débordement, la JVM affiche le message suivant:
Java HotSpot(TM) 64-Bit Server VM warning: CodeCache is full. Compiler has been disabled.
Une autre façon de découvrir un débordement de cette zone de mémoire est d'activer la journalisation du travail du compilateur (comment faire cela est expliqué ci-dessous).
Le cache de code est configurable de la même manière que les autres zones de mémoire de la JVM. La taille initiale est spécifiée par le paramètre -XX: InitialCodeCacheSize . La taille maximale est spécifiée par le paramètre -XX: ReservedCodeCacheSize . Par défaut, la taille initiale est de 2496 Ko. La taille maximale est de 48 Mo lorsque la compilation hiérarchisée est désactivée et de 240 Mo lorsqu'elle est activée.
Depuis Java 9, le cache de code est divisé en 3 segments (la taille totale est toujours limitée par les limites décrites ci-dessus):
- JVM internal (non-method code). , JVM, , . . 5.5 MB. -XX:NonNMethodCodeHeapSize.
- Profiled code. . non-method code . 21.2 MB 117.2 MB . -XX:ProfiledCodeHeapSize.
- Non-profiled code. . non-method code . 21.2 MB 117.2 MB . -XX: NonProfiledCodeHeapSize.
Vous pouvez activer la journalisation du processus de compilation avec l' indicateur -XX: + PrintCompilation (il est désactivé par défaut). Lorsque cet indicateur est défini, la JVM écrira un message sur la sortie standard (STDOUT) chaque fois qu'une méthode ou une boucle est compilée. La plupart des messages ont le format suivant: timestamp compilation_id attributs tiered_level nom_méthode taille deopt.
Le champ d'horodatage correspond à l'heure depuis le démarrage de la JVM.
Le champ compilation_id est l'ID interne du problème. Il se développe généralement de manière séquentielle avec chaque message, mais parfois l'ordre peut être dans le désordre. Cela peut se produire lorsque plusieurs threads de compilation s'exécutent en parallèle.
Le champ des attributs est un ensemble de cinq caractères qui contiennent des informations supplémentaires sur le code compilé. Si l'un des attributs n'est pas applicable, un espace s'affiche à la place. Les attributs suivants existent:
- % - OSR (remplacement sur pile);
- s - la méthode est synchronisée;
- ! - la méthode contient un gestionnaire d'exceptions;
- b - la compilation a eu lieu en mode blocage;
- n - la méthode compilée est un wrapper pour la méthode native.
OSR signifie remplacement sur pile. La compilation est un processus asynchrone. Lorsque la JVM décide qu'une méthode doit être compilée, elle est mise en file d'attente. Pendant la compilation de la méthode, la machine virtuelle Java continue de l'exécuter par l'interpréteur. La prochaine fois que la méthode sera appelée à nouveau, sa version compilée sera exécutée. Dans le cas d'un cycle long, attendre la fin de la méthode n'est pas pratique - il peut ne pas se terminer du tout. La JVM compile le corps de la boucle et doit commencer à exécuter la version compilée de celle-ci. La JVM stocke l'état des threads sur une pile. Pour chaque méthode appelée, un nouvel objet Stack Frame est créé sur la pile, qui stocke les paramètres de méthode, les variables locales, la valeur de retour et d'autres valeurs. Pendant l'OSR, un nouveau cadre de pile est créé pour remplacer le précédent.
