
Systèmes de conversion de requêtes de texte en SQL
Ce qu'un tel système devrait pouvoir faire:
- Recherchez des entités dans le texte qui correspondent aux entités de la base de données: tables, colonnes, parfois des valeurs.
- Lier des tables, former des filtres.
- Définissez un ensemble de données renvoyées, c'est-à-dire créez une liste de sélection.
- Déterminez l'ordre d'échantillonnage et le nombre de lignes.
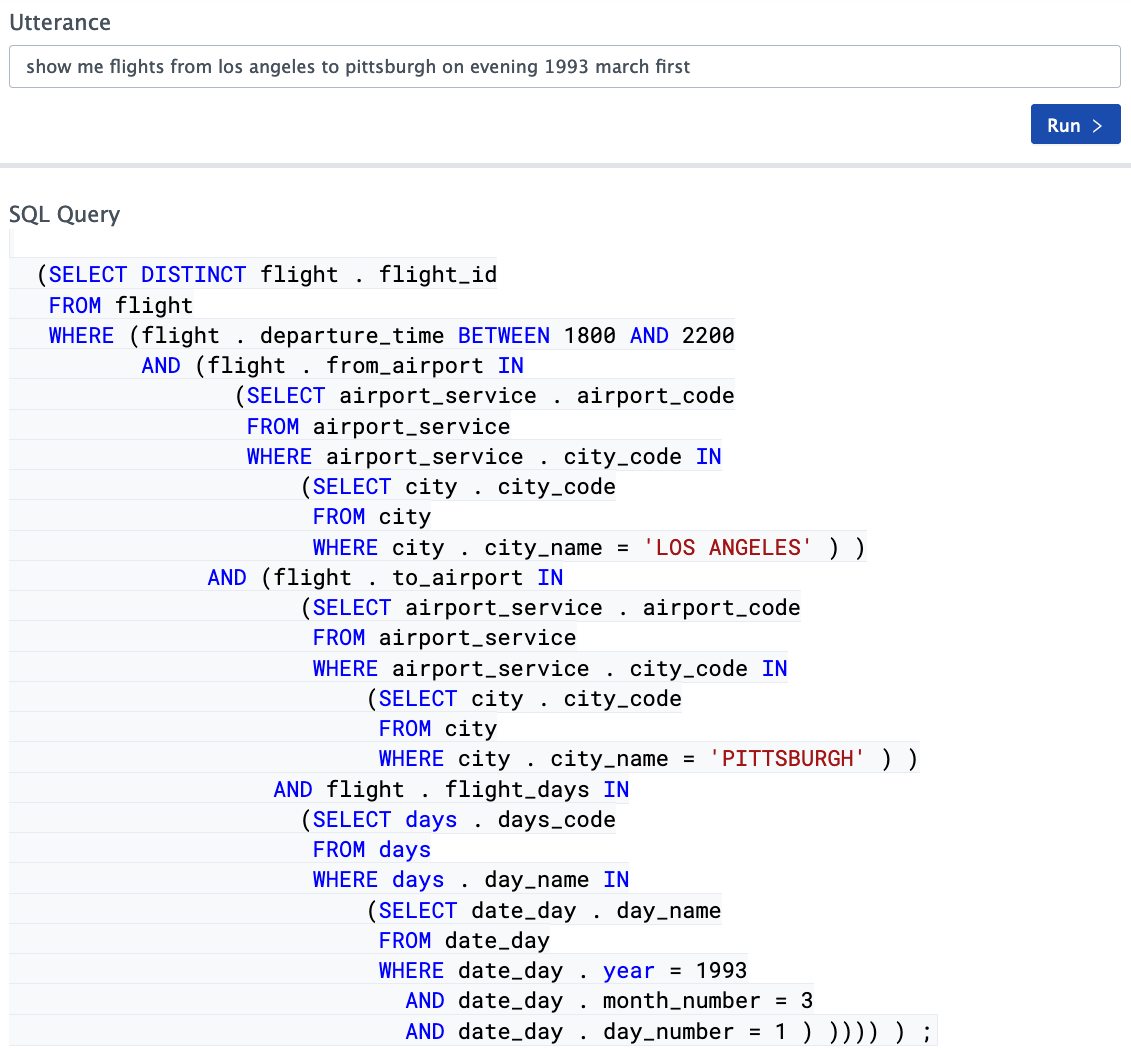
- Identifiez, en plus de celles qui sont relativement évidentes, certaines dépendances ou filtres absolument implicites qui sont opaques pour tout le monde sauf les concepteurs du schéma de base (voir la condition du champ bonus_type dans l'image ci-dessus)
- Résolvez les ambiguïtés lors de la sélection des entités. «Donnez-moi des données sur Ivanov» - devez-vous demander des informations sur une contrepartie ou un employé portant ce nom de famille? Données sur les employés pour février - Limiter l'échantillon par date d'embauche ou date de vente? etc.
