- Vous permet d'écrire du code dans un langage familier, mais en même temps d'utiliser des fonctions qui n'existent que dans une autre langue.
- Permet une collaboration directe avec un collègue qui programme dans une autre langue.
- Il permet de travailler avec deux langues et éventuellement d'apprendre à les maîtriser.

De quoi avons nous besoin
Pour travailler, vous avez besoin de ces composants:
- R et Python, bien sûr.
- IDE RStudio (vous pouvez le faire dans d'autres IDE, mais dans RStudio, c'est plus facile).
- Votre gestionnaire d'environnement Python préféré (j'utilise conda ici).
- Packages
rmarkdown
etreticulate
installés dans R.
Lors de l'écriture de documents R Markdown, nous travaillerons dans RStudio, mais en même temps, nous naviguerons entre des extraits de code écrits en R et en Python. Je vais vous montrer quelques exemples simples.
Configuration de l'environnement Python
Si vous êtes familier avec la programmation Python, vous savez que tout travail effectué en Python doit faire référence à un environnement spécifique contenant tous les packages nécessaires au travail. Il existe de nombreuses façons de gérer les packages en Python, les deux plus populaires sont virtualenv et conda. Ici, je suppose que nous utilisons conda et qu'il est installé en tant que gestionnaire d'environnement Python.
Vous pouvez utiliser le package reticulate dans R pour configurer des environnements conda via la ligne de commande R si vous le souhaitez (en utilisant des fonctionnalités telles que
conda_create()
), mais en tant que programmeur Python ordinaire, je préfère configurer mes environnements manuellement.
Supposons que nous créons un environnement conda nommé
r_and_python
et que nous y installions
pandas
et
statsmodels
... Donc, les commandes dans le terminal:
conda create -name r_and_python conda activate r_and_python conda install pandas conda install statsmodels
Après l' installation
pandas
,
statsmodels
(et tous les autres paquets que vous pourriez avoir besoin), la configuration de l' environnement est terminée. Maintenant, exécutez conda info dans le terminal et sélectionnez le chemin vers votre environnement. Vous en aurez besoin à l'étape suivante.
Configurer votre projet R pour qu'il fonctionne avec R et Python
Nous allons démarrer un projet R dans RStudio, mais nous voulons pouvoir exécuter Python dans le même projet. Pour nous assurer que le code Python s'exécute dans l'environnement souhaité, nous devons définir la variable d'environnement système
RETICULATE_PYTHON
pour l'exécutable Python dans cet environnement. Ce sera le chemin que vous avez choisi dans la section précédente, suivi de
/bin/python3
.
La meilleure façon de s'assurer que cette variable est définie de manière permanente dans votre projet est de créer un fichier texte nommé dans le projet
.Rprofile
et d'y ajouter cette ligne.
Sys.setenv(RETICULATE_PYTHON=”path_to_environment/bin/python3")
Remplacez pathtoenvironment par le chemin que vous avez choisi dans la section précédente. Enregistrez le fichier
.Rprofile
et redémarrez la session R. Chaque fois que vous redémarrez une session ou un projet, il démarre
.Rprofile
et configure votre environnement Python. Si vous souhaitez tester cela, vous pouvez exécuter la ligne Sys.getenv ("RETICULATE_PYTHON").
Code d'écriture - Premier exemple
Vous pouvez désormais configurer un document R Markdown dans votre projet
.Rmd
et écrire du code dans deux langues différentes. Vous devez d'abord charger la bibliothèque réticulée dans votre premier morceau de code.
```{r} library(reticulate) ```
Désormais, lorsque vous souhaitez écrire du code Python, vous pouvez l'encapsuler avec des guillemets arrière normaux, mais marquez-le comme un extrait de code Python avec
{python}
, et lorsque vous souhaitez écrire en R, utilisez
{r}
.
Pour notre premier exemple, supposons que vous exécutiez un modèle Python sur un ensemble de données de résultats de test d'étudiants.
