 Il est pratique de photographier une page d'un passeport, une carte de visite d'un collègue, un accord avec une banque ou un chèque d'un restaurant sur un smartphone. Les documents importants sont toujours à portée de main et peuvent être imprimés ou envoyés. Mais trouver rapidement les fichiers dont vous avez besoin dans la galerie de téléphones mobiles devient de plus en plus difficile. En règle générale, les utilisateurs accumulent toute une collection de mèmes et d'images avec des chats mélangés à des photographies de factures d'électricité, de SNILS, etc. Les employés des entreprises, par exemple les directeurs de terrain d'une banque ou d'un cabinet d'avocats, ont également des situations similaires. Seulement au lieu de photos de chattes - des centaines de photos d'accords clients et d'autres documents. Comment trouver la copie nécessaire à envoyer à des collègues du bureau, ou comment imprimer une photo d'un permis de conduire à la bonne échelle, et non sur l'ensemble du A4? Nous devrons bricoler.
Il est pratique de photographier une page d'un passeport, une carte de visite d'un collègue, un accord avec une banque ou un chèque d'un restaurant sur un smartphone. Les documents importants sont toujours à portée de main et peuvent être imprimés ou envoyés. Mais trouver rapidement les fichiers dont vous avez besoin dans la galerie de téléphones mobiles devient de plus en plus difficile. En règle générale, les utilisateurs accumulent toute une collection de mèmes et d'images avec des chats mélangés à des photographies de factures d'électricité, de SNILS, etc. Les employés des entreprises, par exemple les directeurs de terrain d'une banque ou d'un cabinet d'avocats, ont également des situations similaires. Seulement au lieu de photos de chattes - des centaines de photos d'accords clients et d'autres documents. Comment trouver la copie nécessaire à envoyer à des collègues du bureau, ou comment imprimer une photo d'un permis de conduire à la bonne échelle, et non sur l'ensemble du A4? Nous devrons bricoler.
Il est beaucoup plus facile d'accomplir toutes ces tâches avec une seule application. C'est pourquoi nous avons mis à jour ABBYY FineScanner AI . Il est désormais capable de trier automatiquement les photos de la galerie du smartphone en 7 groupes de documents et de rechercher rapidement les photos nécessaires par requêtes textuelles.
Aujourd'hui, nous vous expliquerons en détail comment nous avons créé chacune de ces fonctionnalités, quelles technologies nous avons utilisées et comment le framework ABBYY NeoML y a contribué. Nous montrerons également comment cela fonctionne dans l'application. Et à la fin - nous partagerons nos plans pour le développement de FineScanner et vous poserons quelques questions.
Mettez tout sur les étagères des papas
Selon une étude d'Appsflyer , l'utilisation des appareils mobiles et les téléchargements d'applications, y compris les non- jeux , ont explosé en 2020. Pour travailler ensemble à distance, les employés ont besoin non seulement de messageries d'entreprise, mais aussi d'outils mobiles pratiques pour un traitement efficace de l'information, une impression, un flux de travail à distance et un stockage de données.
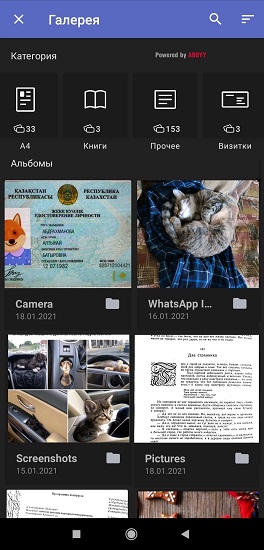
Selon les sondages des utilisateurs de FineScanner et les entretiens avec eux, le plus souvent des pages A4 d'une ou plusieurs pages (contrats, factures, lettres officielles, etc.), passeports et permis de conduire, livres, chèques et cartes de visite sont scannés à l'aide de l'application. 40% des répondants prennent des photographies de documents environ une fois par mois et 20% une fois par semaine. Sur la base de statistiques, nous avons compilé une liste de ces types de documents que les utilisateurs prennent le plus souvent avec un appareil photo et stockent dans la galerie du smartphone pour eux-mêmes ou pour le travail. Et puis nous avons appris à FineScanner à diviser les photos en groupes. Le processus se compose de deux étapes, se déroule entièrement en arrière-plan et ne nécessite pas de connexion Internet.
une). FineScanner classe d'abord les photos de la galerie de l'utilisateur
Après le premier lancement de l'application et la réception de toutes les autorisations de l'utilisateur, les réseaux de neurones intégrés analysent automatiquement les photos sur le smartphone et les répartissent en 7 catégories: format A4, livres, cartes de visite, cartes d'identité, reçus, texte manuscrit et «Autre» (des affiches, des cartes postales sont stockées dans ce dossier, des magazines couleur, etc.).