C'est-à-dire qu'à la première étape, vous devez analyser la requête, comme lorsque vous travaillez avec tous les autres systèmes NLP, puis soit générer du SQL à la volée, soit trouver l'intention la plus appropriée, dans la fonction de laquelle une requête SQL paramétrée préalablement préparée est écrite. À première vue, la première option semble beaucoup plus impressionnante. Parlons-en plus en détail.
La particularité de tels systèmes est qu'en fait, une seule intention y est enregistrée, qui est déclenchée pour tout ce qui a au moins une relation avec le modèle, avec une super-fonction qui génère du SQL pour tous les types de requêtes. SQL peut être créé sur la base de toutes les règles, de manière algorithmique ou avec la participation de réseaux de neurones.
Algorithmes et règles
À première vue, la tâche de conversion d'une phrase analysée en SQL est un problème purement algorithmique, c'est-à-dire qu'elle peut être résolue sans problème. Il semble que nous ayons tout ce dont nous avons besoin pour convertir un modèle fort en un autre: entités reconnues, références, co-références, etc. Mais, malheureusement, les nuances et les ambiguïtés, comme toujours, compliquent tout, et dans ce cas, elles rendent l'approche 100% universelle presque inopérante. Les modèles sont imparfaits (voir exemples ci-dessus et plus loin dans l'article), les entités se croisent, à la fois dans les noms et dans le sens, la croissance de la complexité avec une augmentation du nombre d'entités et la complexité de la base devient non linéaire.
Les réseaux de neurones
L'utilisation de réseaux neuronaux pour de tels systèmes est un domaine en développement rapide. Dans le cadre de cet article, je me limiterai aux liens et aux brèves conclusions.
Je vous conseille de lire une courte série d'articles: 1 , 2 , 3 , 4 , 5 , ils contiennent un peu de théorie, une histoire sur la façon dont la formation et les tests de qualité sont effectués, un bref aperçu des solutions. De plus, ici - plus d'informations sur SparkNLP. Ici - à propos de la solution Photon de SalesForce. Selon la référence, un autre représentant de la communauté open source - Allennlp. Ici- des données sur la qualité des systèmes, c'est-à-dire les taux de test. Voici des données sur l'utilisation des bibliothèques NLP et, en particulier, des solutions similaires dans une entreprise.
Cette direction a un bel avenir, mais encore une fois avec des réserves - pas encore pour tous les types de modèles. Si, lorsque vous travaillez avec un modèle, vous n'avez pas besoin d'obtenir des chiffres complètement stricts et des résultats garantis précis, reproductibles et prévisibles (par exemple, vous devez déterminer une tendance, comparer des indicateurs, identifier les dépendances, etc.) - tout va bien. Mais le non-déterminisme et la nature probabiliste des réponses imposent des restrictions à l'utilisation d'une telle approche pour un certain nombre de systèmes.