```{python} import pandas as pd import statsmodels.api as sm import statsmodels.formula.api as smf # obtain ugtests data url = “http://peopleanalytics-regression-book.org/data/ugtests.csv" ugtests = pd.read_csv(url) # define model model = smf.ols(formula = “Final ~ Yr3 + Yr2 + Yr1”, data = ugtests) # fit model fitted_model = model.fit() # see results summary model_summary = fitted_model.summary() print(model_summary) ```
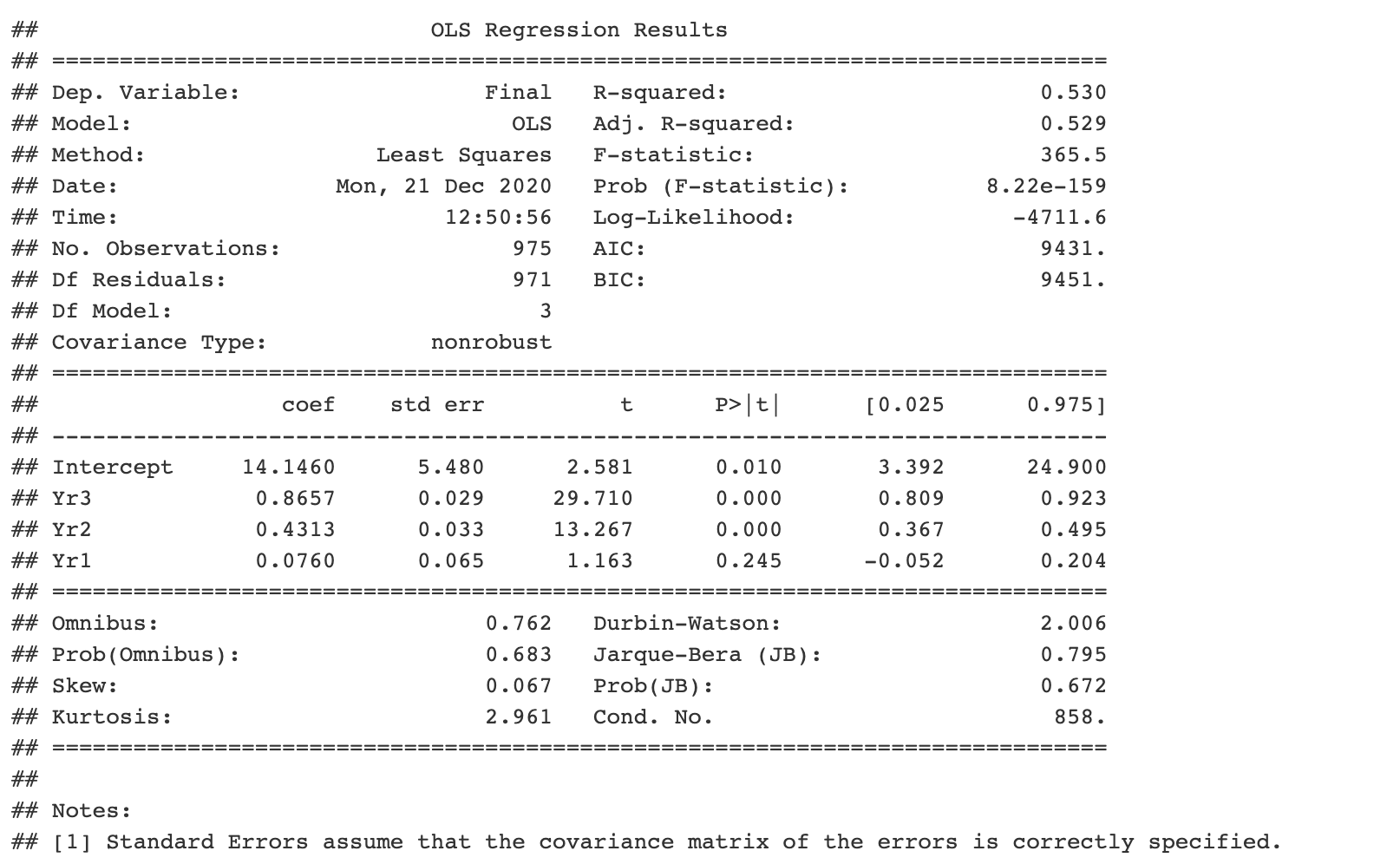
C'est génial, mais disons que vous avez dû quitter votre travail à cause de quelque chose de plus urgent et le remettre à votre collègue, le programmeur R. Vous espériez pouvoir diagnostiquer le modèle.
