Pour certains domaines, tels que la PNL, le cheval de bataille était Transformer, qui nécessite d'énormes quantités de mémoire GPU. Les modèles réalistes ne rentrent tout simplement pas dans la mémoire. La dernière méthode appelée Sharded [lit. «segmenté»] a été présenté dans l' article Zero de Microsoft, dans lequel ils ont développé une méthode qui rapproche l'humanité de 1 billion de paramètres.
Surtout pour le début d'un nouveau cours sur le Machine Learning, partagez avec vous un article sur Sharded qui vous montre comment l'utiliser avec PyTorch aujourd'hui pour entraîner des modèles avec deux fois plus de mémoire et en quelques minutes seulement. Cette fonctionnalité de PyTorch est désormais disponible grâce à la collaboration entre les équipes FairScale Facebook AI Research et PyTorch Lightning .

A qui est destiné cet article?
Cet article s'adresse à tous ceux qui utilisent PyTorch pour entraîner des modèles. Sharded fonctionne sur n'importe quel modèle, quel que soit le modèle à entraîner: PNL (transformateur), visuel (SIMCL, swav, Resnet) ou même modèles de parole. Voici un aperçu du gain de performances que vous pouvez voir avec Sharded sur tous les types de modèles.
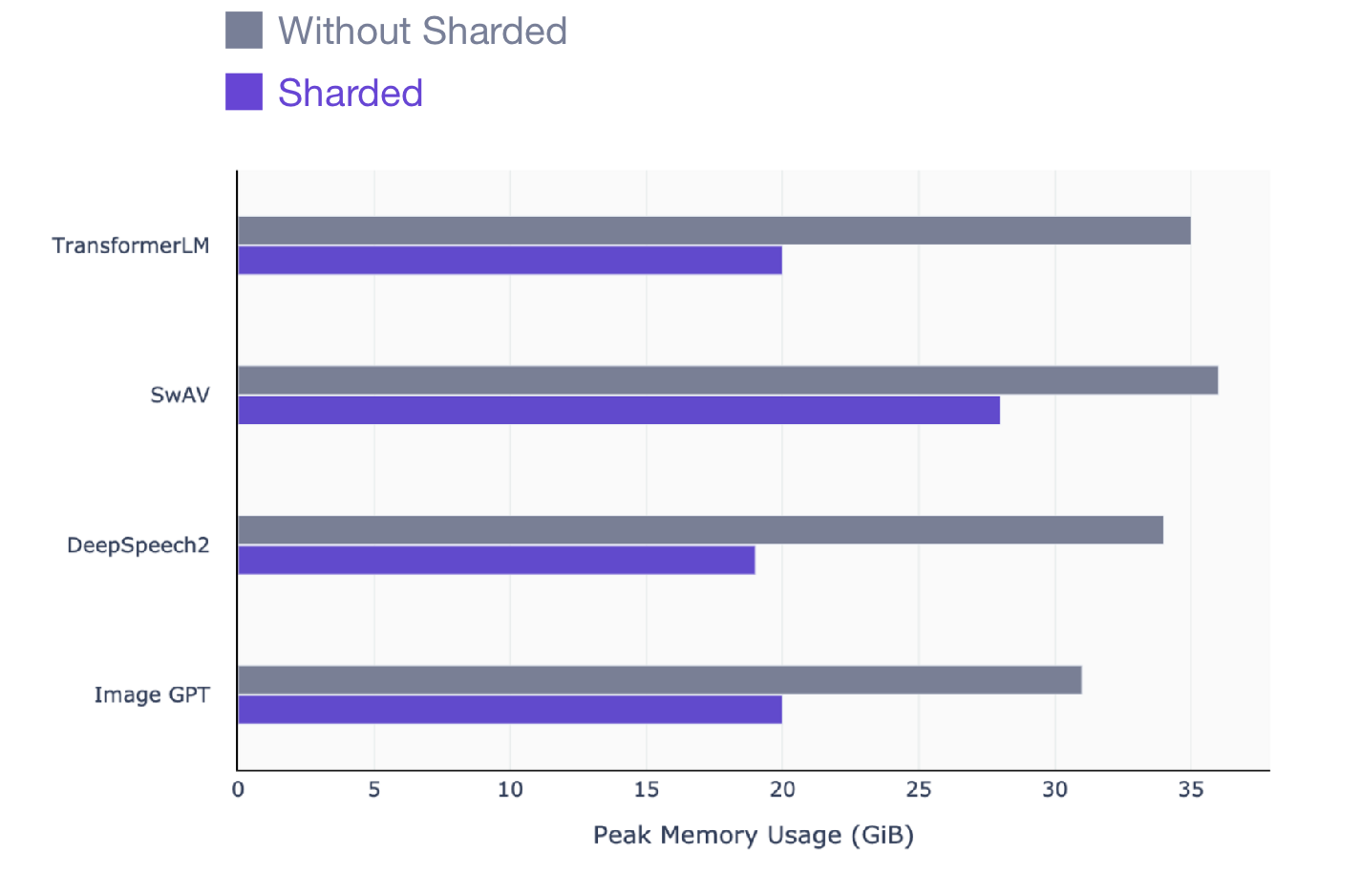
SwAV est une méthode d'apprentissage basée sur les données de pointe en vision par ordinateur.