Exemples de travail avec des systèmes basés sur des réseaux de neurones
Souvent, les entreprises qui fournissent des services de ce type affichent d'excellents résultats sur des vidéos bien faites et proposent ensuite de les contacter pour une conversation détaillée. Mais il existe également des démos en ligne disponibles sur le net. Il est particulièrement pratique d'expérimenter avec Photon , car dans ce cas, le diagramme de base est juste devant vos yeux. La deuxième démo que j'ai vue dans le domaine public vient d'Allennlp. L'analyse de certaines requêtes est surprenante par sa sophistication, certaines options sont légèrement moins réussies. L'impression générale est mitigée, essayez de jouer avec ces démos si vous êtes intéressé et formez votre opinion.
En général, la situation est assez intéressante. Les systèmes de traduction automatique de requêtes textuelles non structurées en SQL basés sur des réseaux de neurones s'améliorent de plus en plus, la qualité des tests réussis est de plus en plus élevée, mais leur valeur ne dépasse pas 70% au mieux ( jeu de données spider - environ 69% aujourd'hui journée). Ce résultat peut-il être considéré comme bon? Du point de vue du développement de tels systèmes, oui, bien sûr, les résultats sont impressionnants, mais il est loin d'être possible de les utiliser dans des systèmes réels sans modification pour tous types de tâches.
Outils Apache NlpCraft
Comment le projet Apache NlpCraft peut- il aider à construire et à organiser de tels systèmes? S'il n'y a pas de questions sur la première partie de la tâche (analyse d'une requête de texte), tout se passe comme d'habitude, alors pour la deuxième partie (la formation de requêtes SQL basées sur des données PNL), NlpCraft ne fournit pas une solution complète à 100%, mais seulement une boîte à outils qui aide à résoudre ce problème à elle seule ...
Où commencer? Si nous voulons automatiser le plus possible le processus de développement, les métadonnées du schéma de base de données et les données elles-mêmes nous aideront. Nous listerons les informations que nous pouvons extraire de la base de données et pour plus de simplicité nous nous limiterons aux tables, nous n'essaierons pas d'analyser les déclencheurs, les procédures stockées, etc.
- — . , .
- (null / not null) (where clause).
- , foreign keys , 1:1, 1:0, 1:n, n:m. joins.
- . , , .. , select list.
- . . - — , — enumeration, . .
- . , . .
- Primary and unique keys — , , , .
- (, , Oracle) — .
- Vérifier les contraintes - la connaissance des contraintes peut aider à créer tous les mêmes filtres sur ces colonnes.
Ainsi, si vous avez obtenu des métadonnées, vous en savez déjà beaucoup sur les entités du modèle. Ainsi, par exemple, dans un monde idéal, vous savez presque tout sur le tableau ci-dessous:
CREATE TABLE users (
id number primary key,
first_name varchar(32) not null,
last_name varchar(64) not null unique,
birthday date null,
salary_level_id number not null foreign key on salary_level(id)
);
En réalité, tout ne sera pas si rose, les noms seront abrégés et illisibles, les types de données s'avéreront souvent complètement inattendus, et les champs dénormalisés et les tables ajoutées à la hâte comme 1: 0 seront dispersés ici et là. Par conséquent, pour être réaliste, la plupart des bases de données qui sont en production depuis longtemps ne peuvent être utilisées qu'avec beaucoup de difficulté pour reconnaître des entités sans préparation préalable. Cela s'applique à tous les systèmes, et basé sur des réseaux de neurones, peut-être même plus que d'autres.
Dans cette situation, il est conseillé de donner au module NLP l'accès à un schéma quelque peu raffiné - un ensemble de vues pré-préparé, avec les noms de champ corrects, un ensemble nécessaire et suffisant de tables et de colonnes, des problèmes de sécurité, etc.