Notre réseau de neurones sur le moteur ABBYY NeoML , dont nous avons parlé en détail sur Habré, travaille sur la classification intelligente des images . Le mécanisme est constitué de deux réseaux de neurones: le premier détecte la présence de texte dans l'image, le second détermine les types de documents. L'architecture du réseau est basée sur des blocs MobilenetV3.
Il était important pour nous de séparer les documents manuscrits des documents imprimés, donc la première grille divise les fichiers en 3 classes:
- image avec texte manuscrit,
- image avec texte imprimé,
- image sans texte (chats, selfies et environnement).
Dans la première grille, nous avons également utilisé des informations sur le cadrage central (un morceau de l'image du centre, rogné en haute résolution) pour déterminer la présence de texte dans l'image. Nous avons pris un tel recadrage, car dans l'échantillon (nous en parlerons un peu ci-dessous) dans toutes les photos, le texte était principalement dans la partie centrale. Cette image est envoyée avec la vignette dans une branche distincte du réseau et l'aide à décider s'il y a du texte dans l'image ou non.
La deuxième grille définit les types de documents:
- Document A4 (avec quelques dessins),
- 4 ( , — , ),
- ( - ),
- ( , , ),
- ,
- ID (, .) – , ,
- ( . ).
L'ensemble de données pour la formation des réseaux de neurones a été collecté et marqué par nos employés. L'échantillon était constitué d'environ 40 000 photographies (cartes de visite, flyers, cartes bancaires, certificats, assurances, etc.) prises avec un smartphone.
En raison du réseau neuronal, le poids de l'application a augmenté de manière insignifiante - de seulement 3 Mo. Nous avons spécifiquement essayé de rendre le réseau neuronal compact. Je ne voulais pas trop gonfler l'application pour une fonctionnalité aussi "expérimentale".
2). Après classement, le texte est reconnu sur les photographies trouvées des documents.
Pour ce faire, nous utilisons notre technologie ABBYY Mobile Capture SDK , qui fonctionne à la fois dans TextGrabber pour l'OCR ou les séquences vidéo, et dans Business Card Reader pour le traitement des cartes de visite. FineScanner a déjà utilisé ce SDK pour une reconnaissance rapide des documents hors ligne. Cette fois, nous l'avons utilisé au maximum: il peut reconnaître le texte de milliers d'images. Bien sûr, nous essayons de le faire doucement et soigneusement afin que le processus ne charge pas l'appareil et ne dévore pas la batterie. De plus, nous avons décidé de ne pas télécharger les photos de l'utilisateur téléchargées sur les nuages pour le moment, mais de traiter uniquement celles qui sont disponibles localement sur l'appareil.
Le temps total de tout traitement de la galerie dépend du nombre de photos et de documents parmi eux, ainsi que de la génération du téléphone et est en moyenne de 10 à 30 minutes pour la première fois. À l'avenir, seules les nouvelles photographies seront numérisées, et il y en aura déjà beaucoup moins, pas des milliers de pièces.
Rechercher un document par son texte
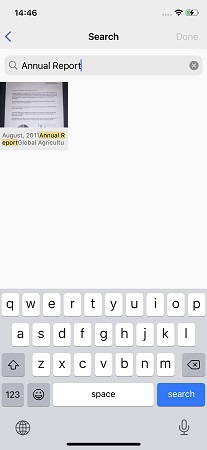 Trier les images par type est une bonne chose, mais que se passe-t-il s'il y a des centaines d'images dans le dossier Livres, mais que vous devez en trouver une, par exemple, une recette de shakshuka épicée photographiée à partir d'une encyclopédie culinaire rare? Ou trouver dans le dossier A4 un contrat de location signé il y a deux ans?
Trier les images par type est une bonne chose, mais que se passe-t-il s'il y a des centaines d'images dans le dossier Livres, mais que vous devez en trouver une, par exemple, une recette de shakshuka épicée photographiée à partir d'une encyclopédie culinaire rare? Ou trouver dans le dossier A4 un contrat de location signé il y a deux ans?
Dans de tels cas, nous avons appris à FineScanner comment rechercher le texte du document. De plus, l'option de recherche d'une requête exacte, mot pour mot, a été immédiatement supprimée. En règle générale, il n'est pas difficile de rechercher du texte sur des documents bien photographiés, mais dans la galerie d'un smartphone, il peut y avoir n'importe quoi - des photos fortement pivotées ou floues. Il n'est pas difficile d'organiser la soi-disant "recherche claire" selon eux, mais les résultats seront tristes. La capitalisation (en utilisant des majuscules), bien sûr, peut et doit être ignorée, mais il y a, par exemple, des fautes d'orthographe de la part des utilisateurs lors de la rédaction d'une demande.