N'ai pas peur. Vous pouvez accéder à tous les objets python que vous avez créés dans la liste générale appelée py. Ainsi, si un bloc R est créé dans votre document R Markdown, vos collègues auront accès aux paramètres de votre modèle:
```{r} py$fitted_model$params ```

ou les premiers restes:
```{r} py$fitted_model$resid[1:5] ```

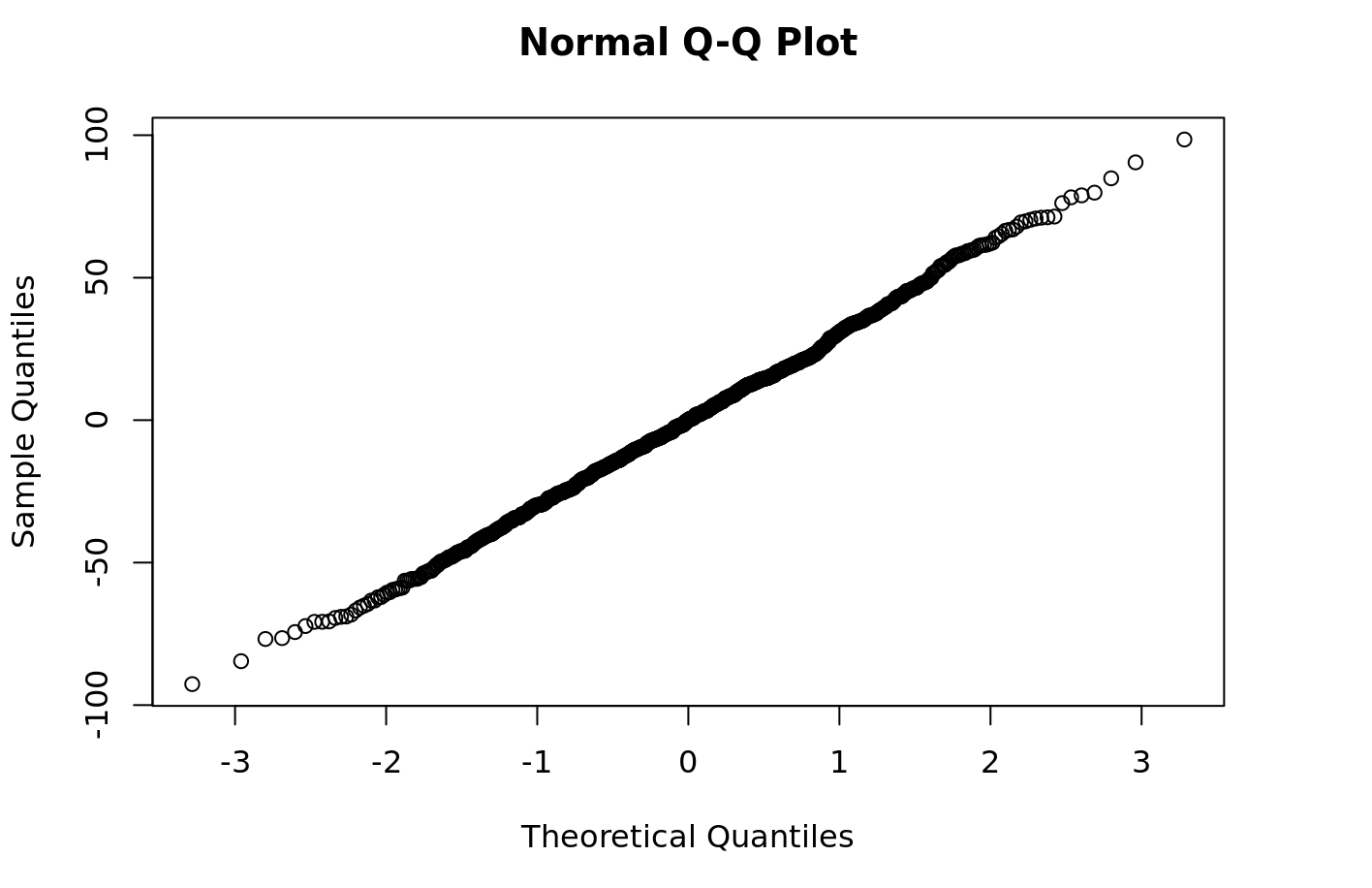
Maintenant, vous pouvez facilement effectuer des diagnostics sur le modèle, tels que le traçage des résidus de votre modèle quantile-quantile:
```{r} qqnorm(py$fitted_model$resid) ```
Code d'écriture - deuxième exemple
Vous avez analysé certaines données de datation Python et créé un cadre de données pandas avec toutes les données qu'il contient. Pour plus de simplicité, chargeons les données et regardons-les:
```{python} import pandas as pd url = “http://peopleanalytics-regression-book.org/data/speed_dating.csv" speed_dating = pd.read_csv(url) print(speed_dating.head()) ```

Vous avez maintenant exécuté un modèle de régression logistique simple en Python pour essayer d'associer la solution dec à d'autres variables. Cependant, vous comprenez que ces données sont en fait hiérarchiques et que le même iid individuel peut avoir plusieurs connaissances.
Vous savez donc que vous devez exécuter un modèle de régression logistique à effets mixtes, mais vous ne trouvez aucun programme Python qui le fasse!
Et encore une fois, n'ayez pas peur, envoyez le projet à un collègue et il écrira la solution dans R.
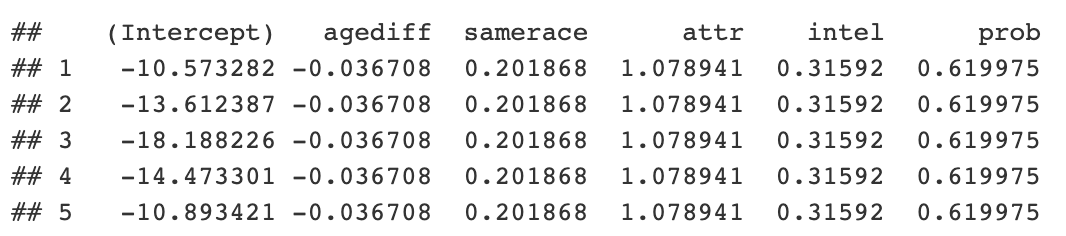