Commençons à concevoir
L'idée principale et très simple est qu'il est presque impossible de couvrir toutes les demandes des utilisateurs. Si l'utilisateur se fixe comme objectif de tromper le système et veut poser une question qui le confondra, il le fera facilement. La tâche du développeur est de trouver un équilibre entre les capacités du système en cours de développement et la complexité de sa mise en œuvre. D'où un conseil très simple: n'essayez pas de prendre en charge une intention universelle qui répond à toutes les questions, avec une méthode universelle qui génère du SQL pour toutes ces options. Essayez de renoncer à 100% de polyvalence, cela rendra le projet un peu moins coloré, mais plus réalisable.
- Demandez aux utilisateurs et notez 30 à 40 des types de questions les plus courants.
- , , , ..
- . SQL, 20-30 . , . SQL ML text2Sql, .
- . — , , , . — SQL . C — , .
Avec un tel volume de travail et des ressources suffisantes, le temps nécessaire pour résoudre un tel problème se mesure en jours, et au final vous avez une couverture à 80% des besoins des utilisateurs, et avec une qualité de performance assez élevée. Revenez ensuite au premier point et ajoutez d'autres intentions.
Le moyen le plus simple d'expliquer pourquoi il vaut la peine de prendre en charge plusieurs intentions est d'utiliser un exemple. Presque toujours les utilisateurs sont intéressés par un certain nombre de rapports très atypiques, quelque chose comme «comparez-moi tel ou tel pour telle ou telle période, mais non inclus dans telle ou telle période et en même temps ...». Aucun système ne sera capable de générer immédiatement du SQL pour une telle requête, vous devrez soit l'entraîner d'une manière ou d'une autre, soit sélectionner et programmer séparément de tels cas. Être capable de répondre à une gamme limitée de requêtes complexes est très important pour vos utilisateurs. Rechercher à nouveau un équilibre, pas le fait qu'il y aura suffisamment de ressources pour satisfaire toutes ces demandes, mais ignorer complètement ces souhaits signifie réduire la fonctionnalité du système à un niveau inacceptable. Si vous trouvez le bon ratio,votre système prendra un temps de développement limité et ne sera pas seulement un jouet amusant pendant quelques jours, causant plus tard de l'ennui plutôt que de l'utilité. Un point très important est que vous pouvez ajouter des intentions pour les demandes délicates non pas immédiatement, mais dans le processus, une par une. Nous avons MVP avec une seule intention universelle à la fois.
Boîte à outils et API
Apache NlpCraft fournit une boîte à outils pour simplifier la manipulation de la base de données.
Mode opératoire:
- Générer un modèle de modèle à partir de l'url jdbc de la base de données. Comme je l'ai mentionné ci-dessus, il est parfois préférable de préparer un ensemble de vues avec une représentation plus «correcte» des données et de donner accès à cet ensemble. Le moyen le plus simple de générer un modèle consiste à utiliser l'utilitaire CLI . Nous lançons l'utilitaire, spécifions le schéma de la base de données, le pilote jdbc, une liste des tables utilisées et ignorées et d'autres paramètres comme paramètres, voir la documentation pour plus de détails .
- JSON YAML , , , , .., , .
:
- id: "tbl:orders" groups: - "table" synonyms: - "orders" metadata: sql:name: "orders" sql:defaultselect: - "order_id" - "customer_id" - "employee_id" sql:defaultsort: - "orders.order_id#desc" sql:extratables: - "customers" - "shippers" - "employees" description: "Auto-generated from 'orders' table." ..... - id: "col:orders_order_id" groups: - "column" synonyms: - "{order_id|order <ID>}" - "orders {order_id|order <ID>}" - "{order_id|order <ID>} <OF> orders" metadata: sql:name: "order_id" sql:tablename: "orders" sql:datatype: 4 sql:isnullable: false sql:ispk: true description: "Auto-generated from 'orders.order_id' column."
- — , , . , . , , , , , , .. .
- Sur la base du modèle riche, le développeur peut utiliser une API compacte qui facilite grandement la construction de requêtes SQL dans la fonction d'intention - voir un exemple détaillé .