Pour que l'application avale ce spectre d'erreurs, nous avons effectué une "recherche floue". Ils n'allaient pas écrire leur propre moteur de recherche à part entière, ils ont donc examiné les approches et les bibliothèques existantes. En conséquence, pour résoudre notre problème est venu le bon algorithme de diff Eugene Myers (l'algorithme de diff de Myer).
L'algorithme diff n'est pas utilisé pour la recherche, mais pour comparer deux textes ou deux versions d'un même document.
Ils ont pris la mise en œuvre finie d'ici . Certes, j'ai dû ajouter en plus le calcul de la distance de Levenshtein entre la requête de recherche et la sous-chaîne trouvée et sélectionner les seuils pour qu'il n'y ait pas d'options complètement sauvages. En conséquence, notre recherche de texte fonctionne clairement, rapidement et en temps réel.
Règle AR dans la version iOS, ou comment déterminer la taille d'un document sans danser avec un tambourin
 Lorsque nous avons développé de nouvelles fonctionnalités dans FineScanner, nous avons pris en compte les souhaits des utilisateurs. Par exemple, ils ont souvent besoin d'imprimer des documents non seulement des formats habituels (A4, A5, A6, carte de visite), mais aussi des documents non standard: dépliants, flyers, SNILS, etc. Et avec l'impression de tels fichiers, des difficultés se posent: par exemple, la photo est étirée sur tout le A4, bien que les proportions d'origine soient différentes.
Lorsque nous avons développé de nouvelles fonctionnalités dans FineScanner, nous avons pris en compte les souhaits des utilisateurs. Par exemple, ils ont souvent besoin d'imprimer des documents non seulement des formats habituels (A4, A5, A6, carte de visite), mais aussi des documents non standard: dépliants, flyers, SNILS, etc. Et avec l'impression de tels fichiers, des difficultés se posent: par exemple, la photo est étirée sur tout le A4, bien que les proportions d'origine soient différentes.
Les formats de documents les plus courants peuvent être sélectionnés à partir d'une liste prête à l'emploi en annexe, il en existe 8 types. Tout autre - cartes postales, visas, etc. - peut maintenant être mesuré automatiquement. Pour ce faire, nous avons intégré ARKit (ligne en réalité augmentée) dans la nouvelle version de FineScanner pour iOS. Pour son développement, nous avons utilisé l'API Apple en conjonction avec notre module de culture ABBYY Mobile Capture SDK, qui vous permet de définir les limites des documents même sur fond blanc et de les compléter si elles sont fermées à la main. La règle détermine la taille physique du document afin de le spécifier dans les propriétés et de l'afficher correctement sur papier lors de l'impression sur une imprimante.
Voilà comment cela fonctionne:
Comment nos clients professionnels utilisent FineScanner
Nos clients B2C seront les premiers à essayer la nouvelle fonctionnalité, et les entreprises commenceront à utiliser l'application un peu plus tard. Cela est principalement dû aux politiques de sécurité d'entreprise strictes.
Nos clients de grandes entreprises utilisent leurs versions d'ABBYY FineScanner sous le contrôle de diverses plates-formes MDM (Mobile Device Management, c'est-à-dire des solutions qui vous permettent de configurer les niveaux de protection des informations d'entreprise contre l'accès et la distribution non autorisés, ainsi que de déterminer si les informations stockées sur un appareil mobile seront disponibles pour des applications tierces). Par exemple, le personnel d' audit ou de conseil en entreprise de PwC utilise un scanner mobilepour une numérisation rapide de tous les documents. Lors des audits, ils prennent des photos, par exemple, de contrats ou de commandes en quelques secondes, les convertissent en PDF consultables et les envoient aux référentiels d'entreprise pour une vérification supplémentaire et une analyse des données.
Pour la commodité de nos clients, nous nous préparons maintenant à publier une version de FineScanner prenant en charge les systèmes MDM les plus populaires - Microsoft InTune, Mobile Iron, Workspace One et autres.
Pour le futur
Nous espérons que le FineScanner mis à jour aidera à simplifier les tâches de numérisation et de reconnaissance de documents et de livres directement sur votre smartphone, ainsi qu'à trouver rapidement les fichiers dont vous avez besoin dans la galerie et à les imprimer.
Nous recueillons régulièrement les demandes des utilisateurs pour FineScanner afin de comprendre comment développer davantage le produit. Selon notre dernière enquête, la moitié des utilisateurs envoient des documents photographiés à leur propre courrier ou à un autre courrier et continuent à travailler avec eux sur l'ordinateur, par exemple, pour imprimer ou stocker. De plus, plus de 70% s'attendent à ce que FineScanner s'intègre à ABBYY FineReader PDF . Il est devenu intéressant pour nous de découvrir ce que les Khabrovites en pensent.