```{r} library(lme4) speed_dating <- py$speed_dating iid_intercept_model <- lme4:::glmer(dec ~ agediff + samerace + attr + intel + prob + (1 | iid), data = speed_dating, family = “binomial”) coefficients <- coef(iid_intercept_model)$iid ```
Vous pouvez maintenant obtenir le code et consulter les cotes. Il est également possible d'accéder aux objets Python R à l'intérieur d'un objet r générique.
```{python} coefs = r.coefficients print(coefs.head()) ```
Ces deux exemples montrent comment vous pouvez naviguer de manière transparente entre R et Python dans le même document R Markdown. Donc, la prochaine fois que vous envisagez de travailler sur un projet multilingue, pensez à exécuter toutes les étapes de R Markdown. Cela peut vous éviter beaucoup de tracas de basculer entre deux langues et vous aider à garder tout votre travail au même endroit sous forme de récit continu.
Vous pouvez voir le document R Markdown terminé construit autour de l'intégration du langage - avec des extraits de R et Python et des objets se déplaçant entre eux - posté ici . Le référentiel Github avec le code source est ici .
Les exemples de données dans le document proviennent de mon Référence de modélisation de régression People Analytics .

Autres professions et cours
PROFESSION
COURS
- Profession de développeur Java
- Profession de développeur frontend
- Profession développeur Web
- Profession hacker éthique
- Profession de développeur C ++
- Développeur de jeux Profession Unity
- Le métier de développeur iOS à partir de zéro
- Profession développeur Android à partir de zéro
COURS
- Cours d'apprentissage automatique
- Cours avancé "Machine Learning Pro + Deep Learning"
- «Python -»
- JavaScript
- « Machine Learning Data Science»
- DevOps