Vous trouverez ci-dessous un extrait de code pour plus de clarté:
@NCIntent(
"intent=commonReport " +
"term(tbls)~{groups @@ 'table'}[0,7] " +
"term(cols)~{
id == 'col:date' ||
id == 'col:num' ||
id == 'col:varchar'
}[0,7] " +
"term(condNums)~{id == 'condition:num'}[0,7] " +
"term(condVals)~{id == 'condition:value'}[0,7] " +
"term(condDates)~{id == 'condition:date'}[0,7] " +
"term(condFreeDate)~{id == 'nlpcraft:date'}? " +
"term(sort)~{id == 'nlpcraft:sort'}? " +
"term(limit)~{id == 'nlpcraft:limit'}?"
)
def onCommonReport(
ctx: NCIntentMatch,
@NCIntentTerm("tbls") tbls: Seq[NCToken],
@NCIntentTerm("cols") cols: Seq[NCToken],
@NCIntentTerm("condNums") condNums: Seq[NCToken],
@NCIntentTerm("condVals") condVals: Seq[NCToken],
@NCIntentTerm("condDates") condDates: Seq[NCToken],
@NCIntentTerm("condFreeDate") freeDateOpt: Option[NCToken],
@NCIntentTerm("sort") sortTokOpt: Option[NCToken],
@NCIntentTerm("limit") limitTokOpt: Option[NCToken]
): NCResult = {
val ext = NCSqlExtractorBuilder.build(SCHEMA, ctx.getVariant)
val query =
SqlBuilder(SCHEMA).
withTables(tbls.map(ext.extractTable): _*).
withAndConditions(extractValuesConditions(ext, condVals): _*).
...
// SQL
// .
}
Voici un fragment de la fonction d'intention par défaut qui répond à tout élément de base défini dans la demande et est déclenché si aucune correspondance plus stricte n'a été trouvée pendant le processus de correspondance. Il montre l'utilisation de l'API d'extraction d'éléments SQL, qui est impliquée dans la création de requêtes SQL, ainsi que l'utilisation de l'exemple du générateur SQL.
Encore une fois, je tiens à souligner qu'Apache NlpCraft ne fournit pas d'outil prêt à l'emploi pour traduire une requête de texte analysé en SQL, cette tâche sort du cadre du projet, du moins dans la version actuelle. Le code du générateur de requêtes est disponible dans des exemples, pas dans l'API, il a des limitations importantes, mais il se compose également de seulement 500 lignes de code avec des commentaires, ou environ 300 sans eux. Dans le même temps, malgré toute sa simplicité et même sa limitation, même cette implémentation la plus simple est capable de générer le SQL nécessaire pour un nombre très important des types les plus divers de requêtes utilisateur. Dans cette version, nous suggérons à nos utilisateurs intéressés par la construction de systèmes similaires d'utiliser cet exemplecomme modèle et développez-le en fonction de vos besoins. Oui, ce n'est pas une tâche pour une soirée, mais vous obtiendrez un résultat d'une qualité incomparablement supérieure à celle de l'utilisation directe de solutions universelles.
Je répète que dans la fonction d'intention par défaut, vous pouvez soit simplement modifier les exemples de l' exemple (selon les critiques, sa fonctionnalité peut bien suffire), soit utiliser des solutions avec des réseaux de neurones.
Conclusion
Construire un système pour accéder à une base de données n'est pas une tâche facile, mais Apache NlpCraft a déjà pris en charge une partie considérable du travail de routine, et en grande partie pour cette raison, le développement d'un système qualité décent prendra du temps et des ressources mesurables. Si la communauté Apache NlpCraft développera la direction de l'automatisation de la traduction des requêtes de texte en SQL et étendra cet exemple SQL simple à une API à part entière - le temps et les demandes des utilisateurs qui forment le plan et la direction du projet le montreront.