DeepSpeech2 est une technique moderne pour les modèles vocaux.
Image GPT est une méthode avancée pour les modèles visuels.
Transformer est une technique avancée de traitement du langage naturel.
Comment utiliser Sharded avec PyTorch
Pour ceux qui n'ont pas beaucoup de temps pour lire l'explication intuitive du fonctionnement de Sharded, je vais vous expliquer tout de suite comment utiliser Sharded avec votre code PyTorch. Mais je vous conseille vivement de lire la fin de l'article pour comprendre comment fonctionne Sharded.
Sharded est conçu pour être utilisé avec plusieurs GPU afin de profiter pleinement des avantages disponibles. Mais la formation sur plusieurs GPU peut être intimidante et très pénible à mettre en place.
Le moyen le plus simple de charger votre code avec Sharded est de convertir votre modèle en PyTorch Lightning (il ne s'agit que d'une refactorisation). Voici une vidéo de 4 minutes qui vous montre comment convertir votre code PyTorch en Lightning.
Une fois que vous avez fait cela, activer Sharded sur 8 GPU est aussi simple que de changer un seul drapeau: aucune modification de votre code n'est requise.

Si votre modèle provient d'une autre bibliothèque d'apprentissage en profondeur, il fonctionnera toujours avec Lightning (NVIDIA Nemo, fast.ai, Hugging Face). Tout ce que vous avez à faire est d'importer le modèle dans LightningModule et de commencer à apprendre.
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
Explication intuitive du fonctionnement de Sharded
