La méthode habituelle de pagination est le décalage ou le numéro de page. Vous faites une demande comme celle-ci:
GET /api/products?page=10 {"items": [...100 products]}
et puis ceci:
GET /api/products?page=11 {"items": [...another 100 products]}
Dans le cas d'un simple déplacement, il s'avère
?offset=1000
et
?offset=1100
- les mêmes œufs, uniquement de profil. Ici, soit on passe directement à la requête SQL du type
OFFSET 1000 LIMIT 100
, soit on multiplie par la taille de la page (valeur
LIMIT
). Ce n'est de toute façon pas une solution optimale, car chaque base de données doit ignorer ces 1000 lignes. Et pour les ignorer, vous devez les identifier. Peu importe qu'il s'agisse de PostgreSQL, ElasticSearch ou MongoDB, il doit les ordonner, les recalculer et les jeter.
C'est un travail inutile. Mais il se répète encore et encore, car cette conception est facile à mettre en œuvre - vous mappez directement votre API à une requête de base de données.
Que faire alors? Nous avons pu voir comment fonctionnent les bases de données! Ils ont un concept de curseur - c'est un pointeur vers une chaîne. Vous pouvez donc dire à la base de données: "Rendez-moi 100 lignes après cela ." Et une telle requête est beaucoup plus pratique pour la base de données, car il y a une forte probabilité que vous identifiiez une ligne par un champ avec un index. Et vous n'êtes pas obligé d'aller chercher et de sauter ces lignes, vous passerez à côté d'elles.
Exemple:
GET /api/products {"items": [...100 products], "cursor": "qWe"}
L'API renvoie une chaîne (opaque), qui peut ensuite être utilisée pour obtenir la page suivante:
GET /api/products?cursor=qWe {"items": [...100 products], "cursor": "qWr"}
En termes de mise en œuvre, il existe de nombreuses options. En règle générale, vous disposez de certains critères de requête, tels qu'un identifiant de produit. Dans ce cas, vous l'encodez avec un algorithme réversible (disons des identificateurs de hachage ). Et lorsque vous recevez une requête avec un curseur, vous la décodez et générez une requête comme
WHERE id > :cursor LIMIT 100
.
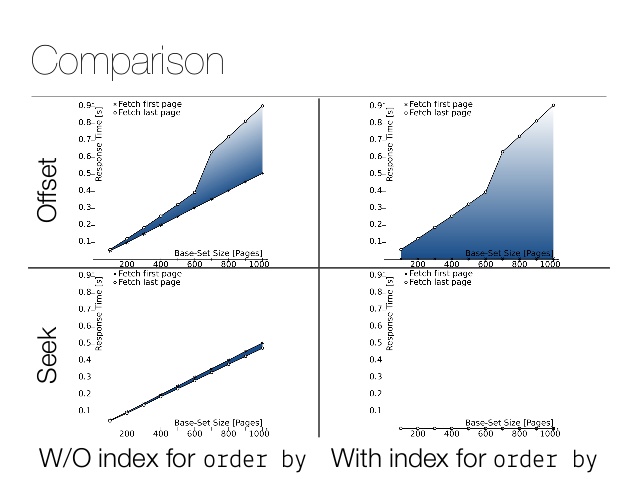
Petite comparaison des performances. Voici le résultat du décalage: Et voici le résultat de l'opération : Une différence de plusieurs ordres de grandeur! Bien entendu, les nombres réels dépendent de la taille de la table, des filtres et de l'implémentation du stockage. Voici un excellent article
=# explain analyze select id from product offset 10000 limit 100;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1114.26..1125.40 rows=100 width=4) (actual time=39.431..39.561 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1274406.22 rows=11437243 width=4) (actual time=0.015..39.123 rows=10100 loops=1)
Planning Time: 0.117 ms
Execution Time: 39.589 ms
where
=# explain analyze select id from product where id > 10000 limit 100;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..11.40 rows=100 width=4) (actual time=0.016..0.067 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1302999.32 rows=11429082 width=4) (actual time=0.015..0.052 rows=100 loops=1)
Filter: (id > 10000)
Planning Time: 0.164 ms
Execution Time: 0.094 ms
pour plus de détails techniques, voir la diapositive 42 pour une comparaison des performances.
Bien sûr, personne ne demande aux produits par ID - ils sont généralement interrogés pour une certaine pertinence (et ensuite l'ID comme paramètre décisif ). Dans le monde réel, le choix d'une solution nécessite d'examiner des données spécifiques. Les demandes peuvent être classées par identifiant (car il augmente de manière monotone). Les articles de la liste des achats futurs peuvent également être triés de cette manière - au moment où la liste a été compilée. Dans notre cas, les produits sont chargés depuis ElasticSearch, qui supporte naturellement un tel curseur.
L'inconvénient est que vous ne pouvez pas créer de lien vers la page précédente à l'aide de l'API sans état. Dans le cas de la pagination utilisateur, il n'y a aucun moyen de contourner ce problème. Donc, s'il est important d'avoir des boutons pour la page précédente / suivante et "Aller directement à la page 10", alors vous devez utiliser l'ancienne méthode. Mais dans d'autres cas, la méthode par curseur peut considérablement améliorer les performances, en particulier sur de très grandes tables avec une pagination très profonde.