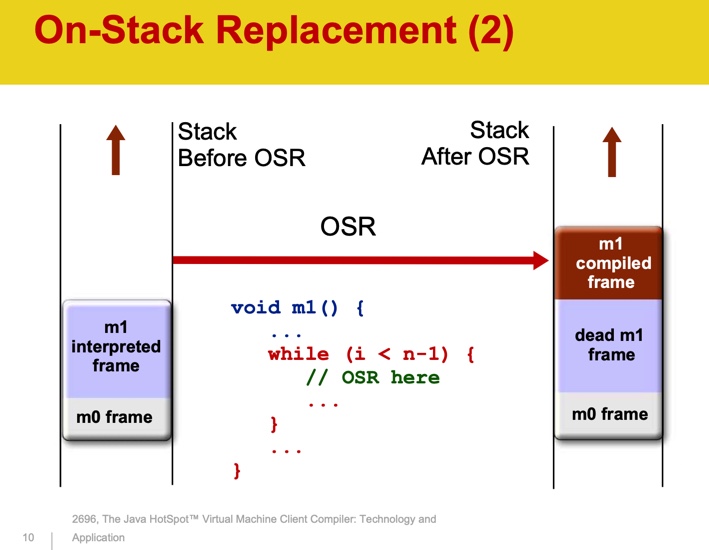
Source: Le compilateur client de machine virtuelle Java HotSpotTM: technologie et application
Les attributs «s» et «!» Je pense qu'ils n'ont pas besoin d'explication.
L'attribut "b" signifie que la compilation n'a pas eu lieu en arrière-plan et ne doit pas être trouvée dans les versions modernes de la JVM.
L'attribut "n" signifie que la méthode compilée est un wrapper autour d'une méthode native.
Le champ tiered_level contient le numéro de niveau auquel le code a été compilé ou peut être vide si la compilation hiérarchisée est désactivée.
Le champ method_name contient le nom de la méthode compilée ou le nom de la méthode contenant la boucle compilée.
Le champ size contient la taille du bytecode compilé, et non la taille du code machine résultant. La taille est en octets.
Le champ deopt n'apparaît pas dans tous les messages, il contient le nom de la désoptimisation effectuée et peut contenir des messages tels que "made not entrant" et "made zombie".
Parfois, les entrées suivantes peuvent apparaître dans le journal: timestamp compile_id COMPILE SKIPPED: raison. Ils signifient que quelque chose s'est mal passé lors de la compilation de la méthode. Il y a des moments où cela est attendu:
- Cache de code rempli - il est nécessaire d'augmenter la taille de la zone de mémoire cache de code.
- Chargement de classe simultané - la classe a été modifiée au moment de la compilation.
Dans tous les cas, à l'exception d'un débordement de cache de code, la JVM tentera de recompiler. Si ce n'est pas le cas, vous pouvez essayer de simplifier le code.
Si le processus a été démarré sans l'indicateur -XX: + PrintCompilation, vous pouvez consulter le processus de compilation à l'aide de l'utilitaire jstat . Jstat a deux options pour afficher les informations de compilation.
Le paramètre -compiler affiche un résumé de l'opération du compilateur (5003 est l'ID de processus):
% jstat -compiler 5003 Compiled Failed Invalid Time FailedType FailedMethod 206 0 0 1.97 0
Cette commande affiche également le nombre de méthodes dont la compilation a échoué et le nom de la dernière méthode de ce type.
Le paramètre -printcompilation imprime des informations sur la dernière méthode compilée. Combiné avec le deuxième paramètre, la période de répétition de l'opération, vous pouvez observer le processus de compilation au fil du temps. L'exemple suivant exécute la commande -printcompilation toutes les secondes (1000 ms):
% jstat -printcompilation 5003 1000 Compiled Size Type Method 207 64 1 java/lang/CharacterDataLatin1 toUpperCase 208 5 1 java/math/BigDecimal$StringBuilderHelper getCharArray
Plans pour la deuxième partie
Dans la partie suivante, nous examinerons les seuils de compteur auxquels la JVM commence la compilation et comment vous pouvez les modifier. Nous verrons également comment la JVM choisit le nombre de threads du compilateur, comment vous pouvez le changer et quand vous devez le faire. Enfin, jetons un coup d'œil rapide à certaines des optimisations effectuées par le compilateur JIT.
Références et liens
- Performances Java: conseils détaillés pour le réglage et la programmation de Java 8, 11 et au-delà, Scott Oaks. ISBN: 978-1-492-05611-9.
- Optimisation de Java: techniques pratiques pour améliorer les performances des applications JVM, Benjamin J. Evans, James Gough et Chris Newland. ISBN: 978-1-492-02579-5.
- JEP 197: Cache de code segmenté
- Le compilateur client de machine virtuelle Java HotSpotTM: technologie et application