Nous nous intéressons depuis longtemps au sujet de l'utilisation d'Apache Kafka comme entrepôt de données, considéré d'un point de vue théorique, par exemple ici . Il est d'autant plus intéressant de porter à votre attention une traduction de matériel du blog Twitter (original - décembre 2020), qui décrit une utilisation non conventionnelle de Kafka comme base de données pour le traitement et la reproduction d'événements. Nous espérons que cet article sera intéressant et vous apportera de nouvelles idées et solutions lorsque vous travaillerez avec Kafka .
introduction
Lorsque les développeurs utilisent des données Twitter accessibles au public via l'API Twitter, ils comptent sur la fiabilité, la vitesse et la stabilité. Par conséquent, il y a quelque temps, Twitter a lancé l' API Account Activity Replay pour l' API Account Activity afin de permettre aux développeurs d'assurer plus facilement la stabilité de leurs systèmes. L'API Account Activity Replay est un outil de récupération de données qui permet aux développeurs de récupérer des événements datant de cinq jours maximum. Cette API récupère les événements qui n'ont pas été diffusés pour diverses raisons, notamment les pannes de serveur survenues lors d'une tentative de diffusion en temps réel.
Les ingénieurs de Twitter s'efforçaient non seulement de créer des API qui seraient bien accueillies par les développeurs, mais aussi de:
- Augmenter la productivité des ingénieurs;
- Rendre le système facile à entretenir. En particulier, pour minimiser le besoin de changement de contexte pour les développeurs, les ingénieurs SRE et tous les autres utilisateurs du système.
Pour cette raison, lors de la création d'un système de relecture reposant sur l'API, il a été décidé de prendre comme base le système existant pour travailler en temps réel, sur lequel repose l'API Account Activity. De cette manière, il était possible de réutiliser les développements existants et de minimiser le changement de contexte et la formation, ce qui serait beaucoup plus important si un système complètement nouveau était créé pour le travail décrit.
La solution temps réel est basée sur une architecture de publication-abonnement. À cette fin, en tenant compte des tâches et en créant le niveau de stockage des informations à partir duquel elles seront lues, l'idée est née de repenser la technologie de streaming bien connue - Apache Kafka.
Le contexte
Les événements survenant en temps réel sont produits dans deux centres de données. Lorsque ces événements sont déclenchés, ils sont écrits dans des rubriques de publication-abonnement qui sont répliquées entre deux centres de données à des fins de redondance.
Tous les événements ne doivent pas nécessairement être livrés, donc tous les événements sont filtrés par une application interne qui consomme les événements des rubriques pertinentes, vérifie chacun par rapport à un ensemble de règles dans le magasin de clés et de valeurs, et décide si l'événement doit être livré à un développeur spécifique via l'API publique. Les événements sont livrés via un webhook et chaque URL de webhook appartient à un développeur identifié par un identifiant unique.
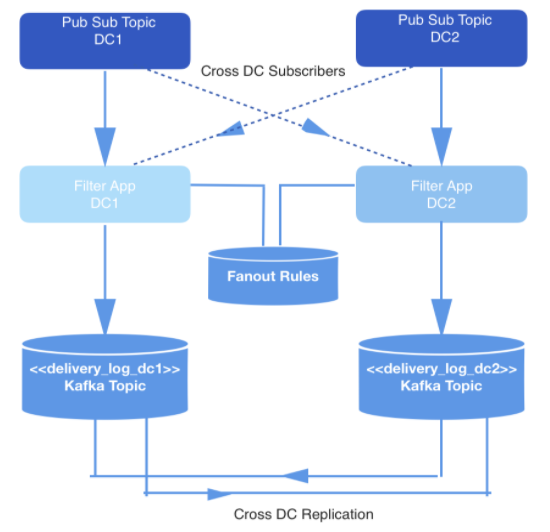
Figure: 1: Pipeline de génération de données
Stockage et segmentation
En règle générale, lors de la construction d'un système de lecture nécessitant un tel entrepôt de données, une architecture basée sur Hadoop et HDFS est choisie. Dans ce cas, au contraire, Apache Kafka a été choisi, pour deux raisons:
- Le système de travail en temps réel était basé sur un principe de publication-abonnement, organique à l'appareil Kafka
- La quantité d'événements à stocker dans le système de lecture n'est pas en pétaoctets. Nous stockons les données pendant quelques jours au maximum. En outre, gérer les tâches MapReduce pour Hadoop est plus coûteux et plus lent que la consommation de données dans Kafka, et la première option ne répond pas aux attentes des développeurs.
Dans ce cas, la charge principale repose sur le pipeline de lecture de données en temps réel pour garantir que les événements qui doivent être fournis à chaque développeur sont stockés dans Kafka. Appelons le sujet Kafka delivery_log; il y aura un tel sujet pour chaque centre de données. Ces rubriques sont répliquées de manière croisée pour la redondance, ce qui permet à une demande de réplication d'être émise à partir d'un seul centre de données. Les événements stockés de cette manière sont dédupliqués avant la livraison.
Dans cette rubrique Kafka, nous créons de nombreuses partitions en utilisant le partitionnement sémantique par défaut. Par conséquent, les partitions correspondent au hachage webhookId du développeur, et cet identifiant sert de clé pour chaque entrée. Il était censé utiliser le partitionnement statique, mais il a finalement été abandonné en raison du risque accru qu'une partition contienne plus de données que d'autres, si certains développeurs génèrent plus d'événements au cours de leurs activités que d'autres. Au lieu de cela, un nombre fixe de partitions a été choisi pour distribuer les données et la stratégie de partitionnement a été laissée à la valeur par défaut. Cela réduit le risque de partitions déséquilibrées et n'a pas besoin de lire toutes les partitions dans la rubrique Kafka.