Plusieurs approches sont utilisées pour s'entraîner efficacement sur un grand nombre de GPU. Dans une approche (DP), chaque package est divisé entre les GPU. Voici une illustration DP où chaque partie du package est envoyée à un GPU différent et le modèle est copié plusieurs fois sur chacun.

Formation DP
Cette approche est cependant mauvaise, car les poids du modèle sont transmis via l'appareil. De plus, le premier GPU prend en charge tous les états de l'optimiseur. Par exemple, Adam conserve une copie complète supplémentaire des poids de votre modèle.
Dans une autre technique (distribution parallèle de données, DDP), chaque GPU est entraîné sur un sous-ensemble de données et les gradients sont synchronisés entre les GPU. Cette méthode fonctionne également sur de nombreuses machines (nœuds). Dans cette figure, chaque GPU reçoit un sous-ensemble des données et initialise les mêmes poids de modèle pour tous les GPU. Ensuite, après le retour, tous les dégradés sont synchronisés et mis à jour.
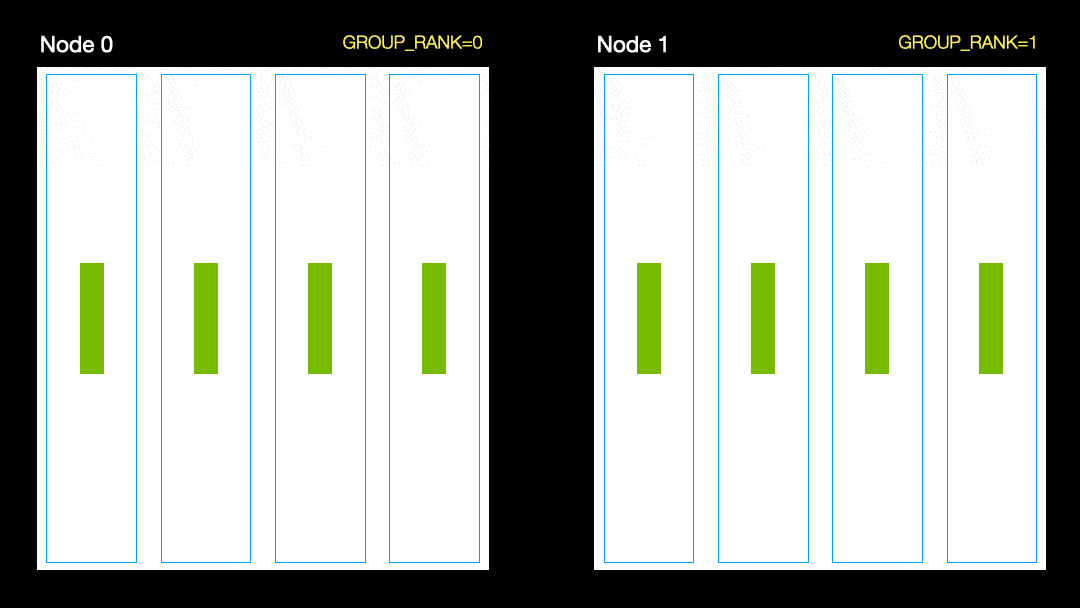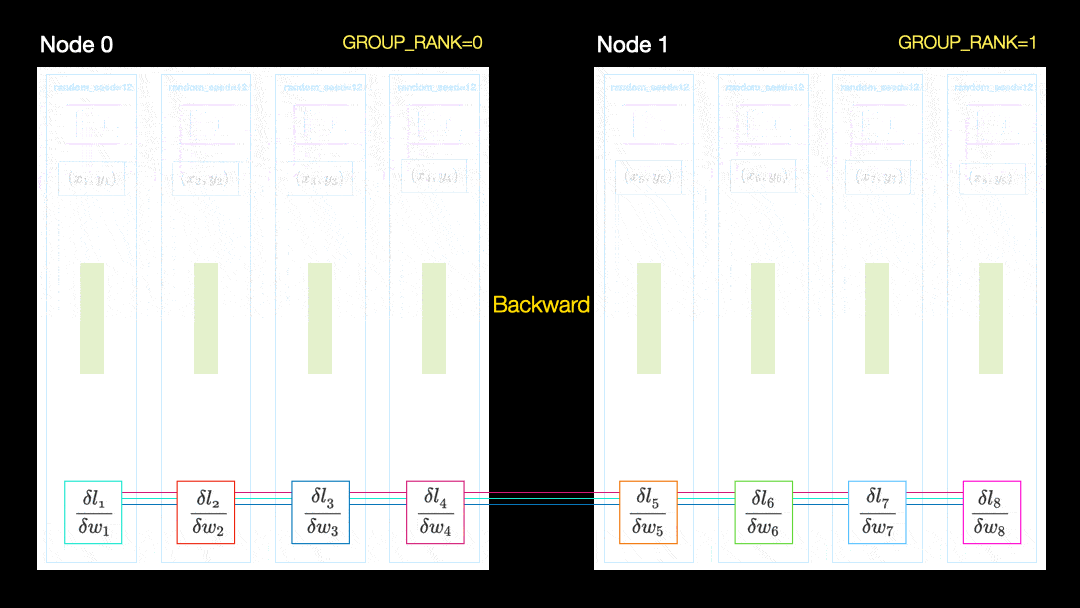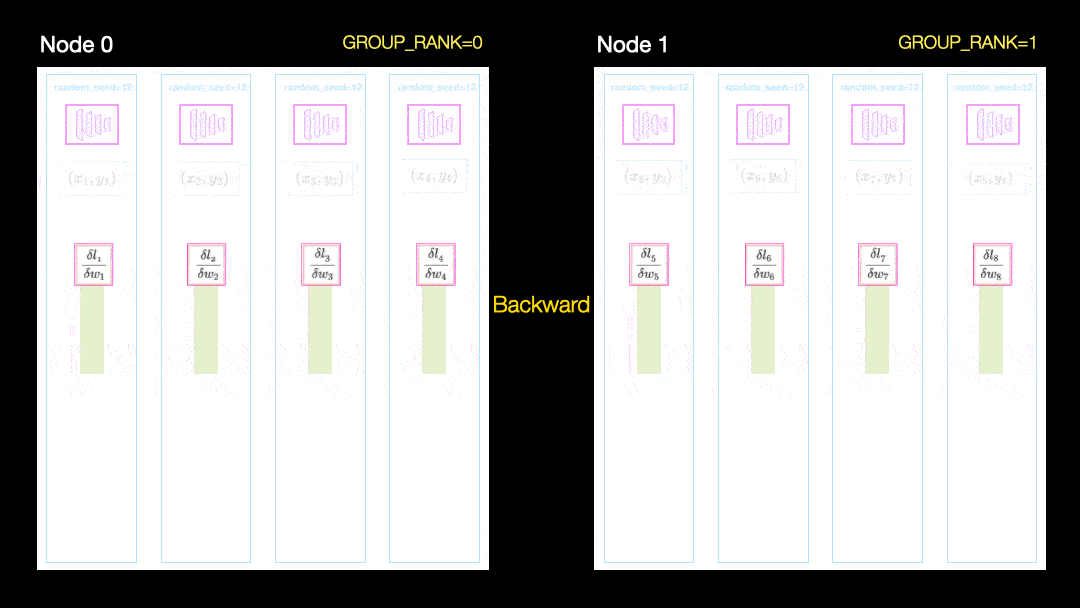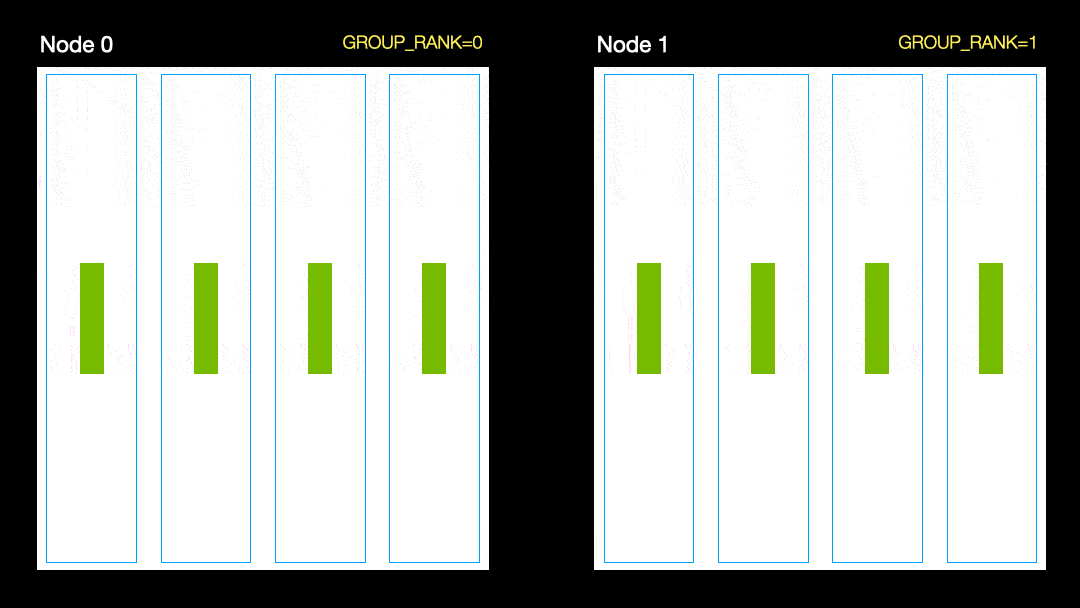
Distribution parallèle des données
Cependant, cette méthode pose toujours un problème, à savoir que chaque GPU doit conserver une copie de tous les états de l'optimiseur (environ 2-3 fois les paramètres du modèle), ainsi que toutes les activations avant et arrière.
