Lorsque l'on travaille avec la parole, plusieurs questions très "simples" se posent toujours, pour lesquelles il n'y a pas beaucoup d'outils pratiques, ouverts et simples: détection de la présence d'une voix (ou d'une musique), détection de la présence de nombres et classification des langues .
Pour résoudre le problème de la détection vocale (Voice Activity Detector, VAD), il existe un outil assez populaire de Google - webRTC VAD . Il est peu exigeant en ressources et compact, mais son principal inconvénient est son instabilité au bruit, un grand nombre de faux positifs et l'impossibilité de réglage fin. Il est clair que si nous reformulons le problème non pas en détection vocale, mais en détection de silence (le silence est l'absence à la fois de voix et de bruit), alors il est résolu de manière très triviale (seuil d'énergie, par exemple), mais avec les mêmes inconvénients et limitations. Le plus désagréable est que ces décisions sont souvent fragiles et que certains seuils de code en dur ne sont pas transférés vers d'autres domaines.
STT ( PyTorch ONNX), , , , VAD , MIT. .
"VAD"?
- VAD — , ;
- Number detector — , ;
- Language classifier — ;
- 4 (, , , ), VAD ( — - , , VAD !);
"" :
- 4 ;
- VAD WebRTC ;
- ;
- , 1 ;
- edge ;
- (PyTorch, ONNX);
- WebRTC , ;
- PyTorch (JIT), ONNX;
- ;
- ;
- (- , , STT);
- edge ;
- ONNX ;
- VAD 16 kHz, 8 kHz;
colab . , :
- PyTorch ONNX;
- — VAD — , / ;
- — . VAD ;
- , ( , 1 , - );
, VAD :
import torch
torch.set_num_threads(1)
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
wav = read_audio(f'{files_dir}/en.wav')
speech_timestamps = get_speech_ts(wav, model,
num_steps=4)
print(speech_timestamps)
VAD
, VAD. .
- 250 . , 100 , 30-50. ( 100 250 );
- VAD ( );
- 500 ( 200 ) 4 8 ;
- ;
- , "" "". - ;
1 AMD Ryzen Threadripper 3960X. :
torch.set_num_threads(1) # pytorch
ort_session.intra_op_num_threads = 1 # onnx
ort_session.inter_op_num_threads = 1 # onnx
, :
- num_steps — "";
- number of audio streams — ;
- , num_steps * number of audio streams;
:
| Batch size | Pytorch latency, ms | Onnx latency, ms |
|---|---|---|
| 2 | 9 | 2 |
| 4 | 11 | 4 |
| 8 | 14 | 7 |
| 16 | 19 | 12 |
| 40 | 36 | 29 |
| 80 | 64 | 55 |
| 120 | 96 | 85 |
| 200 | 157 | 137 |
, 1 :
| Batch size | num_steps | Pytorch model RTS | Onnx model RTS |
|---|---|---|---|
| 40 | 4 | 68 | 86 |
| 40 | 8 | 34 | 43 |
| 80 | 4 | 78 | 91 |
| 80 | 8 | 39 | 45 |
| 120 | 4 | 78 | 88 |
| 120 | 8 | 39 | 44 |
| 200 | 4 | 80 | 91 |
| 200 | 8 | 40 | 46 |
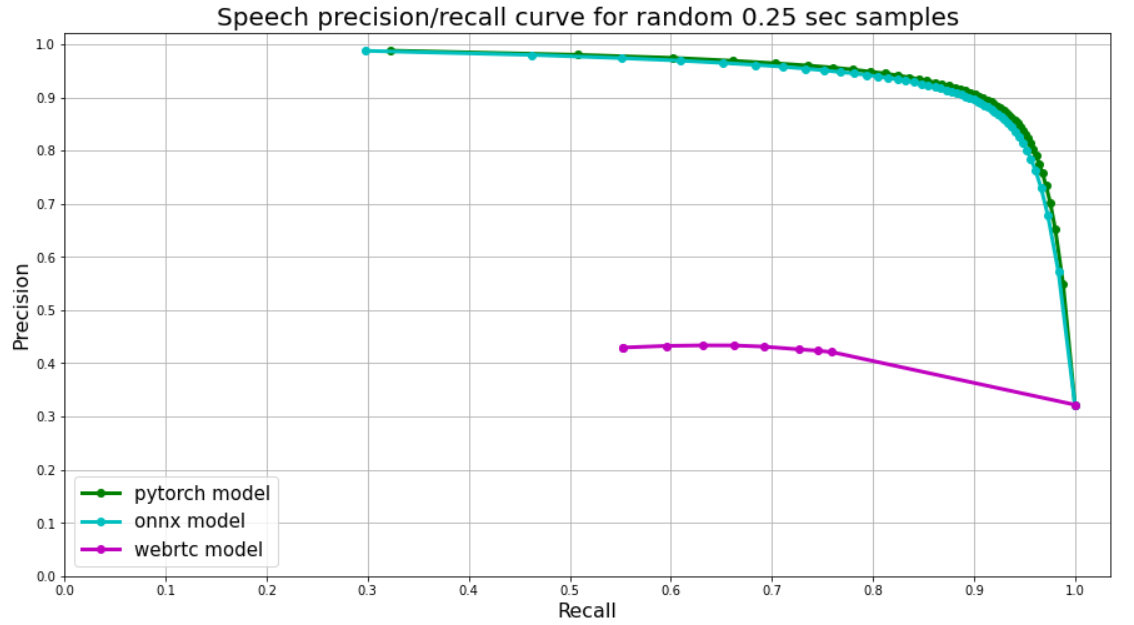
, , VAD . WebRT, 0 1?
WebRTC 0 1. - 30 , 250 8 . , 0 1 .
:
, VAD , . , . VAD.