En revanche, en fonction du webhookId pour lequel la demande est faite, le service de relecture détermine la partition spécifique à partir de laquelle lire et déclenche un nouveau consommateur Kafka pour cette partition. Le nombre de partitions dans la rubrique ne change pas, car le hachage des clés et la distribution des événements en dépendent.
Pour minimiser l'espace de stockage, les informations sont compressées à l'aide de l'algorithme Snappy , car il est connu que la plupart des informations de la tâche décrite sont traitées côté consommateur. De plus, snappy est plus rapide à décompresser que les autres algorithmes de compression pris en charge par Kafka: gzip et lz4....
Demandes et traitement
Dans un système conçu de cette manière, l'API envoie des demandes de relecture. Dans le cadre de la charge utile de chaque demande validée, un webhookId et une plage de données pour lesquelles les événements doivent être lus sont inclus. Ces requêtes sont stockées dans MySQL pendant une longue période et sont mises en file d'attente jusqu'à ce qu'elles soient récupérées par le service de relecture. La plage de données spécifiée dans la demande est utilisée pour déterminer le décalage auquel commencer la lecture à partir du disque. La fonction
offsetForTimes
objet est
Consumer
utilisée pour obtenir les décalages.
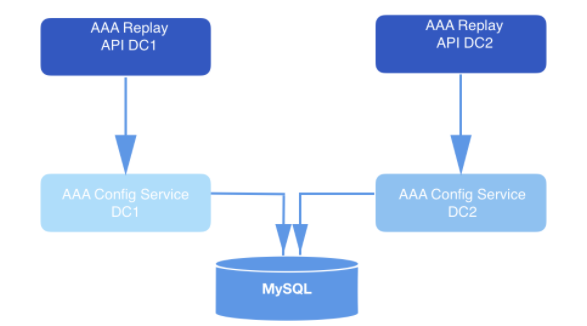
Figure: 2: Système de lecture. Il reçoit la demande et l'envoie au service de configuration (couche d'accès aux données) pour un stockage supplémentaire à long terme dans la base de données.
Les instances de service de relecture gèrent chaque demande de relecture. Les instances sont coordonnées les unes avec les autres à l'aide de MySQL pour traiter le prochain enregistrement de relecture stocké dans la base de données. Chaque processus de travail de relecture interroge MySQL périodiquement pour voir s'il y a un travail à traiter. La demande passe d'un état à l'autre. Une demande qui n'a pas été prélevée pour traitement est à l'état OPEN. La demande qui vient d'être retirée de la file d'attente est à l'état STARTED. La demande en cours de traitement est à l'état EN COURS. Une demande qui a subi toutes les transitions est à l'état COMPLETED. Le flux de travail de relecture ne récupère que les demandes qui n'ont pas encore commencé le traitement (c'est-à-dire celles à l'état OPEN).
Périodiquement, une fois que le processus de travail a supprimé la demande de la file d'attente pour traitement, elle est exploitée dans la table MySQL, laissant des horodatages et démontrant ainsi que le travail de relecture est toujours en cours de traitement. Dans les cas où une instance de flux de travail de reproduction meurt avant la fin du traitement d'une demande, ces travaux sont redémarrés. Par conséquent, les processus de reproduction retirent non seulement les demandes dans l'état OUVERT, mais récupèrent également les demandes qui ont été transférées à l'état DÉMARRÉ ou EN COURS, mais n'ont reçu aucun retour dans la base de données après un nombre spécifié de minutes.
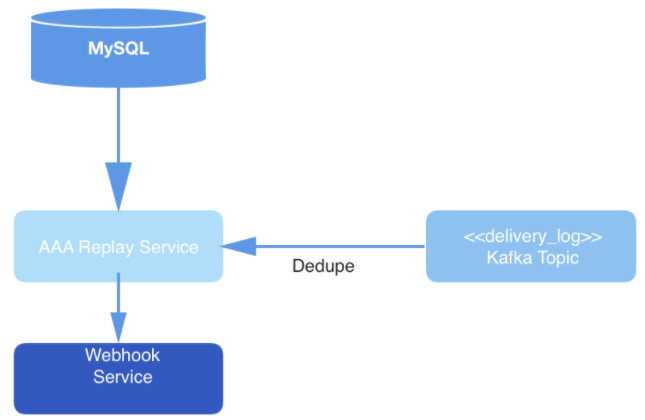
Figure: 3: Couche de livraison de données: le service de relecture interroge MySQL pour un nouveau travail de traitement de requête, consomme la requête du sujet Kafka et délivre des événements via le service Webhook.
Finalement, les événements de la rubrique sont dédupliqués au cours du processus de lecture, puis publiés dans l'URL du webhook d'un utilisateur spécifique. La déduplication est effectuée en conservant un cache des événements de lecture, qui sont ensuite hachés. Si un événement avec un hachage identique à celui qui est déjà dans le hachage tombe, il ne sera pas livré.
En général, cette utilisation de Kafka n'est pas traditionnelle. Mais dans le cadre du système décrit, Kafka fonctionne avec succès comme magasin de données et participe au travail de l'API, ce qui contribue à la fois à la convivialité et à la facilité d'accès aux données lors de la récupération d'événements. Les atouts du système pour un fonctionnement en temps réel se sont avérés utiles dans le cadre d'une telle solution. De plus, le taux de récupération des données dans un tel système répond pleinement aux attentes des développeurs.