Sharded supprime cette redondance. Il fonctionne de la même manière que DDP, sauf que tous les frais généraux (gradients, état de l'optimiseur, etc.) sont calculés pour seulement une fraction des paramètres totaux, et ainsi nous éliminons la redondance de stocker le même gradient et les mêmes états optimiseur sur tous les GPU. En d'autres termes, chaque GPU ne stocke qu'un sous-ensemble d'activations, de paramètres d'optimisation et de calculs de gradient.
Utiliser une sorte de mode distribué

Dans PyTorch Lightning, changer de mode de distribution est trivial.
Comme vous pouvez le voir, avec l'une de ces approches d'optimisation, il existe de nombreuses façons de tirer le meilleur parti de l'apprentissage distribué.
La bonne nouvelle est que tous ces modes sont disponibles dans PyTorch Lightning sans qu'il soit nécessaire de modifier le code. Vous pouvez essayer n'importe lequel d'entre eux et ajuster si nécessaire pour votre modèle spécifique.
Une méthode qui n'existe pas est le modèle parallèle. Cependant, cette méthode doit être mise en garde car elle s'est avérée beaucoup moins efficace que la formation segmentée et doit être utilisée avec prudence. Cela peut fonctionner dans certains cas, mais en général, il est préférable d'utiliser le partitionnement.
L'avantage d'utiliser Lightning est que vous ne vous laissez jamais distancer par les dernières avancées de la recherche sur l'IA! L'équipe et la communauté Open Source se sont engagées à partager les dernières avancées avec Lightning via Lightning.

- Cours d'apprentissage automatique
- Formation aux métiers de la Data Science
- Formation d'analyste de données
Autres professions et cours